 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Deep Local Descriptor for Improved Few-Shot Classification
Mar 30, 2021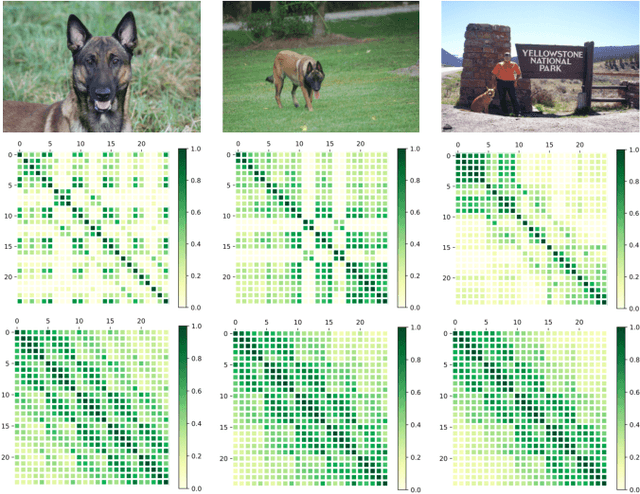
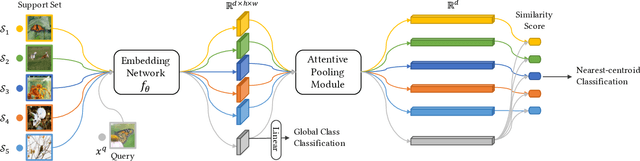
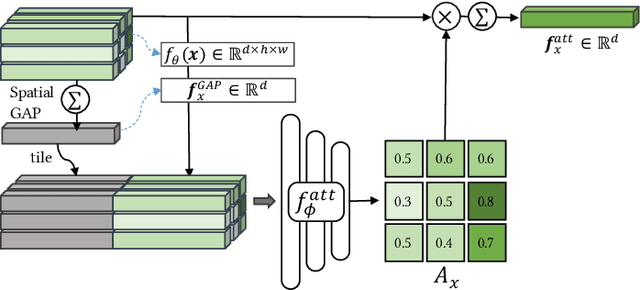
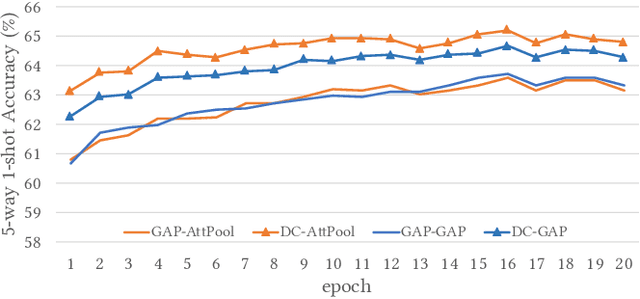
Few-shot classification studies the problem of quickly adapting a deep learner to understanding novel classes based on few support images. In this context, recent research efforts have been aimed at designing more and more complex classifiers that measure similarities between query and support images, but left the importance of feature embeddings seldom explored. We show that the reliance on sophisticated classifier is not necessary and a simple classifier applied directly to improved feature embeddings can outperform state-of-the-art methods. To this end, we present a new method named \textbf{DCAP} in which we investigate how one can improve the quality of embeddings by leveraging \textbf{D}ense \textbf{C}lassification and \textbf{A}ttentive \textbf{P}ooling. Specifically, we propose to pre-train a learner on base classes with abundant samples to solve dense classification problem first and then fine-tune the learner on a bunch of randomly sampled few-shot tasks to adapt it to few-shot scenerio or the test time scenerio. We suggest to pool feature maps by applying attentive pooling instead of the widely used global average pooling (GAP) to prepare embeddings for few-shot classification during meta-finetuning. Attentive pooling learns to reweight local descriptors, explaining what the learner is looking for as evidence for decision making. Experiments on two benchmark datasets show the proposed method to be superior in multiple few-shot settings while being simpler and more explainable. Code is available at: \url{https://github.com/Ukeyboard/dcap/}.
Multi-Agent Path Planning based on MPC and DDPG
Feb 26, 2021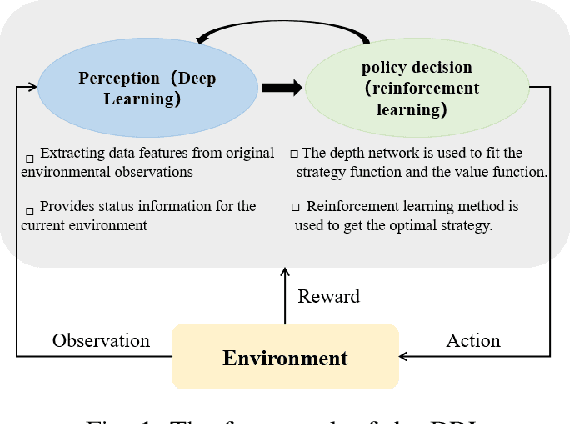
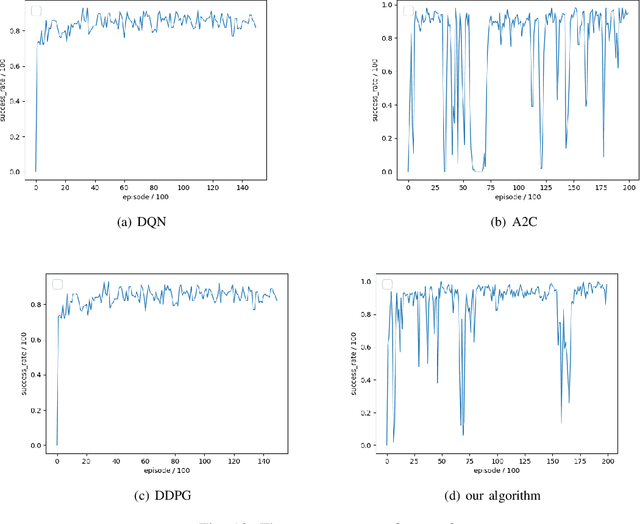
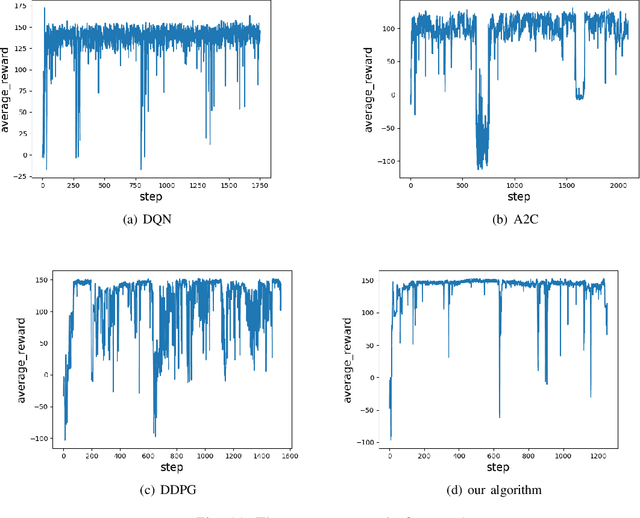
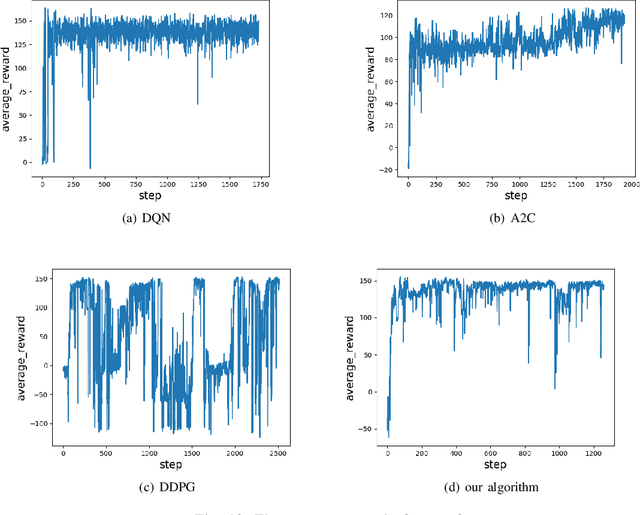
The problem of mixed static and dynamic obstacle avoidance is essential for path planning in highly dynamic environment. However, the paths formed by grid edges can be longer than the true shortest paths in the terrain since their headings are artificially constrained. Existing methods can hardly deal with dynamic obstacles. To address this problem, we propose a new algorithm combining Model Predictive Control (MPC) with Deep Deterministic Policy Gradient (DDPG). Firstly, we apply the MPC algorithm to predict the trajectory of dynamic obstacles. Secondly, the DDPG with continuous action space is designed to provide learning and autonomous decision-making capability for robots. Finally, we introduce the idea of the Artificial Potential Field to set the reward function to improve convergence speed and accuracy. We employ Unity 3D to perform simulation experiments in highly uncertain environment such as aircraft carrier decks and squares. The results show that our method has made great improvement on accuracy by 7%-30% compared with the other methods, and on the length of the path and turning angle by reducing 100 units and 400-450 degrees compared with DQN (Deep Q Network), respectively.
SiMaN: Sign-to-Magnitude Network Binarization
Feb 16, 2021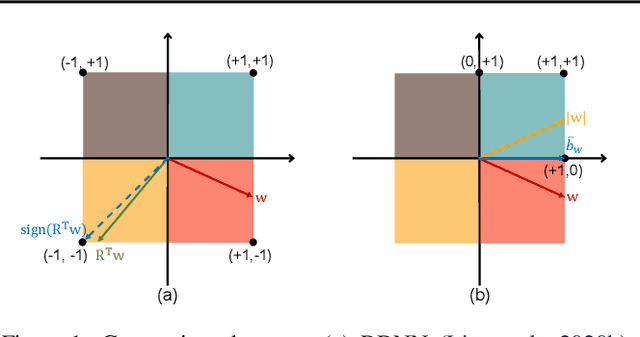

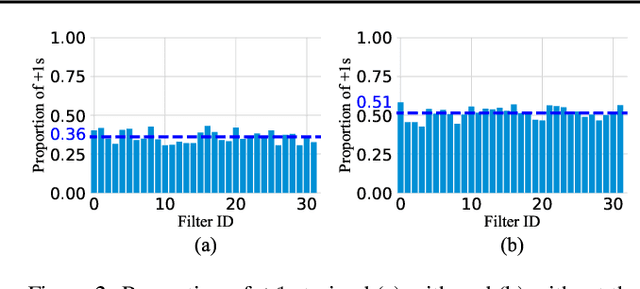
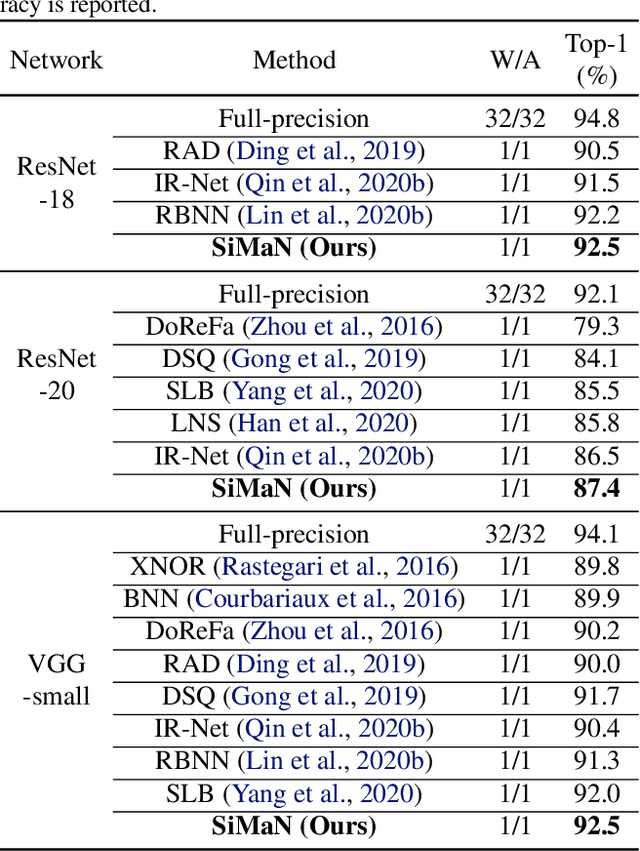
Binary neural networks (BNNs) have attracted broad research interest due to their efficient storage and computational ability. Nevertheless, a significant challenge of BNNs lies in handling discrete constraints while ensuring bit entropy maximization, which typically makes their weight optimization very difficult. Existing methods relax the learning using the sign function, which simply encodes positive weights into +1s, and -1s otherwise. Alternatively, we formulate an angle alignment objective to constrain the weight binarization to {0,+1} to solve the challenge. In this paper, we show that our weight binarization provides an analytical solution by encoding high-magnitude weights into +1s, and 0s otherwise. Therefore, a high-quality discrete solution is established in a computationally efficient manner without the sign function. We prove that the learned weights of binarized networks roughly follow a Laplacian distribution that does not allow entropy maximization, and further demonstrate that it can be effectively solved by simply removing the $\ell_2$ regularization during network training. Our method, dubbed sign-to-magnitude network binarization (SiMaN), is evaluated on CIFAR-10 and ImageNet, demonstrating its superiority over the sign-based state-of-the-arts. Code is at https://github.com/lmbxmu/SiMaN.
Probability Trajectory: One New Movement Description for Trajectory Prediction
Jan 26, 2021
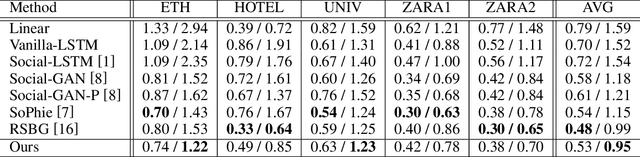


Trajectory prediction is a fundamental and challenging task for numerous applications, such as autonomous driving and intelligent robots. Currently, most of existing work treat the pedestrian trajectory as a series of fixed two-dimensional coordinates. However, in real scenarios, the trajectory often exhibits randomness, and has its own probability distribution. Inspired by this observed fact, also considering other movement characteristics of pedestrians, we propose one simple and intuitive movement description, probability trajectory, which maps the coordinate points of pedestrian trajectory into two-dimensional Gaussian distribution in images. Based on this unique description, we develop one novel trajectory prediction method, called social probability. The method combines the new probability trajectory and powerful convolution recurrent neural networks together. Both the input and output of our method are probability trajectories, which provide the recurrent neural network with sufficient spatial and random information of moving pedestrians. And the social probability extracts spatio-temporal features directly on the new movement description to generate robust and accurate predicted results. The experiments on public benchmark datasets show the effectiveness of the proposed method.
Trear: Transformer-based RGB-D Egocentric Action Recognition
Jan 05, 2021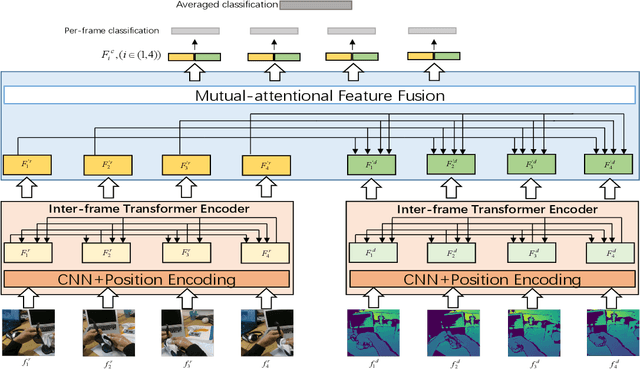
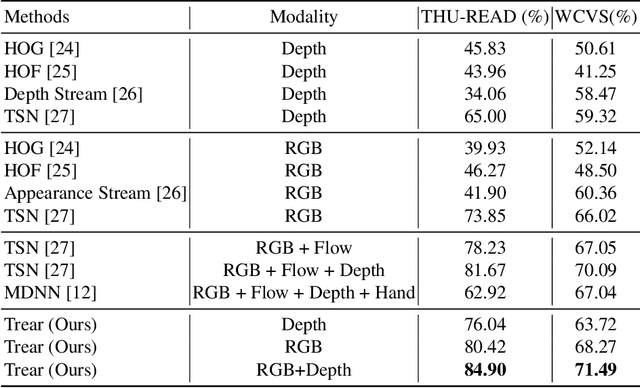
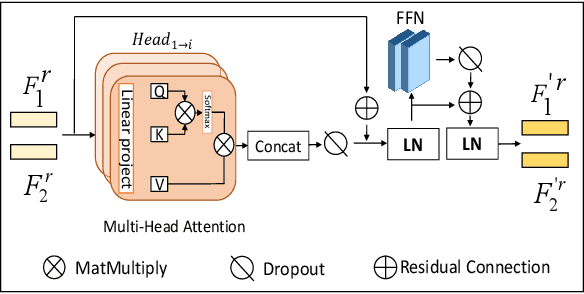
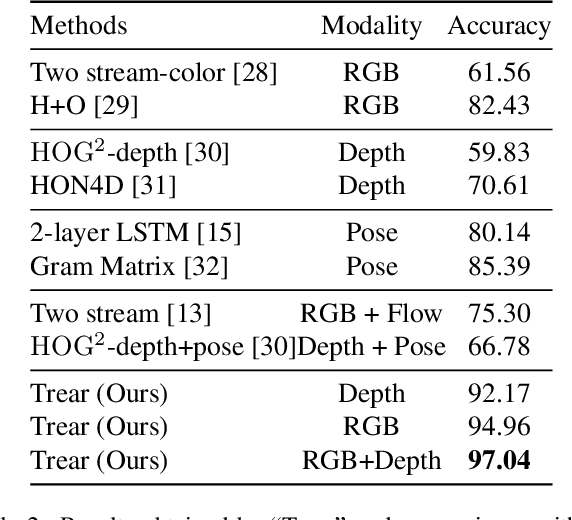
In this paper, we propose a \textbf{Tr}ansformer-based RGB-D \textbf{e}gocentric \textbf{a}ction \textbf{r}ecognition framework, called Trear. It consists of two modules, inter-frame attention encoder and mutual-attentional fusion block. Instead of using optical flow or recurrent units, we adopt self-attention mechanism to model the temporal structure of the data from different modalities. Input frames are cropped randomly to mitigate the effect of the data redundancy. Features from each modality are interacted through the proposed fusion block and combined through a simple yet effective fusion operation to produce a joint RGB-D representation. Empirical experiments on two large egocentric RGB-D datasets, THU-READ and FPHA, and one small dataset, WCVS, have shown that the proposed method outperforms the state-of-the-art results by a large margin.
Transformer Guided Geometry Model for Flow-Based Unsupervised Visual Odometry
Dec 08, 2020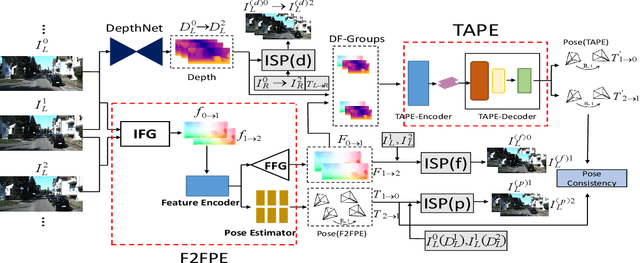
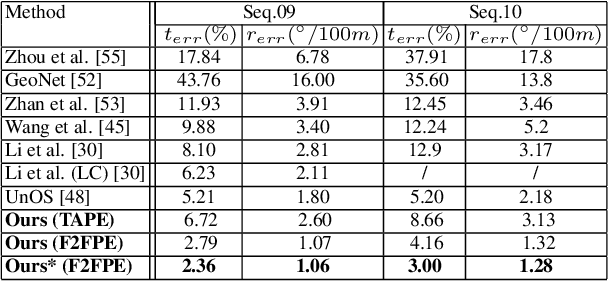
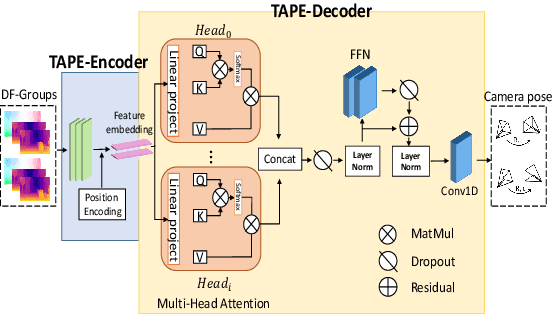
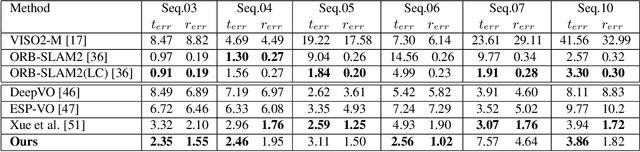
Existing unsupervised visual odometry (VO) methods either match pairwise images or integrate the temporal information using recurrent neural networks over a long sequence of images. They are either not accurate, time-consuming in training or error accumulative. In this paper, we propose a method consisting of two camera pose estimators that deal with the information from pairwise images and a short sequence of images respectively. For image sequences, a Transformer-like structure is adopted to build a geometry model over a local temporal window, referred to as Transformer-based Auxiliary Pose Estimator (TAPE). Meanwhile, a Flow-to-Flow Pose Estimator (F2FPE) is proposed to exploit the relationship between pairwise images. The two estimators are constrained through a simple yet effective consistency loss in training. Empirical evaluation has shown that the proposed method outperforms the state-of-the-art unsupervised learning-based methods by a large margin and performs comparably to supervised and traditional ones on the KITTI and Malaga dataset.
Learning Efficient GANs using Differentiable Masks and co-Attention Distillation
Nov 21, 2020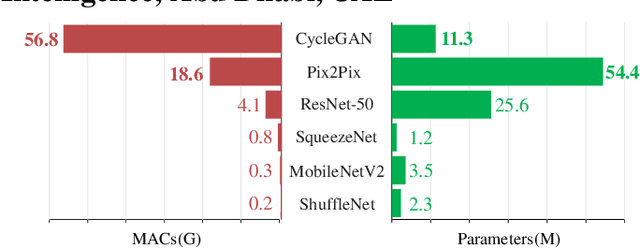
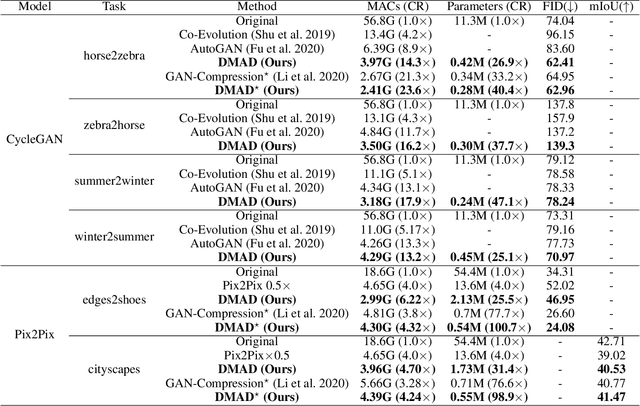
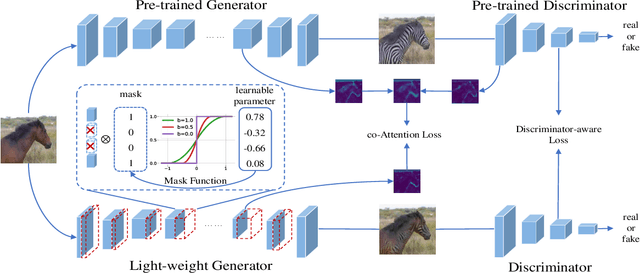
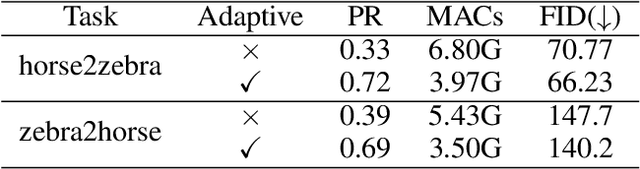
Generative Adversarial Networks (GANs) have been widely-used in image translation, but their high computational and storage costs impede the deployment on mobile devices. Prevalent methods for CNN compression cannot be directly applied to GANs due to the complicated generator architecture and the unstable adversarial training. To solve these, in this paper, we introduce a novel GAN compression method, termed DMAD, by proposing a Differentiable Mask and a co-Attention Distillation. The former searches for a light-weight generator architecture in a training-adaptive manner. To overcome channel inconsistency when pruning the residual connections, an adaptive cross-block group sparsity is further incorporated. The latter simultaneously distills informative attention maps from both the generator and discriminator of a pre-trained model to the searched generator, effectively stabilizing the adversarial training of our light-weight model. Experiments show that DMAD can reduce the Multiply Accumulate Operations (MACs) of CycleGAN by 13x and that of Pix2Pix by 4x while retaining a comparable performance against the full model. Code is available at https://github.com/SJLeo/DMAD.
An End-to-end Method for Producing Scanning-robust Stylized QR Codes
Nov 16, 2020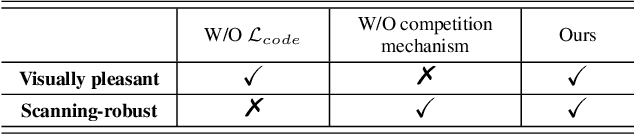

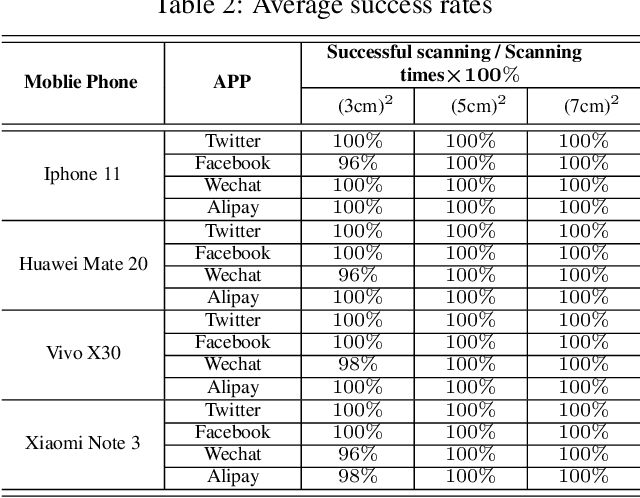
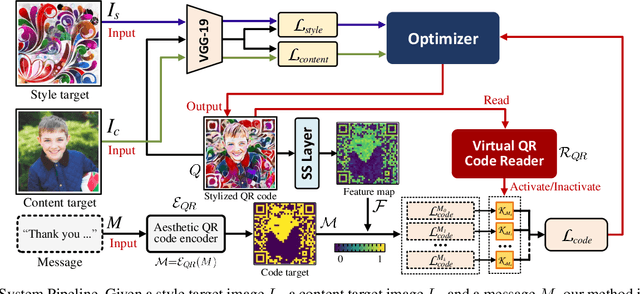
Quick Response (QR) code is one of the most worldwide used two-dimensional codes.~Traditional QR codes appear as random collections of black-and-white modules that lack visual semantics and aesthetic elements, which inspires the recent works to beautify the appearances of QR codes. However, these works adopt fixed generation algorithms and therefore can only generate QR codes with a pre-defined style. In this paper, combining the Neural Style Transfer technique, we propose a novel end-to-end method, named ArtCoder, to generate the stylized QR codes that are personalized, diverse, attractive, and scanning-robust.~To guarantee that the generated stylized QR codes are still scanning-robust, we propose a Sampling-Simulation layer, a module-based code loss, and a competition mechanism. The experimental results show that our stylized QR codes have high-quality in both the visual effect and the scanning-robustness, and they are able to support the real-world application.
Memory-Augmented Relation Network for Few-Shot Learning
May 13, 2020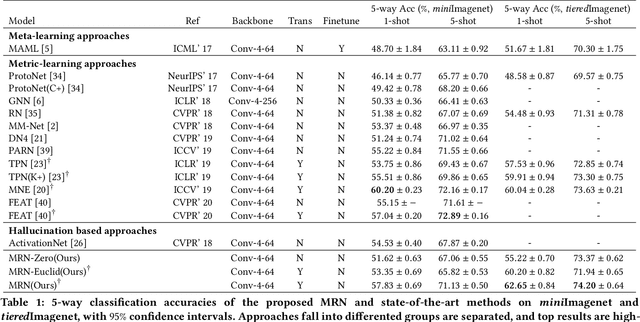
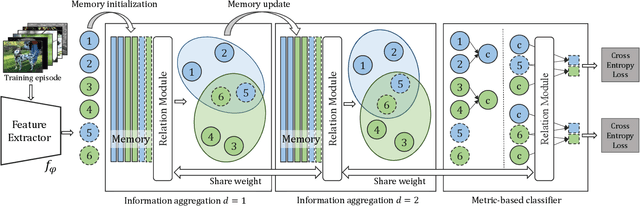
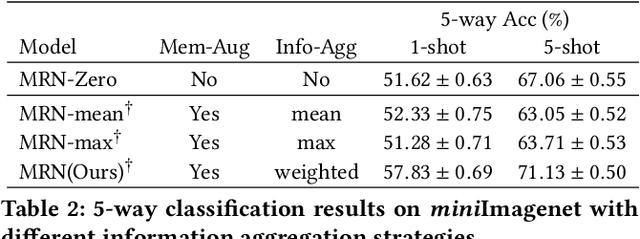

Metric-based few-shot learning methods concentrate on learning transferable feature embedding that generalizes well from seen categories to unseen categories under the supervision of limited number of labelled instances. However, most of them treat each individual instance in the working context separately without considering its relationships with the others. In this work, we investigate a new metric-learning method, Memory-Augmented Relation Network (MRN), to explicitly exploit these relationships. In particular, for an instance, we choose the samples that are visually similar from the working context, and perform weighted information propagation to attentively aggregate helpful information from the chosen ones to enhance its representation. In MRN, we also formulate the distance metric as a learnable relation module which learns to compare for similarity measurement, and augment the working context with memory slots, both contributing to its generality. We empirically demonstrate that MRN yields significant improvement over its ancestor and achieves competitive or even better performance when compared with other few-shot learning approaches on the two major benchmark datasets, i.e. miniImagenet and tieredImagenet.
BANet: Bidirectional Aggregation Network with Occlusion Handling for Panoptic Segmentation
Mar 31, 2020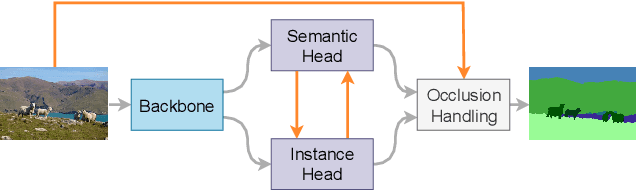
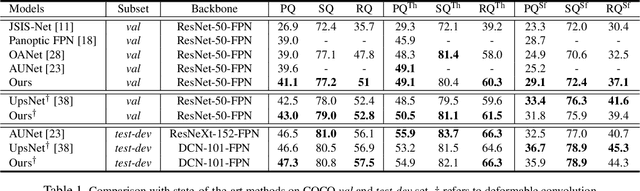
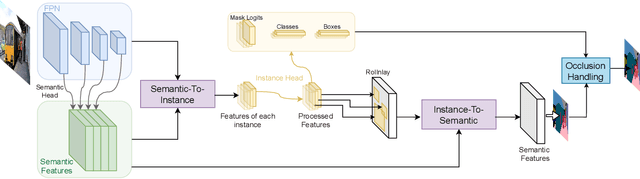

Panoptic segmentation aims to perform instance segmentation for foreground instances and semantic segmentation for background stuff simultaneously. The typical top-down pipeline concentrates on two key issues: 1) how to effectively model the intrinsic interaction between semantic segmentation and instance segmentation, and 2) how to properly handle occlusion for panoptic segmentation. Intuitively, the complementarity between semantic segmentation and instance segmentation can be leveraged to improve the performance. Besides, we notice that using detection/mask scores is insufficient for resolving the occlusion problem. Motivated by these observations, we propose a novel deep panoptic segmentation scheme based on a bidirectional learning pipeline. Moreover, we introduce a plug-and-play occlusion handling algorithm to deal with the occlusion between different object instances. The experimental results on COCO panoptic benchmark validate the effectiveness of our proposed method. Codes will be released soon at https://github.com/Mooonside/BANet.