 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards the Connection between Activation Sparsity and Flat Minima
May 25, 2026The observation that activation sparsity emerges in MLP blocks of standardly trained Transformers offers an opportunity to drastically reduce computation costs without sacrificing performance. To theoretically explain this phenomenon, existing works have shown that activation sparsity does not result from the data properties or data fitting but from the implicit bias of the training process. However, these connections are obtained with strong assumptions, which cannot be applied to deep models standardly trained with a large number of steps. Different from these works, we find that the flatness of loss landscapes is also closely related to the MLP activation sparsity and can serve as a weaker and naturally emerging assumption standard deep networks. Specifically, we find that 1) the MLP activation sparsity equals a ratio between "augmented flatness" (a weighted sum of flatness measures) and the product of the input norm and activation gradient of the MLP. We empirically find that this ratio decreases during training, leading to sparse activations. 2) We also propose the notion of derivative sparsity, which reduces to activation sparsity under ReLU, but further enables pruning in the backward propagation and is more stable than activation sparsity. With the theoretical findings, we can further encourage activation sparsity by decreasing the numerator and increasing the denominator of the ratio using three methods. These plug-and-play modifications can effectively reduce the ratio and produce sparser activations. Experiments on ImageNet-1K and C4 demonstrate relative improvements of at least 36% on inference sparsity and at least 50% on training sparsity over vanilla Transformers, indicating further potential cost reduction in both inference and training
When Shared Knowledge Hurts: Spectral Over-Accumulation in Model Merging
Feb 05, 2026Model merging combines multiple fine-tuned models into a single model by adding their weight updates, providing a lightweight alternative to retraining. Existing methods primarily target resolving conflicts between task updates, leaving the failure mode of over-counting shared knowledge unaddressed. We show that when tasks share aligned spectral directions (i.e., overlapping singular vectors), a simple linear combination repeatedly accumulates these directions, inflating the singular values and biasing the merged model toward shared subspaces. To mitigate this issue, we propose Singular Value Calibration (SVC), a training-free and data-free post-processing method that quantifies subspace overlap and rescales inflated singular values to restore a balanced spectrum. Across vision and language benchmarks, SVC consistently improves strong merging baselines and achieves state-of-the-art performance. Furthermore, by modifying only the singular values, SVC improves the performance of Task Arithmetic by 13.0%. Code is available at: https://github.com/lyymuwu/SVC.
Leveraging Flatness to Improve Information-Theoretic Generalization Bounds for SGD
Jan 04, 2026Information-theoretic (IT) generalization bounds have been used to study the generalization of learning algorithms. These bounds are intrinsically data- and algorithm-dependent so that one can exploit the properties of data and algorithm to derive tighter bounds. However, we observe that although the flatness bias is crucial for SGD's generalization, these bounds fail to capture the improved generalization under better flatness and are also numerically loose. This is caused by the inadequate leverage of SGD's flatness bias in existing IT bounds. This paper derives a more flatness-leveraging IT bound for the flatness-favoring SGD. The bound indicates the learned models generalize better if the large-variance directions of the final weight covariance have small local curvatures in the loss landscape. Experiments on deep neural networks show our bound not only correctly reflects the better generalization when flatness is improved, but is also numerically much tighter. This is achieved by a flexible technique called "omniscient trajectory". When applied to Gradient Descent's minimax excess risk on convex-Lipschitz-Bounded problems, it improves representative IT bounds' $Ω(1)$ rates to $O(1/\sqrt{n})$. It also implies a by-pass of memorization-generalization trade-offs.
* Published as a conference paper at ICLR 2025
Theoretical Explanation of Activation Sparsity through Flat Minima and Adversarial Robustness
Sep 06, 2023A recent empirical observation of activation sparsity in MLP layers offers an opportunity to drastically reduce computation costs for free. Despite several works attributing it to training dynamics, the theoretical explanation of activation sparsity's emergence is restricted to shallow networks, small training steps well as modified training, even though the sparsity has been found in deep models trained by vanilla protocols for large steps. To fill the three gaps, we propose the notion of gradient sparsity as the source of activation sparsity and a theoretical explanation based on it that explains gradient sparsity and then activation sparsity as necessary steps to adversarial robustness w.r.t. hidden features and parameters, which is approximately the flatness of minima for well-learned models. The theory applies to standardly trained LayerNorm-ed pure MLPs, and further to Transformers or other architectures if noises are added to weights during training. To eliminate other sources of flatness when arguing sparsities' necessity, we discover the phenomenon of spectral concentration, i.e., the ratio between the largest and the smallest non-zero singular values of weight matrices is small. We utilize random matrix theory (RMT) as a powerful theoretical tool to analyze stochastic gradient noises and discuss the emergence of spectral concentration. With these insights, we propose two plug-and-play modules for both training from scratch and sparsity finetuning, as well as one radical modification that only applies to from-scratch training. Another under-testing module for both sparsity and flatness is also immediate from our theories. Validational experiments are conducted to verify our explanation. Experiments for productivity demonstrate modifications' improvement in sparsity, indicating further theoretical cost reduction in both training and inference.
Bi-directional Graph Structure Information Model for Multi-Person Pose Estimation
Aug 19, 2018



In this paper, we propose a novel multi-stage network architecture with two branches in each stage to estimate multi-person poses in images. The first branch predicts the confidence maps of joints and uses a geometrical transform kernel to propagate information between neighboring joints at the confidence level. The second branch proposes a bi-directional graph structure information model (BGSIM) to encode rich contextual information and to infer the occlusion relationship among different joints. We dynamically determine the joint point with highest response of the confidence maps as base point of passing message in BGSIM. Based on the proposed network structure, we achieve an average precision of 62.9 on the COCO Keypoint Challenge dataset and 77.6 on the MPII (multi-person) dataset. Compared with other state-of-art methods, our method can achieve highly promising results on our selected multi-person dataset without extra training.
USAR: an Interactive User-specific Aesthetic Ranking Framework for Images
Aug 16, 2018
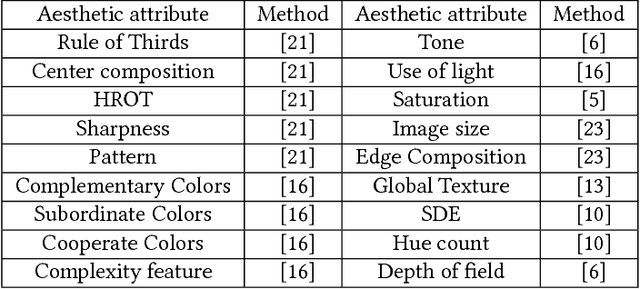
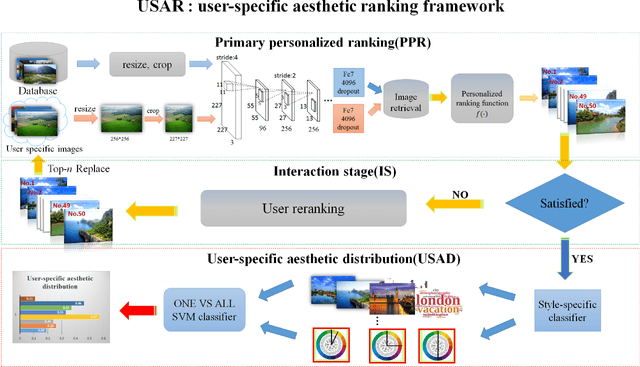
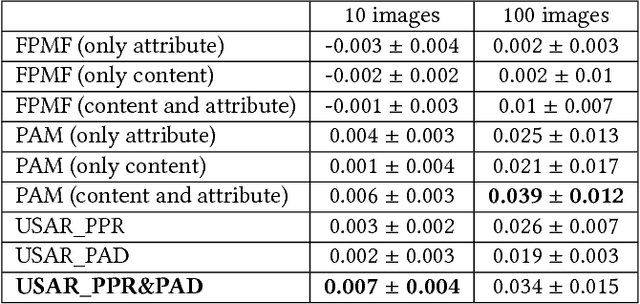
When assessing whether an image is of high or low quality, it is indispensable to take personal preference into account. Existing aesthetic models lay emphasis on hand-crafted features or deep features commonly shared by high quality images, but with limited or no consideration for personal preference and user interaction. To that end, we propose a novel and user-friendly aesthetic ranking framework via powerful deep neural network and a small amount of user interaction, which can automatically estimate and rank the aesthetic characteristics of images in accordance with users' preference. Our framework takes as input a series of photos that users prefer, and produces as output a reliable, user-specific aesthetic ranking model matching with users' preference. Considering the subjectivity of personal preference and the uncertainty of user's single selection, a unique and exclusive dataset will be constructed interactively to describe the preference of one individual by retrieving the most similar images with regard to those specified by users. Based on this unique user-specific dataset and sufficient well-designed aesthetic attributes, a customized aesthetic distribution model can be learned, which concatenates both personalized preference and aesthetic rules. We conduct extensive experiments and user studies on two large-scale public datasets, and demonstrate that our framework outperforms those work based on conventional aesthetic assessment or ranking model.