 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSSAGCN: Social Soft Attention Graph Convolution Network for Pedestrian Trajectory Prediction
Dec 05, 2021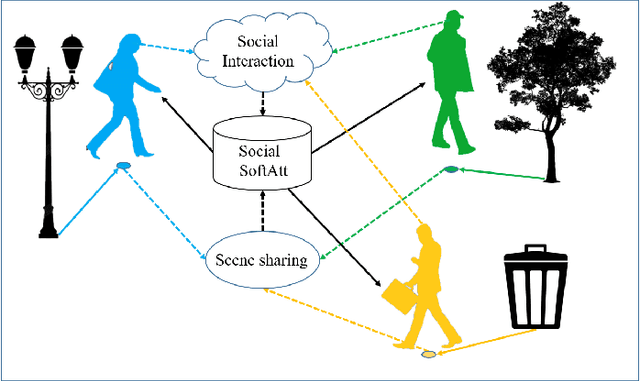
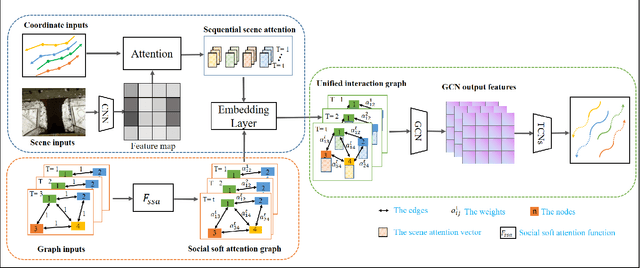
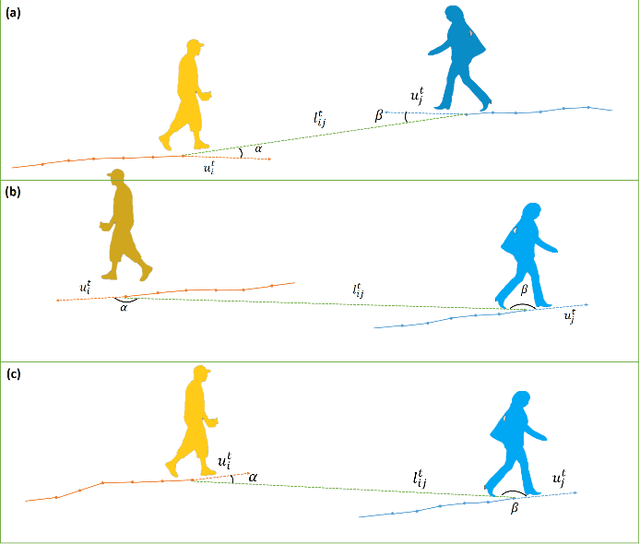
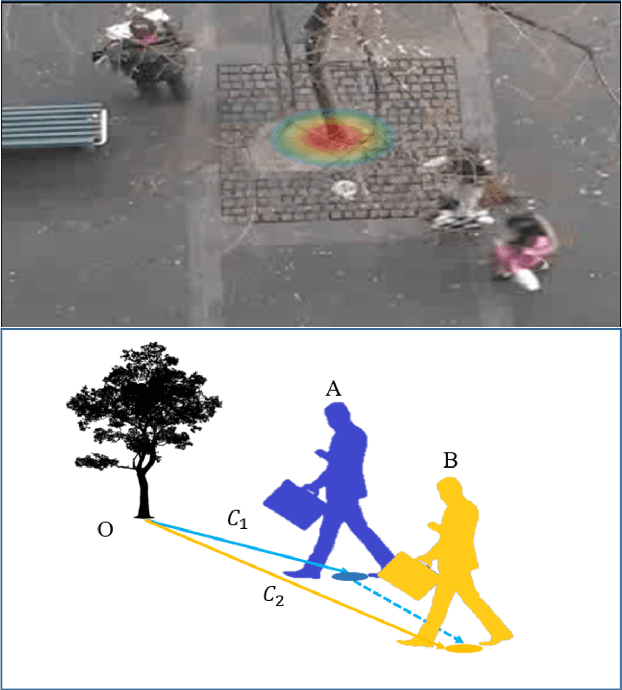
Pedestrian trajectory prediction is an important technique of autonomous driving, which has become a research hot-spot in recent years. Previous methods mainly rely on the position relationship of pedestrians to model social interaction, which is obviously not enough to represent the complex cases in real situations. In addition, most of existing work usually introduce the scene interaction module as an independent branch and embed the social interaction features in the process of trajectory generation, rather than simultaneously carrying out the social interaction and scene interaction, which may undermine the rationality of trajectory prediction. In this paper, we propose one new prediction model named Social Soft Attention Graph Convolution Network (SSAGCN) which aims to simultaneously handle social interactions among pedestrians and scene interactions between pedestrians and environments. In detail, when modeling social interaction, we propose a new \emph{social soft attention function}, which fully considers various interaction factors among pedestrians. And it can distinguish the influence of pedestrians around the agent based on different factors under various situations. For the physical interaction, we propose one new \emph{sequential scene sharing mechanism}. The influence of the scene on one agent at each moment can be shared with other neighbors through social soft attention, therefore the influence of the scene is expanded both in spatial and temporal dimension. With the help of these improvements, we successfully obtain socially and physically acceptable predicted trajectories. The experiments on public available datasets prove the effectiveness of SSAGCN and have achieved state-of-the-art results.
A Central Difference Graph Convolutional Operator for Skeleton-Based Action Recognition
Nov 13, 2021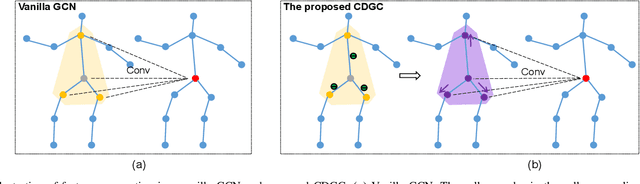
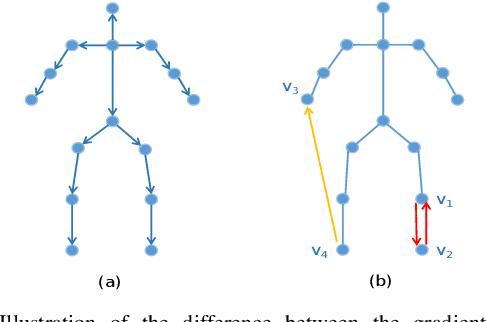
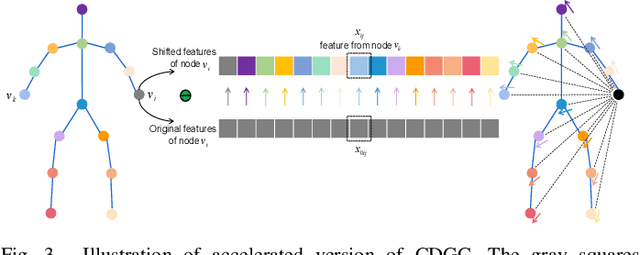
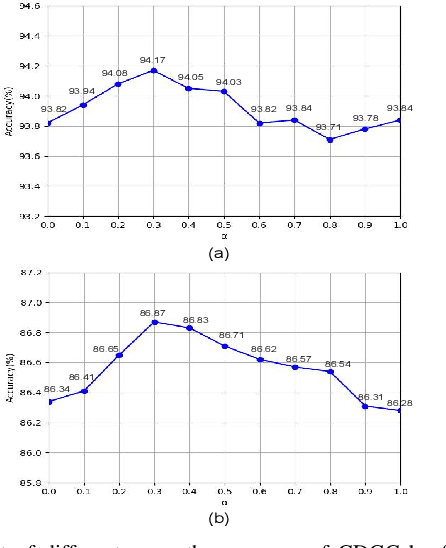
This paper proposes a new graph convolutional operator called central difference graph convolution (CDGC) for skeleton based action recognition. It is not only able to aggregate node information like a vanilla graph convolutional operation but also gradient information. Without introducing any additional parameters, CDGC can replace vanilla graph convolution in any existing Graph Convolutional Networks (GCNs). In addition, an accelerated version of the CDGC is developed which greatly improves the speed of training. Experiments on two popular large-scale datasets NTU RGB+D 60 & 120 have demonstrated the efficacy of the proposed CDGC. Code is available at https://github.com/iesymiao/CD-GCN.
Contrastive Proposal Extension with LSTM Network for Weakly Supervised Object Detection
Oct 16, 2021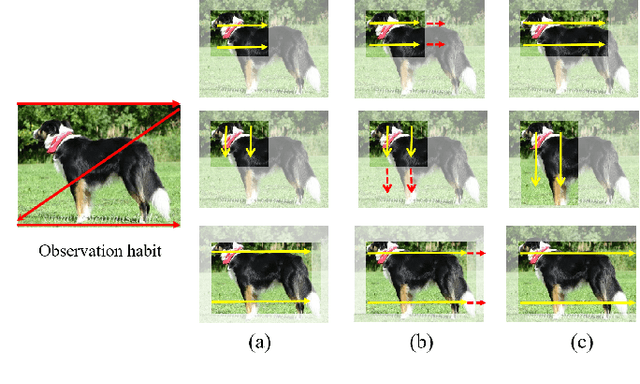

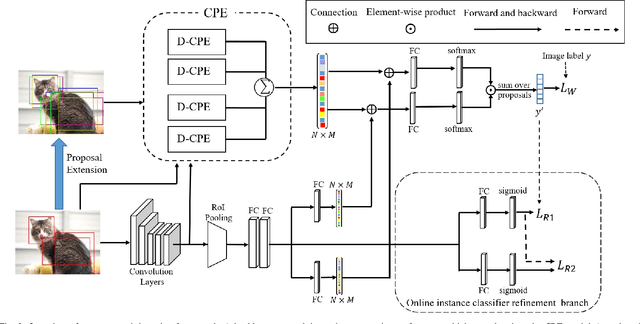
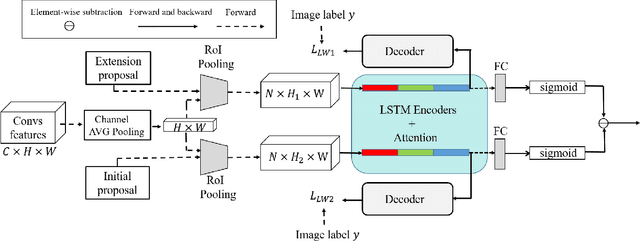
Weakly supervised object detection (WSOD) has attracted more and more attention since it only uses image-level labels and can save huge annotation costs. Most of the WSOD methods use Multiple Instance Learning (MIL) as their basic framework, which regard it as an instance classification problem. However, these methods based on MIL tends to converge only on the most discriminate regions of different instances, rather than their corresponding complete regions, that is, insufficient integrity. Inspired by the habit of observing things by the human, we propose a new method by comparing the initial proposals and the extension ones to optimize those initial proposals. Specifically, we propose one new strategy for WSOD by involving contrastive proposal extension (CPE), which consists of multiple directional contrastive proposal extensions (D-CPE), and each D-CPE contains encoders based on LSTM network and corresponding decoders. Firstly, the boundary of initial proposals in MIL is extended to different positions according to well-designed sequential order. Then, CPE compares the extended proposal and the initial proposal by extracting the feature semantics of them using the encoders, and calculates the integrity of the initial proposal to optimize the score of the initial proposal. These contrastive contextual semantics will guide the basic WSOD to suppress bad proposals and improve the scores of good ones. In addition, a simple two-stream network is designed as the decoder to constrain the temporal coding of LSTM and improve the performance of WSOD further. Experiments on PASCAL VOC 2007, VOC 2012 and MS-COCO datasets show that our method has achieved the state-of-the-art results.
Point Cloud Pre-training by Mixing and Disentangling
Sep 16, 2021
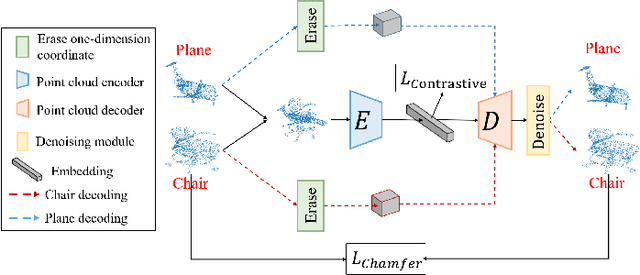
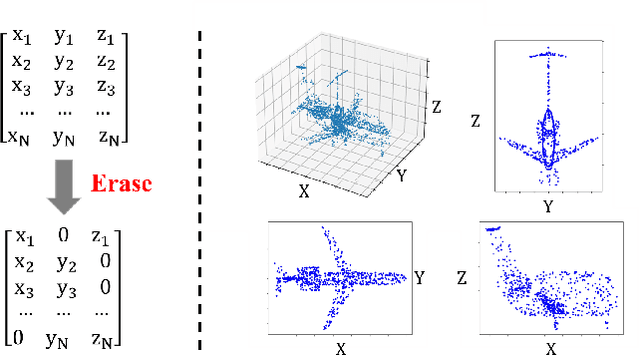
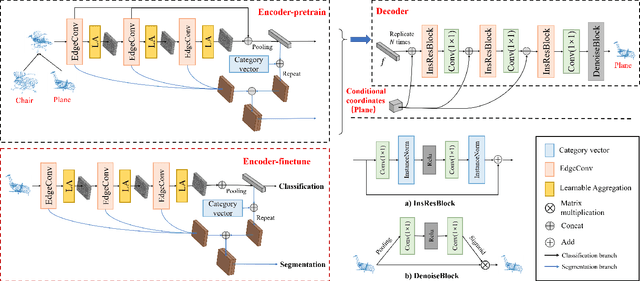
The annotation for large-scale point clouds is still time-consuming and unavailable for many real-world tasks. Point cloud pre-training is one potential solution for obtaining a scalable model for fast adaptation. Therefore, in this paper, we investigate a new self-supervised learning approach, called Mixing and Disentangling (MD), for point cloud pre-training. As the name implies, we explore how to separate the original point cloud from the mixed point cloud, and leverage this challenging task as a pretext optimization objective for model training. Considering the limited training data in the original dataset, which is much less than prevailing ImageNet, the mixing process can efficiently generate more high-quality samples. We build one baseline network to verify our intuition, which simply contains two modules, encoder and decoder. Given a mixed point cloud, the encoder is first pre-trained to extract the semantic embedding. Then an instance-adaptive decoder is harnessed to disentangle the point clouds according to the embedding. Albeit simple, the encoder is inherently able to capture the point cloud keypoints after training and can be fast adapted to downstream tasks including classification and segmentation by the pre-training and fine-tuning paradigm. Extensive experiments on two datasets show that the encoder + ours (MD) significantly surpasses that of the encoder trained from scratch and converges quickly. In ablation studies, we further study the effect of each component and discuss the advantages of the proposed self-supervised learning strategy. We hope this self-supervised learning attempt on point clouds can pave the way for reducing the deeply-learned model dependence on large-scale labeled data and saving a lot of annotation costs in the future.
Zero-sample surface defect detection and classification based on semantic feedback neural network
Jun 15, 2021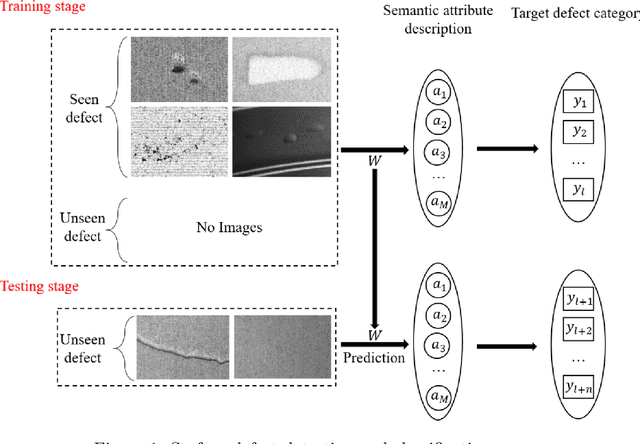



Defect detection and classification technology has changed from traditional artificial visual inspection to current intelligent automated inspection, but most of the current defect detection methods are training related detection models based on a data-driven approach, taking into account the difficulty of collecting some sample data in the industrial field. We apply zero-shot learning technology to the industrial field. Aiming at the problem of the existing "Latent Feature Guide Attribute Attention" (LFGAA) zero-shot image classification network, the output latent attributes and artificially defined attributes are different in the semantic space, which leads to the problem of model performance degradation, proposed an LGFAA network based on semantic feedback, and improved model performance by constructing semantic embedded modules and feedback mechanisms. At the same time, for the common domain shift problem in zero-shot learning, based on the idea of co-training algorithm using the difference information between different views of data to learn from each other, we propose an Ensemble Co-training algorithm, which adaptively reduces the prediction error in image tag embedding from multiple angles. Various experiments conducted on the zero-shot dataset and the cylinder liner dataset in the industrial field provide competitive results.
User-Guided Personalized Image Aesthetic Assessment based on Deep Reinforcement Learning
Jun 14, 2021
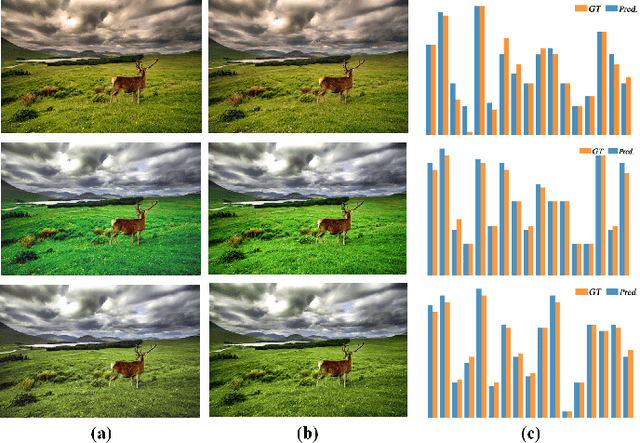
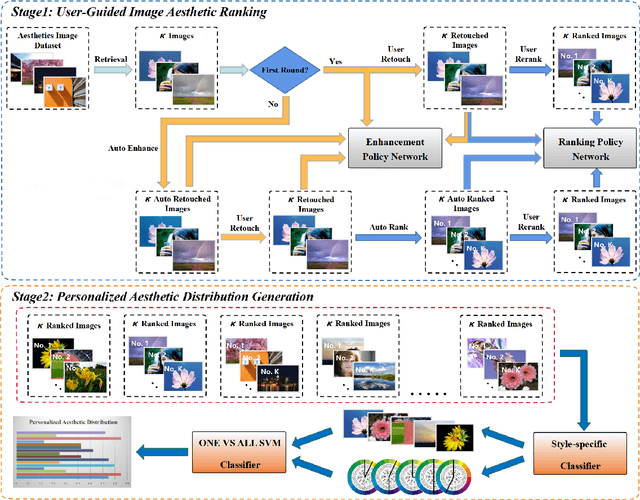
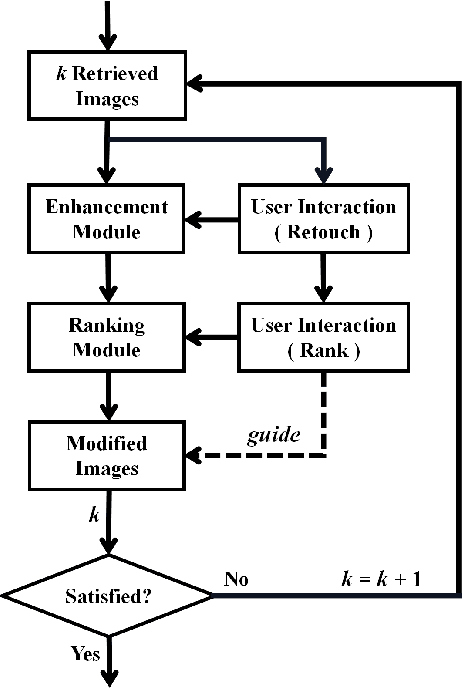
Personalized image aesthetic assessment (PIAA) has recently become a hot topic due to its usefulness in a wide variety of applications such as photography, film and television, e-commerce, fashion design and so on. This task is more seriously affected by subjective factors and samples provided by users. In order to acquire precise personalized aesthetic distribution by small amount of samples, we propose a novel user-guided personalized image aesthetic assessment framework. This framework leverages user interactions to retouch and rank images for aesthetic assessment based on deep reinforcement learning (DRL), and generates personalized aesthetic distribution that is more in line with the aesthetic preferences of different users. It mainly consists of two stages. In the first stage, personalized aesthetic ranking is generated by interactive image enhancement and manual ranking, meanwhile two policy networks will be trained. The images will be pushed to the user for manual retouching and simultaneously to the enhancement policy network. The enhancement network utilizes the manual retouching results as the optimization goals of DRL. After that, the ranking process performs the similar operations like the retouching mentioned before. These two networks will be trained iteratively and alternatively to help to complete the final personalized aesthetic assessment automatically. In the second stage, these modified images are labeled with aesthetic attributes by one style-specific classifier, and then the personalized aesthetic distribution is generated based on the multiple aesthetic attributes of these images, which conforms to the aesthetic preference of users better.
A self-adapting super-resolution structures framework for automatic design of GAN
Jun 10, 2021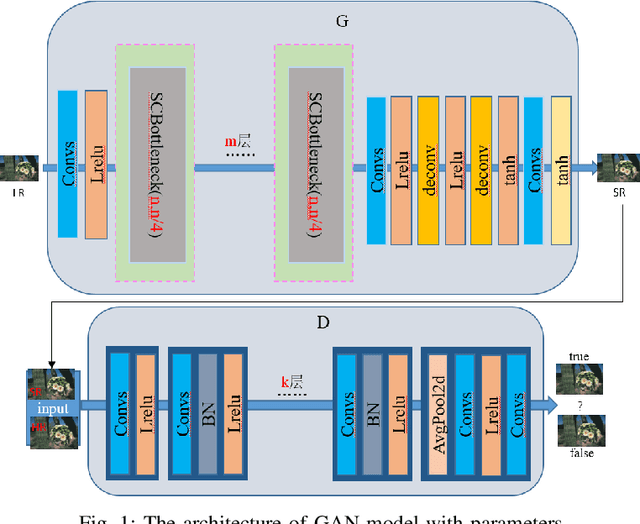
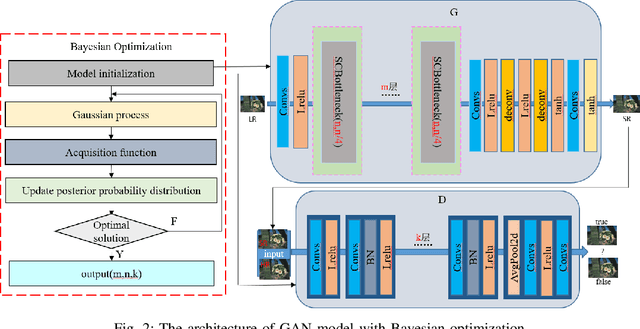
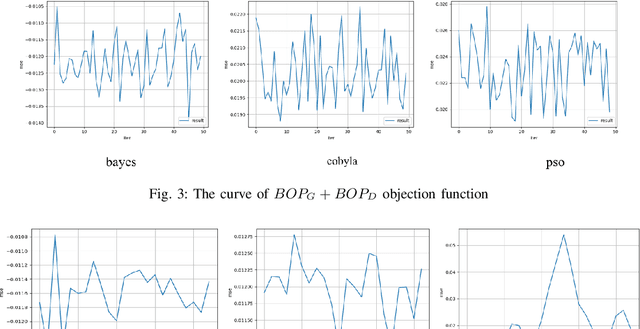
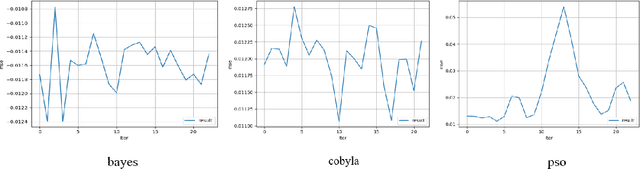
With the development of deep learning, the single super-resolution image reconstruction network models are becoming more and more complex. Small changes in hyperparameters of the models have a greater impact on model performance. In the existing works, experts have gradually explored a set of optimal model parameters based on empirical values or performing brute-force search. In this paper, we introduce a new super-resolution image reconstruction generative adversarial network framework, and a Bayesian optimization method used to optimizing the hyperparameters of the generator and discriminator. The generator is made by self-calibrated convolution, and discriminator is made by convolution lays. We have defined the hyperparameters such as the number of network layers and the number of neurons. Our method adopts Bayesian optimization as a optimization policy of GAN in our model. Not only can find the optimal hyperparameter solution automatically, but also can construct a super-resolution image reconstruction network, reducing the manual workload. Experiments show that Bayesian optimization can search the optimal solution earlier than the other two optimization algorithms.
Super-Resolution Image Reconstruction Based on Self-Calibrated Convolutional GAN
Jun 10, 2021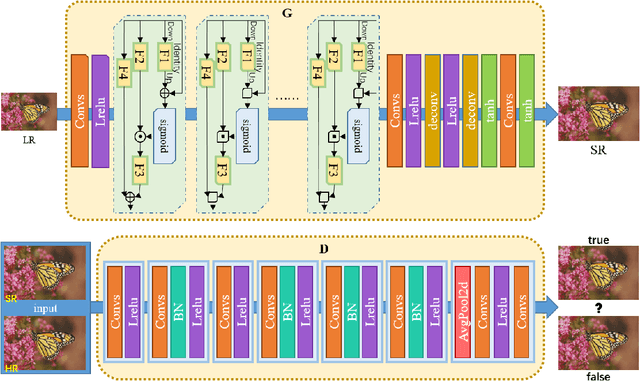
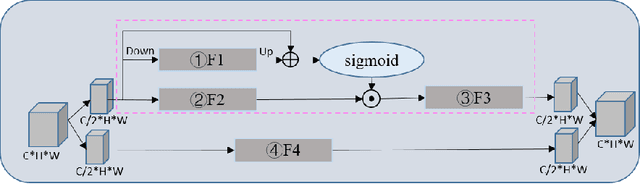

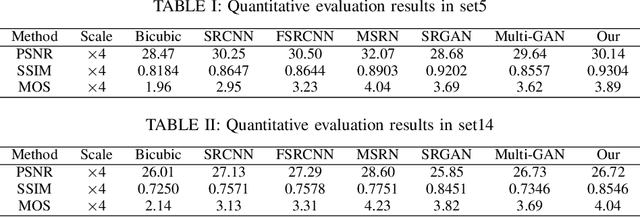
With the effective application of deep learning in computer vision, breakthroughs have been made in the research of super-resolution images reconstruction. However, many researches have pointed out that the insufficiency of the neural network extraction on image features may bring the deteriorating of newly reconstructed image. On the other hand, the generated pictures are sometimes too artificial because of over-smoothing. In order to solve the above problems, we propose a novel self-calibrated convolutional generative adversarial networks. The generator consists of feature extraction and image reconstruction. Feature extraction uses self-calibrated convolutions, which contains four portions, and each portion has specific functions. It can not only expand the range of receptive fields, but also obtain long-range spatial and inter-channel dependencies. Then image reconstruction is performed, and finally a super-resolution image is reconstructed. We have conducted thorough experiments on different datasets including set5, set14 and BSD100 under the SSIM evaluation method. The experimental results prove the effectiveness of the proposed network.
Antagonistic Crowd Simulation Model Integrating Emotion Contagion and Deep Reinforcement Learning
Apr 29, 2021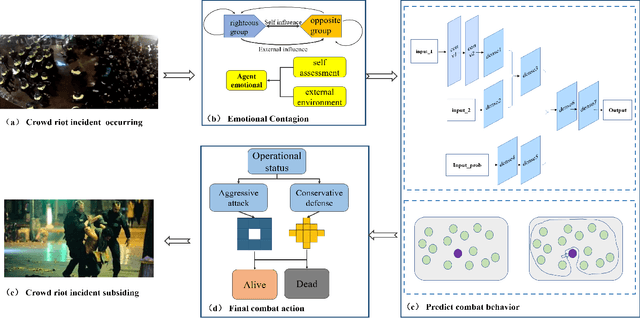

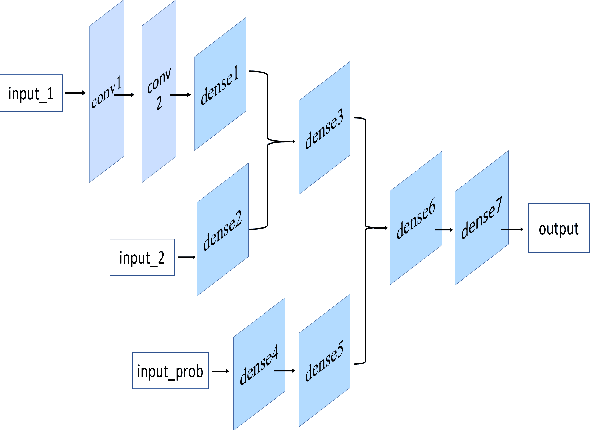

The antagonistic behavior of the crowd often exacerbates the seriousness of the situation in sudden riots, where the spreading of antagonistic emotion and behavioral decision making in the crowd play very important roles. However, the mechanism of complex emotion influencing decision making, especially in the environment of sudden confrontation, has not yet been explored clearly. In this paper, we propose one new antagonistic crowd simulation model by combing emotional contagion and deep reinforcement learning (ACSED). Firstly, we build a group emotional contagion model based on the improved SIS contagion disease model, and estimate the emotional state of the group at each time step during the simulation. Then, the tendency of group antagonistic behavior is modeled based on Deep Q Network (DQN), where the agent can learn the combat behavior autonomously, and leverages the mean field theory to quickly calculate the influence of other surrounding individuals on the central one. Finally, the rationality of the predicted behaviors by the DQN is further analyzed in combination with group emotion, and the final combat behavior of the agent is determined. The method proposed in this paper is verified through several different settings of experiments. The results prove that emotions have a vital impact on the group combat, and positive emotional states are more conducive to combat. Moreover, by comparing the simulation results with real scenes, the feasibility of the method is further verified, which can provide good reference for formulating battle plans and improving the winning rate of righteous groups battles in a variety of situations.
Lottery Jackpots Exist in Pre-trained Models
Apr 18, 2021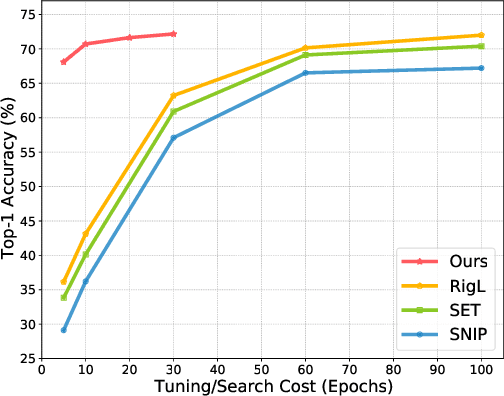
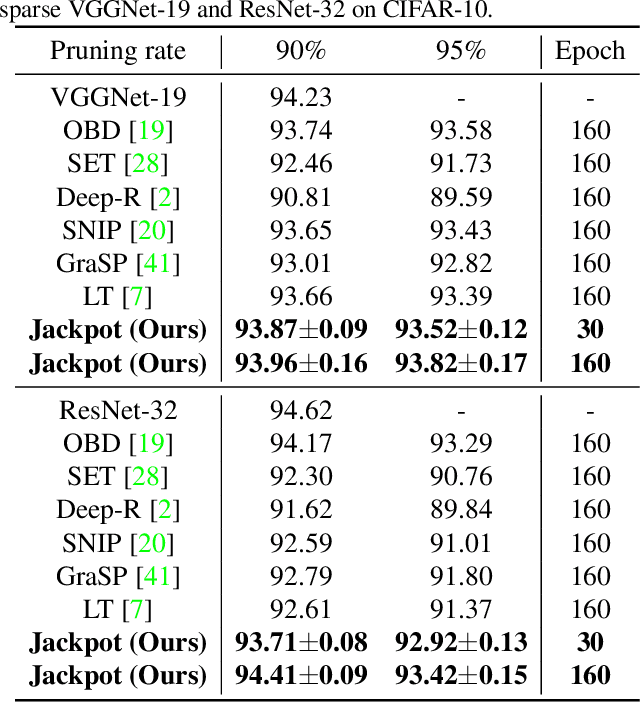
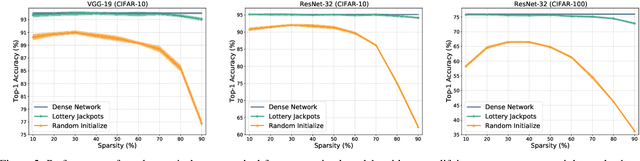
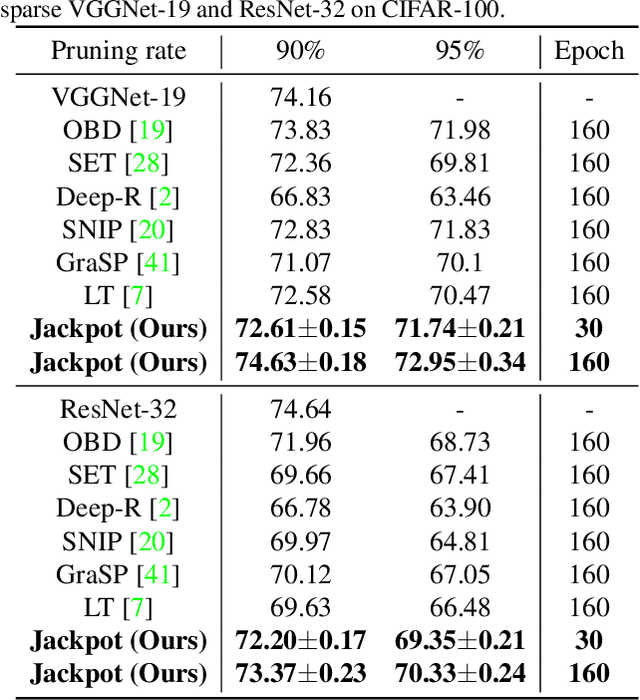
Network pruning is an effective approach to reduce network complexity without performance compromise. Existing studies achieve the sparsity of neural networks via time-consuming weight tuning or complex search on networks with expanded width, which greatly limits the applications of network pruning. In this paper, we show that high-performing and sparse sub-networks without the involvement of weight tuning, termed "lottery jackpots", exist in pre-trained models with unexpanded width. For example, we obtain a lottery jackpot that has only 10% parameters and still reaches the performance of the original dense VGGNet-19 without any modifications on the pre-trained weights. Furthermore, we observe that the sparse masks derived from many existing pruning criteria have a high overlap with the searched mask of our lottery jackpot, among which, the magnitude-based pruning results in the most similar mask with ours. Based on this insight, we initialize our sparse mask using the magnitude pruning, resulting in at least 3x cost reduction on the lottery jackpot search while achieves comparable or even better performance. Specifically, our magnitude-based lottery jackpot removes 90% weights in the ResNet-50, while easily obtains more than 70% top-1 accuracy using only 10 searching epochs on ImageNet.