 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLaVA-MR: Large Language-and-Vision Assistant for Video Moment Retrieval
Nov 21, 2024



Multimodal Large Language Models (MLLMs) are widely used for visual perception, understanding, and reasoning. However, long video processing and precise moment retrieval remain challenging due to LLMs' limited context size and coarse frame extraction. We propose the Large Language-and-Vision Assistant for Moment Retrieval (LLaVA-MR), which enables accurate moment retrieval and contextual grounding in videos using MLLMs. LLaVA-MR combines Dense Frame and Time Encoding (DFTE) for spatial-temporal feature extraction, Informative Frame Selection (IFS) for capturing brief visual and motion patterns, and Dynamic Token Compression (DTC) to manage LLM context limitations. Evaluations on benchmarks like Charades-STA and QVHighlights demonstrate that LLaVA-MR outperforms 11 state-of-the-art methods, achieving an improvement of 1.82% in R1@0.5 and 1.29% in mAP@0.5 on the QVHighlights dataset. Our implementation will be open-sourced upon acceptance.
Learning with Instance-Dependent Noisy Labels by Anchor Hallucination and Hard Sample Label Correction
Jul 10, 2024



Learning from noisy-labeled data is crucial for real-world applications. Traditional Noisy-Label Learning (NLL) methods categorize training data into clean and noisy sets based on the loss distribution of training samples. However, they often neglect that clean samples, especially those with intricate visual patterns, may also yield substantial losses. This oversight is particularly significant in datasets with Instance-Dependent Noise (IDN), where mislabeling probabilities correlate with visual appearance. Our approach explicitly distinguishes between clean vs.noisy and easy vs. hard samples. We identify training samples with small losses, assuming they have simple patterns and correct labels. Utilizing these easy samples, we hallucinate multiple anchors to select hard samples for label correction. Corrected hard samples, along with the easy samples, are used as labeled data in subsequent semi-supervised training. Experiments on synthetic and real-world IDN datasets demonstrate the superior performance of our method over other state-of-the-art NLL methods.
The 8th AI City Challenge
Apr 15, 2024



The eighth AI City Challenge highlighted the convergence of computer vision and artificial intelligence in areas like retail, warehouse settings, and Intelligent Traffic Systems (ITS), presenting significant research opportunities. The 2024 edition featured five tracks, attracting unprecedented interest from 726 teams in 47 countries and regions. Track 1 dealt with multi-target multi-camera (MTMC) people tracking, highlighting significant enhancements in camera count, character number, 3D annotation, and camera matrices, alongside new rules for 3D tracking and online tracking algorithm encouragement. Track 2 introduced dense video captioning for traffic safety, focusing on pedestrian accidents using multi-camera feeds to improve insights for insurance and prevention. Track 3 required teams to classify driver actions in a naturalistic driving analysis. Track 4 explored fish-eye camera analytics using the FishEye8K dataset. Track 5 focused on motorcycle helmet rule violation detection. The challenge utilized two leaderboards to showcase methods, with participants setting new benchmarks, some surpassing existing state-of-the-art achievements.
Addressing Long-Tail Noisy Label Learning Problems: a Two-Stage Solution with Label Refurbishment Considering Label Rarity
Mar 04, 2024



Real-world datasets commonly exhibit noisy labels and class imbalance, such as long-tailed distributions. While previous research addresses this issue by differentiating noisy and clean samples, reliance on information from predictions based on noisy long-tailed data introduces potential errors. To overcome the limitations of prior works, we introduce an effective two-stage approach by combining soft-label refurbishing with multi-expert ensemble learning. In the first stage of robust soft label refurbishing, we acquire unbiased features through contrastive learning, making preliminary predictions using a classifier trained with a carefully designed BAlanced Noise-tolerant Cross-entropy (BANC) loss. In the second stage, our label refurbishment method is applied to obtain soft labels for multi-expert ensemble learning, providing a principled solution to the long-tail noisy label problem. Experiments conducted across multiple benchmarks validate the superiority of our approach, Label Refurbishment considering Label Rarity (LR^2), achieving remarkable accuracies of 94.19% and 77.05% on simulated noisy CIFAR-10 and CIFAR-100 long-tail datasets, as well as 77.74% and 81.40% on real-noise long-tail datasets, Food-101N and Animal-10N, surpassing existing state-of-the-art methods.
A Comprehensive Review of Machine Learning Advances on Data Change: A Cross-Field Perspective
Feb 20, 2024



Recent artificial intelligence (AI) technologies show remarkable evolution in various academic fields and industries. However, in the real world, dynamic data lead to principal challenges for deploying AI models. An unexpected data change brings about severe performance degradation in AI models. We identify two major related research fields, domain shift and concept drift according to the setting of the data change. Although these two popular research fields aim to solve distribution shift and non-stationary data stream problems, the underlying properties remain similar which also encourages similar technical approaches. In this review, we regroup domain shift and concept drift into a single research problem, namely the data change problem, with a systematic overview of state-of-the-art methods in the two research fields. We propose a three-phase problem categorization scheme to link the key ideas in the two technical fields. We thus provide a novel scope for researchers to explore contemporary technical strategies, learn industrial applications, and identify future directions for addressing data change challenges.
Improving Limited Supervised Foot Ulcer Segmentation Using Cross-Domain Augmentation
Jan 16, 2024Diabetic foot ulcers pose health risks, including higher morbidity, mortality, and amputation rates. Monitoring wound areas is crucial for proper care, but manual segmentation is subjective due to complex wound features and background variation. Expert annotations are costly and time-intensive, thus hampering large dataset creation. Existing segmentation models relying on extensive annotations are impractical in real-world scenarios with limited annotated data. In this paper, we propose a cross-domain augmentation method named TransMix that combines Augmented Global Pre-training AGP and Localized CutMix Fine-tuning LCF to enrich wound segmentation data for model learning. TransMix can effectively improve the foot ulcer segmentation model training by leveraging other dermatology datasets not on ulcer skins or wounds. AGP effectively increases the overall image variability, while LCF increases the diversity of wound regions. Experimental results show that TransMix increases the variability of wound regions and substantially improves the Dice score for models trained with only 40 annotated images under various proportions.
Scale-Aware Crowd Count Network with Annotation Error Correction
Dec 28, 2023Traditional crowd counting networks suffer from information loss when feature maps are downsized through pooling layers, leading to inaccuracies in counting crowds at a distance. Existing methods often assume correct annotations during training, disregarding the impact of noisy annotations, especially in crowded scenes. Furthermore, the use of a fixed Gaussian kernel fails to account for the varying pixel distribution with respect to the camera distance. To overcome these challenges, we propose a Scale-Aware Crowd Counting Network (SACC-Net) that introduces a ``scale-aware'' architecture with error-correcting capabilities of noisy annotations. For the first time, we {\bf simultaneously} model labeling errors (mean) and scale variations (variance) by spatially-varying Gaussian distributions to produce fine-grained heat maps for crowd counting. Furthermore, the proposed adaptive Gaussian kernel variance enables the model to learn dynamically with a low-rank approximation, leading to improved convergence efficiency with comparable accuracy. The performance of SACC-Net is extensively evaluated on four public datasets: UCF-QNRF, UCF CC 50, NWPU, and ShanghaiTech A-B. Experimental results demonstrate that SACC-Net outperforms all state-of-the-art methods, validating its effectiveness in achieving superior crowd counting accuracy.
A New Benchmark and Model for Challenging Image Manipulation Detection
Nov 23, 2023



The ability to detect manipulation in multimedia data is vital in digital forensics. Existing Image Manipulation Detection (IMD) methods are mainly based on detecting anomalous features arisen from image editing or double compression artifacts. All existing IMD techniques encounter challenges when it comes to detecting small tampered regions from a large image. Moreover, compression-based IMD approaches face difficulties in cases of double compression of identical quality factors. To investigate the State-of-The-Art (SoTA) IMD methods in those challenging conditions, we introduce a new Challenging Image Manipulation Detection (CIMD) benchmark dataset, which consists of two subsets, for evaluating editing-based and compression-based IMD methods, respectively. The dataset images were manually taken and tampered with high-quality annotations. In addition, we propose a new two-branch network model based on HRNet that can better detect both the image-editing and compression artifacts in those challenging conditions. Extensive experiments on the CIMD benchmark show that our model significantly outperforms SoTA IMD methods on CIMD.
MixNet: Toward Accurate Detection of Challenging Scene Text in the Wild
Aug 28, 2023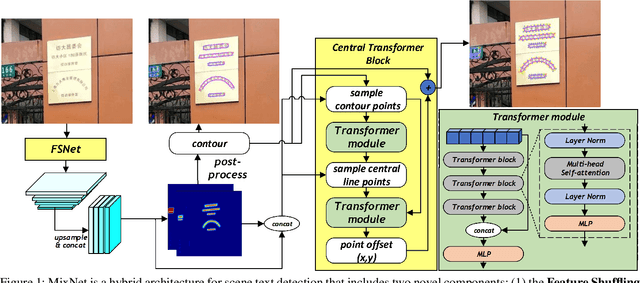
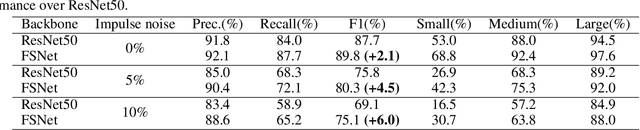
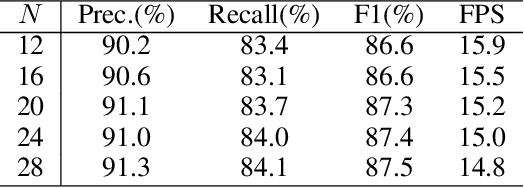

Detecting small scene text instances in the wild is particularly challenging, where the influence of irregular positions and nonideal lighting often leads to detection errors. We present MixNet, a hybrid architecture that combines the strengths of CNNs and Transformers, capable of accurately detecting small text from challenging natural scenes, regardless of the orientations, styles, and lighting conditions. MixNet incorporates two key modules: (1) the Feature Shuffle Network (FSNet) to serve as the backbone and (2) the Central Transformer Block (CTBlock) to exploit the 1D manifold constraint of the scene text. We first introduce a novel feature shuffling strategy in FSNet to facilitate the exchange of features across multiple scales, generating high-resolution features superior to popular ResNet and HRNet. The FSNet backbone has achieved significant improvements over many existing text detection methods, including PAN, DB, and FAST. Then we design a complementary CTBlock to leverage center line based features similar to the medial axis of text regions and show that it can outperform contour-based approaches in challenging cases when small scene texts appear closely. Extensive experimental results show that MixNet, which mixes FSNet with CTBlock, achieves state-of-the-art results on multiple scene text detection datasets.
FishEye8K: A Benchmark and Dataset for Fisheye Camera Object Detection
Jun 06, 2023With the advance of AI, road object detection has been a prominent topic in computer vision, mostly using perspective cameras. Fisheye lens provides omnidirectional wide coverage for using fewer cameras to monitor road intersections, however with view distortions. To our knowledge, there is no existing open dataset prepared for traffic surveillance on fisheye cameras. This paper introduces an open FishEye8K benchmark dataset for road object detection tasks, which comprises 157K bounding boxes across five classes (Pedestrian, Bike, Car, Bus, and Truck). In addition, we present benchmark results of State-of-The-Art (SoTA) models, including variations of YOLOv5, YOLOR, YOLO7, and YOLOv8. The dataset comprises 8,000 images recorded in 22 videos using 18 fisheye cameras for traffic monitoring in Hsinchu, Taiwan, at resolutions of 1080$\times$1080 and 1280$\times$1280. The data annotation and validation process were arduous and time-consuming, due to the ultra-wide panoramic and hemispherical fisheye camera images with large distortion and numerous road participants, particularly people riding scooters. To avoid bias, frames from a particular camera were assigned to either the training or test sets, maintaining a ratio of about 70:30 for both the number of images and bounding boxes in each class. Experimental results show that YOLOv8 and YOLOR outperform on input sizes 640$\times$640 and 1280$\times$1280, respectively. The dataset will be available on GitHub with PASCAL VOC, MS COCO, and YOLO annotation formats. The FishEye8K benchmark will provide significant contributions to the fisheye video analytics and smart city applications.