 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDQ-BART: Efficient Sequence-to-Sequence Model via Joint Distillation and Quantization
Mar 21, 2022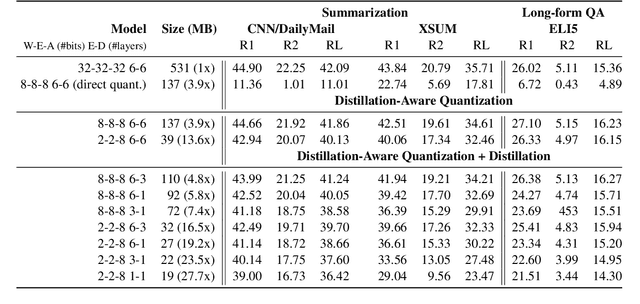
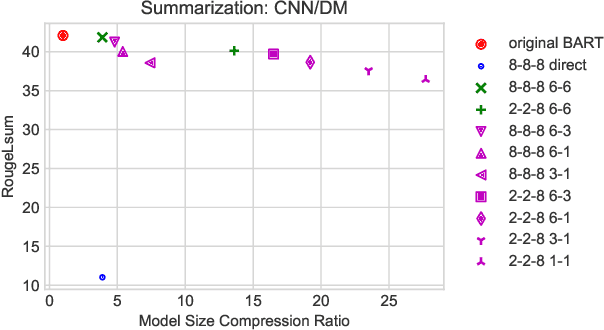
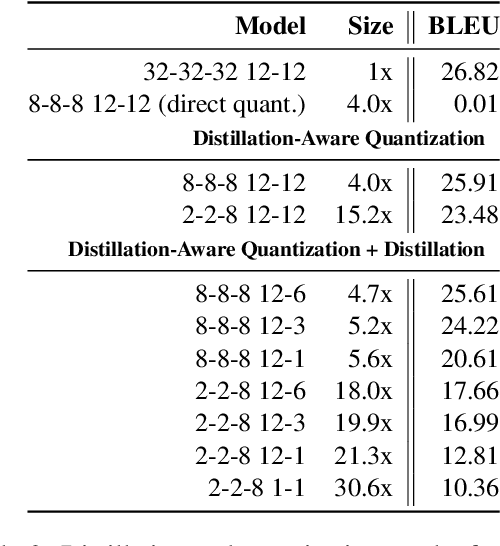
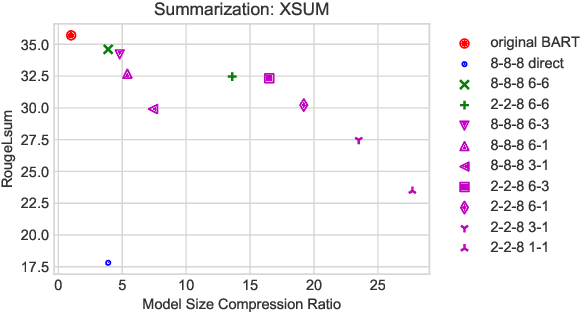
Large-scale pre-trained sequence-to-sequence models like BART and T5 achieve state-of-the-art performance on many generative NLP tasks. However, such models pose a great challenge in resource-constrained scenarios owing to their large memory requirements and high latency. To alleviate this issue, we propose to jointly distill and quantize the model, where knowledge is transferred from the full-precision teacher model to the quantized and distilled low-precision student model. Empirical analyses show that, despite the challenging nature of generative tasks, we were able to achieve a 16.5x model footprint compression ratio with little performance drop relative to the full-precision counterparts on multiple summarization and QA datasets. We further pushed the limit of compression ratio to 27.7x and presented the performance-efficiency trade-off for generative tasks using pre-trained models. To the best of our knowledge, this is the first work aiming to effectively distill and quantize sequence-to-sequence pre-trained models for language generation tasks.
New Benchmark for Household Garbage Image Recognition
Feb 24, 2022
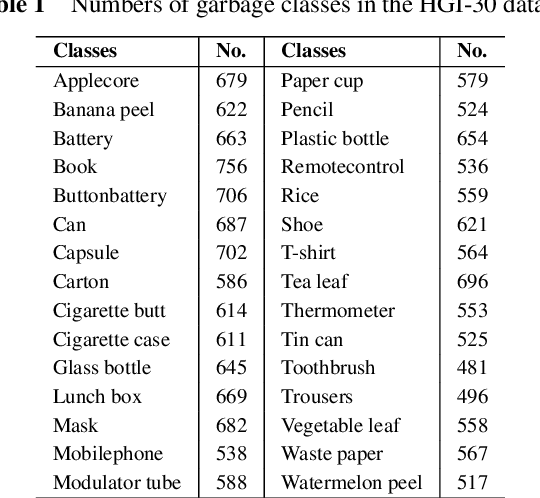

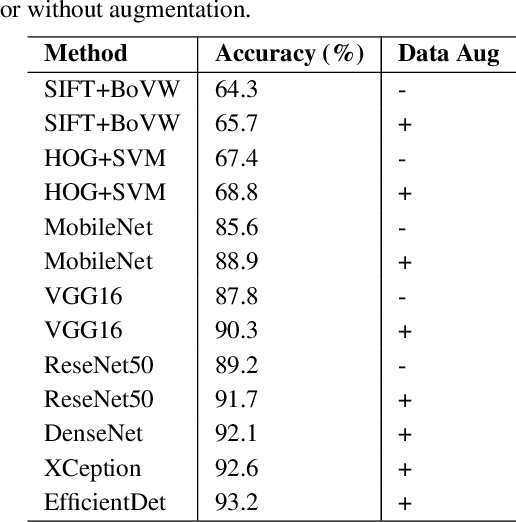
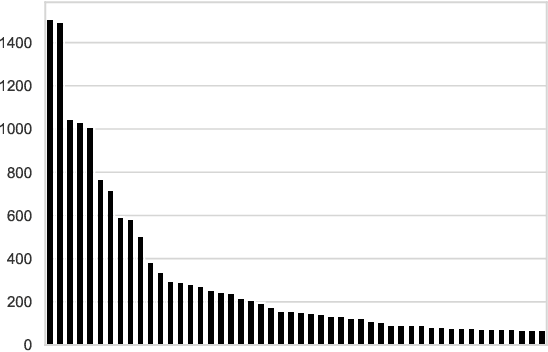
Household garbage images are usually faced with complex backgrounds, variable illuminations, diverse angles, and changeable shapes, which bring a great difficulty in garbage image classification. Due to the ability to discover problem-specific features, deep learning and especially convolutional neural networks (CNNs) have been successfully and widely used for image representation learning. However, available and stable household garbage datasets are insufficient, which seriously limits the development of research and application. Besides, the state of the art in the field of garbage image classification is not entirely clear. To solve this problem, in this study, we built a new open benchmark dataset for household garbage image classification by simulating different lightings, backgrounds, angles, and shapes. This dataset is named 30 Classes of Household Garbage Images (HGI-30), which contains 18,000 images of 30 household garbage classes. The publicly available HGI-30 dataset allows researchers to develop accurate and robust methods for household garbage recognition. We also conducted experiments and performance analysis of the state-of-the-art deep CNN methods on HGI-30, which serves as baseline results on this benchmark.
Generating Synthetic Data for Task-Oriented Semantic Parsing with Hierarchical Representations
Nov 03, 2020
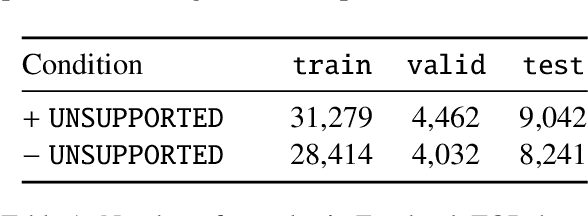
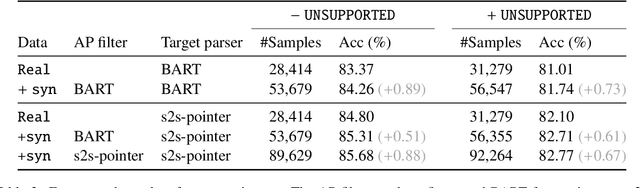
Modern conversational AI systems support natural language understanding for a wide variety of capabilities. While a majority of these tasks can be accomplished using a simple and flat representation of intents and slots, more sophisticated capabilities require complex hierarchical representations supported by semantic parsing. State-of-the-art semantic parsers are trained using supervised learning with data labeled according to a hierarchical schema which might be costly to obtain or not readily available for a new domain. In this work, we explore the possibility of generating synthetic data for neural semantic parsing using a pretrained denoising sequence-to-sequence model (i.e., BART). Specifically, we first extract masked templates from the existing labeled utterances, and then fine-tune BART to generate synthetic utterances conditioning on the extracted templates. Finally, we use an auxiliary parser (AP) to filter the generated utterances. The AP guarantees the quality of the generated data. We show the potential of our approach when evaluating on the Facebook TOP dataset for navigation domain.
Skeleton Based Action Recognition using a Stacked Denoising Autoencoder with Constraints of Privileged Information
Mar 12, 2020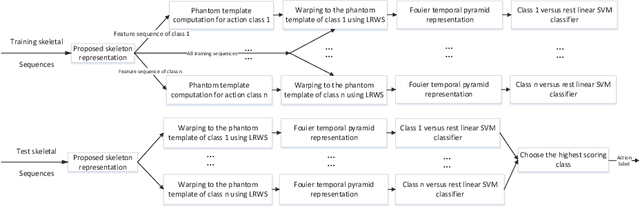
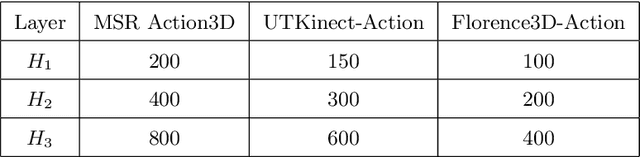
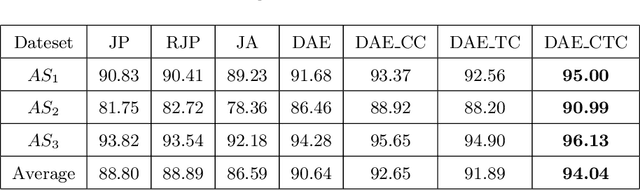
Recently, with the availability of cost-effective depth cameras coupled with real-time skeleton estimation, the interest in skeleton-based human action recognition is renewed. Most of the existing skeletal representation approaches use either the joint location or the dynamics model. Differing from the previous studies, we propose a new method called Denoising Autoencoder with Temporal and Categorical Constraints (DAE_CTC)} to study the skeletal representation in a view of skeleton reconstruction. Based on the concept of learning under privileged information, we integrate action categories and temporal coordinates into a stacked denoising autoencoder in the training phase, to preserve category and temporal feature, while learning the hidden representation from a skeleton. Thus, we are able to improve the discriminative validity of the hidden representation. In order to mitigate the variation resulting from temporary misalignment, a new method of temporal registration, called Locally-Warped Sequence Registration (LWSR), is proposed for registering the sequences of inter- and intra-class actions. We finally represent the sequences using a Fourier Temporal Pyramid (FTP) representation and perform classification using a combination of LWSR registration, FTP representation, and a linear Support Vector Machine (SVM). The experimental results on three action data sets, namely MSR-Action3D, UTKinect-Action, and Florence3D-Action, show that our proposal performs better than many existing methods and comparably to the state of the art.
Out-of-Domain Detection for Low-Resource Text Classification Tasks
Aug 31, 2019
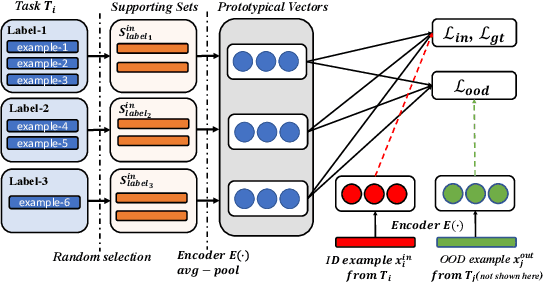
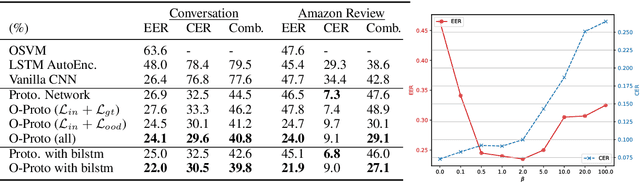
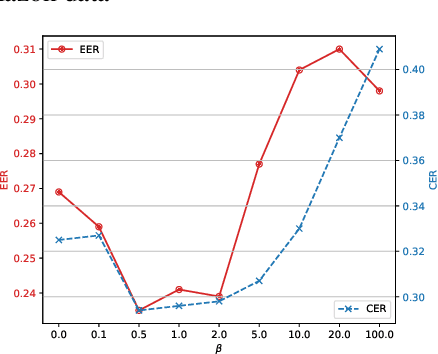
Out-of-domain (OOD) detection for low-resource text classification is a realistic but understudied task. The goal is to detect the OOD cases with limited in-domain (ID) training data, since we observe that training data is often insufficient in machine learning applications. In this work, we propose an OOD-resistant Prototypical Network to tackle this zero-shot OOD detection and few-shot ID classification task. Evaluation on real-world datasets show that the proposed solution outperforms state-of-the-art methods in zero-shot OOD detection task, while maintaining a competitive performance on ID classification task.
Slack Channels Ecology in Enterprises: How Employees Collaborate Through Group Chat
Jun 04, 2019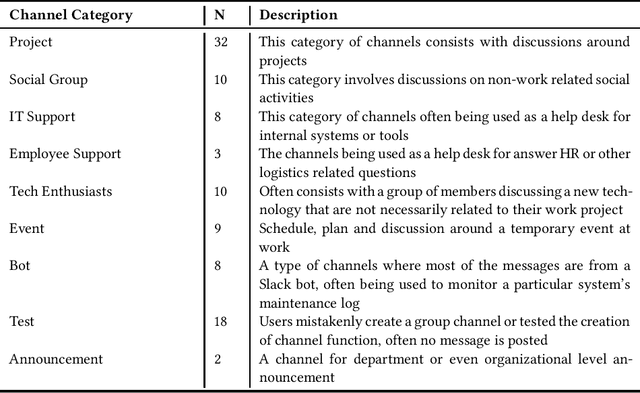
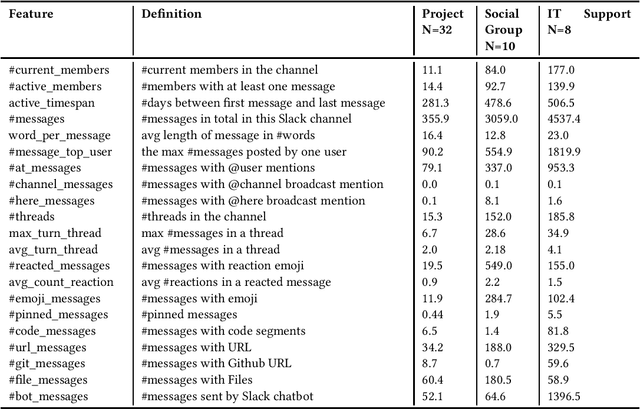
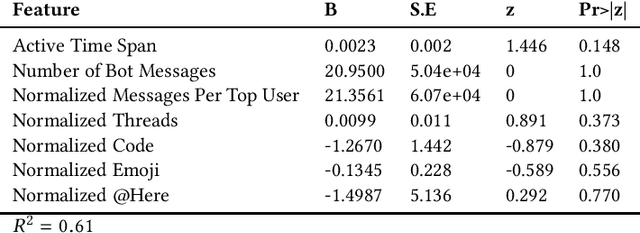
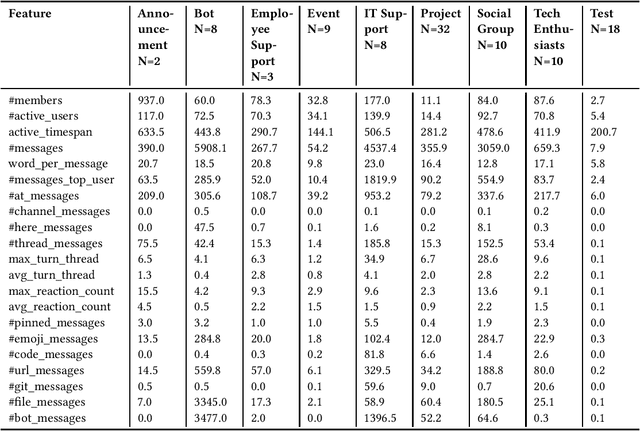
Despite the long history of studying instant messaging usage in organizations, we know very little about how today's people participate in group chat channels and interact with others. In this short note, we aim to update the existing knowledge on how group chat is used in the context of today's organizations. We have the privilege of collecting a total of 4300 publicly available group chat channels in Slack from an R\&D department in a multinational IT company. Through qualitative coding of 100 channels, we identified 9 channel categories such as project based channels and event channels. We further defined a feature metric with 21 features to depict the group communication style for these group chat channels, with which we successfully trained a machine learning model that can automatically classify a given group channel into one of the 9 categories. In addition, we illustrated how these communication metrics could be used for analyzing teams' collaboration activities. We focused on 117 project teams as we have their performance data, and further collected 54 out of the 117 teams' Slack group data and generated the communication style metrics for each of them. With these data, we are able to build a regression model to reveal the relationship between these group communication styles and one indicator of the project team performance.
Extracting Multiple-Relations in One-Pass with Pre-Trained Transformers
Feb 04, 2019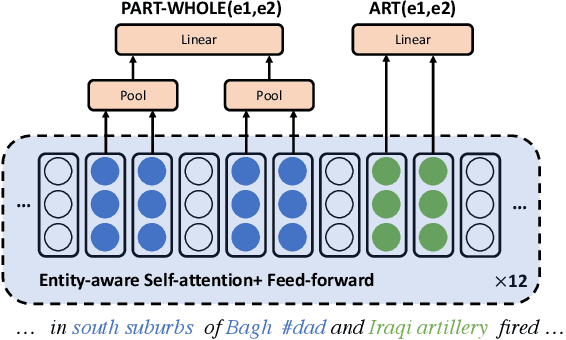
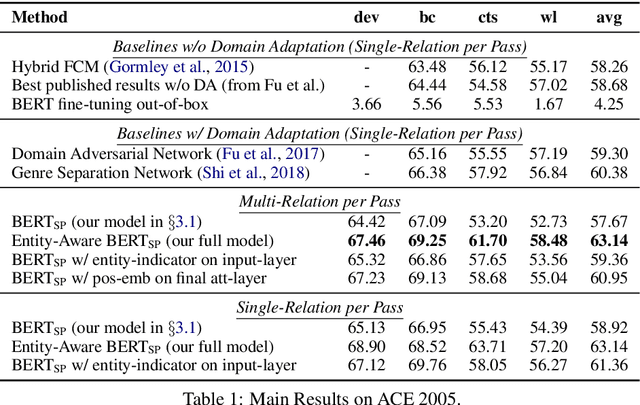

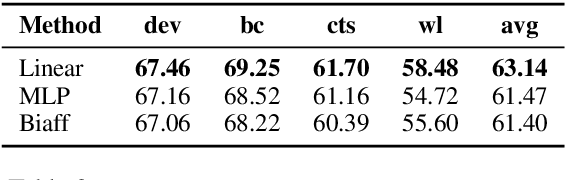
Most approaches to extraction multiple relations from a paragraph require multiple passes over the paragraph. In practice, multiple passes are computationally expensive and this makes difficult to scale to longer paragraphs and larger text corpora. In this work, we focus on the task of multiple relation extraction by encoding the paragraph only once (one-pass). We build our solution on the pre-trained self-attentive (Transformer) models, where we first add a structured prediction layer to handle extraction between multiple entity pairs, then enhance the paragraph embedding to capture multiple relational information associated with each entity with an entity-aware attention technique. We show that our approach is not only scalable but can also perform state-of-the-art on the standard benchmark ACE 2005.
LSTM-based Deep Learning Models for Non-factoid Answer Selection
Mar 28, 2016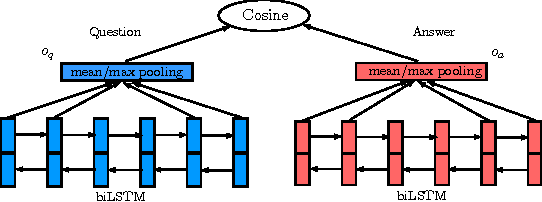
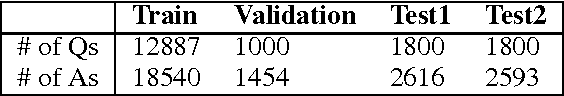

In this paper, we apply a general deep learning (DL) framework for the answer selection task, which does not depend on manually defined features or linguistic tools. The basic framework is to build the embeddings of questions and answers based on bidirectional long short-term memory (biLSTM) models, and measure their closeness by cosine similarity. We further extend this basic model in two directions. One direction is to define a more composite representation for questions and answers by combining convolutional neural network with the basic framework. The other direction is to utilize a simple but efficient attention mechanism in order to generate the answer representation according to the question context. Several variations of models are provided. The models are examined by two datasets, including TREC-QA and InsuranceQA. Experimental results demonstrate that the proposed models substantially outperform several strong baselines.
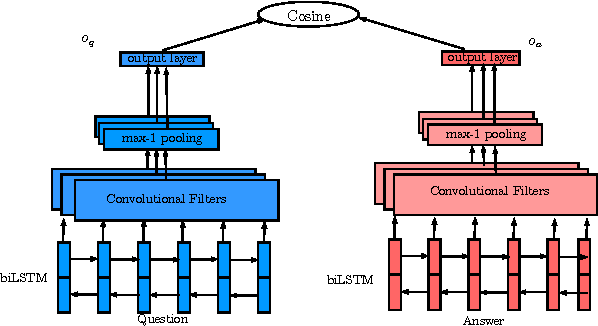
Attentive Pooling Networks
Feb 11, 2016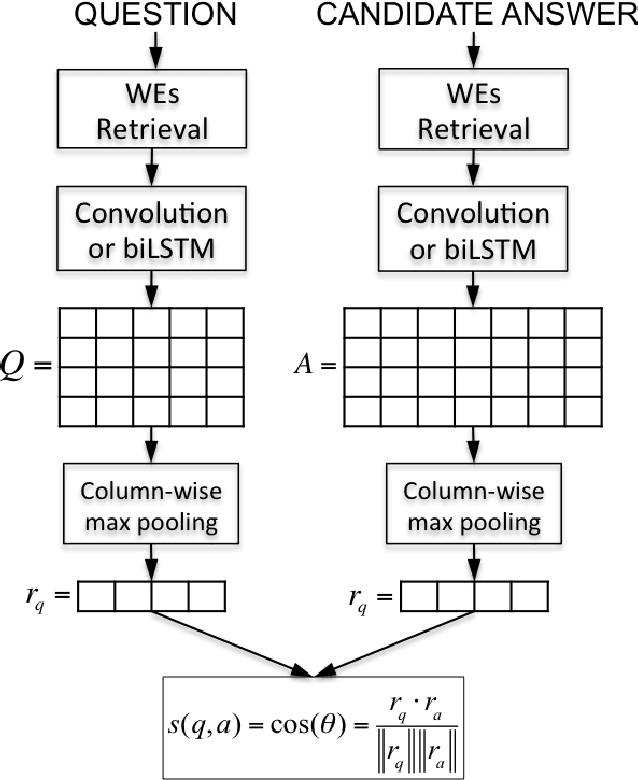

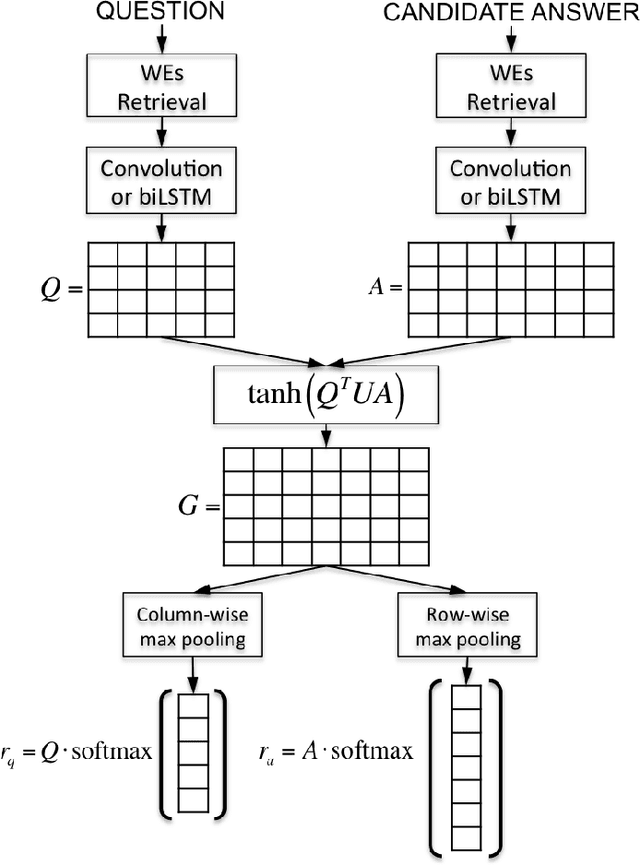
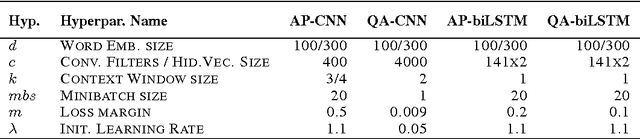
In this work, we propose Attentive Pooling (AP), a two-way attention mechanism for discriminative model training. In the context of pair-wise ranking or classification with neural networks, AP enables the pooling layer to be aware of the current input pair, in a way that information from the two input items can directly influence the computation of each other's representations. Along with such representations of the paired inputs, AP jointly learns a similarity measure over projected segments (e.g. trigrams) of the pair, and subsequently, derives the corresponding attention vector for each input to guide the pooling. Our two-way attention mechanism is a general framework independent of the underlying representation learning, and it has been applied to both convolutional neural networks (CNNs) and recurrent neural networks (RNNs) in our studies. The empirical results, from three very different benchmark tasks of question answering/answer selection, demonstrate that our proposed models outperform a variety of strong baselines and achieve state-of-the-art performance in all the benchmarks.