 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeState-of-the-art generalisation research in NLP: a taxonomy and review
Oct 10, 2022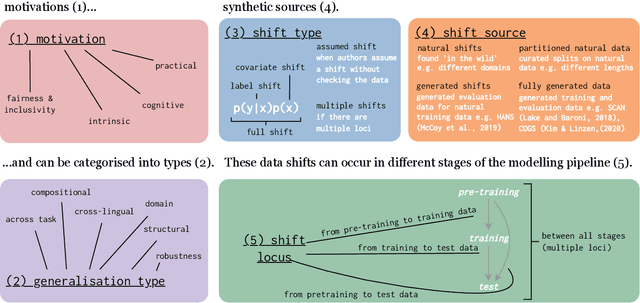
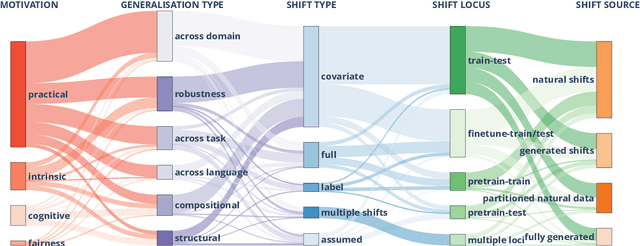
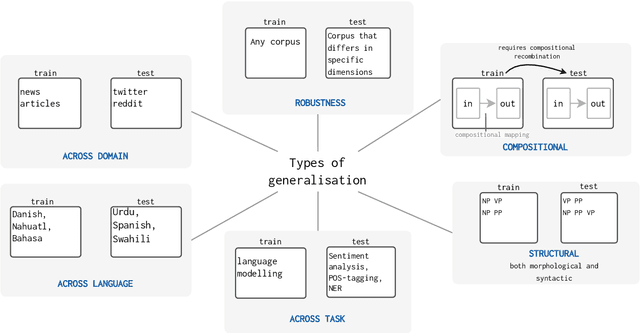

The ability to generalise well is one of the primary desiderata of natural language processing (NLP). Yet, what `good generalisation' entails and how it should be evaluated is not well understood, nor are there any common standards to evaluate it. In this paper, we aim to lay the ground-work to improve both of these issues. We present a taxonomy for characterising and understanding generalisation research in NLP, we use that taxonomy to present a comprehensive map of published generalisation studies, and we make recommendations for which areas might deserve attention in the future. Our taxonomy is based on an extensive literature review of generalisation research, and contains five axes along which studies can differ: their main motivation, the type of generalisation they aim to solve, the type of data shift they consider, the source by which this data shift is obtained, and the locus of the shift within the modelling pipeline. We use our taxonomy to classify over 400 previous papers that test generalisation, for a total of more than 600 individual experiments. Considering the results of this review, we present an in-depth analysis of the current state of generalisation research in NLP, and make recommendations for the future. Along with this paper, we release a webpage where the results of our review can be dynamically explored, and which we intend to up-date as new NLP generalisation studies are published. With this work, we aim to make steps towards making state-of-the-art generalisation testing the new status quo in NLP.
Prompting ELECTRA: Few-Shot Learning with Discriminative Pre-Trained Models
Jun 08, 2022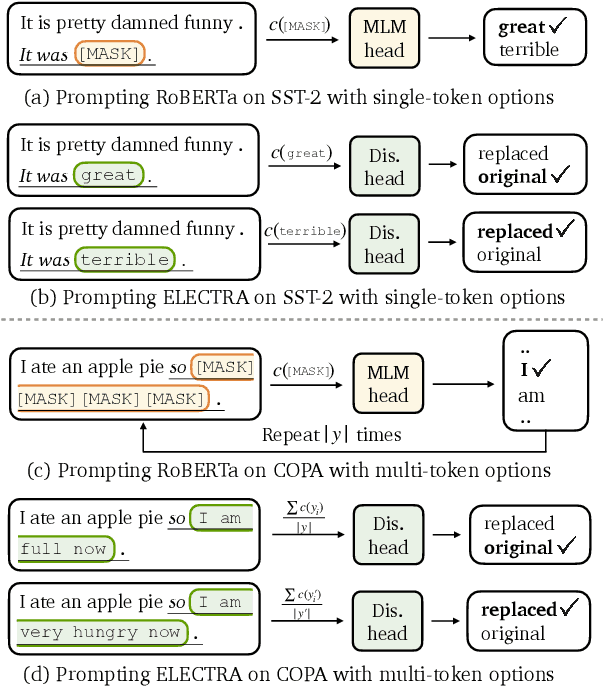
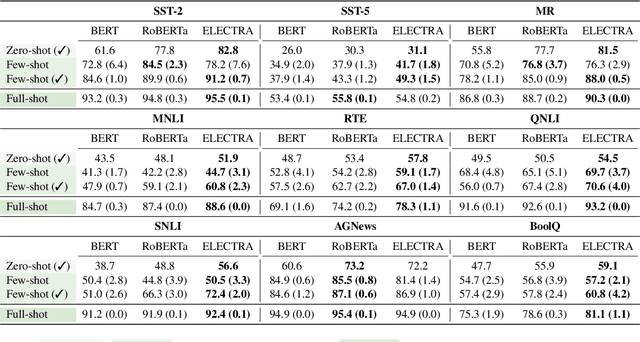
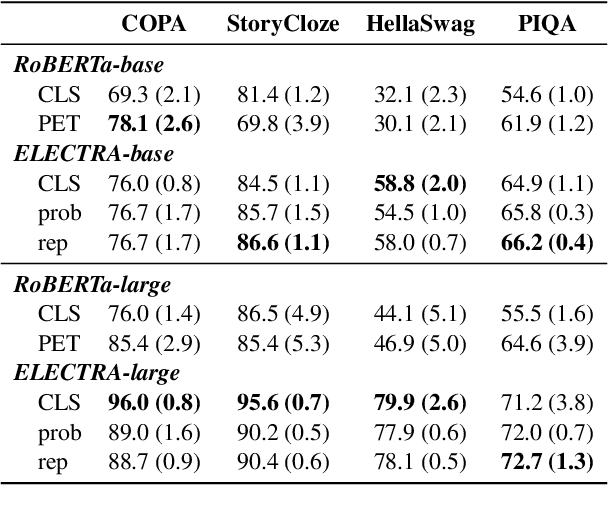
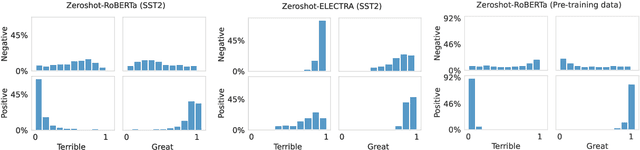
Pre-trained masked language models successfully perform few-shot learning by formulating downstream tasks as text infilling. However, as a strong alternative in full-shot settings, discriminative pre-trained models like ELECTRA do not fit into the paradigm. In this work, we adapt prompt-based few-shot learning to ELECTRA and show that it outperforms masked language models in a wide range of tasks. ELECTRA is pre-trained to distinguish if a token is generated or original. We naturally extend that to prompt-based few-shot learning by training to score the originality of the target options without introducing new parameters. Our method can be easily adapted to tasks involving multi-token predictions without extra computation overhead. Analysis shows that ELECTRA learns distributions that align better with downstream tasks.
Principled Paraphrase Generation with Parallel Corpora
May 24, 2022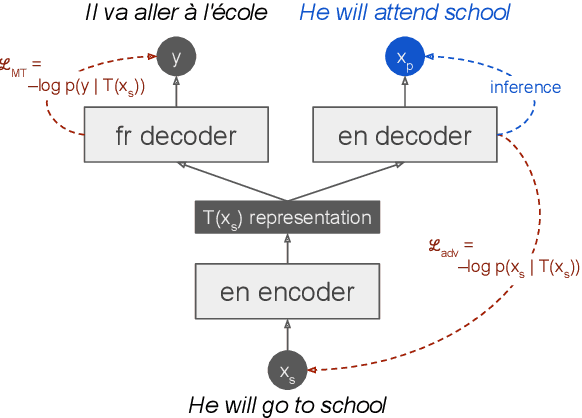
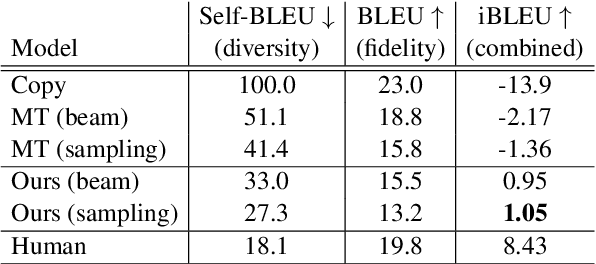
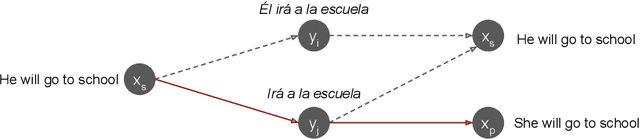
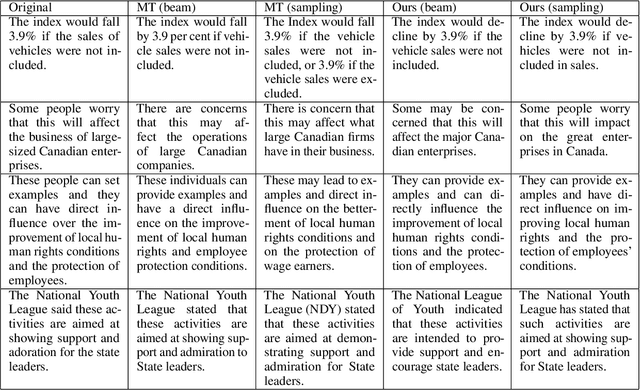
Round-trip Machine Translation (MT) is a popular choice for paraphrase generation, which leverages readily available parallel corpora for supervision. In this paper, we formalize the implicit similarity function induced by this approach, and show that it is susceptible to non-paraphrase pairs sharing a single ambiguous translation. Based on these insights, we design an alternative similarity metric that mitigates this issue by requiring the entire translation distribution to match, and implement a relaxation of it through the Information Bottleneck method. Our approach incorporates an adversarial term into MT training in order to learn representations that encode as much information about the reference translation as possible, while keeping as little information about the input as possible. Paraphrases can be generated by decoding back to the source from this representation, without having to generate pivot translations. In addition to being more principled and efficient than round-trip MT, our approach offers an adjustable parameter to control the fidelity-diversity trade-off, and obtains better results in our experiments.
PoeLM: A Meter- and Rhyme-Controllable Language Model for Unsupervised Poetry Generation
May 24, 2022
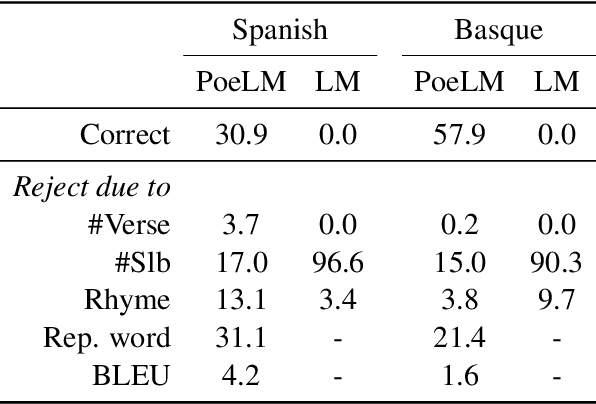
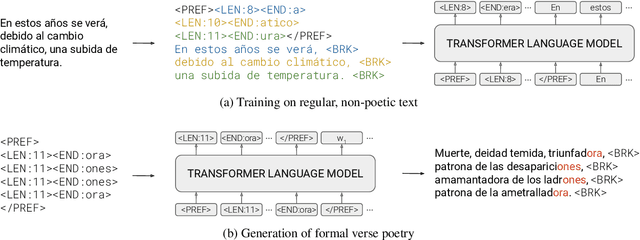
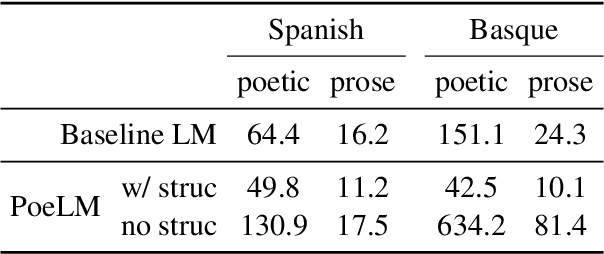
Formal verse poetry imposes strict constraints on the meter and rhyme scheme of poems. Most prior work on generating this type of poetry uses existing poems for supervision, which are difficult to obtain for most languages and poetic forms. In this work, we propose an unsupervised approach to generate poems following any given meter and rhyme scheme, without requiring any poetic text for training. Our method works by splitting a regular, non-poetic corpus into phrases, prepending control codes that describe the length and end rhyme of each phrase, and training a transformer language model in the augmented corpus. During inference, we build control codes for the desired meter and rhyme scheme, and condition our language model on them to generate formal verse poetry. Experiments in Spanish and Basque show that our approach is able to generate valid poems, which are often comparable in quality to those written by humans.
On the Role of Bidirectionality in Language Model Pre-Training
May 24, 2022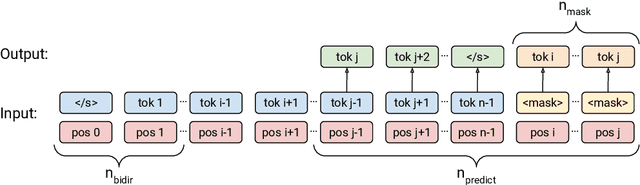

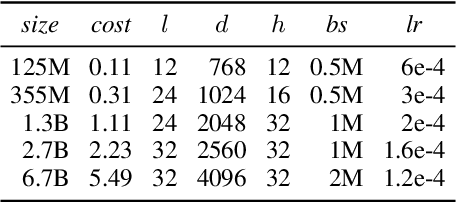
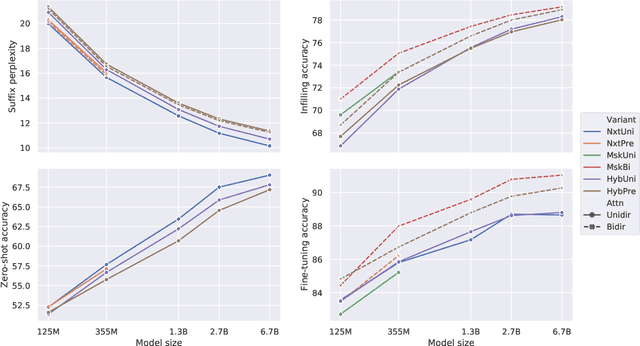
Prior work on language model pre-training has explored different architectures and learning objectives, but differences in data, hyperparameters and evaluation make a principled comparison difficult. In this work, we focus on bidirectionality as a key factor that differentiates existing approaches, and present a comprehensive study of its role in next token prediction, text infilling, zero-shot priming and fine-tuning. We propose a new framework that generalizes prior approaches, including fully unidirectional models like GPT, fully bidirectional models like BERT, and hybrid models like CM3 and prefix LM. Our framework distinguishes between two notions of bidirectionality (bidirectional context and bidirectional attention) and allows us to control each of them separately. We find that the optimal configuration is largely application-dependent (e.g., bidirectional attention is beneficial for fine-tuning and infilling, but harmful for next token prediction and zero-shot priming). We train models with up to 6.7B parameters, and find differences to remain consistent at scale. While prior work on scaling has focused on left-to-right autoregressive models, our results suggest that this approach comes with some trade-offs, and it might be worthwhile to develop very large bidirectional models.
Multilingual Machine Translation with Hyper-Adapters
May 22, 2022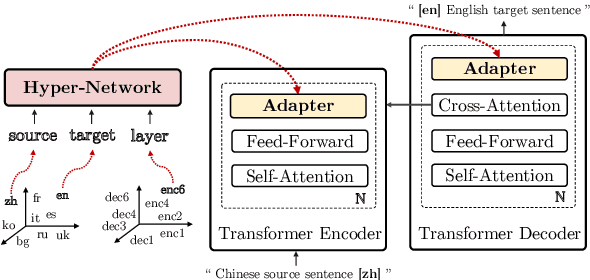
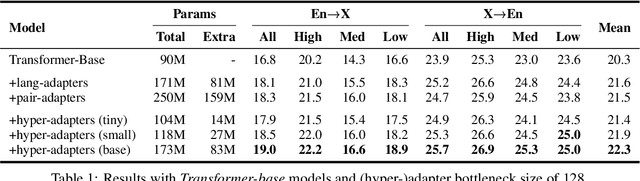
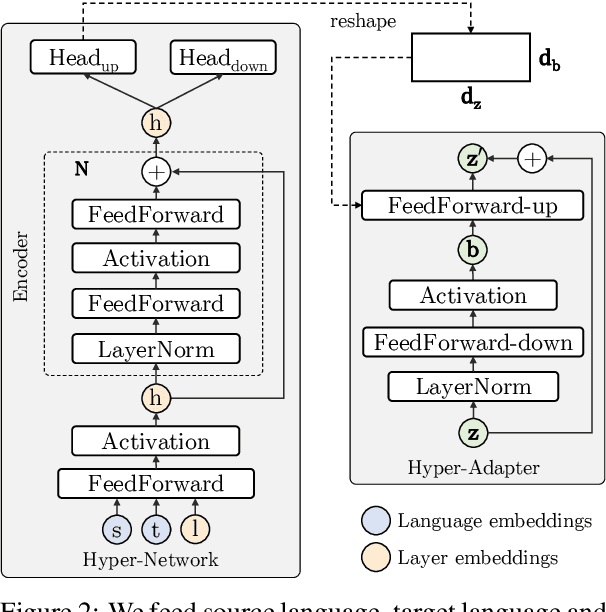
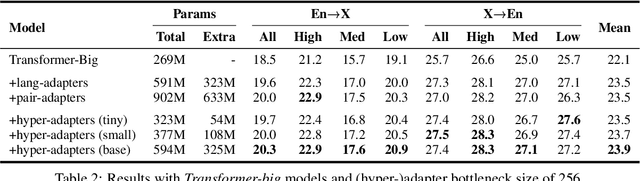
Multilingual machine translation suffers from negative interference across languages. A common solution is to relax parameter sharing with language-specific modules like adapters. However, adapters of related languages are unable to transfer information, and their total number of parameters becomes prohibitively expensive as the number of languages grows. In this work, we overcome these drawbacks using hyper-adapters -- hyper-networks that generate adapters from language and layer embeddings. While past work had poor results when scaling hyper-networks, we propose a rescaling fix that significantly improves convergence and enables training larger hyper-networks. We find that hyper-adapters are more parameter efficient than regular adapters, reaching the same performance with up to 12 times less parameters. When using the same number of parameters and FLOPS, our approach consistently outperforms regular adapters. Also, hyper-adapters converge faster than alternative approaches and scale better than regular dense networks. Our analysis shows that hyper-adapters learn to encode language relatedness, enabling positive transfer across languages.
Lifting the Curse of Multilinguality by Pre-training Modular Transformers
May 12, 2022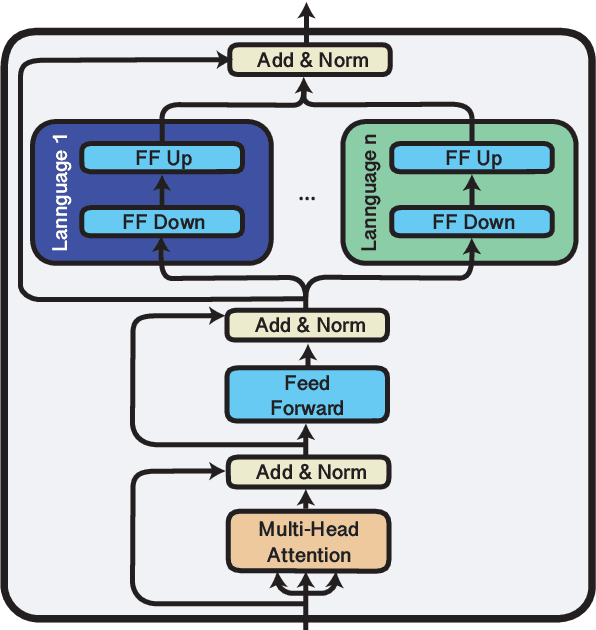

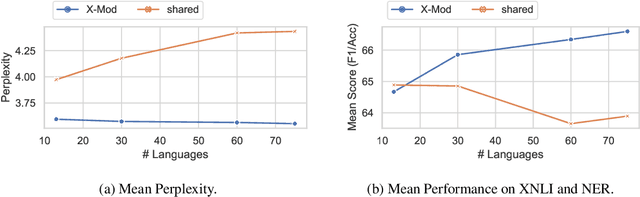
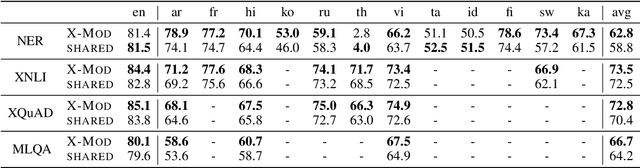
Multilingual pre-trained models are known to suffer from the curse of multilinguality, which causes per-language performance to drop as they cover more languages. We address this issue by introducing language-specific modules, which allows us to grow the total capacity of the model, while keeping the total number of trainable parameters per language constant. In contrast with prior work that learns language-specific components post-hoc, we pre-train the modules of our Cross-lingual Modular (X-Mod) models from the start. Our experiments on natural language inference, named entity recognition and question answering show that our approach not only mitigates the negative interference between languages, but also enables positive transfer, resulting in improved monolingual and cross-lingual performance. Furthermore, our approach enables adding languages post-hoc with no measurable drop in performance, no longer limiting the model usage to the set of pre-trained languages.
OPT: Open Pre-trained Transformer Language Models
May 05, 2022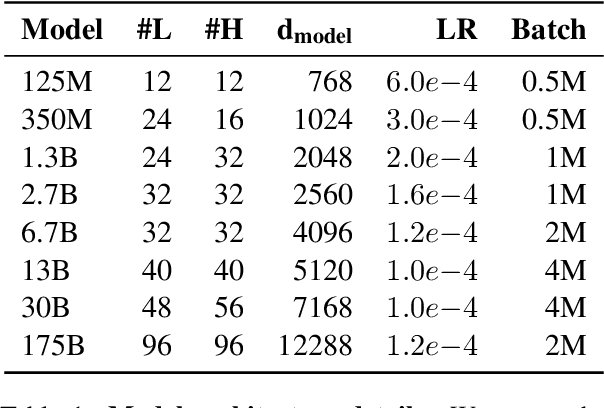
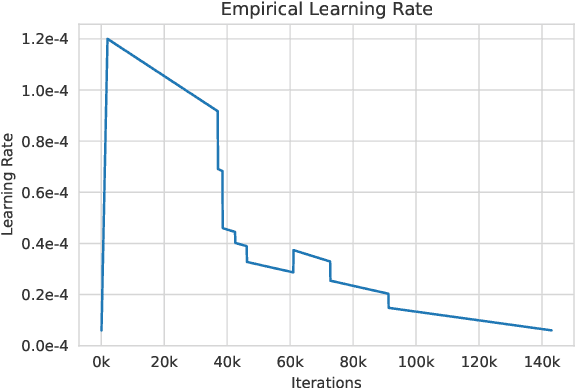
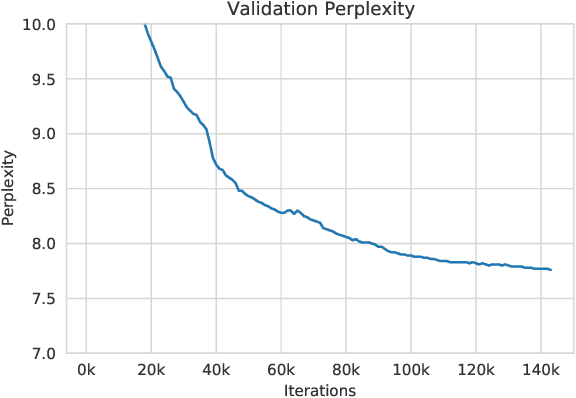
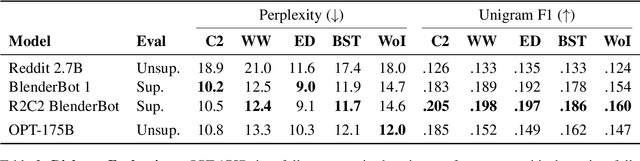
Large language models, which are often trained for hundreds of thousands of compute days, have shown remarkable capabilities for zero- and few-shot learning. Given their computational cost, these models are difficult to replicate without significant capital. For the few that are available through APIs, no access is granted to the full model weights, making them difficult to study. We present Open Pre-trained Transformers (OPT), a suite of decoder-only pre-trained transformers ranging from 125M to 175B parameters, which we aim to fully and responsibly share with interested researchers. We show that OPT-175B is comparable to GPT-3, while requiring only 1/7th the carbon footprint to develop. We are also releasing our logbook detailing the infrastructure challenges we faced, along with code for experimenting with all of the released models.
Efficient Language Modeling with Sparse all-MLP
Mar 16, 2022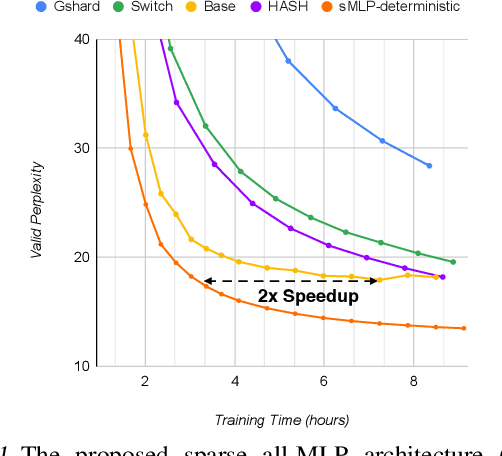

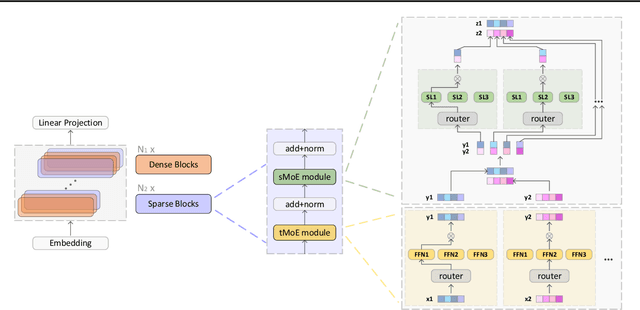

All-MLP architectures have attracted increasing interest as an alternative to attention-based models. In NLP, recent work like gMLP shows that all-MLPs can match Transformers in language modeling, but still lag behind in downstream tasks. In this work, we analyze the limitations of MLPs in expressiveness, and propose sparsely activated MLPs with mixture-of-experts (MoEs) in both feature and input (token) dimensions. Such sparse all-MLPs significantly increase model capacity and expressiveness while keeping the compute constant. We address critical challenges in incorporating conditional computation with two routing strategies. The proposed sparse all-MLP improves language modeling perplexity and obtains up to 2$\times$ improvement in training efficiency compared to both Transformer-based MoEs (GShard, Switch Transformer, Base Layers and HASH Layers) as well as dense Transformers and all-MLPs. Finally, we evaluate its zero-shot in-context learning performance on six downstream tasks, and find that it surpasses Transformer-based MoEs and dense Transformers.
Does Corpus Quality Really Matter for Low-Resource Languages?
Mar 15, 2022
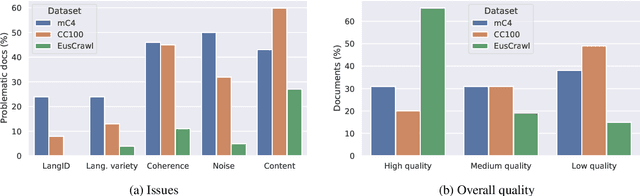
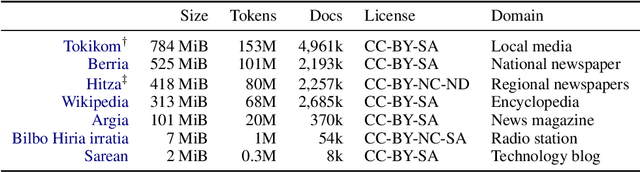
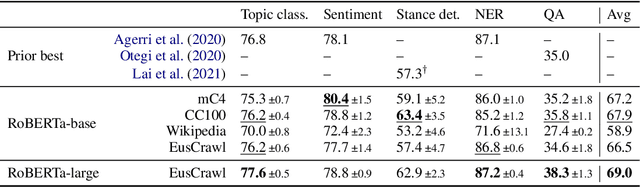
The vast majority of non-English corpora are derived from automatically filtered versions of CommonCrawl. While prior work has identified major issues on the quality of these datasets (Kreutzer et al., 2021), it is not clear how this impacts downstream performance. Taking Basque as a case study, we explore tailored crawling (manually identifying and scraping websites with high-quality content) as an alternative to filtering CommonCrawl. Our new corpus, called EusCrawl, is similar in size to the Basque portion of popular multilingual corpora like CC100 and mC4, yet it has a much higher quality according to native annotators. For instance, 66% of documents are rated as high-quality for EusCrawl, in contrast with <33% for both mC4 and CC100. Nevertheless, we obtain similar results on downstream tasks regardless of the corpus used for pre-training. Our work suggests that NLU performance in low-resource languages is primarily constrained by the quantity rather than the quality of the data, prompting for methods to exploit more diverse data sources.