 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Retrieval and Generation Training for Grounded Text Generation
Jun 03, 2021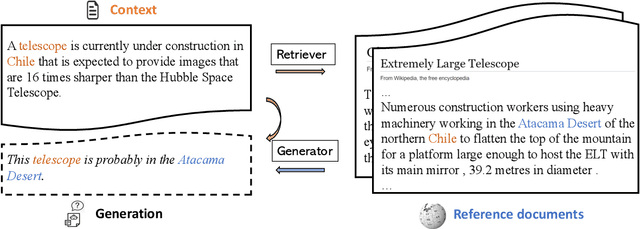
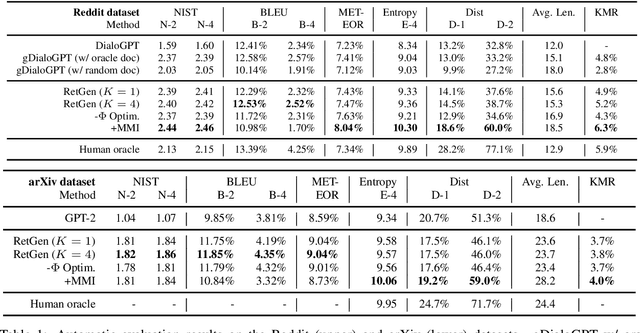
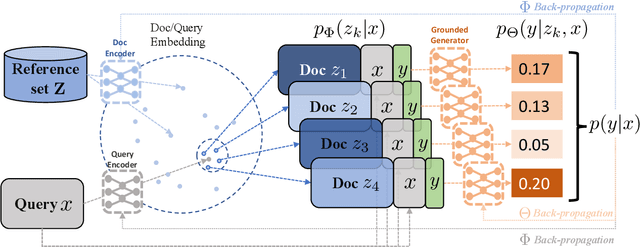

Recent advances in large-scale pre-training such as GPT-3 allow seemingly high quality text to be generated from a given prompt. However, such generation systems often suffer from problems of hallucinated facts, and are not inherently designed to incorporate useful external information. Grounded generation models appear to offer remedies, but their training typically relies on rarely-available parallel data where corresponding information-relevant documents are provided for context. We propose a framework that alleviates this data constraint by jointly training a grounded generator and document retriever on the language model signal. The model learns to reward retrieval of the documents with the highest utility in generation, and attentively combines them using a Mixture-of-Experts (MoE) ensemble to generate follow-on text. We demonstrate that both generator and retriever can take advantage of this joint training and work synergistically to produce more informative and relevant text in both prose and dialogue generation.
An Adversarially-Learned Turing Test for Dialog Generation Models
Apr 16, 2021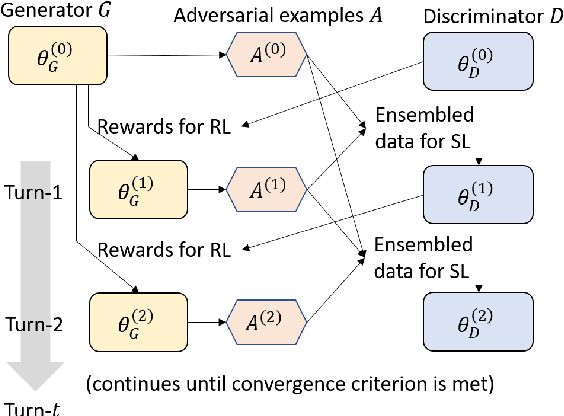

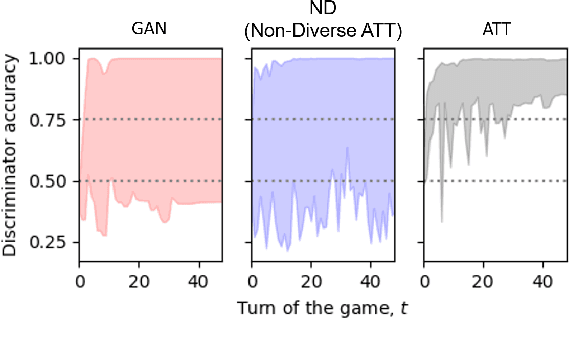
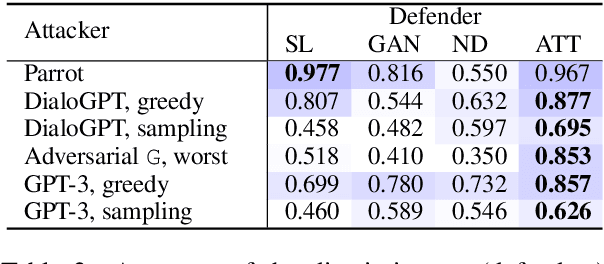
The design of better automated dialogue evaluation metrics offers the potential of accelerate evaluation research on conversational AI. However, existing trainable dialogue evaluation models are generally restricted to classifiers trained in a purely supervised manner, which suffer a significant risk from adversarial attacking (e.g., a nonsensical response that enjoys a high classification score). To alleviate this risk, we propose an adversarial training approach to learn a robust model, ATT (Adversarial Turing Test), that discriminates machine-generated responses from human-written replies. In contrast to previous perturbation-based methods, our discriminator is trained by iteratively generating unrestricted and diverse adversarial examples using reinforcement learning. The key benefit of this unrestricted adversarial training approach is allowing the discriminator to improve robustness in an iterative attack-defense game. Our discriminator shows high accuracy on strong attackers including DialoGPT and GPT-3.
Ask what's missing and what's useful: Improving Clarification Question Generation using Global Knowledge
Apr 14, 2021
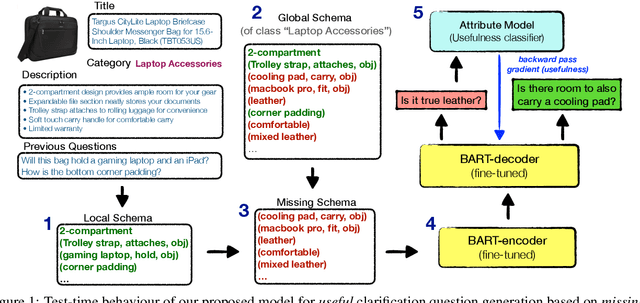
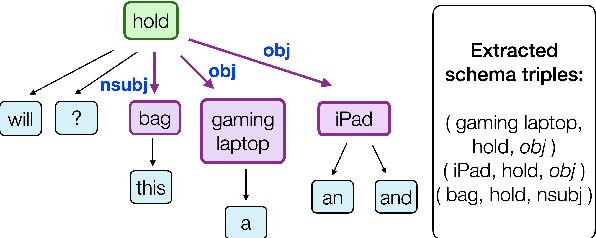
The ability to generate clarification questions i.e., questions that identify useful missing information in a given context, is important in reducing ambiguity. Humans use previous experience with similar contexts to form a global view and compare it to the given context to ascertain what is missing and what is useful in the context. Inspired by this, we propose a model for clarification question generation where we first identify what is missing by taking a difference between the global and the local view and then train a model to identify what is useful and generate a question about it. Our model outperforms several baselines as judged by both automatic metrics and humans.
Data Augmentation for Abstractive Query-Focused Multi-Document Summarization
Mar 02, 2021
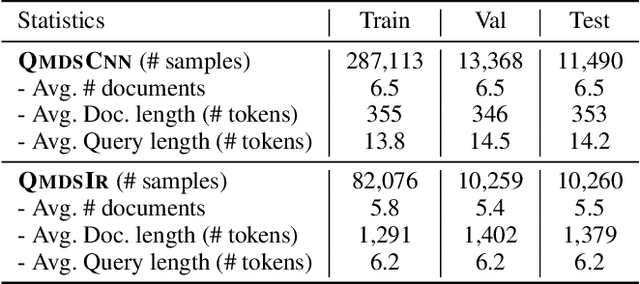
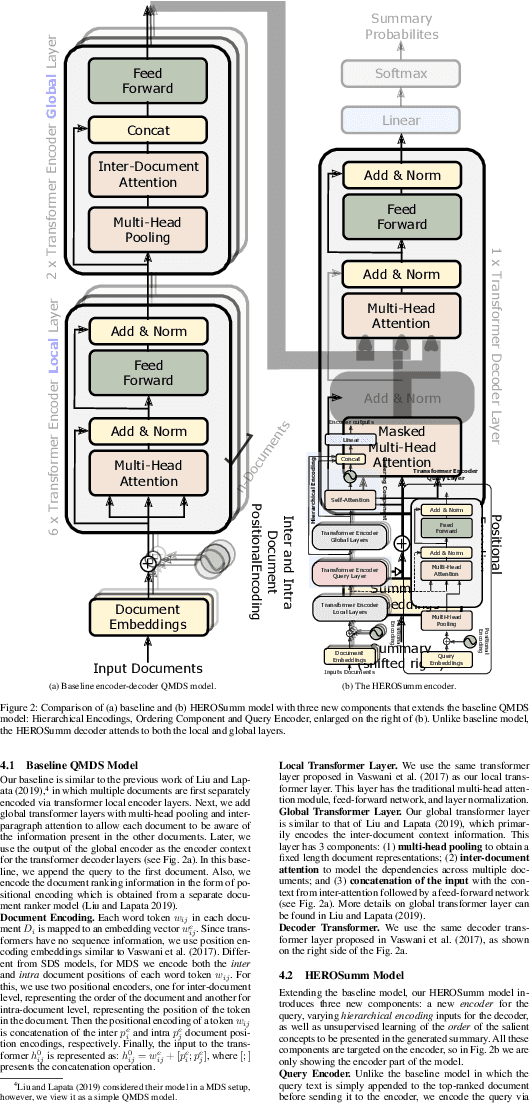
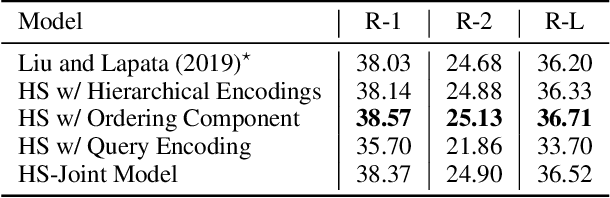
The progress in Query-focused Multi-Document Summarization (QMDS) has been limited by the lack of sufficient largescale high-quality training datasets. We present two QMDS training datasets, which we construct using two data augmentation methods: (1) transferring the commonly used single-document CNN/Daily Mail summarization dataset to create the QMDSCNN dataset, and (2) mining search-query logs to create the QMDSIR dataset. These two datasets have complementary properties, i.e., QMDSCNN has real summaries but queries are simulated, while QMDSIR has real queries but simulated summaries. To cover both these real summary and query aspects, we build abstractive end-to-end neural network models on the combined datasets that yield new state-of-the-art transfer results on DUC datasets. We also introduce new hierarchical encoders that enable a more efficient encoding of the query together with multiple documents. Empirical results demonstrate that our data augmentation and encoding methods outperform baseline models on automatic metrics, as well as on human evaluations along multiple attributes.
Text Editing by Command
Oct 24, 2020
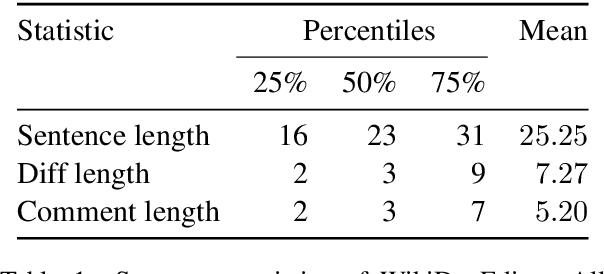
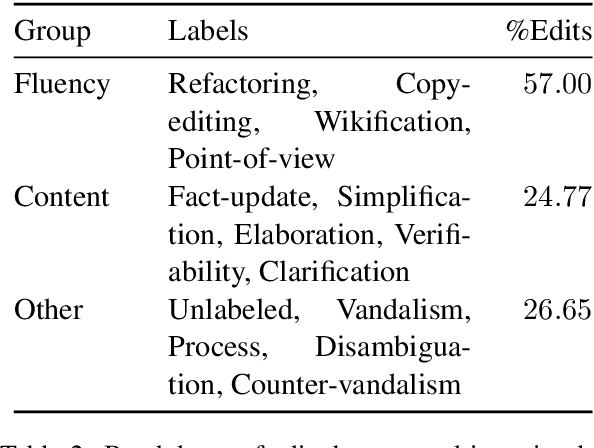
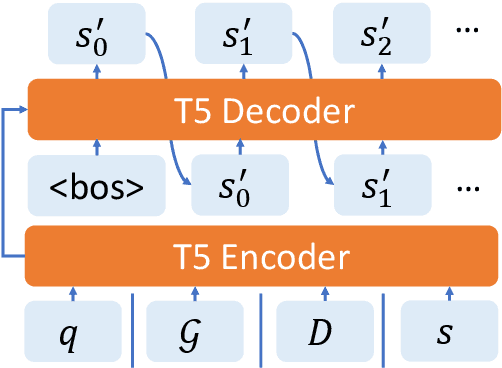
A prevailing paradigm in neural text generation is one-shot generation, where text is produced in a single step. The one-shot setting is inadequate, however, when the constraints the user wishes to impose on the generated text are dynamic, especially when authoring longer documents. We address this limitation with an interactive text generation setting in which the user interacts with the system by issuing commands to edit existing text. To this end, we propose a novel text editing task, and introduce WikiDocEdits, a dataset of single-sentence edits crawled from Wikipedia. We show that our Interactive Editor, a transformer-based model trained on this dataset, outperforms baselines and obtains positive results in both automatic and human evaluations. We present empirical and qualitative analyses of this model's performance.
Dialogue Response Ranking Training with Large-Scale Human Feedback Data
Sep 15, 2020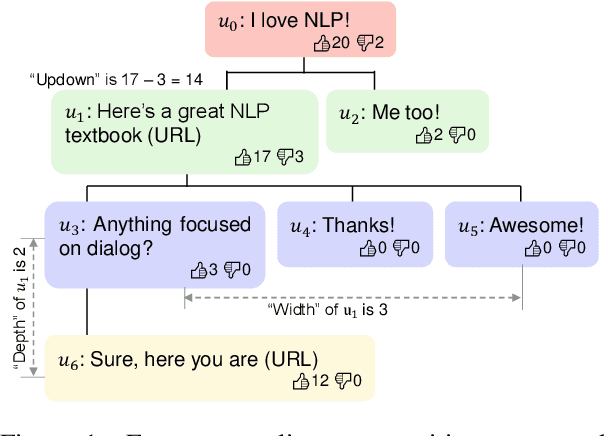
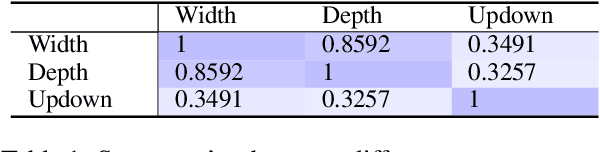
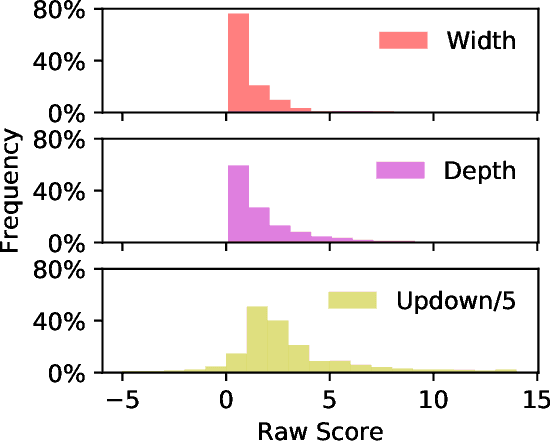
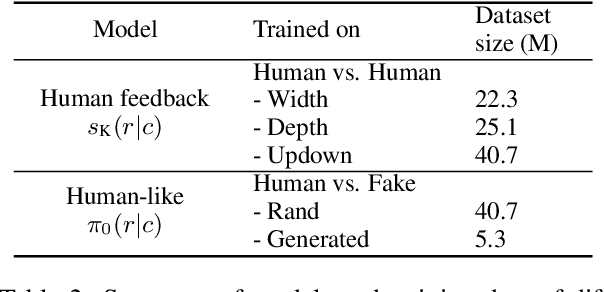
Existing open-domain dialog models are generally trained to minimize the perplexity of target human responses. However, some human replies are more engaging than others, spawning more followup interactions. Current conversational models are increasingly capable of producing turns that are context-relevant, but in order to produce compelling agents, these models need to be able to predict and optimize for turns that are genuinely engaging. We leverage social media feedback data (number of replies and upvotes) to build a large-scale training dataset for feedback prediction. To alleviate possible distortion between the feedback and engagingness, we convert the ranking problem to a comparison of response pairs which involve few confounding factors. We trained DialogRPT, a set of GPT-2 based models on 133M pairs of human feedback data and the resulting ranker outperformed several baselines. Particularly, our ranker outperforms the conventional dialog perplexity baseline with a large margin on predicting Reddit feedback. We finally combine the feedback prediction models and a human-like scoring model to rank the machine-generated dialog responses. Crowd-sourced human evaluation shows that our ranking method correlates better with real human preferences than baseline models.
MixingBoard: a Knowledgeable Stylized Integrated Text Generation Platform
May 17, 2020
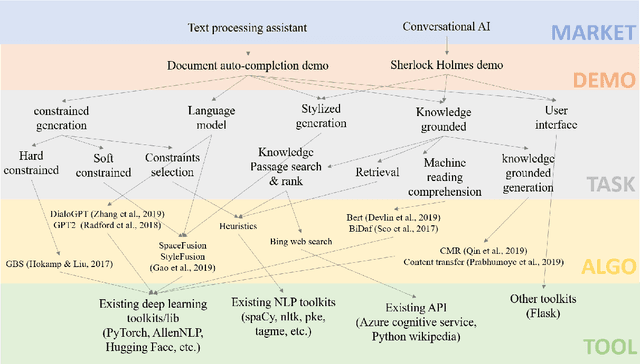
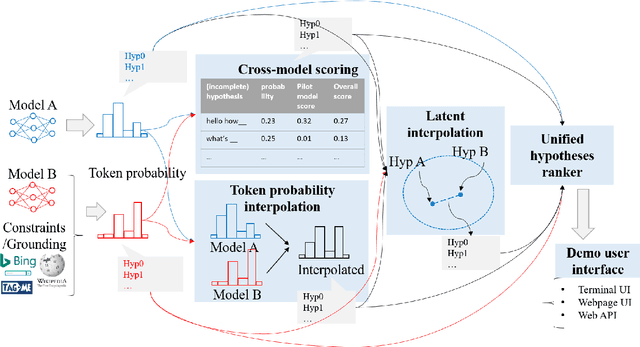
We present MixingBoard, a platform for quickly building demos with a focus on knowledge grounded stylized text generation. We unify existing text generation algorithms in a shared codebase and further adapt earlier algorithms for constrained generation. To borrow advantages from different models, we implement strategies for cross-model integration, from the token probability level to the latent space level. An interface to external knowledge is provided via a module that retrieves on-the-fly relevant knowledge from passages on the web or any document collection. A user interface for local development, remote webpage access, and a RESTful API are provided to make it simple for users to build their own demos.
A Controllable Model of Grounded Response Generation
May 01, 2020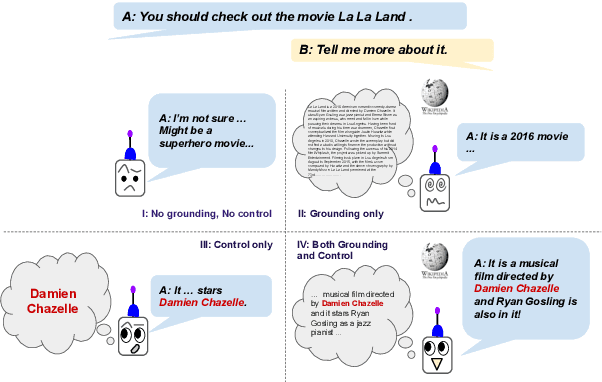
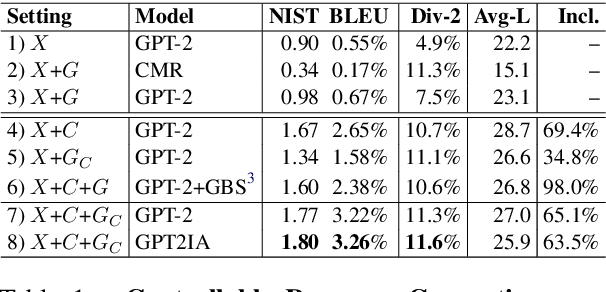
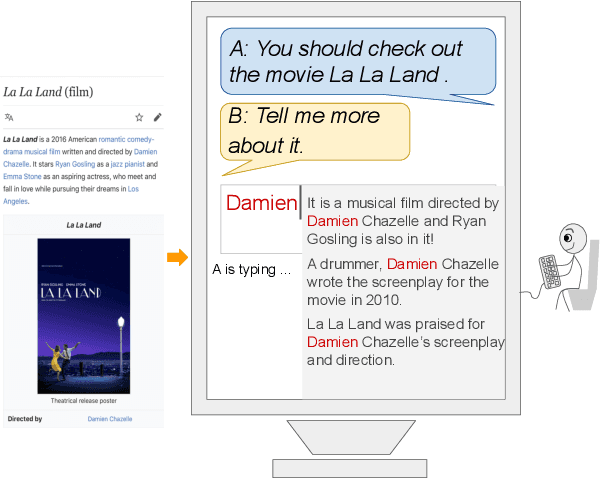
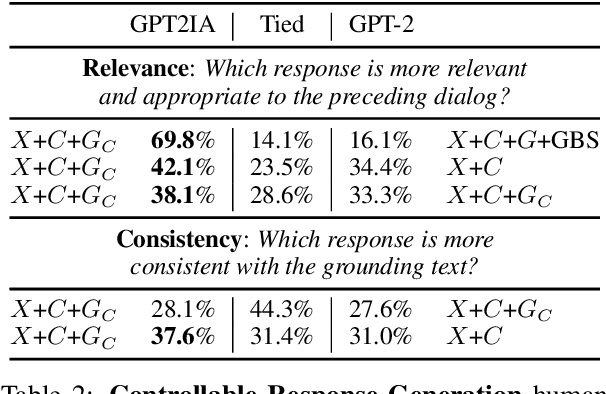
Current end-to-end neural conversation models inherently lack the flexibility to impose semantic control in the response generation process. This control is essential to ensure that users' semantic intents are satisfied and to impose a degree of specificity on generated outputs. Attempts to boost informativeness alone come at the expense of factual accuracy, as attested by GPT-2's propensity to "hallucinate" facts. While this may be mitigated by access to background knowledge, there is scant guarantee of relevance and informativeness in generated responses. We propose a framework that we call controllable grounded response generation (CGRG), in which lexical control phrases are either provided by an user or automatically extracted by a content planner from dialogue context and grounding knowledge. Quantitative and qualitative results show that, using this framework, a GPT-2 based model trained on a conversation-like Reddit dataset outperforms strong generation baselines.
The Eighth Dialog System Technology Challenge
Nov 14, 2019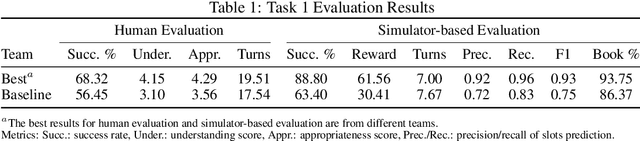
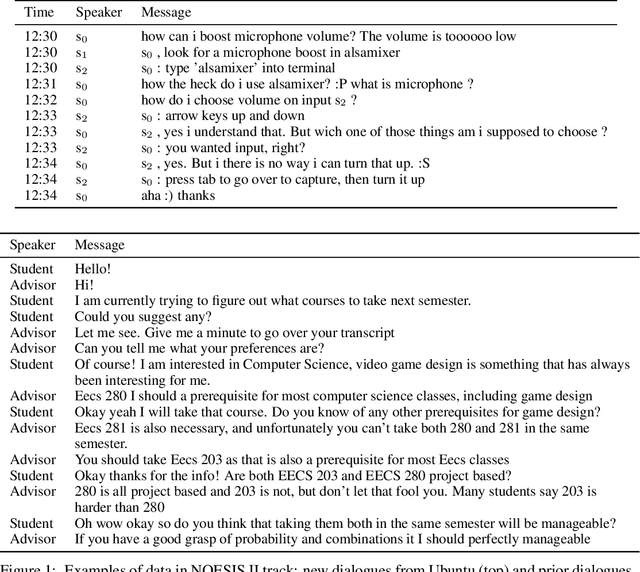
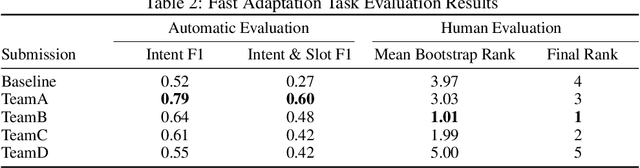
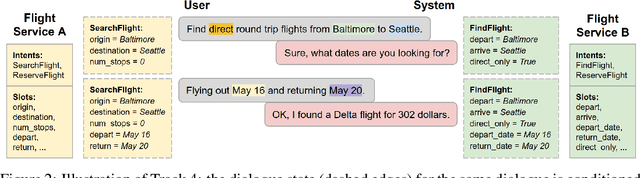
This paper introduces the Eighth Dialog System Technology Challenge. In line with recent challenges, the eighth edition focuses on applying end-to-end dialog technologies in a pragmatic way for multi-domain task-completion, noetic response selection, audio visual scene-aware dialog, and schema-guided dialog state tracking tasks. This paper describes the task definition, provided datasets, and evaluation set-up for each track. We also summarize the results of the submitted systems to highlight the overall trends of the state-of-the-art technologies for the tasks.
DialoGPT: Large-Scale Generative Pre-training for Conversational Response Generation
Nov 01, 2019
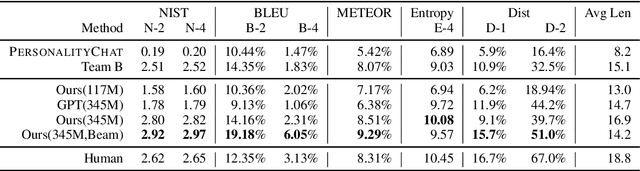

We present a large, tunable neural conversational response generation model, DialoGPT (dialogue generative pre-trained transformer). Trained on 147M conversation-like exchanges extracted from Reddit comment chains over a period spanning from 2005 through 2017, DialoGPT extends the Hugging Face PyTorch transformer to attain a performance close to human both in terms of automatic and human evaluation in single-turn dialogue settings. We show that conversational systems that leverage DialoGPT generate more relevant, contentful and context-consistent responses than strong baseline systems. The pre-trained model and training pipeline are publicly released to facilitate research into neural response generation and the development of more intelligent open-domain dialogue systems.