 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Better Lossless Compression Using Lossy Compression
Mar 23, 2020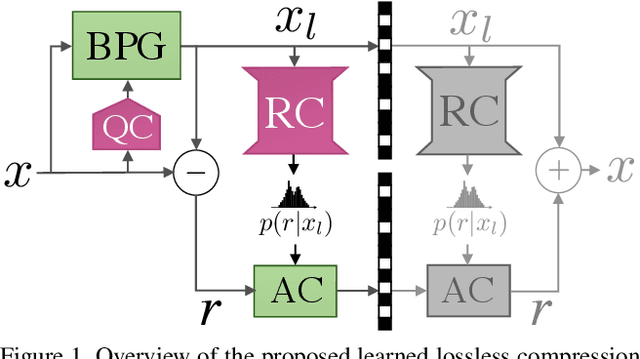
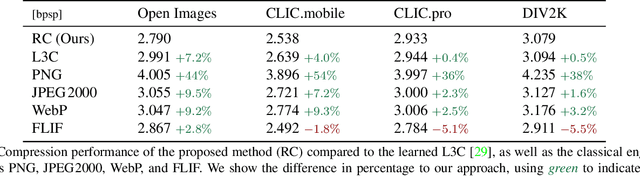
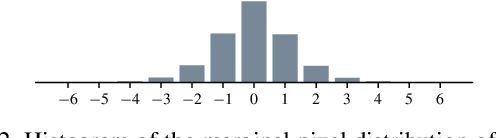
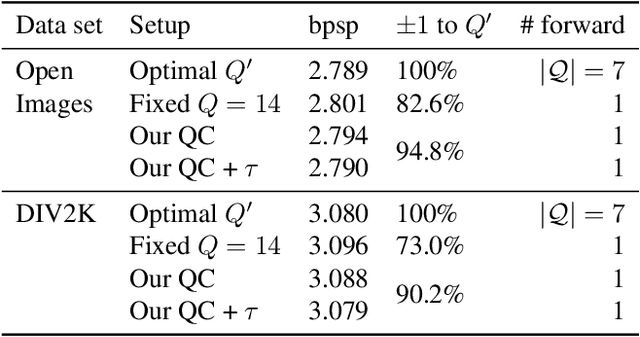
We leverage the powerful lossy image compression algorithm BPG to build a lossless image compression system. Specifically, the original image is first decomposed into the lossy reconstruction obtained after compressing it with BPG and the corresponding residual. We then model the distribution of the residual with a convolutional neural network-based probabilistic model that is conditioned on the BPG reconstruction, and combine it with entropy coding to losslessly encode the residual. Finally, the image is stored using the concatenation of the bitstreams produced by BPG and the learned residual coder. The resulting compression system achieves state-of-the-art performance in learned lossless full-resolution image compression, outperforming previous learned approaches as well as PNG, WebP, and JPEG2000.
Automatic Shortcut Removal for Self-Supervised Representation Learning
Feb 21, 2020
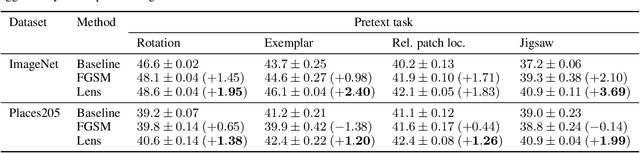
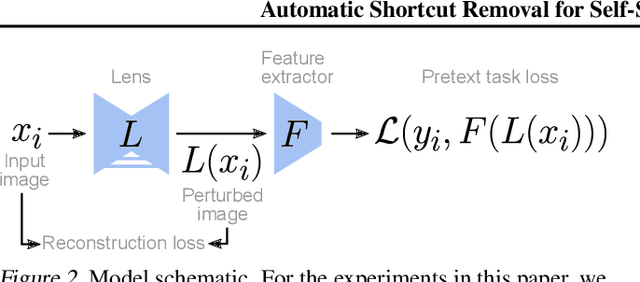
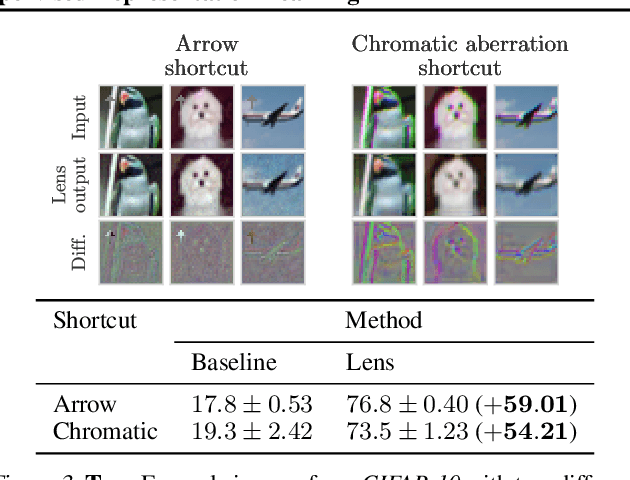
In self-supervised visual representation learning, a feature extractor is trained on a "pretext task" for which labels can be generated cheaply. A central challenge in this approach is that the feature extractor quickly learns to exploit low-level visual features such as color aberrations or watermarks and then fails to learn useful semantic representations. Much work has gone into identifying such "shortcut" features and hand-designing schemes to reduce their effect. Here, we propose a general framework for removing shortcut features automatically. Our key assumption is that those features which are the first to be exploited for solving the pretext task may also be the most vulnerable to an adversary trained to make the task harder. We show that this assumption holds across common pretext tasks and datasets by training a "lens" network to make small image changes that maximally reduce performance in the pretext task. Representations learned with the modified images outperform those learned without in all tested cases. Additionally, the modifications made by the lens reveal how the choice of pretext task and dataset affects the features learned by self-supervision.
Weakly-Supervised Disentanglement Without Compromises
Feb 07, 2020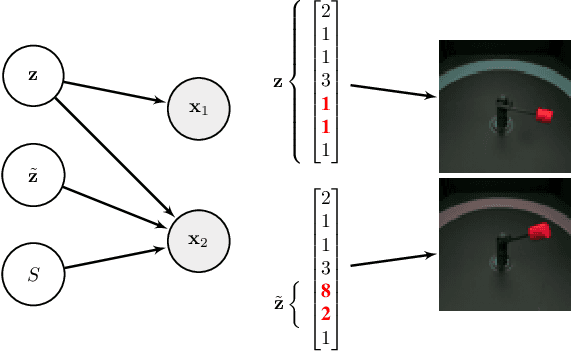

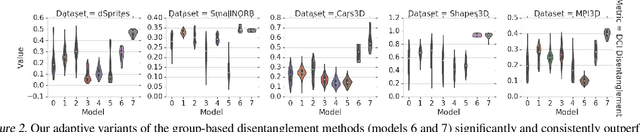
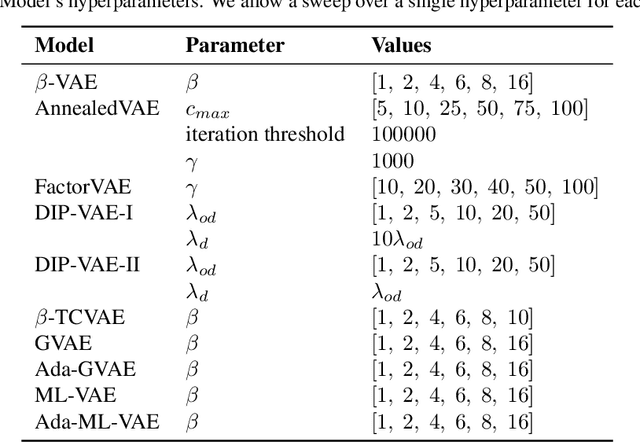
Intelligent agents should be able to learn useful representations by observing changes in their environment. We model such observations as pairs of non-i.i.d. images sharing at least one of the underlying factors of variation. First, we theoretically show that only knowing how many factors have changed, but not which ones, is sufficient to learn disentangled representations. Second, we provide practical algorithms that learn disentangled representations from pairs of images without requiring annotation of groups, individual factors, or the number of factors that have changed. Third, we perform a large-scale empirical study and show that such pairs of observations are sufficient to reliably learn disentangled representations on several benchmark data sets. Finally, we evaluate our learned representations and find that they are simultaneously useful on a diverse suite of tasks, including generalization under covariate shifts, fairness, and abstract reasoning. Overall, our results demonstrate that weak supervision enables learning of useful disentangled representations in realistic scenarios.
Self-Supervised Learning of Video-Induced Visual Invariances
Dec 05, 2019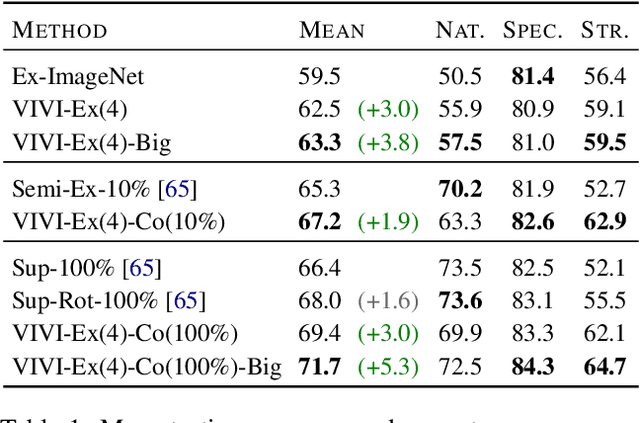
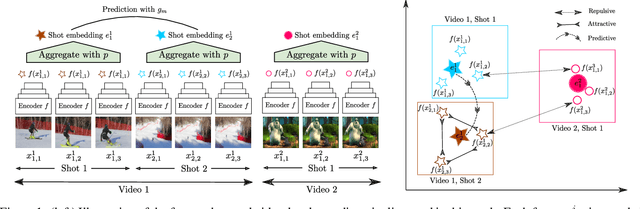
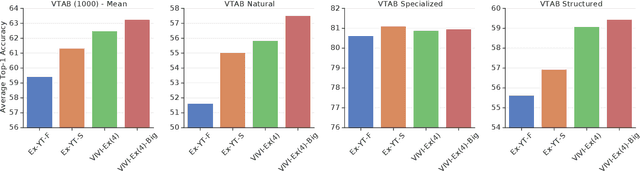
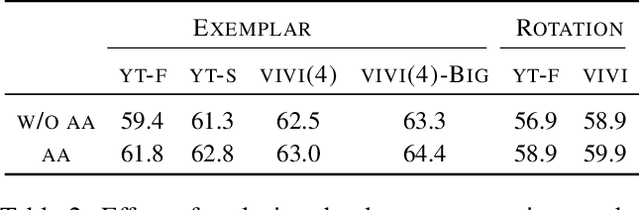
We propose a general framework for self-supervised learning of transferable visual representations based on video-induced visual invariances (VIVI). We consider the implicit hierarchy present in the videos and make use of (i) frame-level invariances (e.g. stability to color and contrast perturbations), (ii) shot/clip-level invariances (e.g. robustness to changes in object orientation and lighting conditions), and (iii) video-level invariances (semantic relationships of scenes across shots/clips), to define a holistic self-supervised loss. Training models using different variants of the proposed framework on videos from the YouTube-8M data set, we obtain state-of-the-art self-supervised transfer learning results on the 19 diverse downstream tasks of the Visual Task Adaptation Benchmark (VTAB), using only 1000 labels per task. We then show how to co-train our models jointly with labeled images, outperforming an ImageNet-pretrained ResNet-50 by 0.8 points with 10x fewer labeled images, as well as the previous best supervised model by 3.7 points using the full ImageNet data set.
Semantic Bottleneck Scene Generation
Nov 26, 2019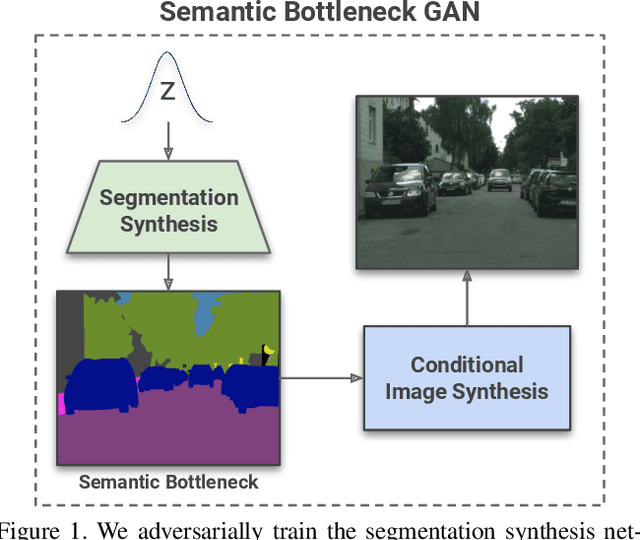
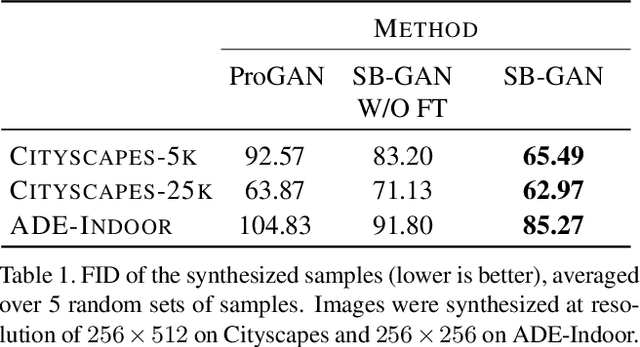
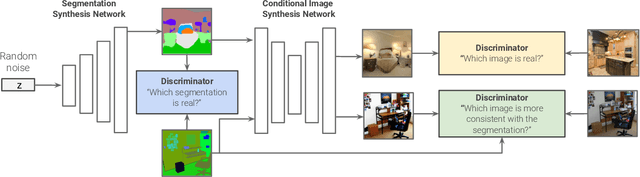
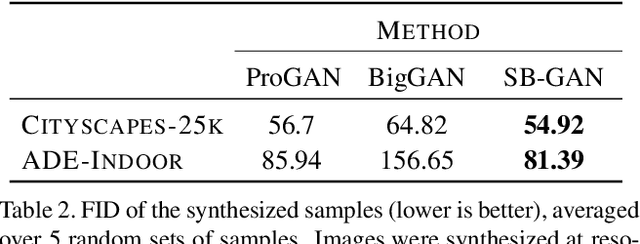
Coupling the high-fidelity generation capabilities of label-conditional image synthesis methods with the flexibility of unconditional generative models, we propose a semantic bottleneck GAN model for unconditional synthesis of complex scenes. We assume pixel-wise segmentation labels are available during training and use them to learn the scene structure. During inference, our model first synthesizes a realistic segmentation layout from scratch, then synthesizes a realistic scene conditioned on that layout. For the former, we use an unconditional progressive segmentation generation network that captures the distribution of realistic semantic scene layouts. For the latter, we use a conditional segmentation-to-image synthesis network that captures the distribution of photo-realistic images conditioned on the semantic layout. When trained end-to-end, the resulting model outperforms state-of-the-art generative models in unsupervised image synthesis on two challenging domains in terms of the Frechet Inception Distance and user-study evaluations. Moreover, we demonstrate the generated segmentation maps can be used as additional training data to strongly improve recent segmentation-to-image synthesis networks.
The Visual Task Adaptation Benchmark
Oct 01, 2019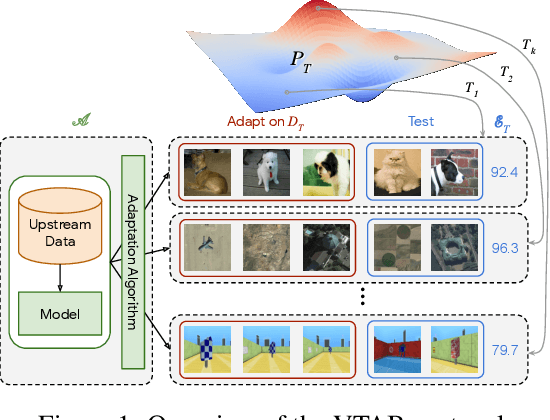
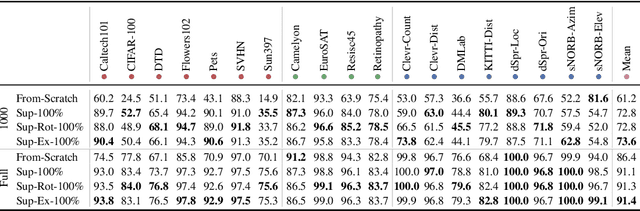
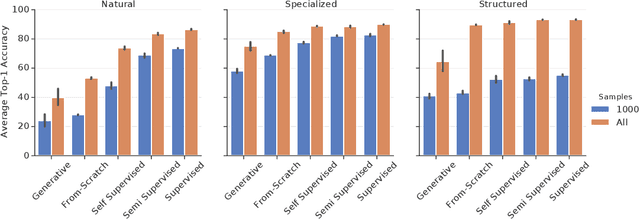
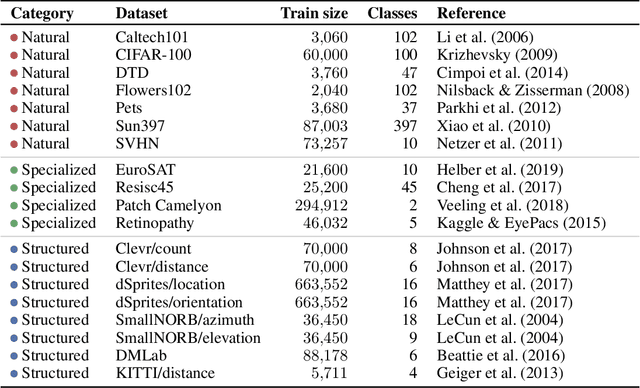
Representation learning promises to unlock deep learning for the long tail of vision tasks without expansive labelled datasets. Yet, the absence of a unified yardstick to evaluate general visual representations hinders progress. Many sub-fields promise representations, but each has different evaluation protocols that are either too constrained (linear classification), limited in scope (ImageNet, CIFAR, Pascal-VOC), or only loosely related to representation quality (generation). We present the Visual Task Adaptation Benchmark (VTAB): a diverse, realistic, and challenging benchmark to evaluate representations. VTAB embodies one principle: good representations adapt to unseen tasks with few examples. We run a large VTAB study of popular algorithms, answering questions like: How effective are ImageNet representation on non-standard datasets? Are generative models competitive? Is self-supervision useful if one already has labels?
On Mutual Information Maximization for Representation Learning
Jul 31, 2019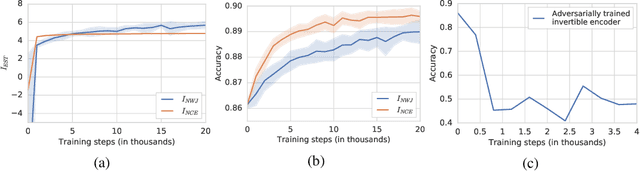
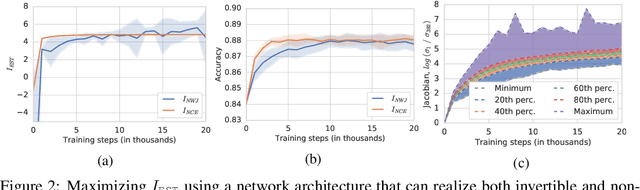
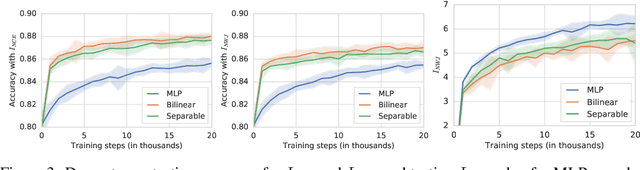
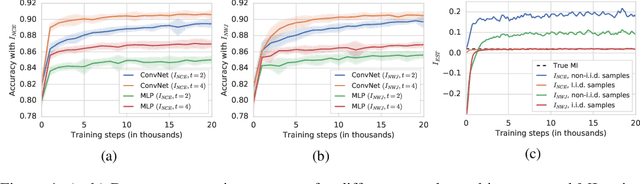
Many recent methods for unsupervised or self-supervised representation learning train feature extractors by maximizing an estimate of the mutual information (MI) between different views of the data. This comes with several immediate problems: For example, MI is notoriously hard to estimate, and using it as an objective for representation learning may lead to highly entangled representations due to its invariance under arbitrary invertible transformations. Nevertheless, these methods have been repeatedly shown to excel in practice. In this paper we argue, and provide empirical evidence, that the success of these methods might be only loosely attributed to the properties of MI, and that they strongly depend on the inductive bias in both the choice of feature extractor architectures and the parametrization of the employed MI estimators. Finally, we establish a connection to deep metric learning and argue that this interpretation may be a plausible explanation for the success of the recently introduced methods.
Disentangling Factors of Variation Using Few Labels
May 03, 2019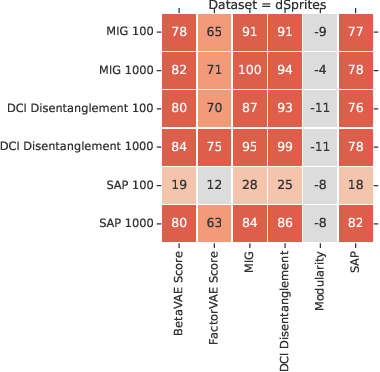
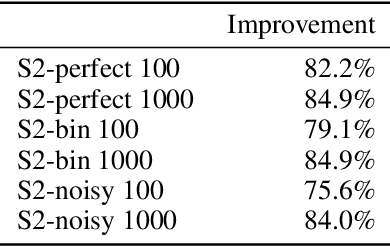
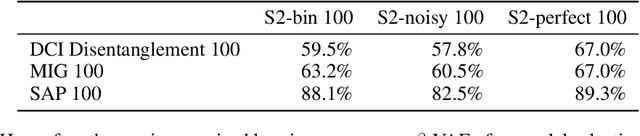

Learning disentangled representations is considered a cornerstone problem in representation learning. Recently, Locatello et al. (2019) demonstrated that unsupervised disentanglement learning without inductive biases is theoretically impossible and that existing inductive biases and unsupervised methods do not allow to consistently learn disentangled representations. However, in many practical settings, one might have access to a very limited amount of supervision, for example through manual labeling of training examples. In this paper, we investigate the impact of such supervision on state-of-the-art disentanglement methods and perform a large scale study, training over 29000 models under well-defined and reproducible experimental conditions. We first observe that a very limited number of labeled examples (0.01--0.5% of the data set) is sufficient to perform model selection on state-of-the-art unsupervised models. Yet, if one has access to labels for supervised model selection, this raises the natural question of whether they should also be incorporated into the training process. As a case-study, we test the benefit of introducing (very limited) supervision into existing state-of-the-art unsupervised disentanglement methods exploiting both the values of the labels and the ordinal information that can be deduced from them. Overall, we empirically validate that with very little and potentially imprecise supervision it is possible to reliably learn disentangled representations.
High-Fidelity Image Generation With Fewer Labels
Mar 06, 2019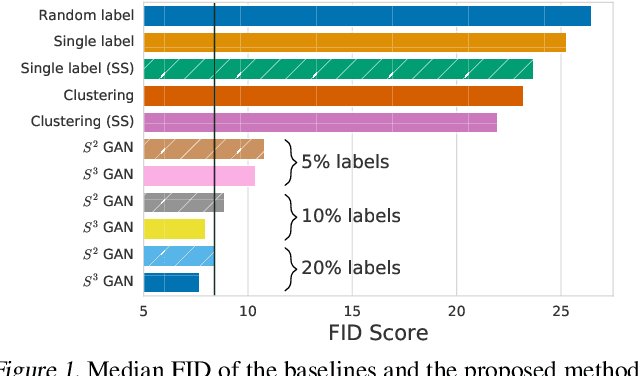
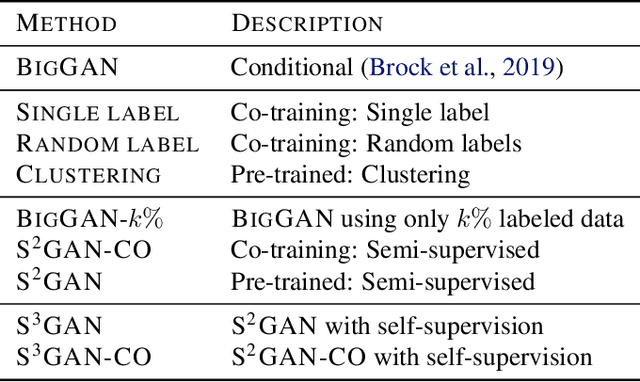

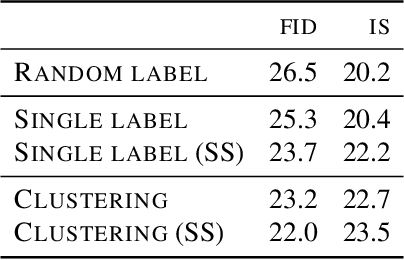
Deep generative models are becoming a cornerstone of modern machine learning. Recent work on conditional generative adversarial networks has shown that learning complex, high-dimensional distributions over natural images is within reach. While the latest models are able to generate high-fidelity, diverse natural images at high resolution, they rely on a vast quantity of labeled data. In this work we demonstrate how one can benefit from recent work on self- and semi-supervised learning to outperform state-of-the-art (SOTA) on both unsupervised ImageNet synthesis, as well as in the conditional setting. In particular, the proposed approach is able to match the sample quality (as measured by FID) of the current state-of-the art conditional model BigGAN on ImageNet using only 10% of the labels and outperform it using 20% of the labels.
Recent Advances in Autoencoder-Based Representation Learning
Dec 12, 2018
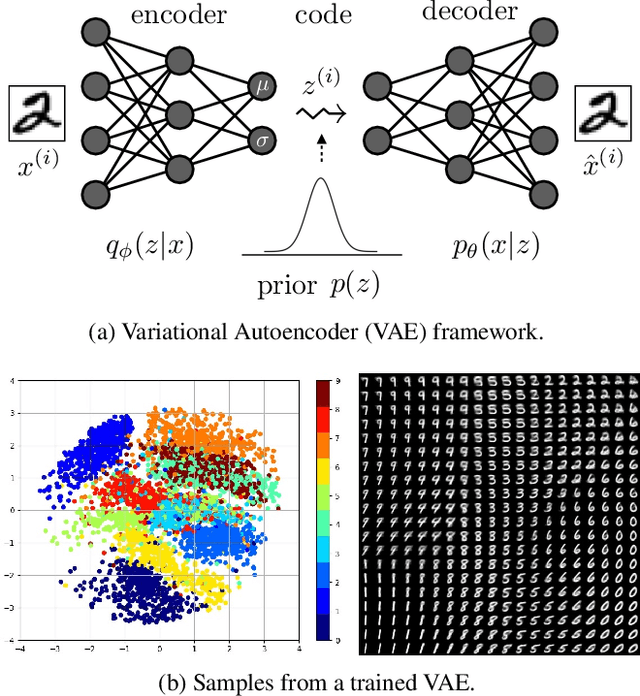
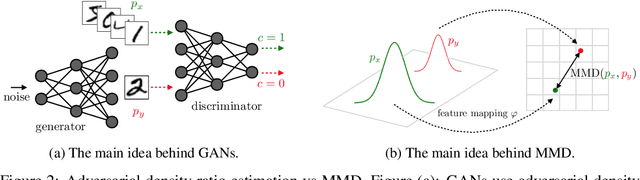

Learning useful representations with little or no supervision is a key challenge in artificial intelligence. We provide an in-depth review of recent advances in representation learning with a focus on autoencoder-based models. To organize these results we make use of meta-priors believed useful for downstream tasks, such as disentanglement and hierarchical organization of features. In particular, we uncover three main mechanisms to enforce such properties, namely (i) regularizing the (approximate or aggregate) posterior distribution, (ii) factorizing the encoding and decoding distribution, or (iii) introducing a structured prior distribution. While there are some promising results, implicit or explicit supervision remains a key enabler and all current methods use strong inductive biases and modeling assumptions. Finally, we provide an analysis of autoencoder-based representation learning through the lens of rate-distortion theory and identify a clear tradeoff between the amount of prior knowledge available about the downstream tasks, and how useful the representation is for this task.