 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFLEX: A Backbone for Diffusion-Based Modeling of Spatio-temporal Physical Systems
May 23, 2025We introduce FLEX (FLow EXpert), a backbone architecture for generative modeling of spatio-temporal physical systems using diffusion models. FLEX operates in the residual space rather than on raw data, a modeling choice that we motivate theoretically, showing that it reduces the variance of the velocity field in the diffusion model, which helps stabilize training. FLEX integrates a latent Transformer into a U-Net with standard convolutional ResNet layers and incorporates a redesigned skip connection scheme. This hybrid design enables the model to capture both local spatial detail and long-range dependencies in latent space. To improve spatio-temporal conditioning, FLEX uses a task-specific encoder that processes auxiliary inputs such as coarse or past snapshots. Weak conditioning is applied to the shared encoder via skip connections to promote generalization, while strong conditioning is applied to the decoder through both skip and bottleneck features to ensure reconstruction fidelity. FLEX achieves accurate predictions for super-resolution and forecasting tasks using as few as two reverse diffusion steps. It also produces calibrated uncertainty estimates through sampling. Evaluations on high-resolution 2D turbulence data show that FLEX outperforms strong baselines and generalizes to out-of-distribution settings, including unseen Reynolds numbers, physical observables (e.g., fluid flow velocity fields), and boundary conditions.
Removing Watermarks with Partial Regeneration using Semantic Information
May 13, 2025As AI-generated imagery becomes ubiquitous, invisible watermarks have emerged as a primary line of defense for copyright and provenance. The newest watermarking schemes embed semantic signals - content-aware patterns that are designed to survive common image manipulations - yet their true robustness against adaptive adversaries remains under-explored. We expose a previously unreported vulnerability and introduce SemanticRegen, a three-stage, label-free attack that erases state-of-the-art semantic and invisible watermarks while leaving an image's apparent meaning intact. Our pipeline (i) uses a vision-language model to obtain fine-grained captions, (ii) extracts foreground masks with zero-shot segmentation, and (iii) inpaints only the background via an LLM-guided diffusion model, thereby preserving salient objects and style cues. Evaluated on 1,000 prompts across four watermarking systems - TreeRing, StegaStamp, StableSig, and DWT/DCT - SemanticRegen is the only method to defeat the semantic TreeRing watermark (p = 0.10 > 0.05) and reduces bit-accuracy below 0.75 for the remaining schemes, all while maintaining high perceptual quality (masked SSIM = 0.94 +/- 0.01). We further introduce masked SSIM (mSSIM) to quantify fidelity within foreground regions, showing that our attack achieves up to 12 percent higher mSSIM than prior diffusion-based attackers. These results highlight an urgent gap between current watermark defenses and the capabilities of adaptive, semantics-aware adversaries, underscoring the need for watermarking algorithms that are resilient to content-preserving regenerative attacks.
Paving the way for scientific foundation models: enhancing generalization and robustness in PDEs with constraint-aware pre-training
Mar 24, 2025Partial differential equations (PDEs) govern a wide range of physical systems, but solving them efficiently remains a major challenge. The idea of a scientific foundation model (SciFM) is emerging as a promising tool for learning transferable representations across diverse domains. However, SciFMs require large amounts of solution data, which may be scarce or computationally expensive to generate. To maximize generalization while reducing data dependence, we propose incorporating PDE residuals into pre-training either as the sole learning signal or in combination with data loss to compensate for limited or infeasible training data. We evaluate this constraint-aware pre-training across three key benchmarks: (i) generalization to new physics, where material properties, e.g., the diffusion coefficient, is shifted with respect to the training distribution; (ii) generalization to entirely new PDEs, requiring adaptation to different operators; and (iii) robustness against noisy fine-tuning data, ensuring stability in real-world applications. Our results show that pre-training with PDE constraints significantly enhances generalization, outperforming models trained solely on solution data across all benchmarks. These findings prove the effectiveness of our proposed constraint-aware pre-training as a crucial component for SciFMs, providing a scalable approach to data-efficient, generalizable PDE solvers.
Determinant Estimation under Memory Constraints and Neural Scaling Laws
Mar 06, 2025Calculating or accurately estimating log-determinants of large positive semi-definite matrices is of fundamental importance in many machine learning tasks. While its cubic computational complexity can already be prohibitive, in modern applications, even storing the matrices themselves can pose a memory bottleneck. To address this, we derive a novel hierarchical algorithm based on block-wise computation of the LDL decomposition for large-scale log-determinant calculation in memory-constrained settings. In extreme cases where matrices are highly ill-conditioned, accurately computing the full matrix itself may be infeasible. This is particularly relevant when considering kernel matrices at scale, including the empirical Neural Tangent Kernel (NTK) of neural networks trained on large datasets. Under the assumption of neural scaling laws in the test error, we show that the ratio of pseudo-determinants satisfies a power-law relationship, allowing us to derive corresponding scaling laws. This enables accurate estimation of NTK log-determinants from a tiny fraction of the full dataset; in our experiments, this results in a $\sim$100,000$\times$ speedup with improved accuracy over competing approximations. Using these techniques, we successfully estimate log-determinants for dense matrices of extreme sizes, which were previously deemed intractable and inaccessible due to their enormous scale and computational demands.
ETS: Efficient Tree Search for Inference-Time Scaling
Feb 19, 2025



Test-time compute scaling has emerged as a new axis along which to improve model accuracy, where additional computation is used at inference time to allow the model to think longer for more challenging problems. One promising approach for test-time compute scaling is search against a process reward model, where a model generates multiple potential candidates at each step of the search, and these partial trajectories are then scored by a separate reward model in order to guide the search process. The diversity of trajectories in the tree search process affects the accuracy of the search, since increasing diversity promotes more exploration. However, this diversity comes at a cost, as divergent trajectories have less KV sharing, which means they consume more memory and slow down the search process. Previous search methods either do not perform sufficient exploration, or else explore diverse trajectories but have high latency. We address this challenge by proposing Efficient Tree Search (ETS), which promotes KV sharing by pruning redundant trajectories while maintaining necessary diverse trajectories. ETS incorporates a linear programming cost model to promote KV cache sharing by penalizing the number of nodes retained, while incorporating a semantic coverage term into the cost model to ensure that we retain trajectories which are semantically different. We demonstrate how ETS can achieve 1.8$\times$ reduction in average KV cache size during the search process, leading to 1.4$\times$ increased throughput relative to prior state-of-the-art methods, with minimal accuracy degradation and without requiring any custom kernel implementation. Code is available at: https://github.com/SqueezeAILab/ETS.
Fundamental Bias in Inverting Random Sampling Matrices with Application to Sub-sampled Newton
Feb 19, 2025



A substantial body of work in machine learning (ML) and randomized numerical linear algebra (RandNLA) has exploited various sorts of random sketching methodologies, including random sampling and random projection, with much of the analysis using Johnson--Lindenstrauss and subspace embedding techniques. Recent studies have identified the issue of inversion bias -- the phenomenon that inverses of random sketches are not unbiased, despite the unbiasedness of the sketches themselves. This bias presents challenges for the use of random sketches in various ML pipelines, such as fast stochastic optimization, scalable statistical estimators, and distributed optimization. In the context of random projection, the inversion bias can be easily corrected for dense Gaussian projections (which are, however, too expensive for many applications). Recent work has shown how the inversion bias can be corrected for sparse sub-gaussian projections. In this paper, we show how the inversion bias can be corrected for random sampling methods, both uniform and non-uniform leverage-based, as well as for structured random projections, including those based on the Hadamard transform. Using these results, we establish problem-independent local convergence rates for sub-sampled Newton methods.
MatterChat: A Multi-Modal LLM for Material Science
Feb 18, 2025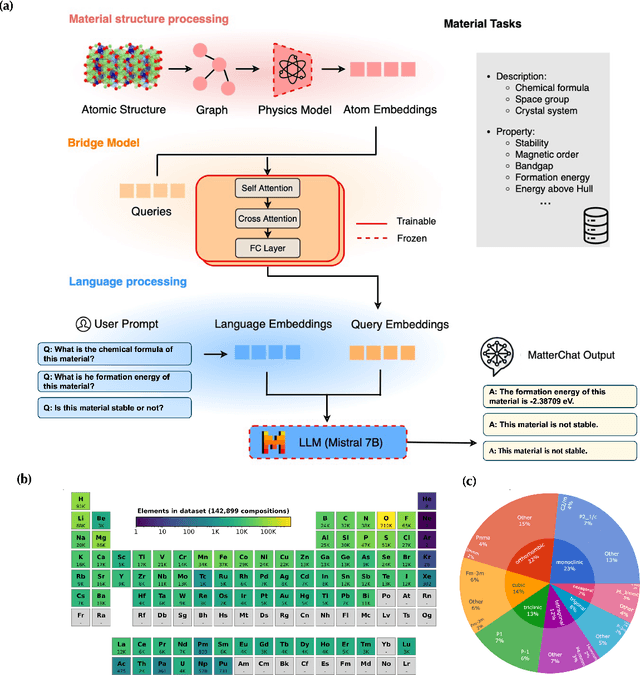

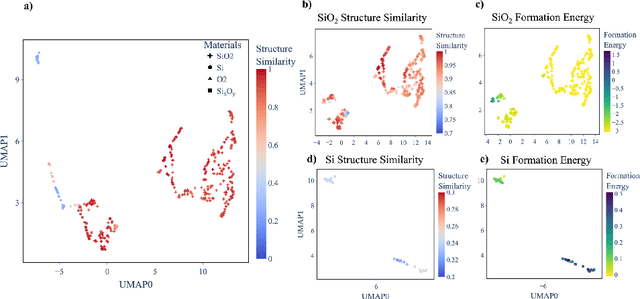
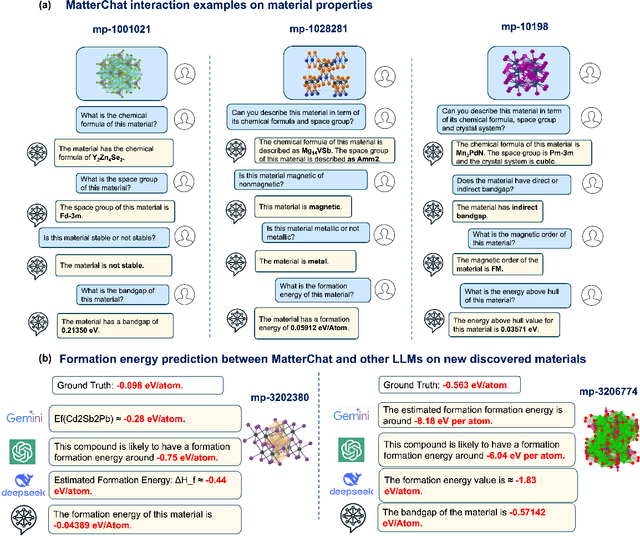
Understanding and predicting the properties of inorganic materials is crucial for accelerating advancements in materials science and driving applications in energy, electronics, and beyond. Integrating material structure data with language-based information through multi-modal large language models (LLMs) offers great potential to support these efforts by enhancing human-AI interaction. However, a key challenge lies in integrating atomic structures at full resolution into LLMs. In this work, we introduce MatterChat, a versatile structure-aware multi-modal LLM that unifies material structural data and textual inputs into a single cohesive model. MatterChat employs a bridging module to effectively align a pretrained machine learning interatomic potential with a pretrained LLM, reducing training costs and enhancing flexibility. Our results demonstrate that MatterChat significantly improves performance in material property prediction and human-AI interaction, surpassing general-purpose LLMs such as GPT-4. We also demonstrate its usefulness in applications such as more advanced scientific reasoning and step-by-step material synthesis.
Powerformer: A Transformer with Weighted Causal Attention for Time-series Forecasting
Feb 10, 2025Transformers have recently shown strong performance in time-series forecasting, but their all-to-all attention mechanism overlooks the (temporal) causal and often (temporally) local nature of data. We introduce Powerformer, a novel Transformer variant that replaces noncausal attention weights with causal weights that are reweighted according to a smooth heavy-tailed decay. This simple yet effective modification endows the model with an inductive bias favoring temporally local dependencies, while still allowing sufficient flexibility to learn the unique correlation structure of each dataset. Our empirical results demonstrate that Powerformer not only achieves state-of-the-art accuracy on public time-series benchmarks, but also that it offers improved interpretability of attention patterns. Our analyses show that the model's locality bias is amplified during training, demonstrating an interplay between time-series data and power-law-based attention. These findings highlight the importance of domain-specific modifications to the Transformer architecture for time-series forecasting, and they establish Powerformer as a strong, efficient, and principled baseline for future research and real-world applications.
Neural equilibria for long-term prediction of nonlinear conservation laws
Jan 12, 2025We introduce Neural Discrete Equilibrium (NeurDE), a machine learning (ML) approach for long-term forecasting of flow phenomena that relies on a "lifting" of physical conservation laws into the framework of kinetic theory. The kinetic formulation provides an excellent structure for ML algorithms by separating nonlinear, non-local physics into a nonlinear but local relaxation to equilibrium and a linear non-local transport. This separation allows the ML to focus on the local nonlinear components while addressing the simpler linear transport with efficient classical numerical algorithms. To accomplish this, we design an operator network that maps macroscopic observables to equilibrium states in a manner that maximizes entropy, yielding expressive BGK-type collisions. By incorporating our surrogate equilibrium into the lattice Boltzmann (LB) algorithm, we achieve accurate flow forecasts for a wide range of challenging flows. We show that NeurDE enables accurate prediction of compressible flows, including supersonic flows, while tracking shocks over hundreds of time steps, using a small velocity lattice-a heretofore unattainable feat without expensive numerical root finding.
Using Pre-trained LLMs for Multivariate Time Series Forecasting
Jan 10, 2025



Pre-trained Large Language Models (LLMs) encapsulate large amounts of knowledge and take enormous amounts of compute to train. We make use of this resource, together with the observation that LLMs are able to transfer knowledge and performance from one domain or even modality to another seemingly-unrelated area, to help with multivariate demand time series forecasting. Attention in transformer-based methods requires something worth attending to -- more than just samples of a time-series. We explore different methods to map multivariate input time series into the LLM token embedding space. In particular, our novel multivariate patching strategy to embed time series features into decoder-only pre-trained Transformers produces results competitive with state-of-the-art time series forecasting models. We also use recently-developed weight-based diagnostics to validate our findings.