 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScene Retrieval for Contextual Visual Mapping
Feb 25, 2021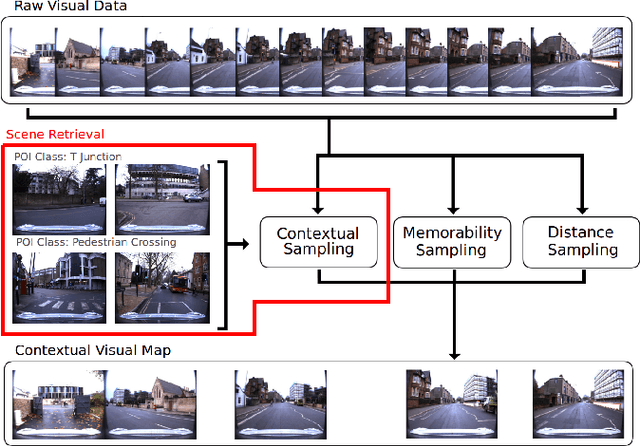

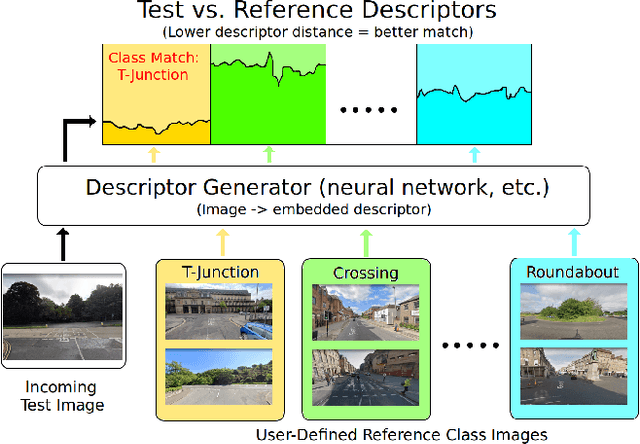
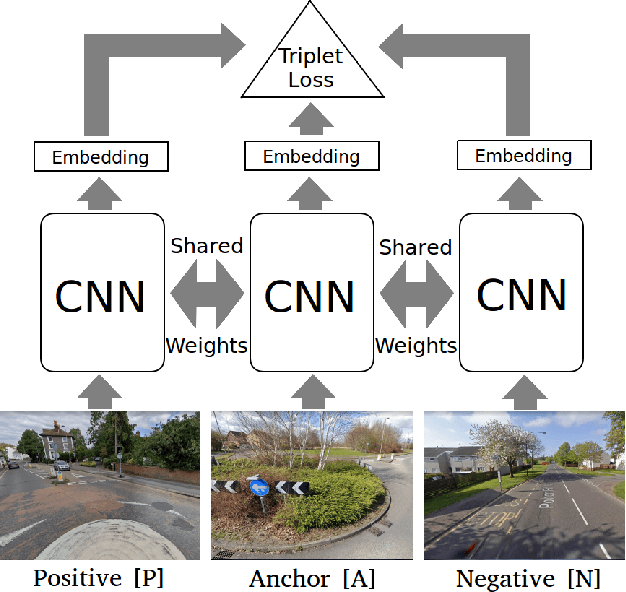
Visual navigation localizes a query place image against a reference database of place images, also known as a `visual map'. Localization accuracy requirements for specific areas of the visual map, `scene classes', vary according to the context of the environment and task. State-of-the-art visual mapping is unable to reflect these requirements by explicitly targetting scene classes for inclusion in the map. Four different scene classes, including pedestrian crossings and stations, are identified in each of the Nordland and St. Lucia datasets. Instead of re-training separate scene classifiers which struggle with these overlapping scene classes we make our first contribution: defining the problem of `scene retrieval'. Scene retrieval extends image retrieval to classification of scenes defined at test time by associating a single query image to reference images of scene classes. Our second contribution is a triplet-trained convolutional neural network (CNN) to address this problem which increases scene classification accuracy by up to 7% against state-of-the-art networks pre-trained for scene recognition. The second contribution is an algorithm `DMC' that combines our scene classification with distance and memorability for visual mapping. Our analysis shows that DMC includes 64% more images of our chosen scene classes in a visual map than just using distance interval mapping. State-of-the-art visual place descriptors AMOS-Net, Hybrid-Net and NetVLAD are finally used to show that DMC improves scene class localization accuracy by a mean of 3% and localization accuracy of the remaining map images by a mean of 10% across both datasets.
SeqNet: Learning Descriptors for Sequence-based Hierarchical Place Recognition
Feb 24, 2021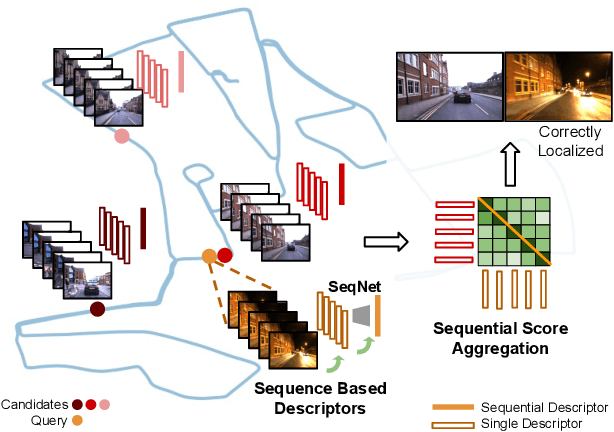
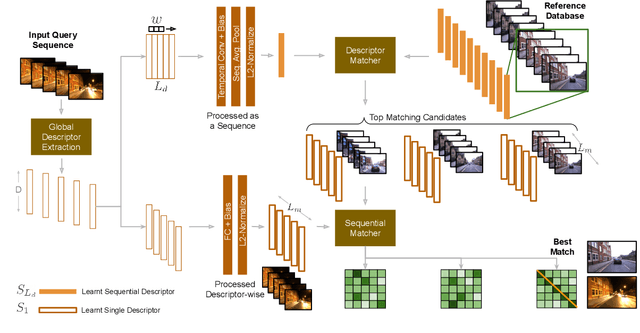
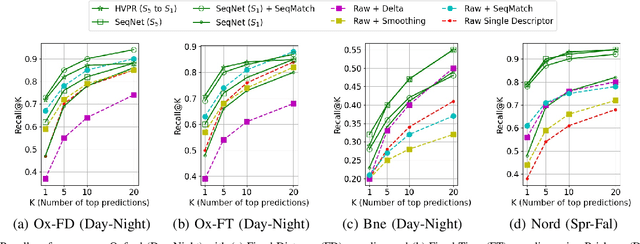
Visual Place Recognition (VPR) is the task of matching current visual imagery from a camera to images stored in a reference map of the environment. While initial VPR systems used simple direct image methods or hand-crafted visual features, recent work has focused on learning more powerful visual features and further improving performance through either some form of sequential matcher / filter or a hierarchical matching process. In both cases the performance of the initial single-image based system is still far from perfect, putting significant pressure on the sequence matching or (in the case of hierarchical systems) pose refinement stages. In this paper we present a novel hybrid system that creates a high performance initial match hypothesis generator using short learnt sequential descriptors, which enable selective control sequential score aggregation using single image learnt descriptors. Sequential descriptors are generated using a temporal convolutional network dubbed SeqNet, encoding short image sequences using 1-D convolutions, which are then matched against the corresponding temporal descriptors from the reference dataset to provide an ordered list of place match hypotheses. We then perform selective sequential score aggregation using shortlisted single image learnt descriptors from a separate pipeline to produce an overall place match hypothesis. Comprehensive experiments on challenging benchmark datasets demonstrate the proposed method outperforming recent state-of-the-art methods using the same amount of sequential information. Source code and supplementary material can be found at https://github.com/oravus/seqNet.
Improving Visual Place Recognition Performance by Maximising Complementarity
Feb 16, 2021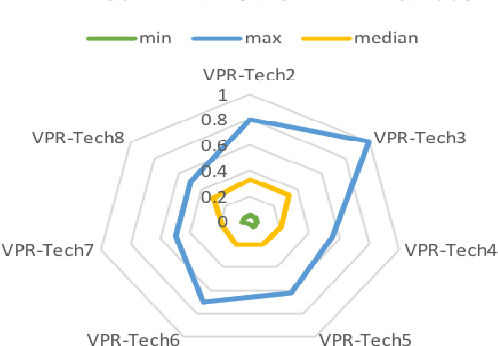
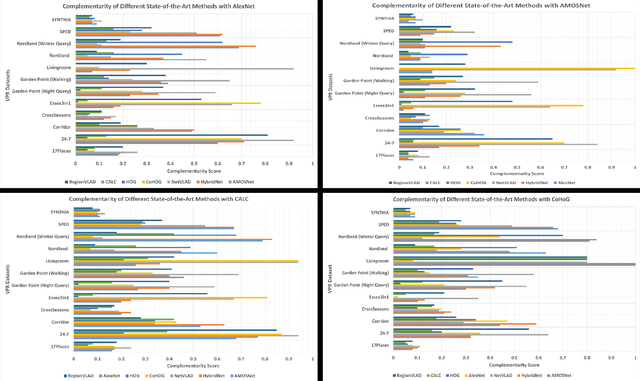
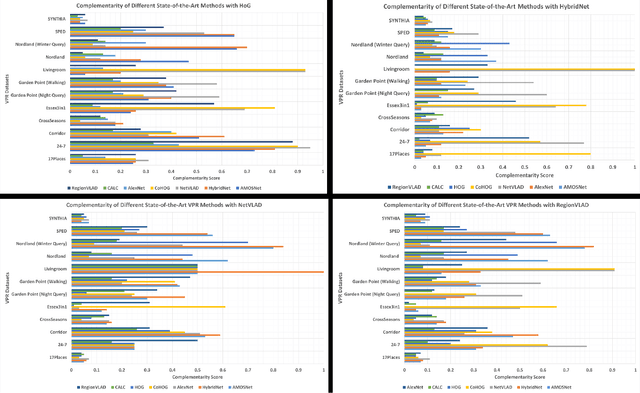
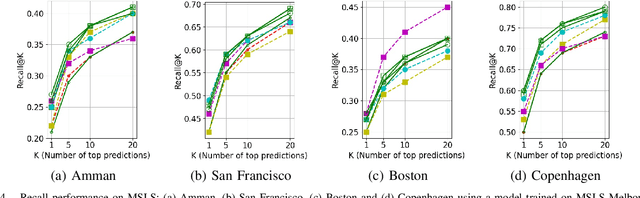
Visual place recognition (VPR) is the problem of recognising a previously visited location using visual information. Many attempts to improve the performance of VPR methods have been made in the literature. One approach that has received attention recently is the multi-process fusion where different VPR methods run in parallel and their outputs are combined in an effort to achieve better performance. The multi-process fusion, however, does not have a well-defined criterion for selecting and combining different VPR methods from a wide range of available options. To the best of our knowledge, this paper investigates the complementarity of state-of-the-art VPR methods systematically for the first time and identifies those combinations which can result in better performance. The paper presents a well-defined framework which acts as a sanity check to find the complementarity between two techniques by utilising a McNemar's test-like approach. The framework allows estimation of upper and lower complementarity bounds for the VPR techniques to be combined, along with an estimate of maximum VPR performance that may be achieved. Based on this framework, results are presented for eight state-of-the-art VPR methods on ten widely-used VPR datasets showing the potential of different combinations of techniques for achieving better performance.
Semantics for Robotic Mapping, Perception and Interaction: A Survey
Jan 02, 2021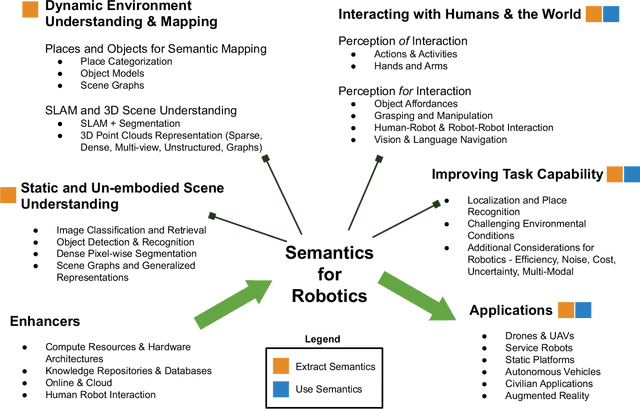
For robots to navigate and interact more richly with the world around them, they will likely require a deeper understanding of the world in which they operate. In robotics and related research fields, the study of understanding is often referred to as semantics, which dictates what does the world "mean" to a robot, and is strongly tied to the question of how to represent that meaning. With humans and robots increasingly operating in the same world, the prospects of human-robot interaction also bring semantics and ontology of natural language into the picture. Driven by need, as well as by enablers like increasing availability of training data and computational resources, semantics is a rapidly growing research area in robotics. The field has received significant attention in the research literature to date, but most reviews and surveys have focused on particular aspects of the topic: the technical research issues regarding its use in specific robotic topics like mapping or segmentation, or its relevance to one particular application domain like autonomous driving. A new treatment is therefore required, and is also timely because so much relevant research has occurred since many of the key surveys were published. This survey therefore provides an overarching snapshot of where semantics in robotics stands today. We establish a taxonomy for semantics research in or relevant to robotics, split into four broad categories of activity, in which semantics are extracted, used, or both. Within these broad categories we survey dozens of major topics including fundamentals from the computer vision field and key robotics research areas utilizing semantics, including mapping, navigation and interaction with the world. The survey also covers key practical considerations, including enablers like increased data availability and improved computational hardware, and major application areas where...
* 81 pages, 1 figure, published in Foundations and Trends in Robotics, 2020
DeepSeqSLAM: A Trainable CNN+RNN for Joint Global Description and Sequence-based Place Recognition
Nov 17, 2020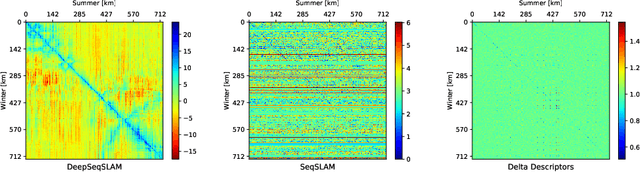
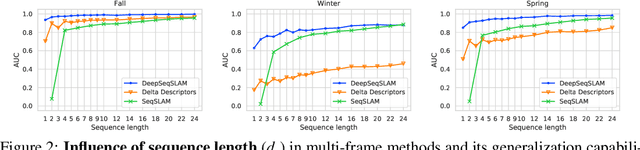

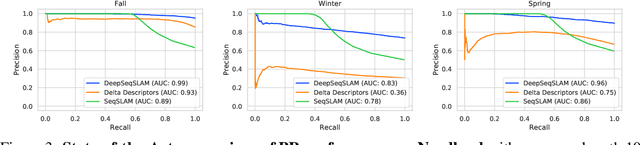
Sequence-based place recognition methods for all-weather navigation are well-known for producing state-of-the-art results under challenging day-night or summer-winter transitions. These systems, however, rely on complex handcrafted heuristics for sequential matching - which are applied on top of a pre-computed pairwise similarity matrix between reference and query image sequences of a single route - to further reduce false-positive rates compared to single-frame retrieval methods. As a result, performing multi-frame place recognition can be extremely slow for deployment on autonomous vehicles or evaluation on large datasets, and fail when using relatively short parameter values such as a sequence length of 2 frames. In this paper, we propose DeepSeqSLAM: a trainable CNN+RNN architecture for jointly learning visual and positional representations from a single monocular image sequence of a route. We demonstrate our approach on two large benchmark datasets, Nordland and Oxford RobotCar - recorded over 728 km and 10 km routes, respectively, each during 1 year with multiple seasons, weather, and lighting conditions. On Nordland, we compare our method to two state-of-the-art sequence-based methods across the entire route under summer-winter changes using a sequence length of 2 and show that our approach can get over 72% AUC compared to 27% AUC for Delta Descriptors and 2% AUC for SeqSLAM; while drastically reducing the deployment time from around 1 hour to 1 minute against both. The framework code and video are available at https://mchancan.github.io/deepseqslam
* 9 pages, 6 figures, 2 tables
Fast and Robust Bio-inspired Teach and Repeat Navigation
Oct 21, 2020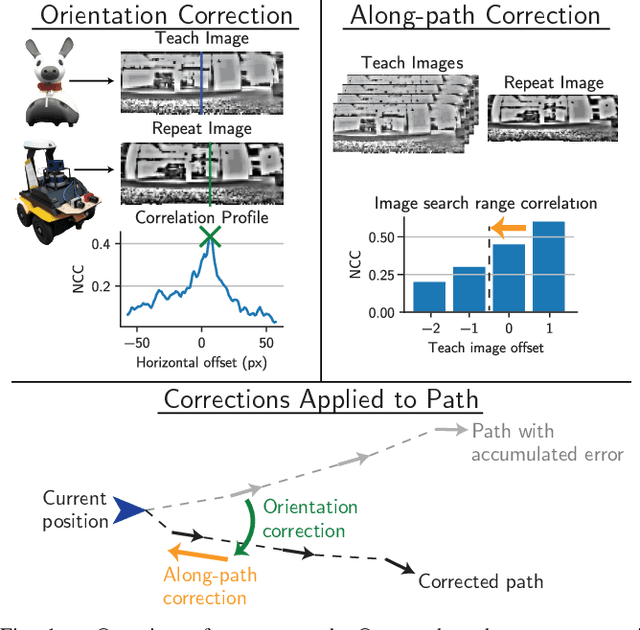
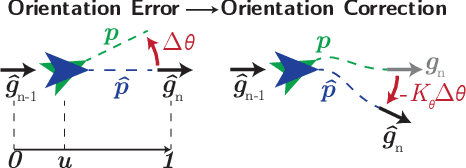
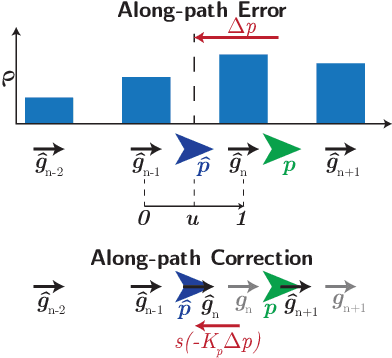

Fully autonomous mobile robots have a multitude of potential applications, but guaranteeing robust navigation performance remains an open research problem. For many tasks such as repeated infrastructure inspection, item delivery or inventory transport, a route repeating capability rather than full navigation stack can be sufficient and offers potential practical advantages. Previous teach and repeat research has achieved high performance in difficult conditions generally by using sophisticated, often expensive sensors, and has often had high computational requirements. Biological systems, such as small animals and insects like seeing ants, offer a proof of concept that robust and generalisable navigation can be achieved with extremely limited visual systems and computing power. In this work we create a novel asynchronous formulation for teach and repeat navigation that fully utilises odometry information, paired with a correction signal driven by much more computationally lightweight visual processing than is typically required. This correction signal is also decoupled from the robot's motor control, allowing its rate to be modulated by the available computing capacity. We evaluate this approach with extensive experimentation on two different robotic platforms, the Consequential Robotics Miro and the Clearpath Jackal robots, across navigation trials totalling more than 6000 metres in a range of challenging indoor and outdoor environments. Our approach is more robust and requires significantly less compute than the state-of-the-art. It is also capable of intervention-free -- no parameter changes required -- cross-platform generalisation, learning to navigate a route on one robot and repeating that route on a different type of robot with different camera.
Intelligent Reference Curation for Visual Place Recognition via Bayesian Selective Fusion
Oct 19, 2020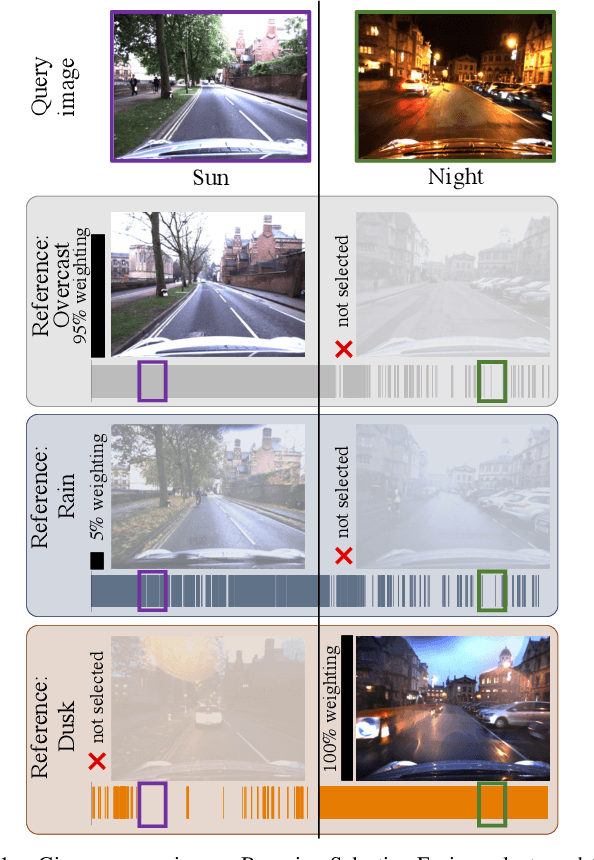
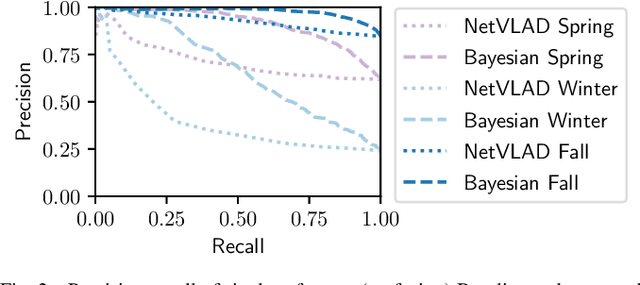
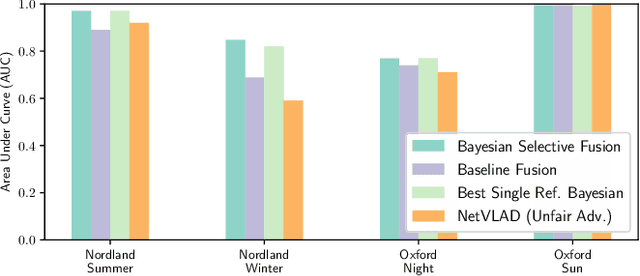
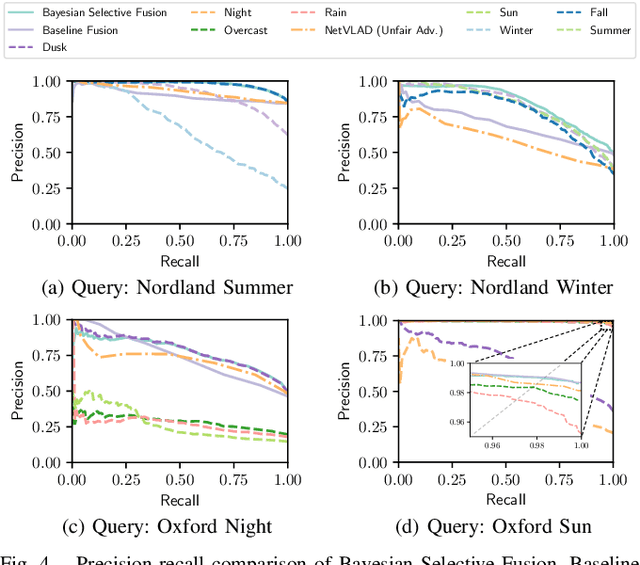
The key challenge of visual place recognition (VPR) lies in recognizing places despite drastic visual appearance changes due to factors such as time of day, season, or weather or lighting conditions. Numerous approaches based on deep-learnt image descriptors, sequence matching, domain translation, and probabilistic localization have had success in addressing this challenge, but most rely on the availability of carefully curated representative reference images of the possible places. In this paper, we propose a novel approach, dubbed Bayesian Selective Fusion, for actively selecting and fusing informative reference images to determine the best place match for a given query image. The selective element of our approach avoids the counterproductive fusion of every reference image and enables the dynamic selection of informative reference images in environments with changing visual conditions (such as indoors with flickering lights, outdoors during sunshowers or over the day-night cycle). The probabilistic element of our approach provides a means of fusing multiple reference images that accounts for their varying uncertainty via a novel training-free likelihood function for VPR. On difficult query images from two benchmark datasets, we demonstrate that our approach matches and exceeds the performance of several alternative fusion approaches along with state-of-the-art techniques that are provided with a priori (unfair) knowledge of the best reference images. Our approach is well suited for long-term robot autonomy where dynamic visual environments are commonplace since it is training-free, descriptor-agnostic, and complements existing techniques such as sequence matching.
Binary Neural Networks for Memory-Efficient and Effective Visual Place Recognition in Changing Environments
Oct 01, 2020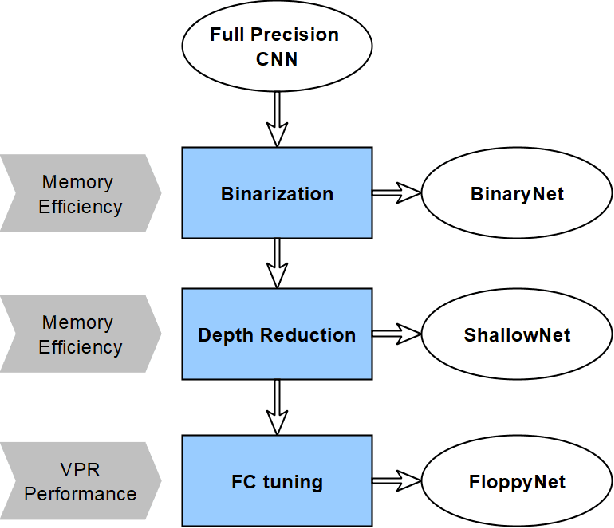
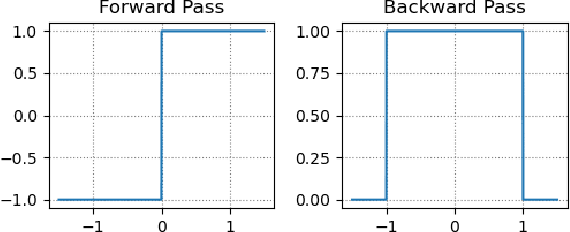
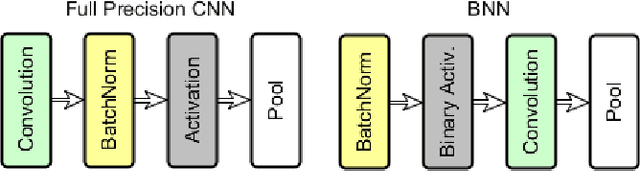
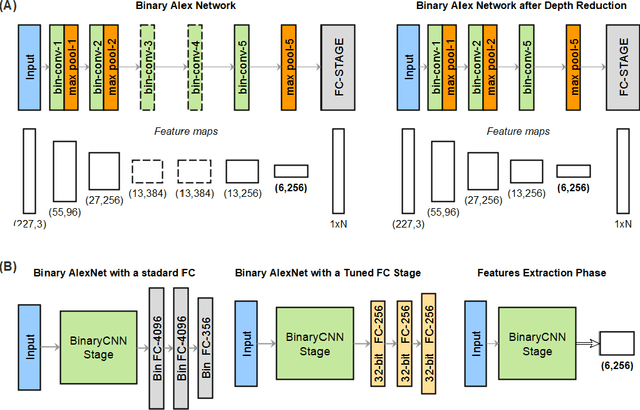
Visual place recognition (VPR) is a robot's ability to determine whether a place was visited before using visual data. While conventional hand-crafted methods for VPR fail under extreme environmental appearance changes, those based on convolutional neural networks (CNNs) achieve state-of-the-art performance but result in model sizes that demand a large amount of memory. Hence, CNN-based approaches are unsuitable for memory-constrained platforms, such as small robots and drones. In this paper, we take a multi-step approach of decreasing the precision of model parameters, combining it with network depth reduction and fewer neurons in the classifier stage to propose a new class of highly compact models that drastically reduce the memory requirements while maintaining state-of-the-art VPR performance, and can be tuned to various platforms and application scenarios. To the best of our knowledge, this is the first attempt to propose binary neural networks for solving the visual place recognition problem effectively under changing conditions and with significantly reduced memory requirements. Our best-performing binary neural network with a minimum number of layers, dubbed FloppyNet, achieves comparable VPR performance when considered against its full precision and deeper counterparts while consuming 99% less memory.
ConvSequential-SLAM: A Sequence-based, Training-less Visual Place Recognition Technique for Changing Environments
Sep 28, 2020


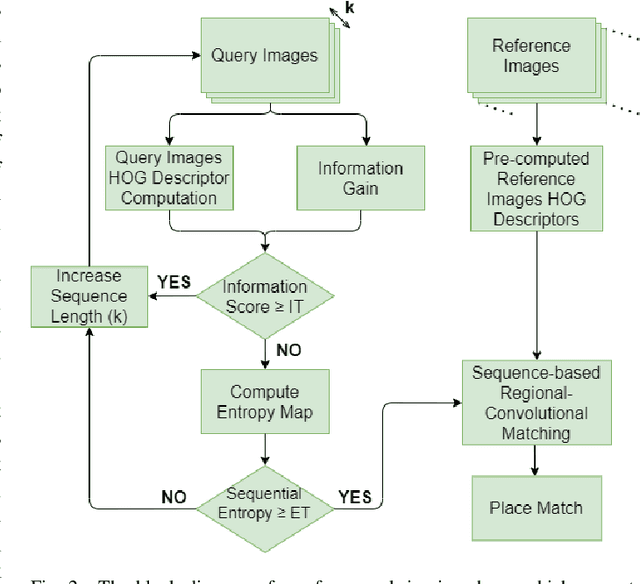
Visual Place Recognition (VPR) is the ability to correctly recall a previously visited place under changing viewpoints and appearances. A large number of handcrafted and deep-learning-based VPR techniques exist, where the former suffer from appearance changes and the latter have significant computational needs. In this paper, we present a new handcrafted VPR technique that achieves state-of-the-art place matching performance under challenging conditions. Our technique combines the best of 2 existing trainingless VPR techniques, SeqSLAM and CoHOG, which are each robust to conditional and viewpoint changes, respectively. This blend, namely ConvSequential-SLAM, utilises sequential information and block-normalisation to handle appearance changes, while using regional-convolutional matching to achieve viewpoint-invariance. We analyse content-overlap in-between query frames to find a minimum sequence length, while also re-using the image entropy information for environment-based sequence length tuning. State-of-the-art performance is reported in contrast to 8 contemporary VPR techniques on 4 public datasets. Qualitative insights and an ablation study on sequence length are also provided.
Robot Perception enables Complex Navigation Behavior via Self-Supervised Learning
Jun 16, 2020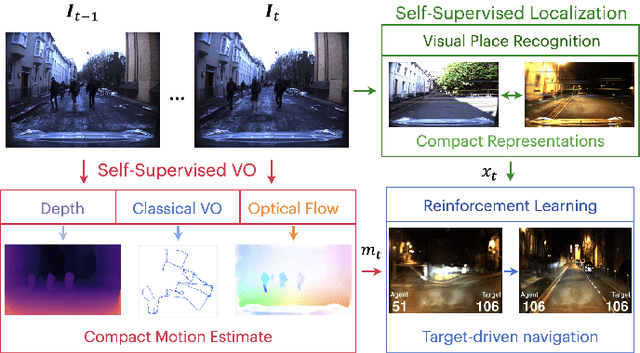


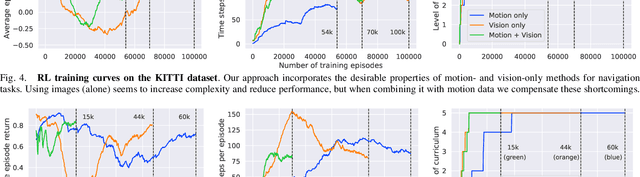
Learning visuomotor control policies in robotic systems is a fundamental problem when aiming for long-term behavioral autonomy. Recent supervised-learning-based vision and motion perception systems, however, are often separately built with limited capabilities, while being restricted to few behavioral skills such as passive visual odometry (VO) or mobile robot visual localization. Here we propose an approach to unify those successful robot perception systems for active target-driven navigation tasks via reinforcement learning (RL). Our method temporally incorporates compact motion and visual perception data - directly obtained using self-supervision from a single image sequence - to enable complex goal-oriented navigation skills. We demonstrate our approach on two real-world driving dataset, KITTI and Oxford RobotCar, using the new interactive CityLearn framework. The results show that our method can accurately generalize to extreme environmental changes such as day to night cycles with up to an 80% success rate, compared to 30% for a vision-only navigation systems.