 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Learning Rates and Schrödinger Operators
Apr 15, 2020
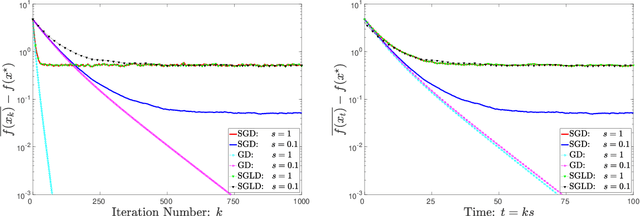
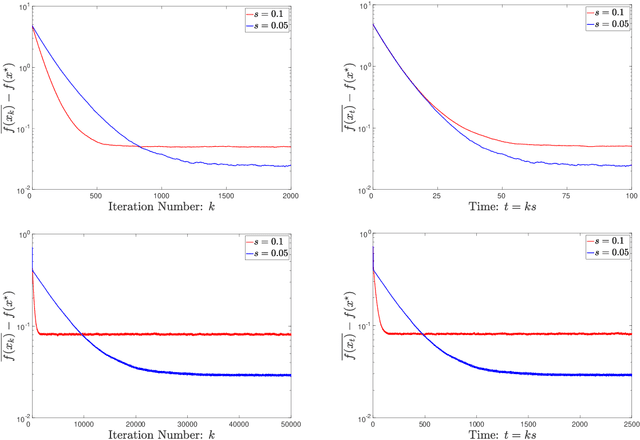
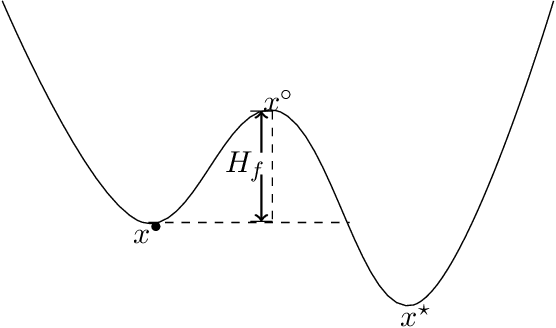
The learning rate is perhaps the single most important parameter in the training of neural networks and, more broadly, in stochastic (nonconvex) optimization. Accordingly, there are numerous effective, but poorly understood, techniques for tuning the learning rate, including learning rate decay, which starts with a large initial learning rate that is gradually decreased. In this paper, we present a general theoretical analysis of the effect of the learning rate in stochastic gradient descent (SGD). Our analysis is based on the use of a learning-rate-dependent stochastic differential equation (lr-dependent SDE) that serves as a surrogate for SGD. For a broad class of objective functions, we establish a linear rate of convergence for this continuous-time formulation of SGD, highlighting the fundamental importance of the learning rate in SGD, and contrasting to gradient descent and stochastic gradient Langevin dynamics. Moreover, we obtain an explicit expression for the optimal linear rate by analyzing the spectrum of the Witten-Laplacian, a special case of the Schr\"odinger operator associated with the lr-dependent SDE. Strikingly, this expression clearly reveals the dependence of the linear convergence rate on the learning rate -- the linear rate decreases rapidly to zero as the learning rate tends to zero for a broad class of nonconvex functions, whereas it stays constant for strongly convex functions. Based on this sharp distinction between nonconvex and convex problems, we provide a mathematical interpretation of the benefits of using learning rate decay for nonconvex optimization.
On Dissipative Symplectic Integration with Applications to Gradient-Based Optimization
Apr 15, 2020
Continuous-time dynamical systems have proved useful in providing conceptual and quantitative insights into gradient-based optimization. An important question that arises in this line of work is how to discretize the continuous-time system in such a way that its stability and rates of convergence are preserved. In this paper we propose a geometric framework in which such discretizations can be realized systematically, enabling the derivation of rate-matching optimization algorithms without the need for a discrete-time convergence analysis. More specifically, we show that a generalization of symplectic integrators to dissipative Hamiltonian systems is able to preserve continuous-time rates of convergence up to a controlled error. Our arguments rely on a combination of backward-error analysis with fundamental results from symplectic geometry.
On Linear Stochastic Approximation: Fine-grained Polyak-Ruppert and Non-Asymptotic Concentration
Apr 09, 2020We undertake a precise study of the asymptotic and non-asymptotic properties of stochastic approximation procedures with Polyak-Ruppert averaging for solving a linear system $\bar{A} \theta = \bar{b}$. When the matrix $\bar{A}$ is Hurwitz, we prove a central limit theorem (CLT) for the averaged iterates with fixed step size and number of iterations going to infinity. The CLT characterizes the exact asymptotic covariance matrix, which is the sum of the classical Polyak-Ruppert covariance and a correction term that scales with the step size. Under assumptions on the tail of the noise distribution, we prove a non-asymptotic concentration inequality whose main term matches the covariance in CLT in any direction, up to universal constants. When the matrix $\bar{A}$ is not Hurwitz but only has non-negative real parts in its eigenvalues, we prove that the averaged LSA procedure actually achieves an $O(1/T)$ rate in mean-squared error. Our results provide a more refined understanding of linear stochastic approximation in both the asymptotic and non-asymptotic settings. We also show various applications of the main results, including the study of momentum-based stochastic gradient methods as well as temporal difference algorithms in reinforcement learning.
Finite-Time Last-Iterate Convergence for Multi-Agent Learning in Games
Mar 18, 2020We consider multi-agent learning via online gradient descent (OGD) in a class of games called $\lambda$-cocoercive games, a broad class of games that admits many Nash equilibria and that properly includes strongly monotone games. We characterize the finite-time last-iterate convergence rate for joint OGD learning on $\lambda$-cocoercive games; further, building on this result, we develop a fully adaptive OGD learning algorithm that does not require any knowledge of the problem parameter (e.g., the cocoercive constant $\lambda$) and show, via a novel double-stopping-time technique, that this adaptive algorithm achieves the same finite-time last-iterate convergence rate as its non-adaptive counterpart. Subsequently, we extend OGD learning to the noisy gradient feedback case and establish last-iterate convergence results---first qualitative almost sure convergence, then quantitative finite-time convergence rates---all under non-decreasing step-sizes. These results fill in several gaps in the existing multi-agent online learning literature, where three aspects---finite-time convergence rates, non-decreasing step-sizes, and fully adaptive algorithms---have not been previously explored.
Revisiting Fixed Support Wasserstein Barycenter: Computational Hardness and Efficient Algorithms
Mar 18, 2020
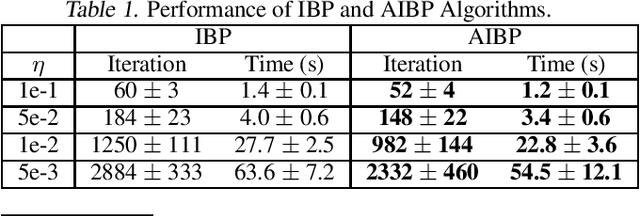
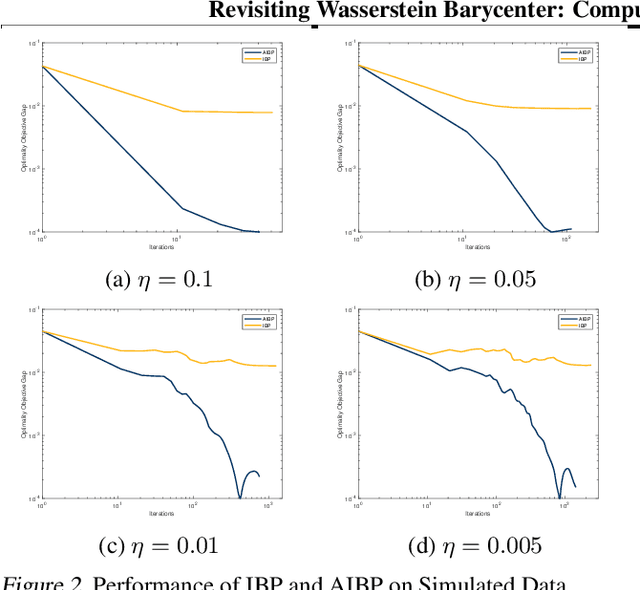
We study the fixed-support Wasserstein barycenter problem (FS-WBP), which consists in computing the Wasserstein barycenter of $m$ discrete probability measures supported on a finite metric space of size $n$. We show first that the constraint matrix arising from the linear programming (LP) representation of the FS-WBP is totally unimodular when $m \geq 3$ and $n = 2$, but not totally unimodular when $m \geq 3$ and $n \geq 3$. This result answers an open problem, since it shows that the FS-WBP is not a minimum-cost flow problem and therefore cannot be solved efficiently using linear programming. Building on this negative result, we propose and analyze a simple and efficient variant of the iterative Bregman projection (IBP) algorithm, currently the most widely adopted algorithm to solve the FS-WBP. The algorithm is an accelerated IBP algorithm which achieves the complexity bound of $\widetilde{\mathcal{O}}(mn^{7/3}/\varepsilon)$. This bound is better than that obtained for the standard IBP algorithm---$\widetilde{\mathcal{O}}(mn^{2}/\varepsilon^2)$---in terms of $\varepsilon$, and that of accelerated primal-dual gradient algorithm---$\widetilde{\mathcal{O}}(mn^{5/2}/\varepsilon)$---in terms of $n$. Empirical study demonstrates that the acceleration promised by the theory is real in practice.
Is Temporal Difference Learning Optimal? An Instance-Dependent Analysis
Mar 16, 2020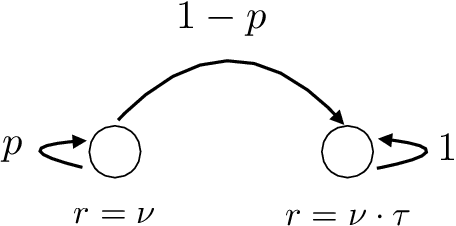
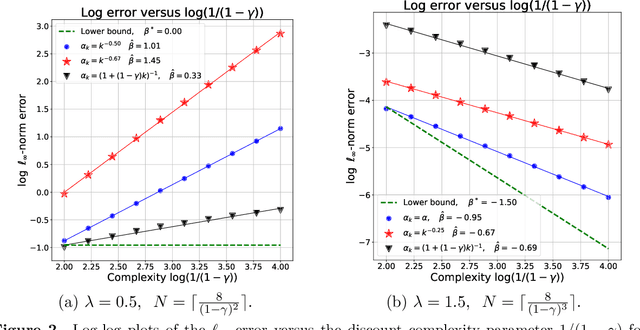
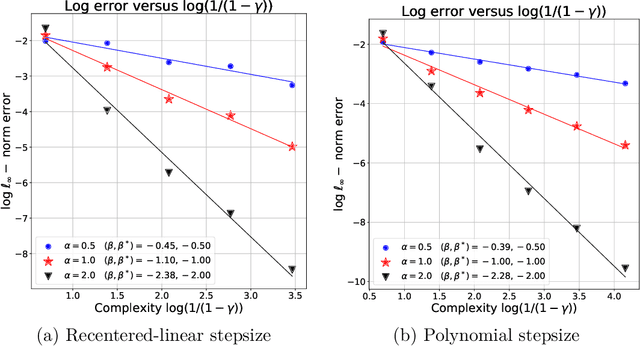
We address the problem of policy evaluation in discounted Markov decision processes, and provide instance-dependent guarantees on the $\ell_\infty$-error under a generative model. We establish both asymptotic and non-asymptotic versions of local minimax lower bounds for policy evaluation, thereby providing an instance-dependent baseline by which to compare algorithms. Theory-inspired simulations show that the widely-used temporal difference (TD) algorithm is strictly suboptimal when evaluated in a non-asymptotic setting, even when combined with Polyak-Ruppert iterate averaging. We remedy this issue by introducing and analyzing variance-reduced forms of stochastic approximation, showing that they achieve non-asymptotic, instance-dependent optimality up to logarithmic factors.
Post-Estimation Smoothing: A Simple Baseline for Learning with Side Information
Mar 12, 2020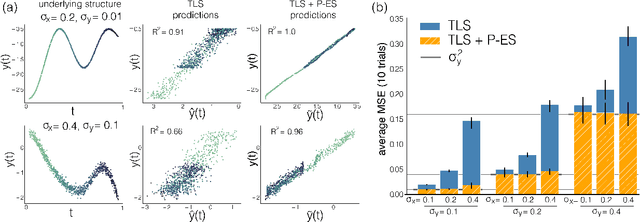
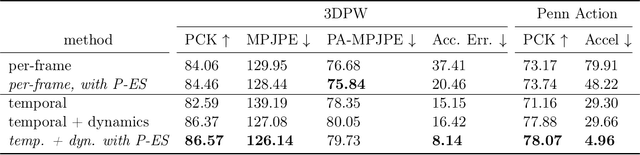
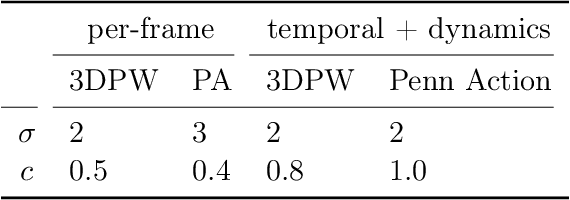
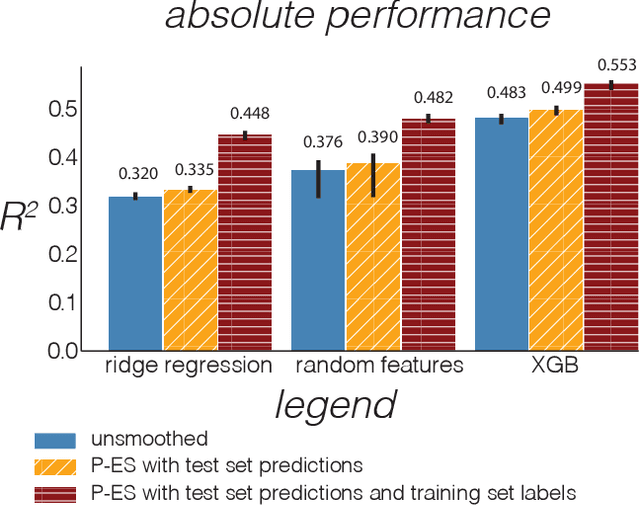
Observational data are often accompanied by natural structural indices, such as time stamps or geographic locations, which are meaningful to prediction tasks but are often discarded. We leverage semantically meaningful indexing data while ensuring robustness to potentially uninformative or misleading indices. We propose a post-estimation smoothing operator as a fast and effective method for incorporating structural index data into prediction. Because the smoothing step is separate from the original predictor, it applies to a broad class of machine learning tasks, with no need to retrain models. Our theoretical analysis details simple conditions under which post-estimation smoothing will improve accuracy over that of the original predictor. Our experiments on large scale spatial and temporal datasets highlight the speed and accuracy of post-estimation smoothing in practice. Together, these results illuminate a novel way to consider and incorporate the natural structure of index variables in machine learning.
Robustness Guarantees for Mode Estimation with an Application to Bandits
Mar 05, 2020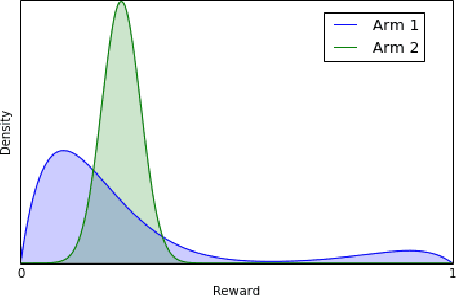



Mode estimation is a classical problem in statistics with a wide range of applications in machine learning. Despite this, there is little understanding in its robustness properties under possibly adversarial data contamination. In this paper, we give precise robustness guarantees as well as privacy guarantees under simple randomization. We then introduce a theory for multi-armed bandits where the values are the modes of the reward distributions instead of the mean. We prove regret guarantees for the problems of top arm identification, top m-arms identification, contextual modal bandits, and infinite continuous arms top arm recovery. We show in simulations that our algorithms are robust to perturbation of the arms by adversarial noise sequences, thus rendering modal bandits an attractive choice in situations where the rewards may have outliers or adversarial corruptions.
Optimization with Momentum: Dynamical, Control-Theoretic, and Symplectic Perspectives
Feb 28, 2020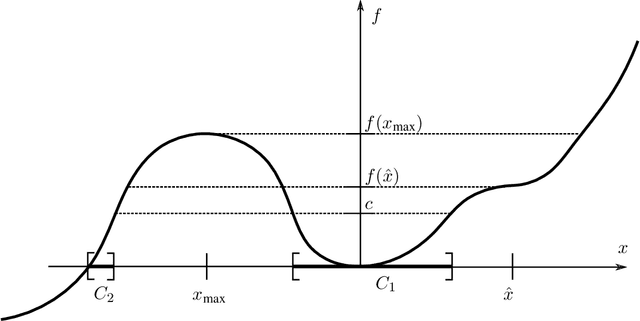
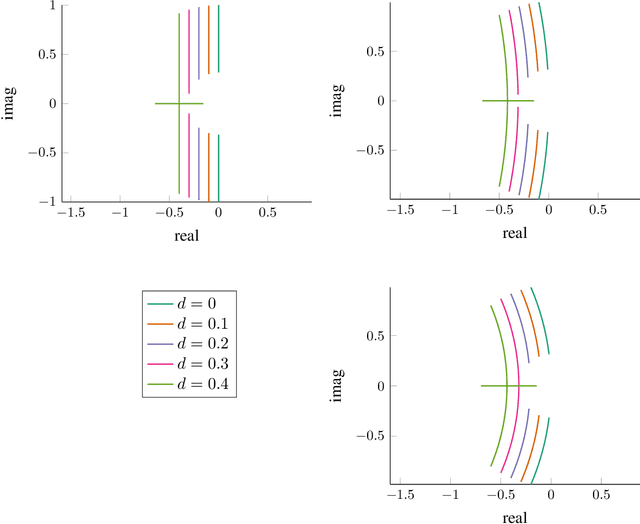
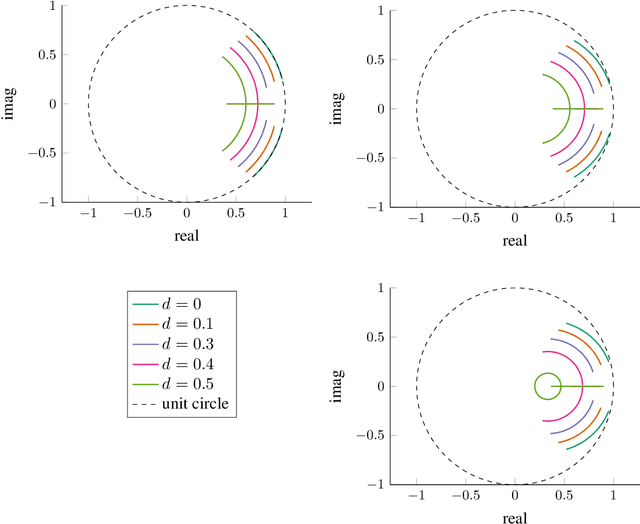
We analyze the convergence rate of various momentum-based optimization algorithms from a dynamical systems point of view. Our analysis exploits fundamental topological properties, such as the continuous dependence of iterates on their initial conditions, to provide a simple characterization of convergence rates. In many cases, closed-form expressions are obtained that relate algorithm parameters to the convergence rate. The analysis encompasses discrete time and continuous time, as well as time-invariant and time-variant formulations, and is not limited to a convex or Euclidean setting. In addition, the article rigorously establishes why symplectic discretization schemes are important for momentum-based optimization algorithms, and provides a characterization of algorithms that exhibit accelerated convergence.
Provable Meta-Learning of Linear Representations
Feb 26, 2020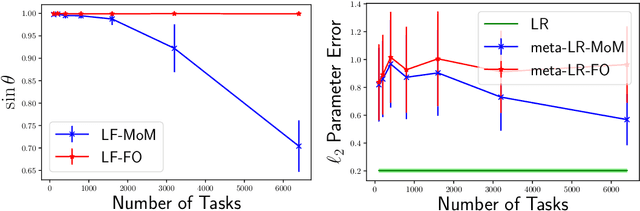
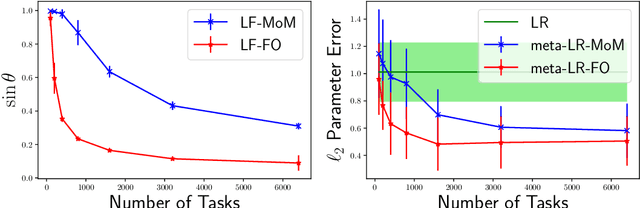
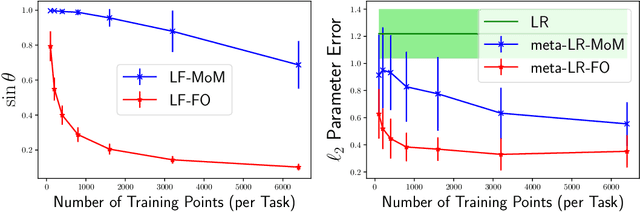
Meta-learning, or learning-to-learn, seeks to design algorithms that can utilize previous experience to rapidly learn new skills or adapt to new environments. Representation learning---a key tool for performing meta-learning---learns a data representation that can transfer knowledge across multiple tasks, which is essential in regimes where data is scarce. Despite a recent surge of interest in the practice of meta-learning, the theoretical underpinnings of meta-learning algorithms are lacking, especially in the context of learning transferable representations. In this paper, we focus on the problem of multi-task linear regression---in which multiple linear regression models share a common, low-dimensional linear representation. Here, we provide provably fast, sample-efficient algorithms to address the dual challenges of (1) learning a common set of features from multiple, related tasks, and (2) transferring this knowledge to new, unseen tasks. Both are central to the general problem of meta-learning. Finally, we complement these results by providing information-theoretic lower bounds on the sample complexity of learning these linear features, showing that our algorithms are optimal up to logarithmic factors.