 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWasserstein Reinforcement Learning
Paper and Code

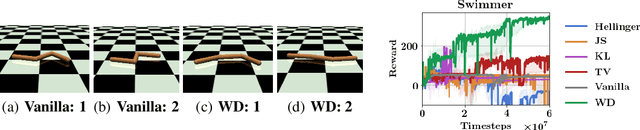
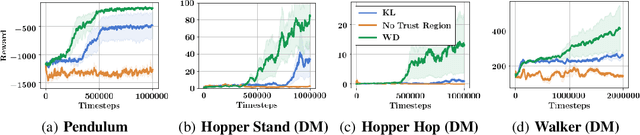
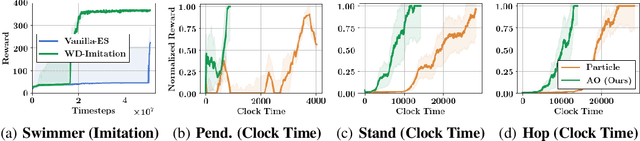
We propose behavior-driven optimization via Wasserstein distances (WDs) to improve several classes of state-of-the-art reinforcement learning (RL) algorithms. We show that WD regularizers acting on appropriate policy embeddings efficiently incorporate behavioral characteristics into policy optimization. We demonstrate that they improve Evolution Strategy methods by encouraging more efficient exploration, can be applied in imitation learning and to speed up training of Trust Region Policy Optimization methods. Since the exact computation of WDs is expensive, we develop approximate algorithms based on the combination of different methods: dual formulation of the optimal transport problem, alternating optimization and random feature maps, to effectively replace exact WD computations in the RL tasks considered. We provide theoretical analysis of our algorithms and exhaustive empirical evaluation in a variety of RL settings.