 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEntity Abstraction in Visual Model-Based Reinforcement Learning
Dec 04, 2019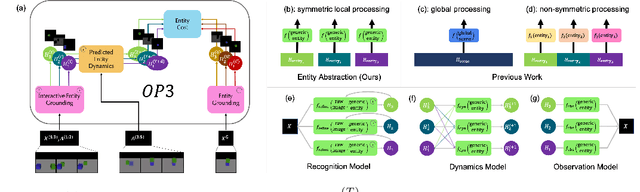
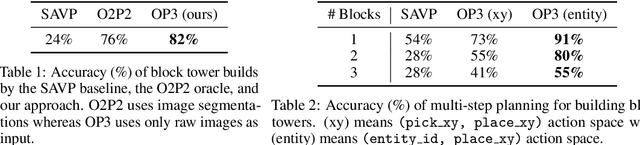
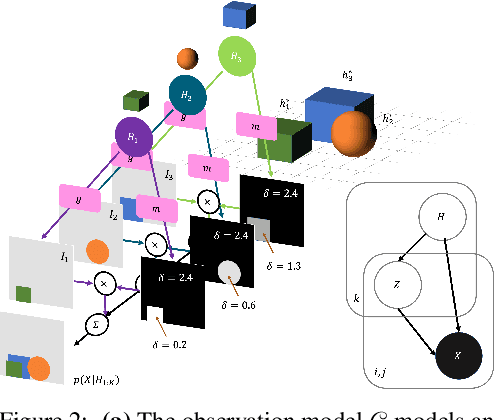
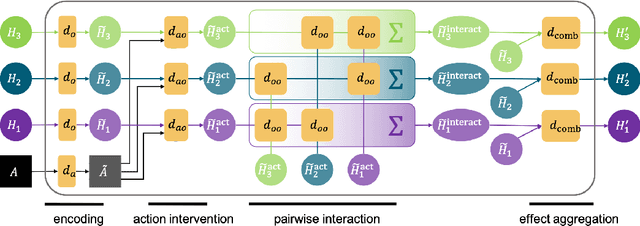
This paper tests the hypothesis that modeling a scene in terms of entities and their local interactions, as opposed to modeling the scene globally, provides a significant benefit in generalizing to physical tasks in a combinatorial space the learner has not encountered before. We present object-centric perception, prediction, and planning (OP3), which to the best of our knowledge is the first entity-centric dynamic latent variable framework for model-based reinforcement learning that acquires entity representations from raw visual observations without supervision and uses them to predict and plan. OP3 enforces entity-abstraction -- symmetric processing of each entity representation with the same locally-scoped function -- which enables it to scale to model different numbers and configurations of objects from those in training. Our approach to solving the key technical challenge of grounding these entity representations to actual objects in the environment is to frame this variable binding problem as an inference problem, and we developing an interactive inference algorithm that uses temporal continuity and interactive feedback to bind information about object properties to the entity variables. On block-stacking tasks, OP3 generalizes to novel block configurations and more objects than observed during training, outperforming an oracle model that assumes access to object supervision and achieving two to three times better accuracy than a state-of-the-art video prediction model.
MCP: Learning Composable Hierarchical Control with Multiplicative Compositional Policies
May 23, 2019

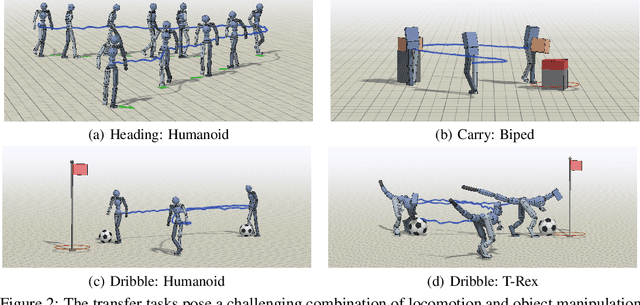
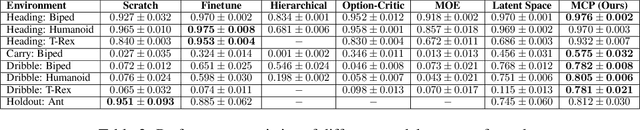
Humans are able to perform a myriad of sophisticated tasks by drawing upon skills acquired through prior experience. For autonomous agents to have this capability, they must be able to extract reusable skills from past experience that can be recombined in new ways for subsequent tasks. Furthermore, when controlling complex high-dimensional morphologies, such as humanoid bodies, tasks often require coordination of multiple skills simultaneously. Learning discrete primitives for every combination of skills quickly becomes prohibitive. Composable primitives that can be recombined to create a large variety of behaviors can be more suitable for modeling this combinatorial explosion. In this work, we propose multiplicative compositional policies (MCP), a method for learning reusable motor skills that can be composed to produce a range of complex behaviors. Our method factorizes an agent's skills into a collection of primitives, where multiple primitives can be activated simultaneously via multiplicative composition. This flexibility allows the primitives to be transferred and recombined to elicit new behaviors as necessary for novel tasks. We demonstrate that MCP is able to extract composable skills for highly complex simulated characters from pre-training tasks, such as motion imitation, and then reuse these skills to solve challenging continuous control tasks, such as dribbling a soccer ball to a goal, and picking up an object and transporting it to a target location.
Representational efficiency outweighs action efficiency in human program induction
Jul 18, 2018
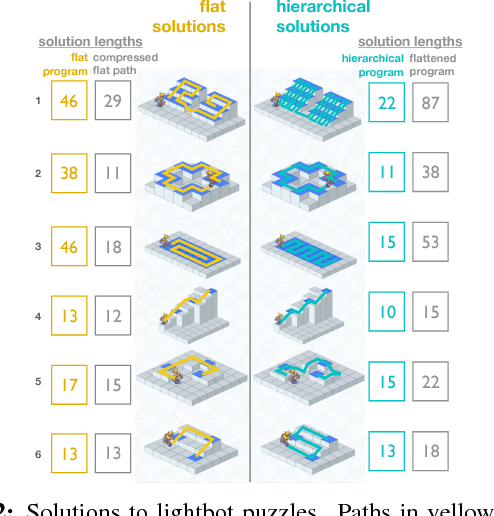
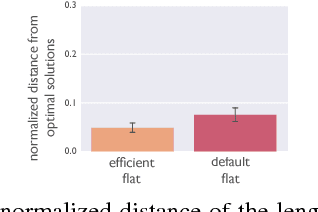
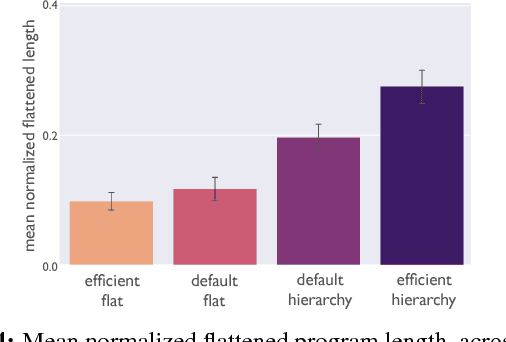
The importance of hierarchically structured representations for tractable planning has long been acknowledged. However, the questions of how people discover such abstractions and how to define a set of optimal abstractions remain open. This problem has been explored in cognitive science in the problem solving literature and in computer science in hierarchical reinforcement learning. Here, we emphasize an algorithmic perspective on learning hierarchical representations in which the objective is to efficiently encode the structure of the problem, or, equivalently, to learn an algorithm with minimal length. We introduce a novel problem-solving paradigm that links problem solving and program induction under the Markov Decision Process (MDP) framework. Using this task, we target the question of whether humans discover hierarchical solutions by maximizing efficiency in number of actions they generate or by minimizing the complexity of the resulting representation and find evidence for the primacy of representational efficiency.
Relational Neural Expectation Maximization: Unsupervised Discovery of Objects and their Interactions
Feb 28, 2018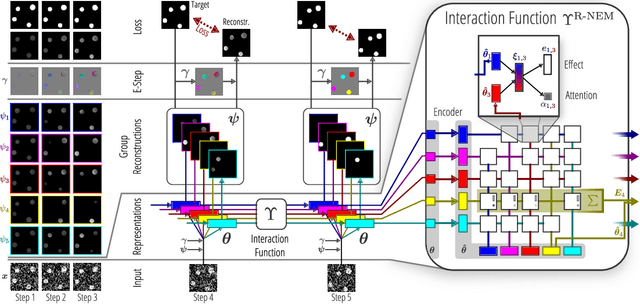

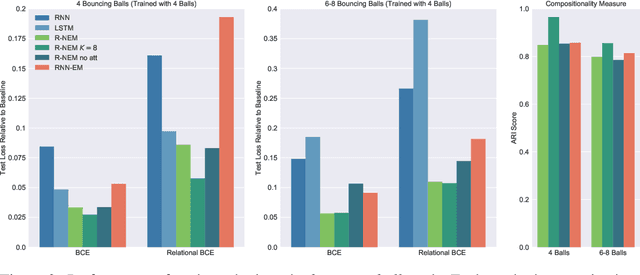

Common-sense physical reasoning is an essential ingredient for any intelligent agent operating in the real-world. For example, it can be used to simulate the environment, or to infer the state of parts of the world that are currently unobserved. In order to match real-world conditions this causal knowledge must be learned without access to supervised data. To address this problem we present a novel method that learns to discover objects and model their physical interactions from raw visual images in a purely \emph{unsupervised} fashion. It incorporates prior knowledge about the compositional nature of human perception to factor interactions between object-pairs and learn efficiently. On videos of bouncing balls we show the superior modelling capabilities of our method compared to other unsupervised neural approaches that do not incorporate such prior knowledge. We demonstrate its ability to handle occlusion and show that it can extrapolate learned knowledge to scenes with different numbers of objects.
Understanding Visual Concepts with Continuation Learning
Feb 22, 2016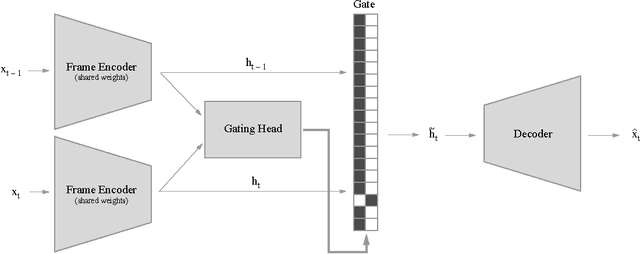
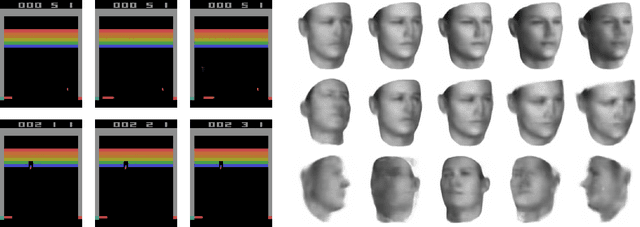
We introduce a neural network architecture and a learning algorithm to produce factorized symbolic representations. We propose to learn these concepts by observing consecutive frames, letting all the components of the hidden representation except a small discrete set (gating units) be predicted from the previous frame, and let the factors of variation in the next frame be represented entirely by these discrete gated units (corresponding to symbolic representations). We demonstrate the efficacy of our approach on datasets of faces undergoing 3D transformations and Atari 2600 games.