 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian Action Decoder for Deep Multi-Agent Reinforcement Learning
Nov 04, 2018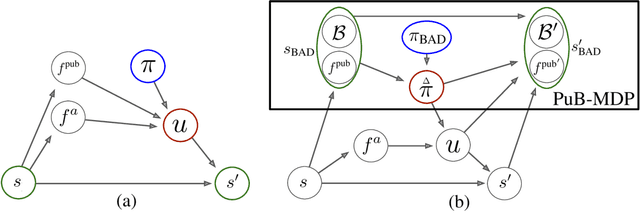
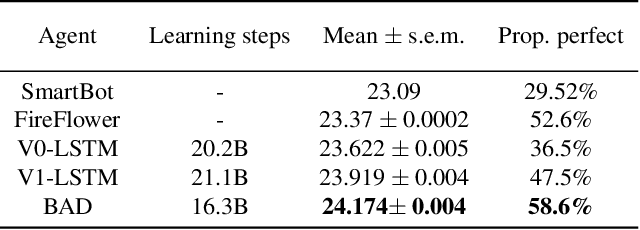
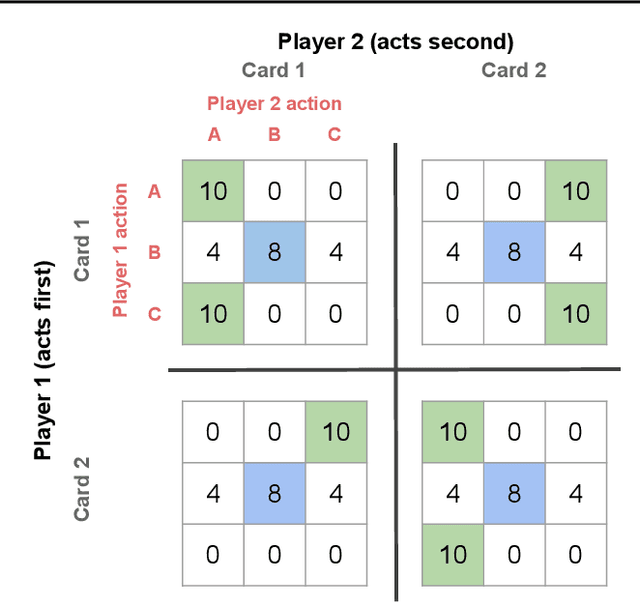
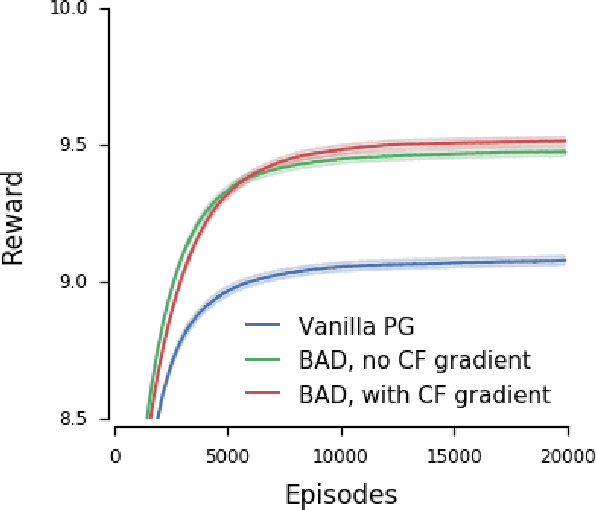
When observing the actions of others, humans carry out inferences about why the others acted as they did, and what this implies about their view of the world. Humans also use the fact that their actions will be interpreted in this manner when observed by others, allowing them to act informatively and thereby communicate efficiently with others. Although learning algorithms have recently achieved superhuman performance in a number of two-player, zero-sum games, scalable multi-agent reinforcement learning algorithms that can discover effective strategies and conventions in complex, partially observable settings have proven elusive. We present the Bayesian action decoder (BAD), a new multi-agent learning method that uses an approximate Bayesian update to obtain a public belief that conditions on the actions taken by all agents in the environment. Together with the public belief, this Bayesian update effectively defines a new Markov decision process, the public belief MDP, in which the action space consists of deterministic partial policies, parameterised by deep neural networks, that can be sampled for a given public state. It exploits the fact that an agent acting only on this public belief state can still learn to use its private information if the action space is augmented to be over partial policies mapping private information into environment actions. The Bayesian update is also closely related to the theory of mind reasoning that humans carry out when observing others' actions. We first validate BAD on a proof-of-principle two-step matrix game, where it outperforms traditional policy gradient methods. We then evaluate BAD on the challenging, cooperative partial-information card game Hanabi, where in the two-player setting the method surpasses all previously published learning and hand-coded approaches.
Actor-Critic Policy Optimization in Partially Observable Multiagent Environments
Oct 21, 2018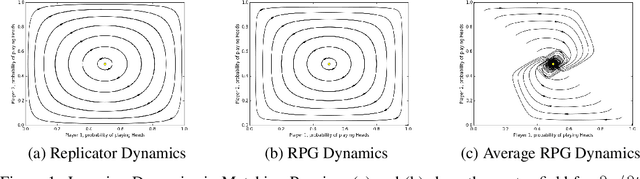
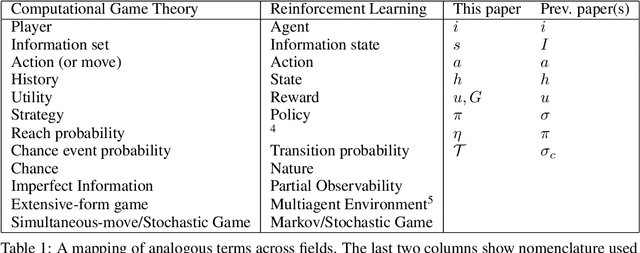
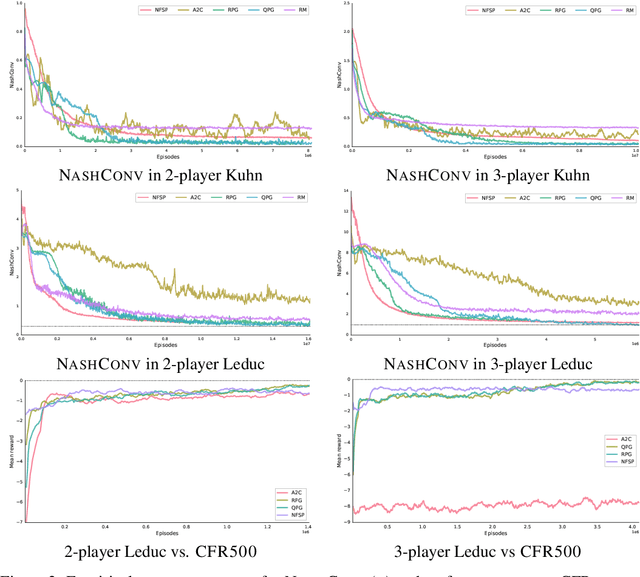
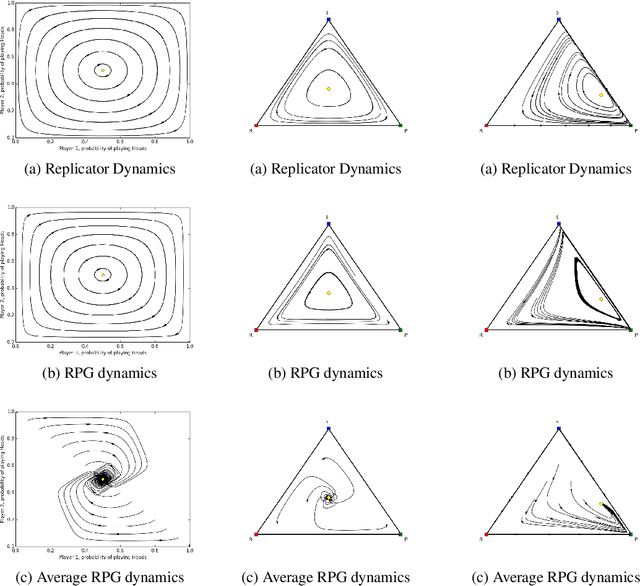
Optimization of parameterized policies for reinforcement learning (RL) is an important and challenging problem in artificial intelligence. Among the most common approaches are algorithms based on gradient ascent of a score function representing discounted return. In this paper, we examine the role of these policy gradient and actor-critic algorithms in partially-observable multiagent environments. We show several candidate policy update rules and relate them to a foundation of regret minimization and multiagent learning techniques for the one-shot and tabular cases, leading to previously unknown convergence guarantees. We apply our method to model-free multiagent reinforcement learning in adversarial sequential decision problems (zero-sum imperfect information games), using RL-style function approximation. We evaluate on commonly used benchmark Poker domains, showing performance against fixed policies and empirical convergence to approximate Nash equilibria in self-play with rates similar to or better than a baseline model-free algorithm for zero sum games, without any domain-specific state space reductions.
Generalization and Regularization in DQN
Sep 29, 2018
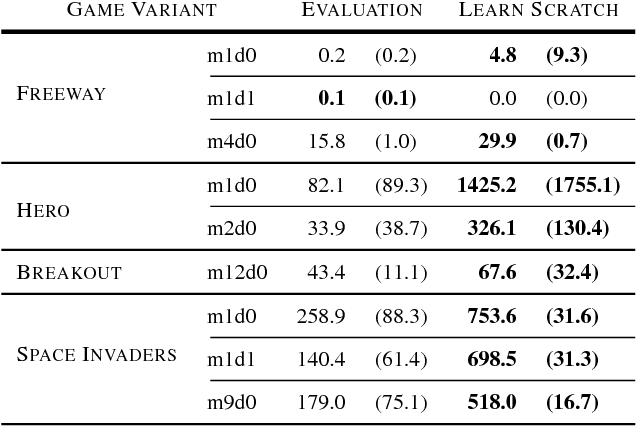
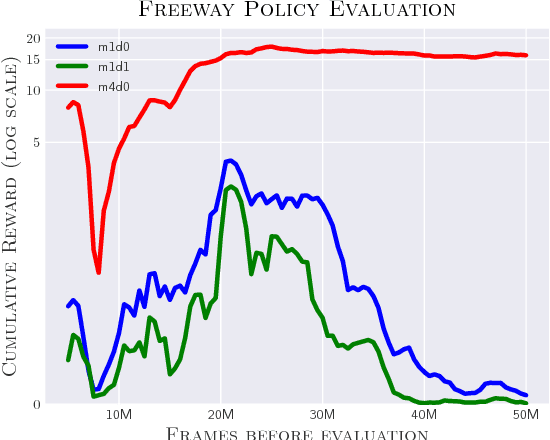
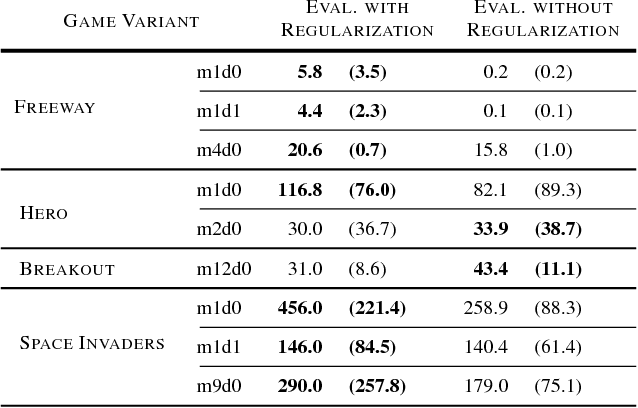
Deep reinforcement learning (RL) algorithms have shown an impressive ability to learn complex control policies in high-dimensional environments. However, despite the ever-increasing performance on popular benchmarks like the Arcade Learning Environment (ALE), policies learned by deep RL algorithms can struggle to generalize when evaluated in remarkably similar environments. These results are unexpected given the fact that, in supervised learning, deep neural networks often learn robust features that generalize across tasks. In this paper, we study the generalization capabilities of DQN in order to aid in understanding this mismatch between generalization in deep RL and supervised learning methods. We provide evidence suggesting that DQN overspecializes to the domain it is trained on. We then comprehensively evaluate the impact of traditional methods of regularization from supervised learning, $\ell_2$ and dropout, and of reusing learned representations to improve the generalization capabilities of DQN. We perform this study using different game modes of Atari 2600 games, a recently introduced modification for the ALE which supports slight variations of the Atari 2600 games used for benchmarking in the field. Despite regularization being largely underutilized in deep RL, we show that it can, in fact, help DQN learn more general features. These features can then be reused and fine-tuned on similar tasks, considerably improving the sample efficiency of DQN.
Solving Large Extensive-Form Games with Strategy Constraints
Sep 20, 2018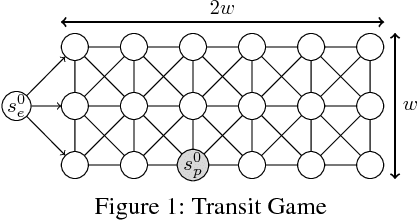
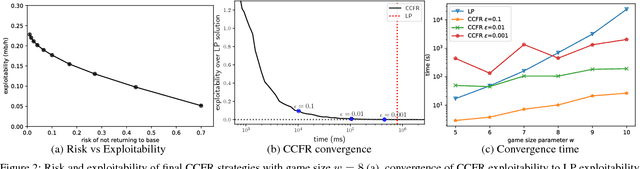
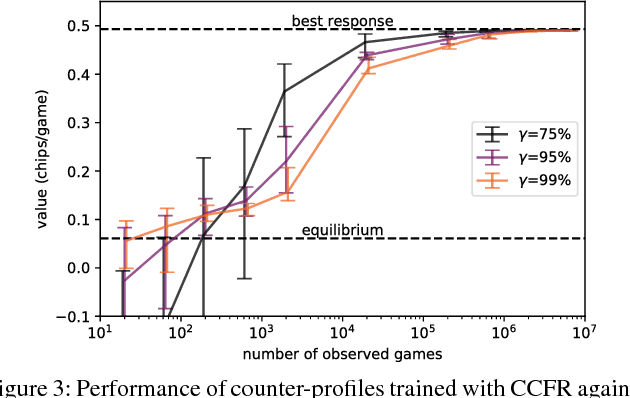
Extensive-form games are a common model for multiagent interactions with imperfect information. In two-player zero-sum games, the typical solution concept is a Nash equilibrium over the unconstrained strategy set for each player. In many situations, however, we would like to constrain the set of possible strategies. For example, constraints are a natural way to model limited resources, risk mitigation, safety, consistency with past observations of behavior, or other secondary objectives for an agent. In small games, optimal strategies under linear constraints can be found by solving a linear program; however, state-of-the-art algorithms for solving large games cannot handle general constraints. In this work we introduce a generalized form of Counterfactual Regret Minimization that provably finds optimal strategies under any feasible set of convex constraints. We demonstrate the effectiveness of our algorithm for finding strategies that mitigate risk in security games, and for opponent modeling in poker games when given only partial observations of private information.
Variance Reduction in Monte Carlo Counterfactual Regret Minimization (VR-MCCFR) for Extensive Form Games using Baselines
Sep 09, 2018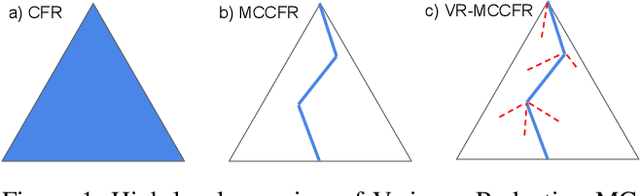
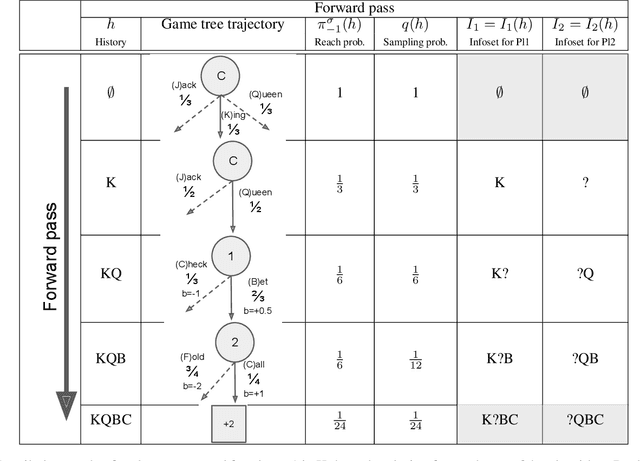
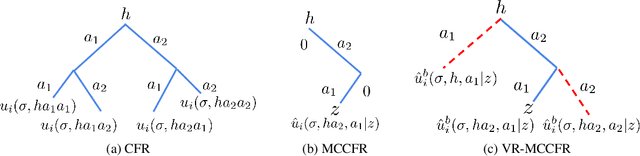
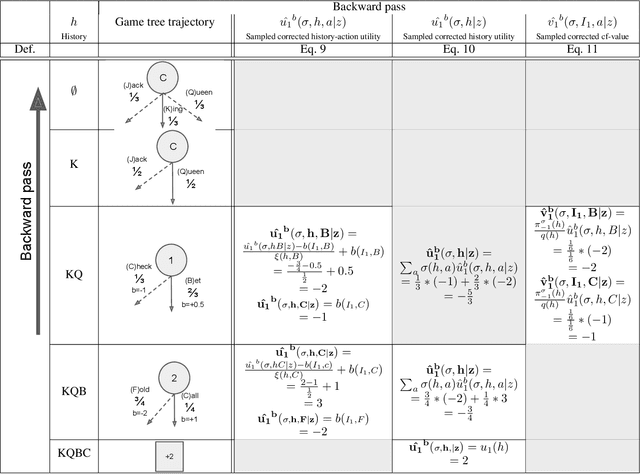
Learning strategies for imperfect information games from samples of interaction is a challenging problem. A common method for this setting, Monte Carlo Counterfactual Regret Minimization (MCCFR), can have slow long-term convergence rates due to high variance. In this paper, we introduce a variance reduction technique (VR-MCCFR) that applies to any sampling variant of MCCFR. Using this technique, per-iteration estimated values and updates are reformulated as a function of sampled values and state-action baselines, similar to their use in policy gradient reinforcement learning. The new formulation allows estimates to be bootstrapped from other estimates within the same episode, propagating the benefits of baselines along the sampled trajectory; the estimates remain unbiased even when bootstrapping from other estimates. Finally, we show that given a perfect baseline, the variance of the value estimates can be reduced to zero. Experimental evaluation shows that VR-MCCFR brings an order of magnitude speedup, while the empirical variance decreases by three orders of magnitude. The decreased variance allows for the first time CFR+ to be used with sampling, increasing the speedup to two orders of magnitude.
Count-Based Exploration with the Successor Representation
Aug 14, 2018
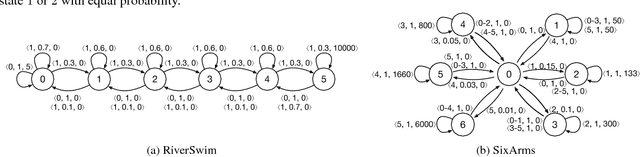

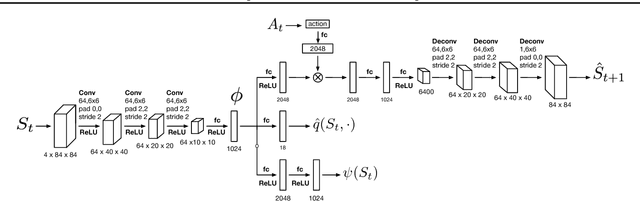
The problem of exploration in reinforcement learning is well-understood in the tabular case and many sample-efficient algorithms are known. Nevertheless, it is often unclear how the algorithms in the tabular setting can be extended to tasks with large state-spaces where generalization is required. Recent promising developments generally depend on problem-specific density models or handcrafted features. In this paper we introduce a simple approach for exploration that allows us to develop theoretically justified algorithms in the tabular case but that also give us intuitions for new algorithms applicable to settings where function approximation is required. Our approach and its underlying theory is based on the substochastic successor representation, a concept we develop here. While the traditional successor representation is a representation that defines state generalization by the similarity of successor states, the substochastic successor representation is also able to implicitly count the number of times each state (or feature) has been observed. This extension connects two until now disjoint areas of research. We show in traditional tabular domains (RiverSwim and SixArms) that our algorithm empirically performs as well as other sample-efficient algorithms. We then describe a deep reinforcement learning algorithm inspired by these ideas and show that it matches the performance of recent pseudo-count-based methods in hard exploration Atari 2600 games.
The Effect of Planning Shape on Dyna-style Planning in High-dimensional State Spaces
Jun 08, 2018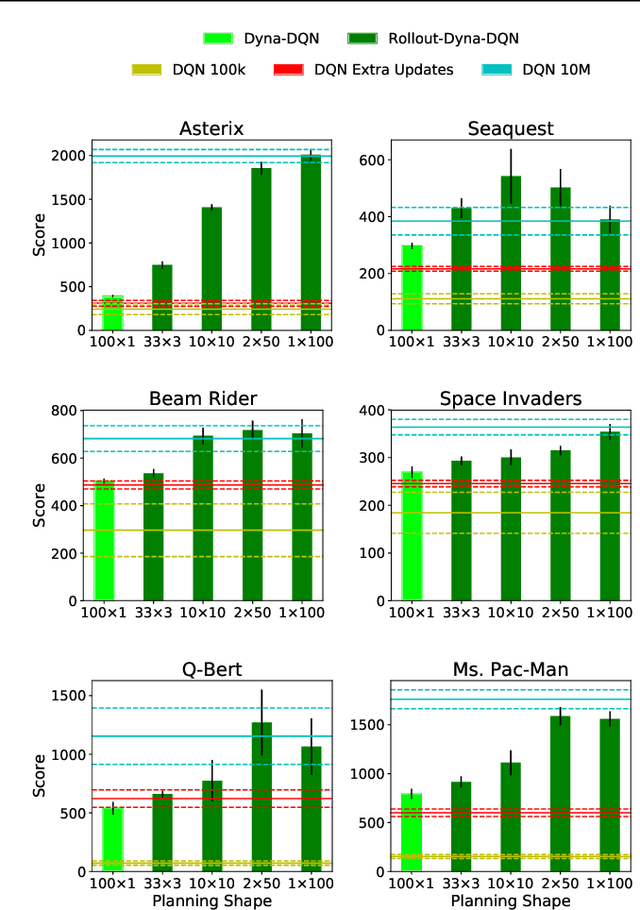
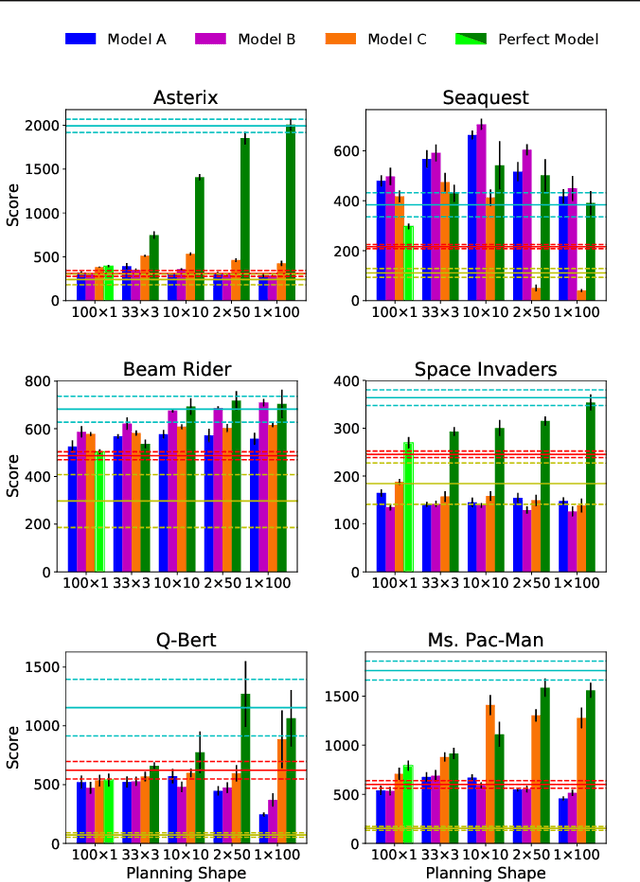
Dyna is an architecture for reinforcement learning agents that interleaves planning, acting, and learning in an online setting. This architecture aims to make fuller use of limited experience to achieve better performance with fewer environmental interactions. Dyna has been well studied in problems with a tabular representation of states, and has also been extended to some settings with larger state spaces that require function approximation. However, little work has studied Dyna in environments with high-dimensional state spaces like images. In Dyna, the environment model is typically used to generate one-step transitions from selected start states. We applied one-step Dyna to several games from the Arcade Learning Environment and found that the model-based updates offered surprisingly little benefit, even with a perfect model. However, when the model was used to generate longer trajectories of simulated experience, performance improved dramatically. This observation also holds when using a model that is learned from experience; even though the learned model is flawed, it can still be used to accelerate learning.
Revisiting the Arcade Learning Environment: Evaluation Protocols and Open Problems for General Agents
Dec 01, 2017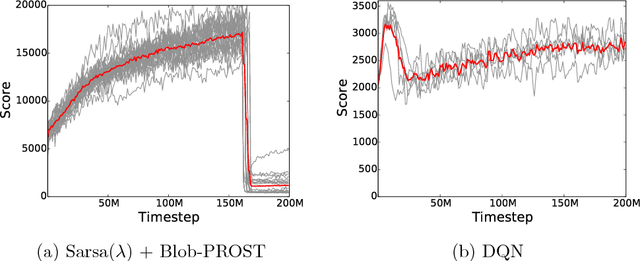
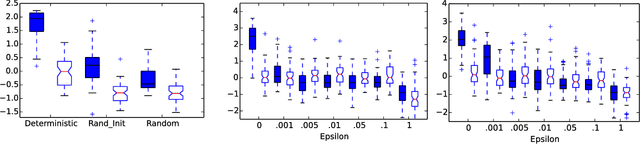
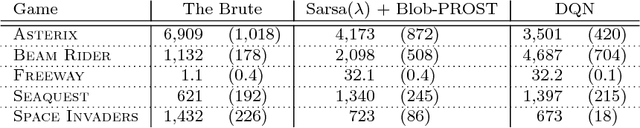

The Arcade Learning Environment (ALE) is an evaluation platform that poses the challenge of building AI agents with general competency across dozens of Atari 2600 games. It supports a variety of different problem settings and it has been receiving increasing attention from the scientific community, leading to some high-profile success stories such as the much publicized Deep Q-Networks (DQN). In this article we take a big picture look at how the ALE is being used by the research community. We show how diverse the evaluation methodologies in the ALE have become with time, and highlight some key concerns when evaluating agents in the ALE. We use this discussion to present some methodological best practices and provide new benchmark results using these best practices. To further the progress in the field, we introduce a new version of the ALE that supports multiple game modes and provides a form of stochasticity we call sticky actions. We conclude this big picture look by revisiting challenges posed when the ALE was introduced, summarizing the state-of-the-art in various problems and highlighting problems that remain open.
A Laplacian Framework for Option Discovery in Reinforcement Learning
Jun 16, 2017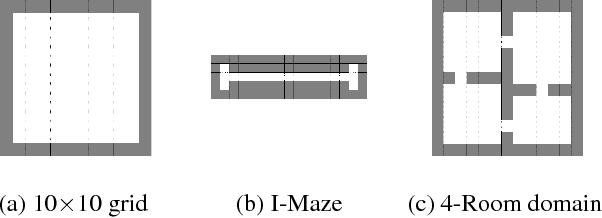
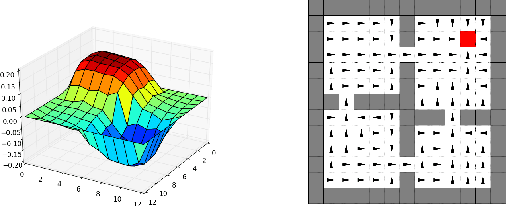


Representation learning and option discovery are two of the biggest challenges in reinforcement learning (RL). Proto-value functions (PVFs) are a well-known approach for representation learning in MDPs. In this paper we address the option discovery problem by showing how PVFs implicitly define options. We do it by introducing eigenpurposes, intrinsic reward functions derived from the learned representations. The options discovered from eigenpurposes traverse the principal directions of the state space. They are useful for multiple tasks because they are discovered without taking the environment's rewards into consideration. Moreover, different options act at different time scales, making them helpful for exploration. We demonstrate features of eigenpurposes in traditional tabular domains as well as in Atari 2600 games.
DeepStack: Expert-Level Artificial Intelligence in No-Limit Poker
Mar 03, 2017Artificial intelligence has seen several breakthroughs in recent years, with games often serving as milestones. A common feature of these games is that players have perfect information. Poker is the quintessential game of imperfect information, and a longstanding challenge problem in artificial intelligence. We introduce DeepStack, an algorithm for imperfect information settings. It combines recursive reasoning to handle information asymmetry, decomposition to focus computation on the relevant decision, and a form of intuition that is automatically learned from self-play using deep learning. In a study involving 44,000 hands of poker, DeepStack defeated with statistical significance professional poker players in heads-up no-limit Texas hold'em. The approach is theoretically sound and is shown to produce more difficult to exploit strategies than prior approaches.