 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUltralytics YOLO26: Unified Real-Time End-to-End Vision Models
Jun 02, 2026Real-time vision demands models that are accurate, efficient, and simple to deploy across diverse hardware. The YOLO family has become widely deployed for this reason, yet most YOLO detectors still rely on non-maximum suppression at inference, carry heavy detection heads due to Distribution Focal Loss, require long training schedules, and can leave the smallest objects without positive label assignments. We present Ultralytics YOLO26, a unified real-time vision model family that addresses these limitations through coordinated architecture and training advances. YOLO26 uses a dual-head design for native NMS-free end-to-end inference and removes DFL entirely, yielding a lighter head with unconstrained regression range. Its training pipeline combines MuSGD, a hybrid Muon-SGD optimizer adapted from large language model training; Progressive Loss, which shifts supervision toward the inference-time head; and STAL, a label assignment strategy that guarantees positive coverage for small objects. Beyond detection, YOLO26 introduces task-specific head and loss designs for instance segmentation, pose estimation, and oriented detection, producing consistent gains across tasks and scales. The family spans five scales (n/s/m/l/x) and supports detection, instance segmentation, pose estimation, classification, and oriented detection in a single pipeline, with an open-vocabulary extension, YOLOE-26, for text-, visual-, and prompt-free inference. Across all scales, YOLO26 achieves 40.9-57.5 mAP on COCO at 1.7-11.8 ms T4 TensorRT latency, advancing the accuracy-latency Pareto front over prior real-time detectors, while YOLOE-26x reaches 40.6 AP on LVIS minival under text prompting. Code and models are available at https://github.com/ultralytics/ultralytics.
SafePilot: A Framework for Assuring LLM-enabled Cyber-Physical Systems
Mar 23, 2026Large Language Models (LLMs), deep learning architectures with typically over 10 billion parameters, have recently begun to be integrated into various cyber-physical systems (CPS) such as robotics, industrial automation, and autopilot systems. The abstract knowledge and reasoning capabilities of LLMs are employed for tasks like planning and navigation. However, a significant challenge arises from the tendency of LLMs to produce "hallucinations" - outputs that are coherent yet factually incorrect or contextually unsuitable. This characteristic can lead to undesirable or unsafe actions in the CPS. Therefore, our research focuses on assuring the LLM-enabled CPS by enhancing their critical properties. We propose SafePilot, a novel hierarchical neuro-symbolic framework that provides end-to-end assurance for LLM-enabled CPS according to attribute-based and temporal specifications. Given a task and its specification, SafePilot first invokes a hierarchical planner with a discriminator that assesses task complexity. If the task is deemed manageable, it is passed directly to an LLM-based task planner with built-in verification. Otherwise, the hierarchical planner applies a divide-and-conquer strategy, decomposing the task into sub-tasks, each of which is individually planned and later merged into a final solution. The LLM-based task planner translates natural language constraints into formal specifications and verifies the LLM's output against them. If violations are detected, it identifies the flaw, adjusts the prompt accordingly, and re-invokes the LLM. This iterative process continues until a valid plan is produced or a predefined limit is reached. Our framework supports LLM-enabled CPS with both attribute-based and temporal constraints. Its effectiveness and adaptability are demonstrated through two illustrative case studies.
SafeGen-LLM: Enhancing Safety Generalization in Task Planning for Robotic Systems
Feb 27, 2026Safety-critical task planning in robotic systems remains challenging: classical planners suffer from poor scalability, Reinforcement Learning (RL)-based methods generalize poorly, and base Large Language Models (LLMs) cannot guarantee safety. To address this gap, we propose safety-generalizable large language models, named SafeGen-LLM. SafeGen-LLM can not only enhance the safety satisfaction of task plans but also generalize well to novel safety properties in various domains. We first construct a multi-domain Planning Domain Definition Language 3 (PDDL3) benchmark with explicit safety constraints. Then, we introduce a two-stage post-training framework: Supervised Fine-Tuning (SFT) on a constraint-compliant planning dataset to learn planning syntax and semantics, and Group Relative Policy Optimization (GRPO) guided by fine-grained reward machines derived from formal verification to enforce safety alignment and by curriculum learning to better handle complex tasks. Extensive experiments show that SafeGen-LLM achieves strong safety generalization and outperforms frontier proprietary baselines across multi-domain planning tasks and multiple input formats (e.g., PDDLs and natural language).
Enhancing LLM-Based Test Generation by Eliminating Covered Code
Feb 25, 2026Automated test generation is essential for software quality assurance, with coverage rate serving as a key metric to ensure thorough testing. Recent advancements in Large Language Models (LLMs) have shown promise in improving test generation, particularly in achieving higher coverage. However, while existing LLM-based test generation solutions perform well on small, isolated code snippets, they struggle when applied to complex methods under test. To address these issues, we propose a scalable LLM-based unit test generation method. Our approach consists of two key steps. The first step is context information retrieval, which uses both LLMs and static analysis to gather relevant contextual information associated with the complex methods under test. The second step, iterative test generation with code elimination, repeatedly generates unit tests for the code slice, tracks the achieved coverage, and selectively removes code segments that have already been covered. This process simplifies the testing task and mitigates issues arising from token limits or reduced reasoning effectiveness associated with excessively long contexts. Through comprehensive evaluations on open-source projects, our approach outperforms state-of-the-art LLM-based and search-based methods, demonstrating its effectiveness in achieving high coverage on complex methods.
Vulnerability Analysis of Safe Reinforcement Learning via Inverse Constrained Reinforcement Learning
Feb 18, 2026Safe reinforcement learning (Safe RL) aims to ensure policy performance while satisfying safety constraints. However, most existing Safe RL methods assume benign environments, making them vulnerable to adversarial perturbations commonly encountered in real-world settings. In addition, existing gradient-based adversarial attacks typically require access to the policy's gradient information, which is often impractical in real-world scenarios. To address these challenges, we propose an adversarial attack framework to reveal vulnerabilities of Safe RL policies. Using expert demonstrations and black-box environment interaction, our framework learns a constraint model and a surrogate (learner) policy, enabling gradient-based attack optimization without requiring the victim policy's internal gradients or the ground-truth safety constraints. We further provide theoretical analysis establishing feasibility and deriving perturbation bounds. Experiments on multiple Safe RL benchmarks demonstrate the effectiveness of our approach under limited privileged access.
Low-Complexity Iterative Precoding Design for Near-field Multiuser Systems With Spatial Non-Stationarity
Jan 18, 2025



Extremely large antenna arrays (ELAA) are regarded as a promising technology for supporting sixth-generation (6G) networks. However, the large number of antennas significantly increases the computational complexity in precoding design, even for linearly regularized zero-forcing (RZF) precoding. To address this issue, a series of low-complexity iterative precoding are investigated. The main idea of these methods is to avoid matrix inversion of RZF precoding. Specifically, RZF precoding is equivalent to a system of linear equations that can be solved by fast iterative algorithms, such as random Kaczmarz (RK) algorithm. Yet, the performance of RK-based precoding algorithm is limited by the energy distributions of multiple users, which restricts its application in ELAA-assisted systems. To accelerate the RK-based precoding, we introduce the greedy random Kaczmarz (GRK)-based precoding by using the greedy criterion-based selection strategy. To further reduce the complexity of the GRK-based precoding, we propose a visibility region (VR)-based orthogonal GRK (VR-OGRK) precoding that leverages near-field spatial non-stationarity, which is characterized by the concept of VR. Next, by utilizing the information from multiple hyperplanes in each iteration, we extend the GRK-based precoding to the aggregation hyperplane Kaczmarz (AHK)-based pecoding algorithm, which further enhances the convergence rate. Building upon the AHK algorithm, we propose a VR-based orthogonal AHK (VR-OAHK) precoding to further reduce the computational complexity. Furthermore, the proposed iterative precoding algorithms are proven to converge to RZF globally at an exponential rate. Simulation results show that the proposed algorithms achieve faster convergence and lower computational complexity than benchmark algorithms, and yield very similar performance to the RZF precoding.
Addressing the Mutual Interference in Uplink ISAC Receivers: A Projection Method
Aug 29, 2024


Dual function radar and communication (DFRC) is a promising research direction within integrated sensing and communication (ISAC), improving hardware and spectrum efficiency by merging sensing and communication (S&C) functionalities into a shared platform. However, the DFRC receiver (DFRC-R) is tasked with both uplink communication signal detection and simultaneously target-related parameter estimation from the echoes, leading to issues with mutual interference. In this paper, a projection-based scheme is proposed to equivalently transform the joint signal detection and target estimation problem into a joint signal detection process across multiple snapshots. Compared with conventional successive interference cancellation (SIC) schemes, our proposed approach achieves a higher signal-to-noise ratio (SNR), and a higher ergodic rate when the radar signal is non-negligible. Nonetheless, it introduces an ill-conditioned signal detection problem, which is addressed using a non-linear detector. By jointly processing an increased number of snapshots, the proposed scheme can achieve high S&C performance simultaneously.
Automating Weak Label Generation for Data Programming with Clinicians in the Loop
Jul 10, 2024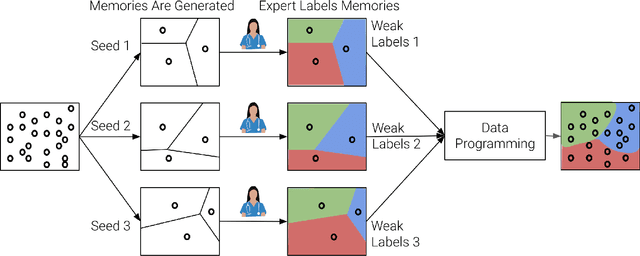
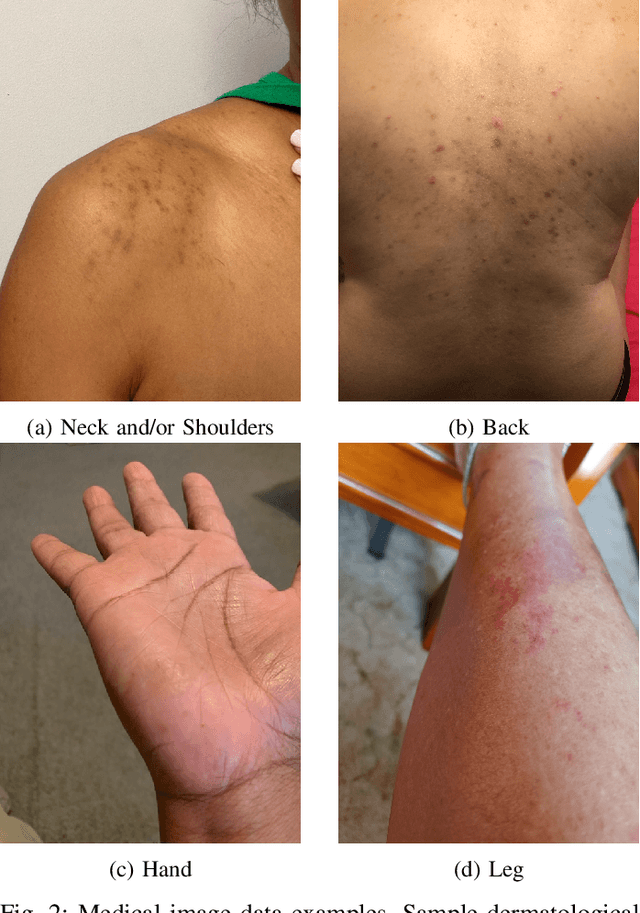
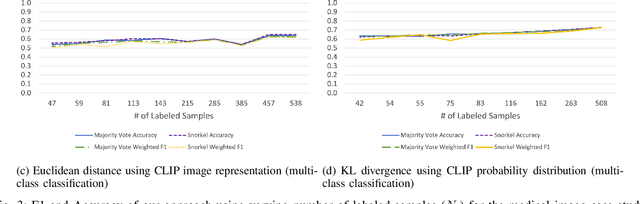
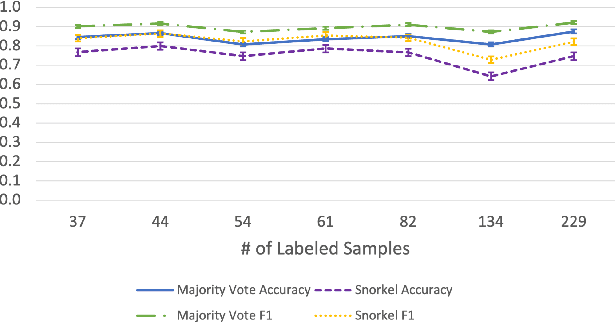
Large Deep Neural Networks (DNNs) are often data hungry and need high-quality labeled data in copious amounts for learning to converge. This is a challenge in the field of medicine since high quality labeled data is often scarce. Data programming has been the ray of hope in this regard, since it allows us to label unlabeled data using multiple weak labeling functions. Such functions are often supplied by a domain expert. Data-programming can combine multiple weak labeling functions and suggest labels better than simple majority voting over the different functions. However, it is not straightforward to express such weak labeling functions, especially in high-dimensional settings such as images and time-series data. What we propose in this paper is a way to bypass this issue, using distance functions. In high-dimensional spaces, it is easier to find meaningful distance metrics which can generalize across different labeling tasks. We propose an algorithm that queries an expert for labels of a few representative samples of the dataset. These samples are carefully chosen by the algorithm to capture the distribution of the dataset. The labels assigned by the expert on the representative subset induce a labeling on the full dataset, thereby generating weak labels to be used in the data programming pipeline. In our medical time series case study, labeling a subset of 50 to 130 out of 3,265 samples showed 17-28% improvement in accuracy and 13-28% improvement in F1 over the baseline using clinician-defined labeling functions. In our medical image case study, labeling a subset of about 50 to 120 images from 6,293 unlabeled medical images using our approach showed significant improvement over the baseline method, Snuba, with an increase of approximately 5-15% in accuracy and 12-19% in F1 score.
Beamforming Design for Double-Active-RIS-aided Communication Systems with Inter-Excitation
Mar 17, 2024



In this paper, we investigate a double-active-reconfigurable intelligent surface (RIS)-aided downlink wireless communication system, where a multi-antenna base station (BS) serves multiple single-antenna users with both double reflection and single reflection links. Due to the signal amplification capability of active RISs, the mutual influence between active RISs, which is termed as the "inter-excitation" effect, cannot be ignored. Then, we develop a feedback-type model to characterize the signal containing the inter-excitation effect. Based on the signal model, we formulate a weighted sum rate (WSR) maximization problem by jointly optimizing the beamforming matrix at the BS and the reflecting coefficient matrices at the two active RISs, subject to power constraints at the BS and active RISs, as well as the maximum amplification gain constraints of the active RISs. To solve this non-convex problem, we first transform the problem into a more tractable form using the fractional programming (FP) method. Then, by introducing auxiliary variables, the problem can be converted into an equivalent form that can be solved by using a low-complexity penalty dual decomposition (PDD) algorithm. Finally, simulation results indicate that it is crucial to consider the inter-excitation effect between active RISs in beamforming design for double-active-RIS-aided communication systems. Additionally, it prevails over other benchmark schemes with single active RIS and double passive RISs in terms of achievable rate.
Joint Beamforming Design for Double Active RIS-assisted Radar-Communication Coexistence Systems
Feb 07, 2024



Integrated sensing and communication (ISAC) technology has been considered as one of the key candidate technologies in the next-generation wireless communication systems. However, when radar and communication equipment coexist in the same system, i.e. radar-communication coexistence (RCC), the interference from communication systems to radar can be large and cannot be ignored. Recently, reconfigurable intelligent surface (RIS) has been introduced into RCC systems to reduce the interference. However, the "multiplicative fading" effect introduced by passive RIS limits its performance. To tackle this issue, we consider a double active RIS-assisted RCC system, which focuses on the design of the radar's beamforming vector and the active RISs' reflecting coefficient matrices, to maximize the achievable data rate of the communication system. The considered system needs to meet the radar detection constraint and the power budgets at the radar and the RISs. Since the problem is non-convex, we propose an algorithm based on the penalty dual decomposition (PDD) framework. Specifically, we initially introduce auxiliary variables to reformulate the coupled variables into equation constraints and incorporate these constraints into the objective function through the PDD framework. Then, we decouple the equivalent problem into several subproblems by invoking the block coordinate descent (BCD) method. Furthermore, we employ the Lagrange dual method to alternately optimize these subproblems. Simulation results verify the effectiveness of the proposed algorithm. Furthermore, the results also show that under the same power budget, deploying double active RISs in RCC systems can achieve higher data rate than those with single active RIS and double passive RISs.