 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuralKalman: A Learnable Kalman Filter for Acoustic Echo Cancellation
Feb 03, 2023



The Kalman filter is widely used for addressing acoustic echo cancellation (AEC) problems due to their robustness to double-talk and fast convergence. However, the inability to model nonlinearity and the need to tune control parameters cast limitations on such adaptive filtering algorithms. In this paper, we integrate the frequency domain Kalman filter (FDKF) and deep neural networks (DNNs) into a hybrid method, called NeuralKalman, to leverage the advantages of deep learning and adaptive filtering algorithms. Specifically, we employ a DNN to estimate nonlinearly distorted far-end signals, a transition factor, and the nonlinear transition function in the state equation of the FDKF algorithm. Experimental results show that the proposed NeuralKalman improves the performance of FDKF significantly and outperforms strong baseline methods.
Deep Neural Mel-Subband Beamformer for In-car Speech Separation
Nov 22, 2022


While current deep learning (DL)-based beamforming techniques have been proved effective in speech separation, they are often designed to process narrow-band (NB) frequencies independently which results in higher computational costs and inference times, making them unsuitable for real-world use. In this paper, we propose DL-based mel-subband spatio-temporal beamformer to perform speech separation in a car environment with reduced computation cost and inference time. As opposed to conventional subband (SB) approaches, our framework uses a mel-scale based subband selection strategy which ensures a fine-grained processing for lower frequencies where most speech formant structure is present, and coarse-grained processing for higher frequencies. In a recursive way, robust frame-level beamforming weights are determined for each speaker location/zone in a car from the estimated subband speech and noise covariance matrices. Furthermore, proposed framework also estimates and suppresses any echoes from the loudspeaker(s) by using the echo reference signals. We compare the performance of our proposed framework to several NB, SB, and full-band (FB) processing techniques in terms of speech quality and recognition metrics. Based on experimental evaluations on simulated and real-world recordings, we find that our proposed framework achieves better separation performance over all SB and FB approaches and achieves performance closer to NB processing techniques while requiring lower computing cost.
NeuralEcho: A Self-Attentive Recurrent Neural Network For Unified Acoustic Echo Suppression And Speech Enhancement
May 20, 2022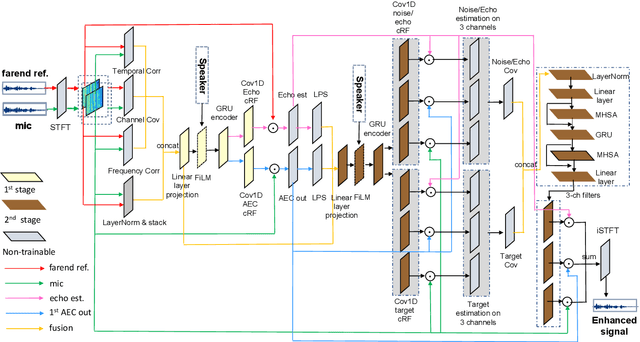
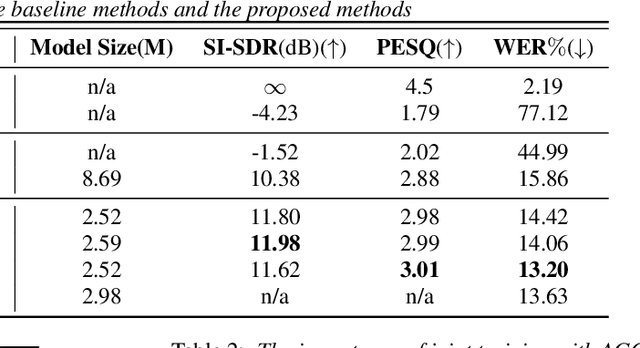
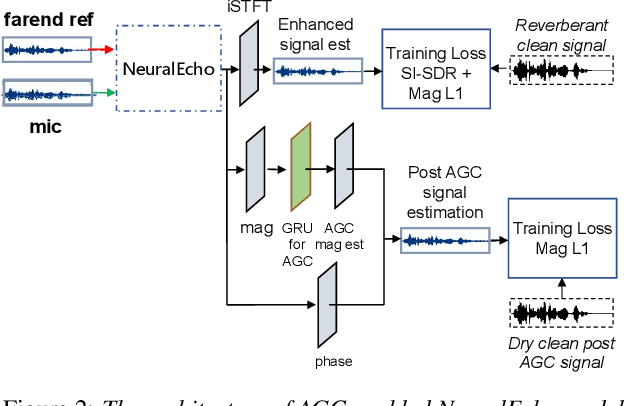

Acoustic echo cancellation (AEC) plays an important role in the full-duplex speech communication as well as the front-end speech enhancement for recognition in the conditions when the loudspeaker plays back. In this paper, we present an all-deep-learning framework that implicitly estimates the second order statistics of echo/noise and target speech, and jointly solves echo and noise suppression through an attention based recurrent neural network. The proposed model outperforms the state-of-the-art joint echo cancellation and speech enhancement method F-T-LSTM in terms of objective speech quality metrics, speech recognition accuracy and model complexity. We show that this model can work with speaker embedding for better target speech enhancement and furthermore develop a branch for automatic gain control (AGC) task to form an all-in-one front-end speech enhancement system.
EEND-SS: Joint End-to-End Neural Speaker Diarization and Speech Separation for Flexible Number of Speakers
Mar 31, 2022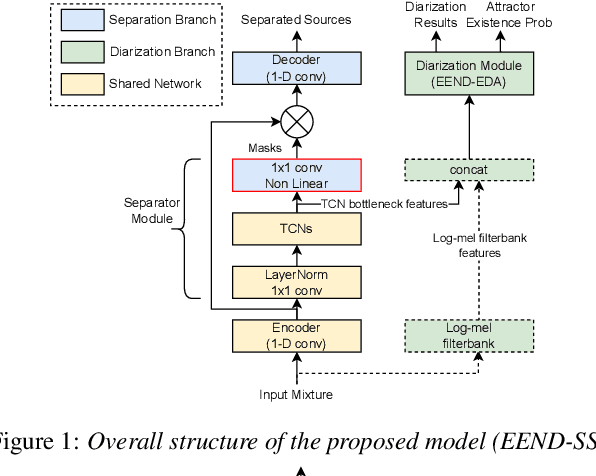
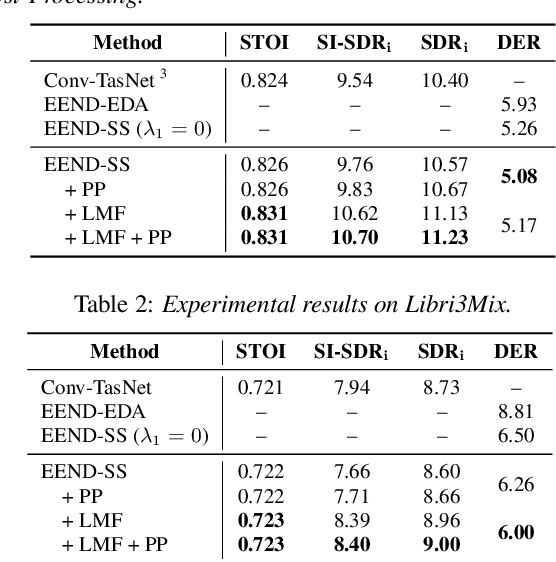

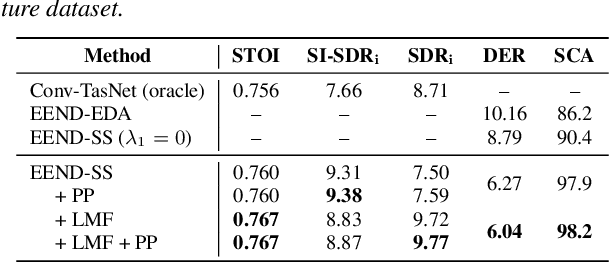
In this paper, we present a novel framework that jointly performs speaker diarization, speech separation, and speaker counting. Our proposed method combines end-to-end speaker diarization and speech separation methods, namely, End-to-End Neural Speaker Diarization with Encoder-Decoder-based Attractor calculation (EEND-EDA) and the Convolutional Time-domain Audio Separation Network (ConvTasNet) as multi-tasking joint model. We also propose the multiple 1x1 convolutional layer architecture for estimating the separation masks corresponding to the number of speakers, and a post-processing technique for refining the separated speech signal with speech activity. Experiments using LibriMix dataset show that our proposed method outperforms the baselines in terms of diarization and separation performance for both fixed and flexible numbers of speakers, as well as speaker counting performance for flexible numbers of speakers. All materials will be open-sourced and reproducible in ESPnet toolkit.
Enhancing Zero-Shot Many to Many Voice Conversion with Self-Attention VAE
Mar 30, 2022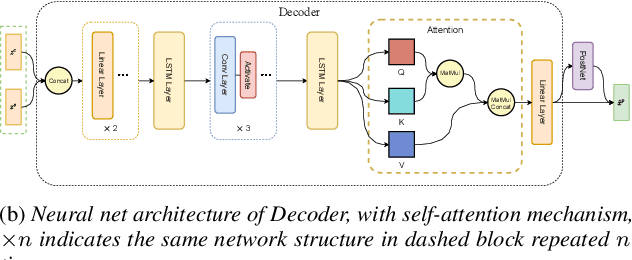
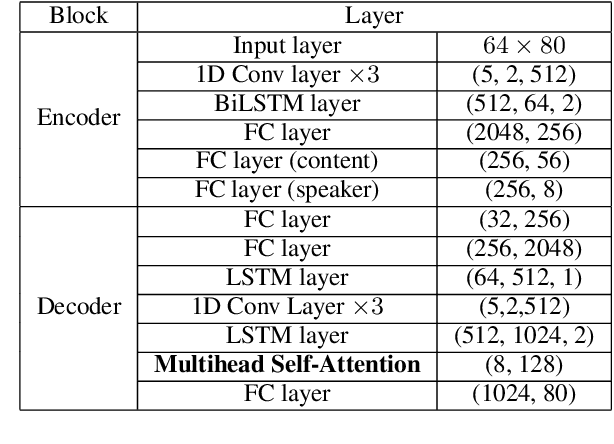
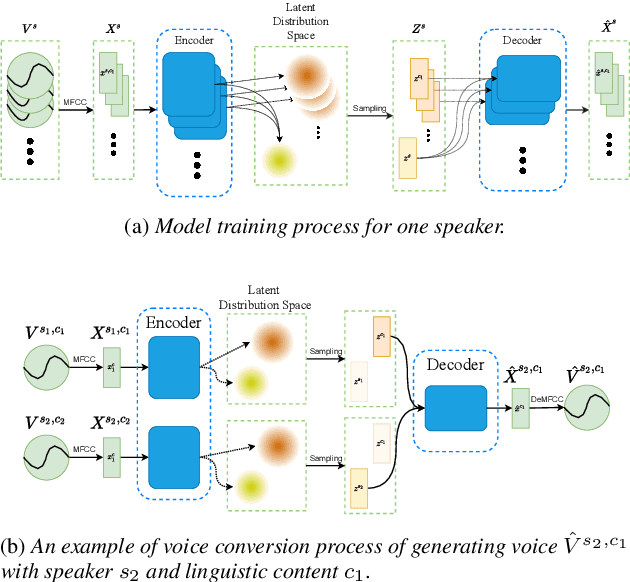

Variational auto-encoder(VAE) is an effective neural network architecture to disentangle a speech utterance into speaker identity and linguistic content latent embeddings, then generate an utterance for a target speaker from that of a source speaker. This is possible by concatenating the identity embedding of the target speaker and the content embedding of the source speaker uttering a desired sentence. In this work, we found a suitable location of VAE's decoder to add a self-attention layer for incorporating non-local information in generating a converted utterance and hiding the source speaker's identity. In experiments of zero-shot many-to-many voice conversion task on VCTK data set, the self-attention layer enhances speaker classification accuracy on unseen speakers by 27\% while increasing the decoder parameter size by 12\%. The voice quality of converted utterance degrades by merely 3\% measured by the MOSNet scores. To reduce over-fitting and generalization error, we further applied a relaxed group-wise splitting method in network training and achieved a gain of speaker classification accuracy on unseen speakers by 46\% while maintaining the conversion voice quality in terms of MOSNet scores. Our encouraging findings point to future research on integrating more variety of attention structures in VAE framework for advancing zero-shot many-to-many voice conversions.
Joint Modeling of Code-Switched and Monolingual ASR via Conditional Factorization
Nov 29, 2021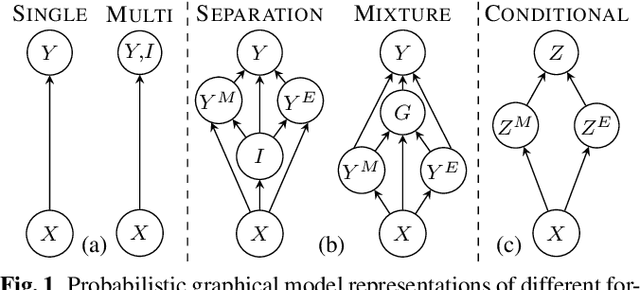
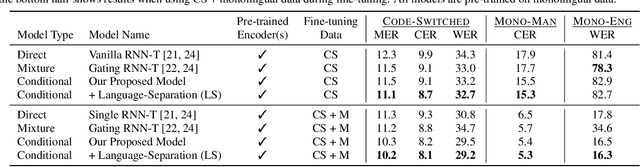
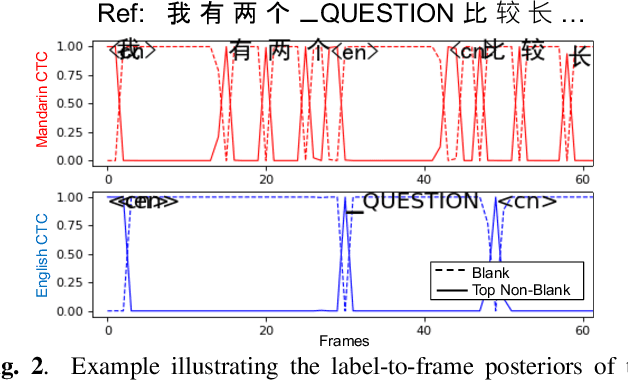
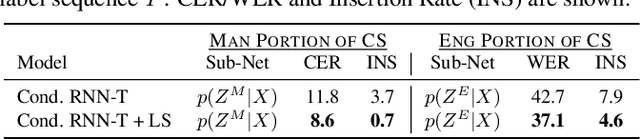
Conversational bilingual speech encompasses three types of utterances: two purely monolingual types and one intra-sententially code-switched type. In this work, we propose a general framework to jointly model the likelihoods of the monolingual and code-switch sub-tasks that comprise bilingual speech recognition. By defining the monolingual sub-tasks with label-to-frame synchronization, our joint modeling framework can be conditionally factorized such that the final bilingual output, which may or may not be code-switched, is obtained given only monolingual information. We show that this conditionally factorized joint framework can be modeled by an end-to-end differentiable neural network. We demonstrate the efficacy of our proposed model on bilingual Mandarin-English speech recognition across both monolingual and code-switched corpora.
Joint AEC AND Beamforming with Double-Talk Detection using RNN-Transformer
Nov 09, 2021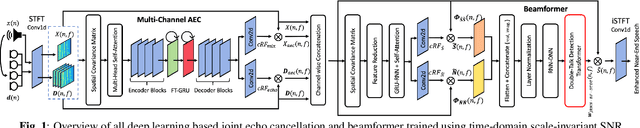
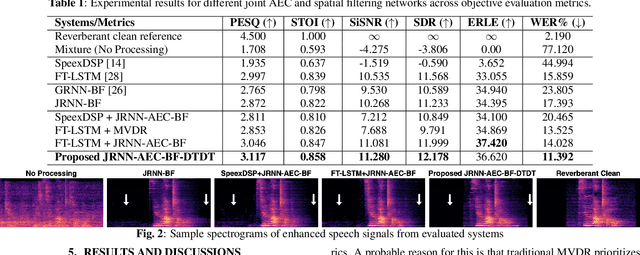
Acoustic echo cancellation (AEC) is a technique used in full-duplex communication systems to eliminate acoustic feedback of far-end speech. However, their performance degrades in naturalistic environments due to nonlinear distortions introduced by the speaker, as well as background noise, reverberation, and double-talk scenarios. To address nonlinear distortions and co-existing background noise, several deep neural network (DNN)-based joint AEC and denoising systems were developed. These systems are based on either purely "black-box" neural networks or "hybrid" systems that combine traditional AEC algorithms with neural networks. We propose an all-deep-learning framework that combines multi-channel AEC and our recently proposed self-attentive recurrent neural network (RNN) beamformer. We propose an all-deep-learning framework that combines multi-channel AEC and our recently proposed self-attentive recurrent neural network (RNN) beamformer. Furthermore, we propose a double-talk detection transformer (DTDT) module based on the multi-head attention transformer structure that computes attention over time by leveraging frame-wise double-talk predictions. Experiments show that our proposed method outperforms other approaches in terms of improving speech quality and speech recognition rate of an ASR system.
FAST-RIR: Fast neural diffuse room impulse response generator
Oct 07, 2021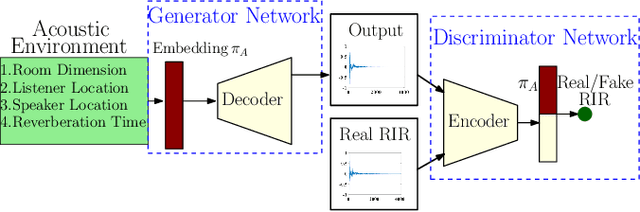
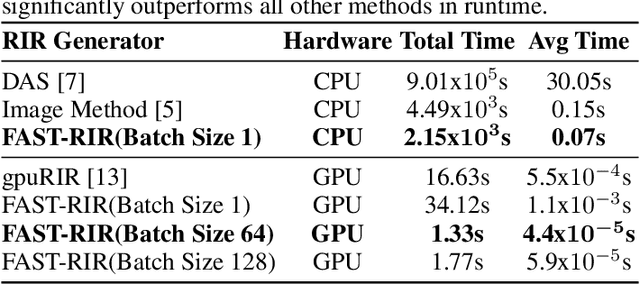

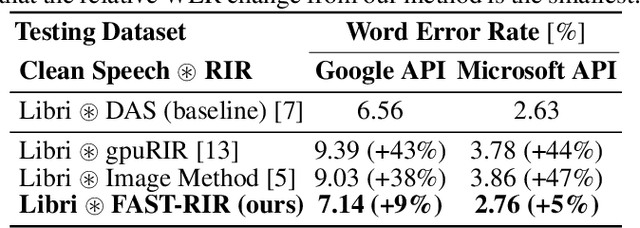
We present a neural-network-based fast diffuse room impulse response generator (FAST-RIR) for generating room impulse responses (RIRs) for a given acoustic environment. Our FAST-RIR takes rectangular room dimensions, listener and speaker positions, and reverberation time as inputs and generates specular and diffuse reflections for a given acoustic environment. Our FAST-RIR is capable of generating RIRs for a given input reverberation time with an average error of 0.02s. We evaluate our generated RIRs in automatic speech recognition (ASR) applications using Google Speech API, Microsoft Speech API, and Kaldi tools. We show that our proposed FAST-RIR with batch size 1 is 400 times faster than a state-of-the-art diffuse acoustic simulator (DAS) on a CPU and gives similar performance to DAS in ASR experiments. Our FAST-RIR is 12 times faster than an existing GPU-based RIR generator (gpuRIR). We show that our FAST-RIR outperforms gpuRIR by 2.5% in an AMI far-field ASR benchmark.
MIMO Self-attentive RNN Beamformer for Multi-speaker Speech Separation
Apr 26, 2021
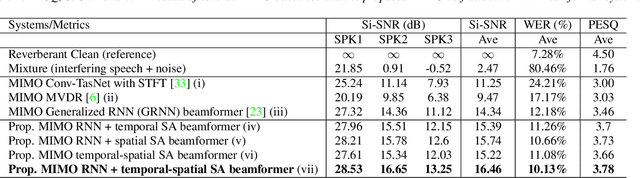

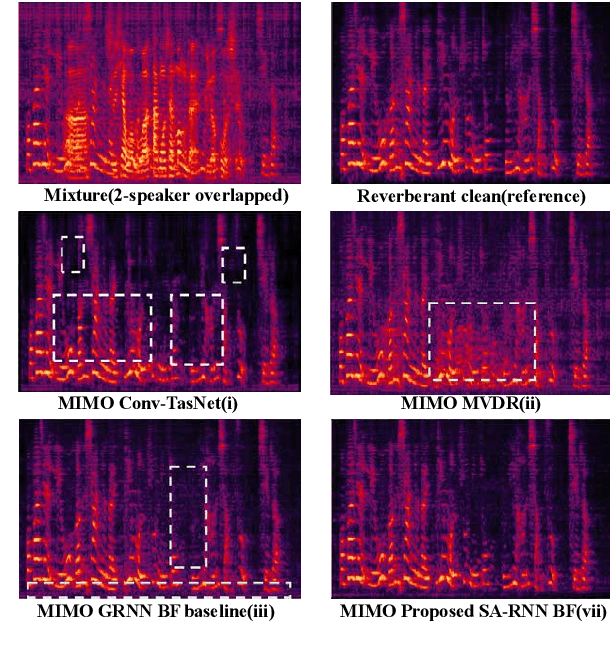
Recently, our proposed recurrent neural network (RNN) based all deep learning minimum variance distortionless response (ADL-MVDR) beamformer method yielded superior performance over the conventional MVDR by replacing the matrix inversion and eigenvalue decomposition with two recurrent neural networks. In this work, we present a self-attentive RNN beamformer to further improve our previous RNN-based beamformer by leveraging on the powerful modeling capability of self-attention. Temporal-spatial self-attention module is proposed to better learn the beamforming weights from the speech and noise spatial covariance matrices. The temporal self-attention module could help RNN to learn global statistics of covariance matrices. The spatial self-attention module is designed to attend on the cross-channel correlation in the covariance matrices. Furthermore, a multi-channel input with multi-speaker directional features and multi-speaker speech separation outputs (MIMO) model is developed to improve the inference efficiency. The evaluations demonstrate that our proposed MIMO self-attentive RNN beamformer improves both the automatic speech recognition (ASR) accuracy and the perceptual estimation of speech quality (PESQ) against prior arts.
MetricNet: Towards Improved Modeling For Non-Intrusive Speech Quality Assessment
Apr 02, 2021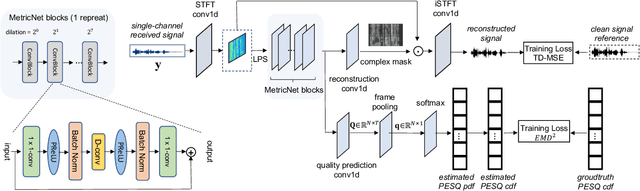
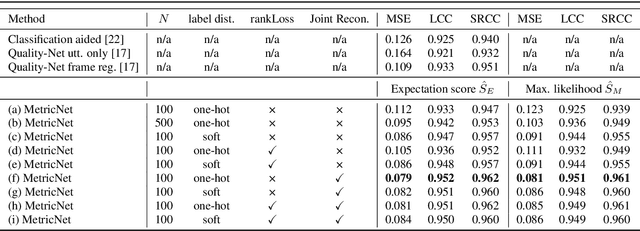
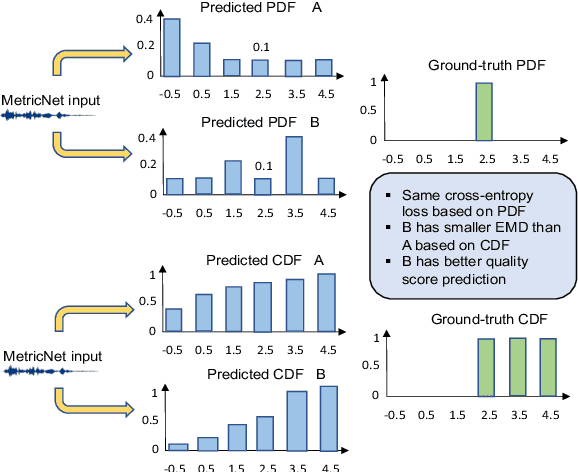
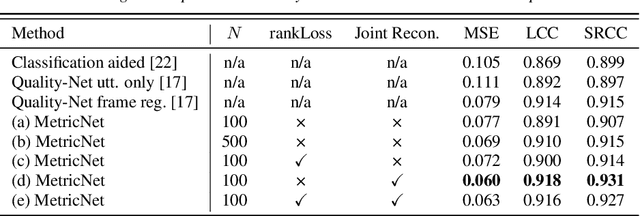
The objective speech quality assessment is usually conducted by comparing received speech signal with its clean reference, while human beings are capable of evaluating the speech quality without any reference, such as in the mean opinion score (MOS) tests. Non-intrusive speech quality assessment has attracted much attention recently due to the lack of access to clean reference signals for objective evaluations in real scenarios. In this paper, we propose a novel non-intrusive speech quality measurement model, MetricNet, which leverages label distribution learning and joint speech reconstruction learning to achieve significantly improved performance compared to the existing non-intrusive speech quality measurement models. We demonstrate that the proposed approach yields promisingly high correlation to the intrusive objective evaluation of speech quality on clean, noisy and processed speech data.