 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Faithful and Controllable Personalization via Critique-Post-Edit Reinforcement Learning
Oct 21, 2025Faithfully personalizing large language models (LLMs) to align with individual user preferences is a critical but challenging task. While supervised fine-tuning (SFT) quickly reaches a performance plateau, standard reinforcement learning from human feedback (RLHF) also struggles with the nuances of personalization. Scalar-based reward models are prone to reward hacking which leads to verbose and superficially personalized responses. To address these limitations, we propose Critique-Post-Edit, a robust reinforcement learning framework that enables more faithful and controllable personalization. Our framework integrates two key components: (1) a Personalized Generative Reward Model (GRM) that provides multi-dimensional scores and textual critiques to resist reward hacking, and (2) a Critique-Post-Edit mechanism where the policy model revises its own outputs based on these critiques for more targeted and efficient learning. Under a rigorous length-controlled evaluation, our method substantially outperforms standard PPO on personalization benchmarks. Personalized Qwen2.5-7B achieves an average 11\% win-rate improvement, and personalized Qwen2.5-14B model surpasses the performance of GPT-4.1. These results demonstrate a practical path to faithful, efficient, and controllable personalization.
MiCoTA: Bridging the Learnability Gap with Intermediate CoT and Teacher Assistants
Jul 02, 2025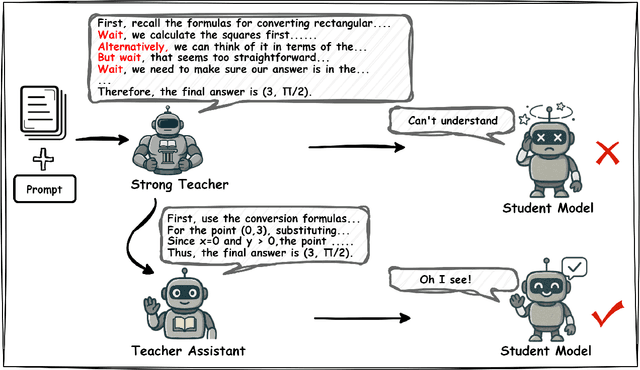
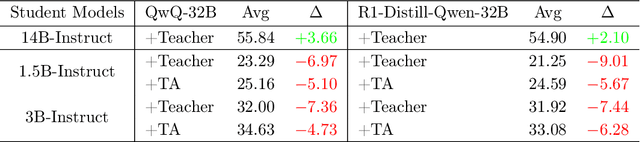
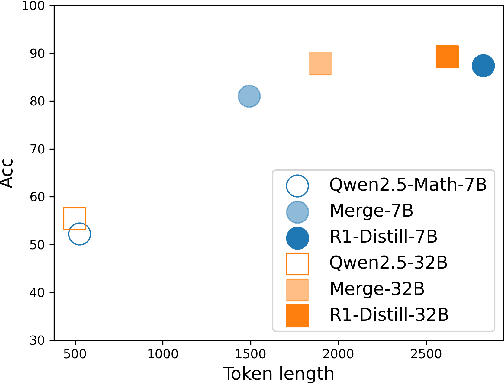
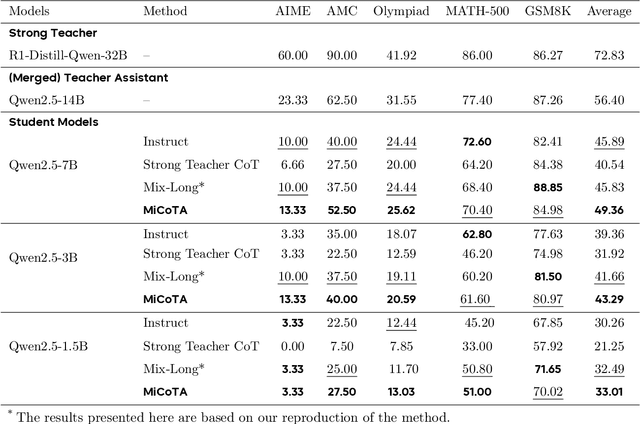
Large language models (LLMs) excel at reasoning tasks requiring long thought sequences for planning, reflection, and refinement. However, their substantial model size and high computational demands are impractical for widespread deployment. Yet, small language models (SLMs) often struggle to learn long-form CoT reasoning due to their limited capacity, a phenomenon we refer to as the "SLMs Learnability Gap". To address this, we introduce \textbf{Mi}d-\textbf{Co}T \textbf{T}eacher \textbf{A}ssistant Distillation (MiCoTAl), a framework for improving long CoT distillation for SLMs. MiCoTA employs intermediate-sized models as teacher assistants and utilizes intermediate-length CoT sequences to bridge both the capacity and reasoning length gaps. Our experiments on downstream tasks demonstrate that although SLMs distilled from large teachers can perform poorly, by applying MiCoTA, they achieve significant improvements in reasoning performance. Specifically, Qwen2.5-7B-Instruct and Qwen2.5-3B-Instruct achieve an improvement of 3.47 and 3.93 respectively on average score on AIME2024, AMC, Olympiad, MATH-500 and GSM8K benchmarks. To better understand the mechanism behind MiCoTA, we perform a quantitative experiment demonstrating that our method produces data more closely aligned with base SLM distributions. Our insights pave the way for future research into long-CoT data distillation for SLMs.
PersonaFeedback: A Large-scale Human-annotated Benchmark For Personalization
Jun 15, 2025With the rapid improvement in the general capabilities of LLMs, LLM personalization, i.e., how to build LLM systems that can generate personalized responses or services that are tailored to distinct user personas, has become an increasingly important research and engineering problem. However, unlike many new challenging benchmarks being released for evaluating the general/reasoning capabilities, the lack of high-quality benchmarks for evaluating LLM personalization greatly hinders progress in this field. To address this, we introduce PersonaFeedback, a new benchmark that directly evaluates LLMs' ability to provide personalized responses given pre-defined user personas and queries. Unlike existing benchmarks that require models to infer implicit user personas from historical interactions, PersonaFeedback decouples persona inference from personalization, focusing on evaluating the model's ability to generate responses tailored to explicit personas. PersonaFeedback consists of 8298 human-annotated test cases, which are categorized into easy, medium, and hard tiers based on the contextual complexity of the user personas and the difficulty in distinguishing subtle differences between two personalized responses. We conduct comprehensive evaluations across a wide range of models. The empirical results reveal that even state-of-the-art LLMs that can solve complex real-world reasoning tasks could fall short on the hard tier of PersonaFeedback where even human evaluators may find the distinctions challenging. Furthermore, we conduct an in-depth analysis of failure modes across various types of systems, demonstrating that the current retrieval-augmented framework should not be seen as a de facto solution for personalization tasks. All benchmark data, annotation protocols, and the evaluation pipeline will be publicly available to facilitate future research on LLM personalization.