 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComputation Offloading and Resource Allocation in F-RANs: A Federated Deep Reinforcement Learning Approach
Jun 13, 2022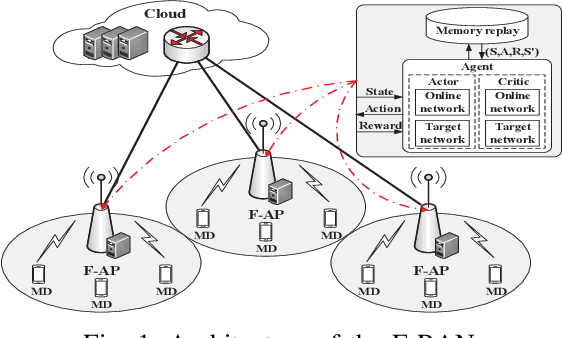
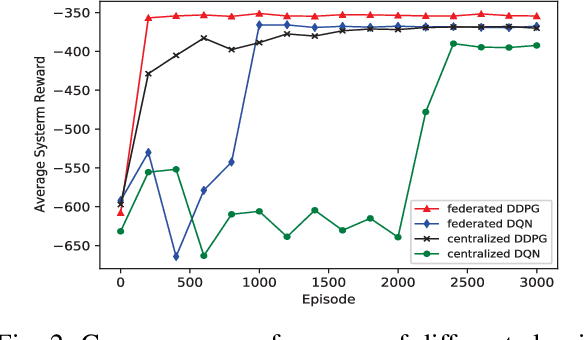
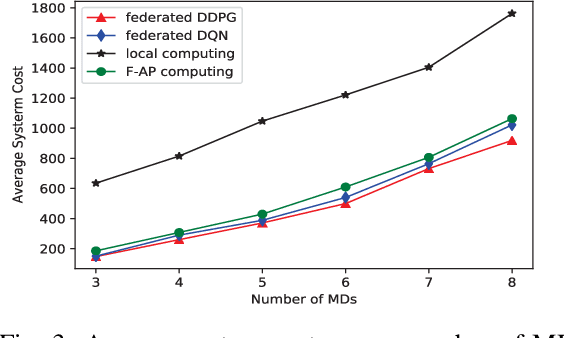
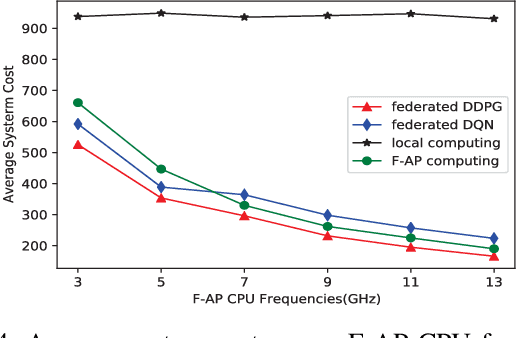
The fog radio access network (F-RAN) is a promising technology in which the user mobile devices (MDs) can offload computation tasks to the nearby fog access points (F-APs). Due to the limited resource of F-APs, it is important to design an efficient task offloading scheme. In this paper, by considering time-varying network environment, a dynamic computation offloading and resource allocation problem in F-RANs is formulated to minimize the task execution delay and energy consumption of MDs. To solve the problem, a federated deep reinforcement learning (DRL) based algorithm is proposed, where the deep deterministic policy gradient (DDPG) algorithm performs computation offloading and resource allocation in each F-AP. Federated learning is exploited to train the DDPG agents in order to decrease the computing complexity of training process and protect the user privacy. Simulation results show that the proposed federated DDPG algorithm can achieve lower task execution delay and energy consumption of MDs more quickly compared with the other existing strategies.
Xavier-Enabled Extreme Reservoir Machine for Millimeter-Wave Beamspace Channel Tracking
Jun 01, 2022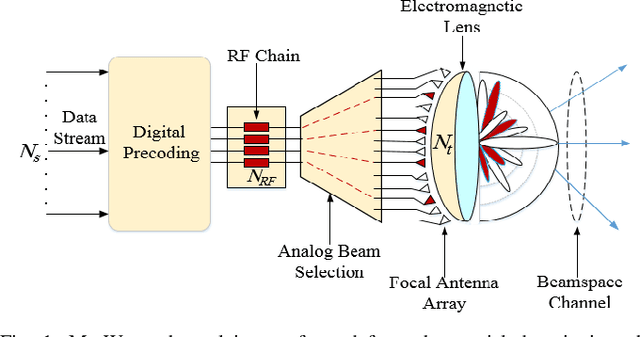
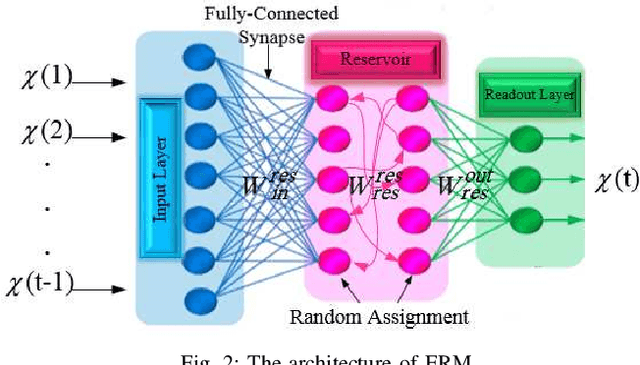
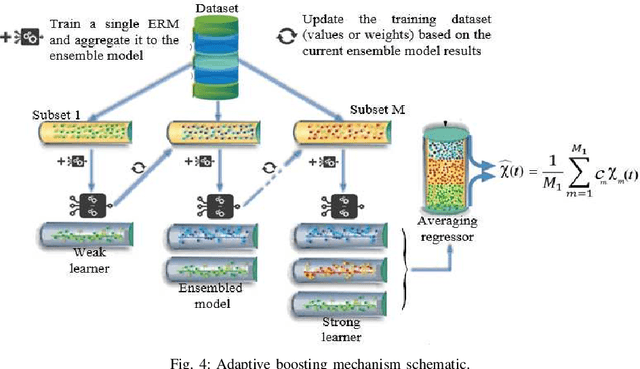
In this paper, we propose an accurate two-phase millimeter-Wave (mmWave) beamspace channel tracking mechanism. Particularly in the first phase, we train an extreme reservoir machine (ERM) for tracking the historical features of the mmWave beamspace channel and predicting them in upcoming time steps. Towards a more accurate prediction, we further fine-tune the ERM by means of Xavier initializer technique, whereby the input weights in ERM are initially derived from a zero mean and finite variance Gaussian distribution, leading to 49% degradation in prediction variance of the conventional ERM. The proposed method numerically improves the achievable spectral efficiency (SE) of the existing counterparts, by 13%, when signal-to-noise-ratio (SNR) is 15dB. We further investigate an ensemble learning technique in the second phase by sequentially incorporating multiple ERMs to form an ensembled model, namely adaptive boosting (AdaBoost), which further reduces the prediction variance in conventional ERM by 56%, and concludes in 21% enhancement of achievable SE upon the existing schemes at SNR=15dB.
Cell-Free MmWave Massive MIMO Systems with Low-Capacity Fronthaul Links and Low-Resolution ADC/DACs
May 16, 2022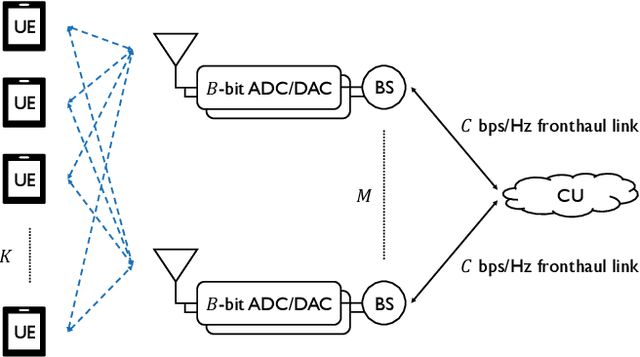
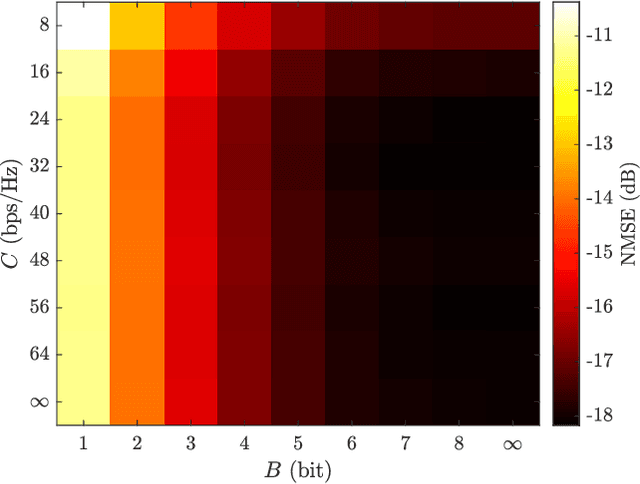
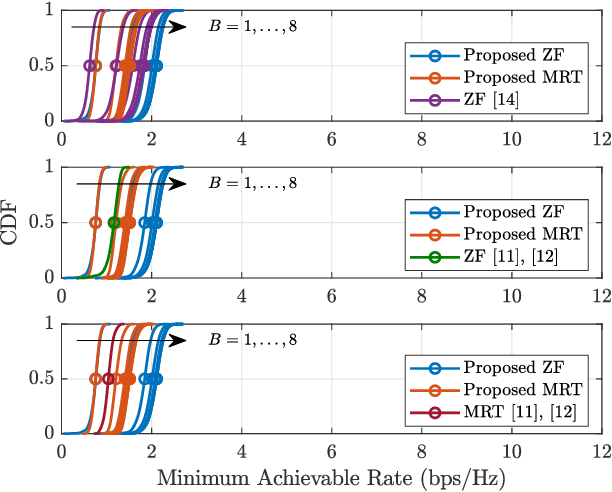
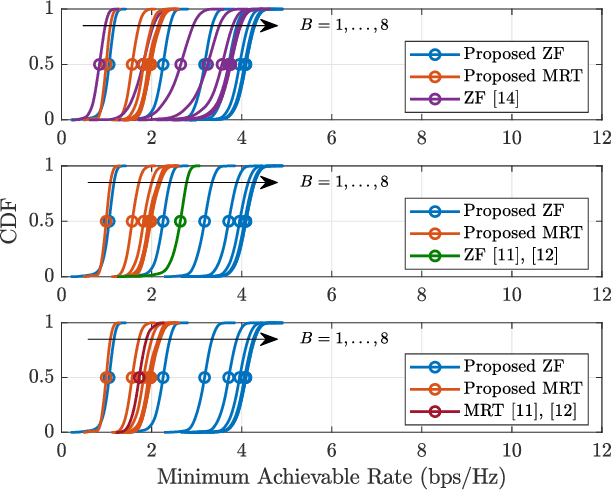
In this paper, we consider the uplink channel estimation phase and downlink data transmission phase of cell-free millimeter wave (mmWave) massive multiple-input multiple-output (MIMO) systems with low-capacity fronthaul links and low-resolution analog-to-digital converters/digital-to-analog converters (ADC/DACs). In cell-free massive MIMO, a control unit dictates the baseband processing at a geographical scale, while the base stations communicate with the control unit through fronthaul links. Unlike most of previous works in cell-free massive MIMO with finite-capacity fronthaul links, we consider the general case where the fronthaul capacity and ADC/DAC resolution are not necessarily the same. In particular, the fronthaul compression and ADC/DAC quantization occur independently where each one is modeled based on the information theoretic argument and additive quantization noise model (AQNM). Then, we address the codebook design problem that aims to minimize the channel estimation error for the independent and identically distributed (i.i.d.) and colored compression noise cases. Also, we propose an alternating optimization (AO) method to tackle the max-min fairness problem. In essence, the AO method alternates between two subproblems that correspond to the power allocation and codebook design problems. The AO method proposed for the zero-forcing (ZF) precoder is guaranteed to converge, whereas the one for the maximum ratio transmission (MRT) precoder has no such guarantee. Finally, the performance of the proposed schemes is evaluated by the simulation results in terms of both energy and spectral efficiency. The numerical results show that the proposed scheme for the ZF precoder yields spectral and energy efficiency 28% and 15% higher than that of the best baseline.
Pervasive Machine Learning for Smart Radio Environments Enabled by Reconfigurable Intelligent Surfaces
May 08, 2022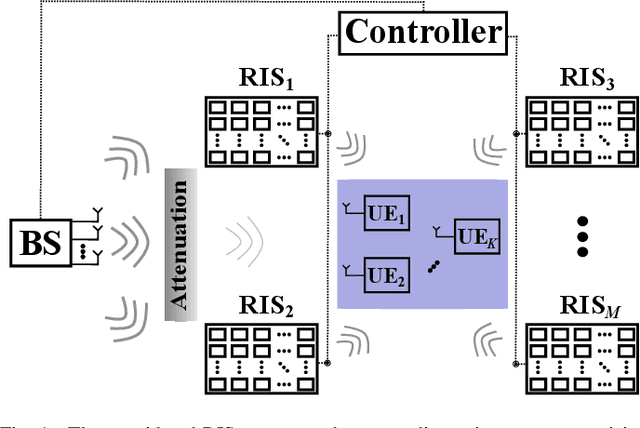
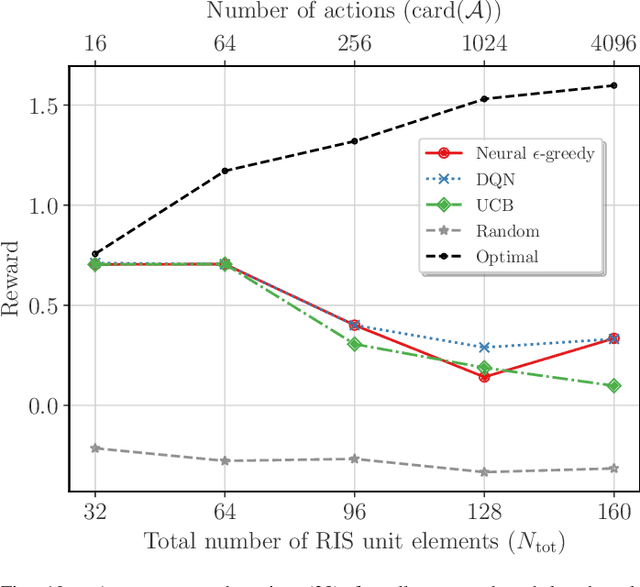
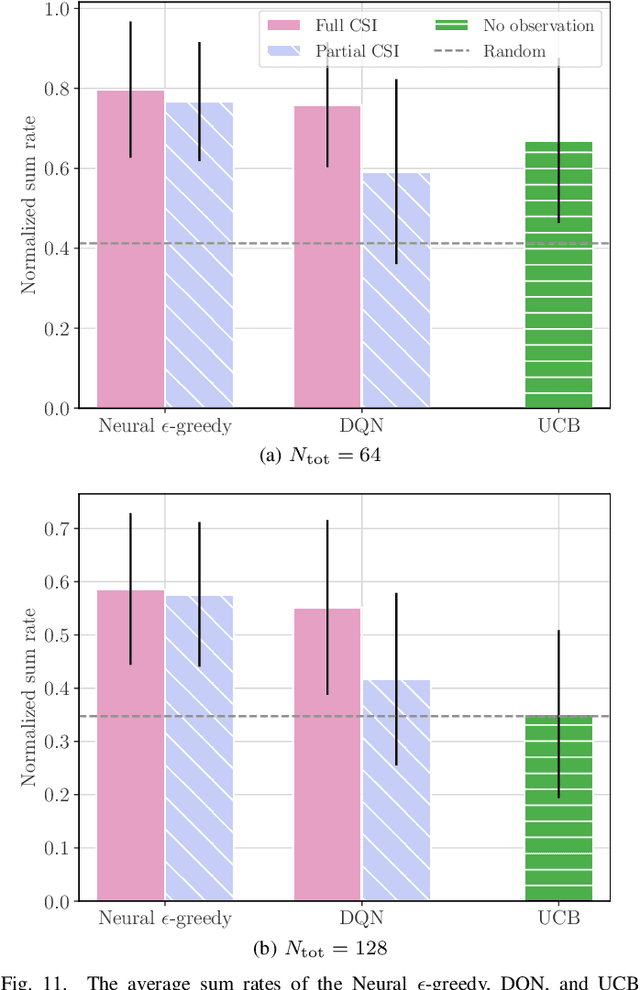
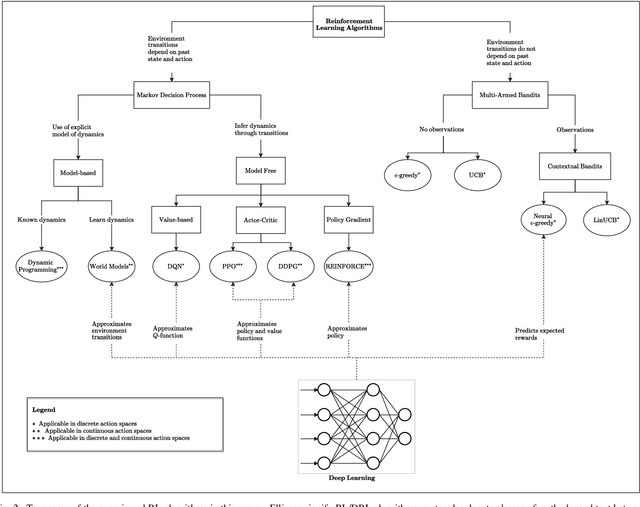
The emerging technology of Reconfigurable Intelligent Surfaces (RISs) is provisioned as an enabler of smart wireless environments, offering a highly scalable, low-cost, hardware-efficient, and almost energy-neutral solution for dynamic control of the propagation of electromagnetic signals over the wireless medium, ultimately providing increased environmental intelligence for diverse operation objectives. One of the major challenges with the envisioned dense deployment of RISs in such reconfigurable radio environments is the efficient configuration of multiple metasurfaces with limited, or even the absence of, computing hardware. In this paper, we consider multi-user and multi-RIS-empowered wireless systems, and present a thorough survey of the online machine learning approaches for the orchestration of their various tunable components. Focusing on the sum-rate maximization as a representative design objective, we present a comprehensive problem formulation based on Deep Reinforcement Learning (DRL). We detail the correspondences among the parameters of the wireless system and the DRL terminology, and devise generic algorithmic steps for the artificial neural network training and deployment, while discussing their implementation details. Further practical considerations for multi-RIS-empowered wireless communications in the sixth Generation (6G) era are presented along with some key open research challenges. Differently from the DRL-based status quo, we leverage the independence between the configuration of the system design parameters and the future states of the wireless environment, and present efficient multi-armed bandits approaches, whose resulting sum-rate performances are numerically shown to outperform random configurations, while being sufficiently close to the conventional Deep Q-Network (DQN) algorithm, but with lower implementation complexity.
Autonomy and Intelligence in the Computing Continuum: Challenges, Enablers, and Future Directions for Orchestration
May 03, 2022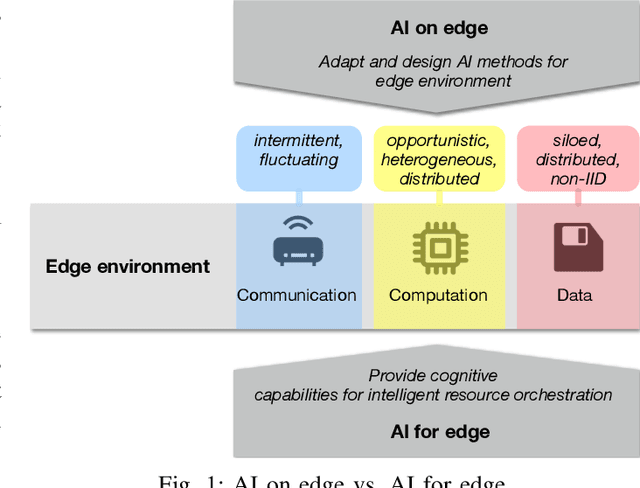
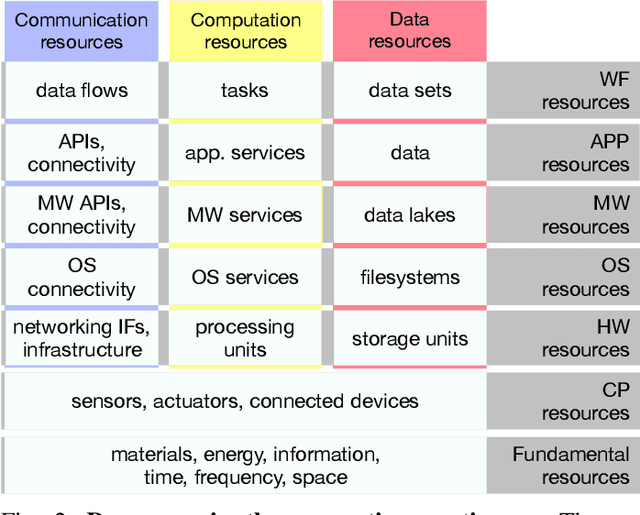
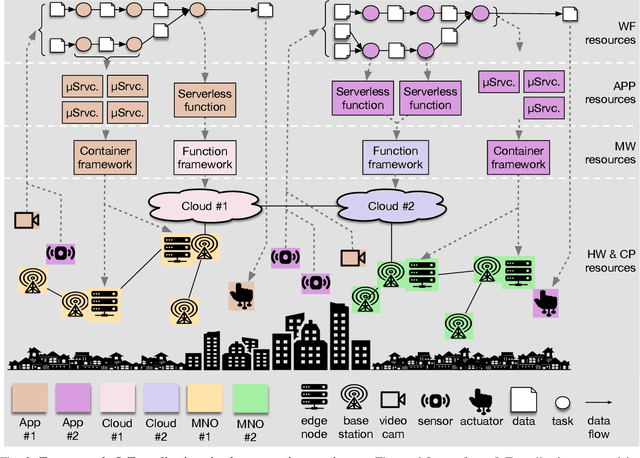
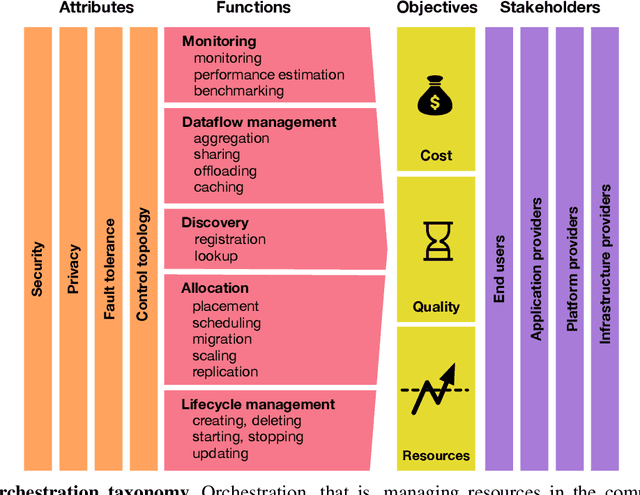
Future AI applications require performance, reliability and privacy that the existing, cloud-dependant system architectures cannot provide. In this article, we study orchestration in the device-edge-cloud continuum, and focus on AI for edge, that is, the AI methods used in resource orchestration. We claim that to support the constantly growing requirements of intelligent applications in the device-edge-cloud computing continuum, resource orchestration needs to embrace edge AI and emphasize local autonomy and intelligence. To justify the claim, we provide a general definition for continuum orchestration, and look at how current and emerging orchestration paradigms are suitable for the computing continuum. We describe certain major emerging research themes that may affect future orchestration, and provide an early vision of an orchestration paradigm that embraces those research themes. Finally, we survey current key edge AI methods and look at how they may contribute into fulfilling the vision of future continuum orchestration.
Time-triggered Federated Learning over Wireless Networks
May 02, 2022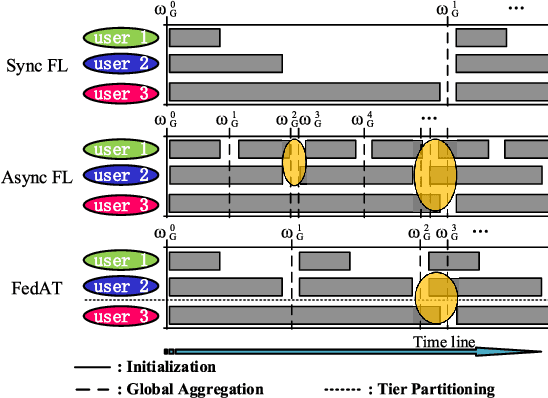
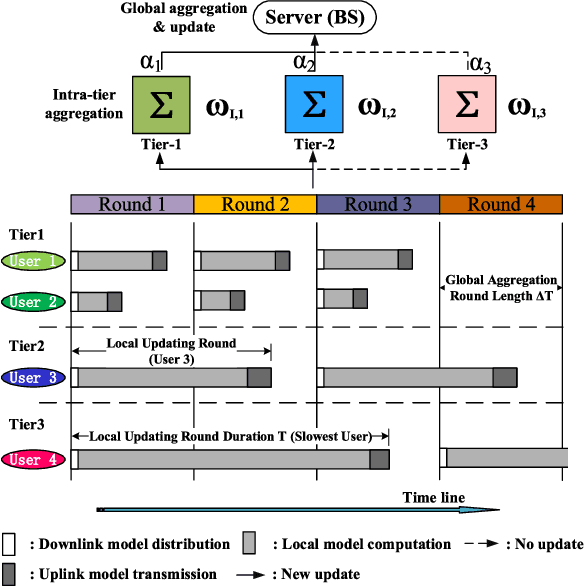
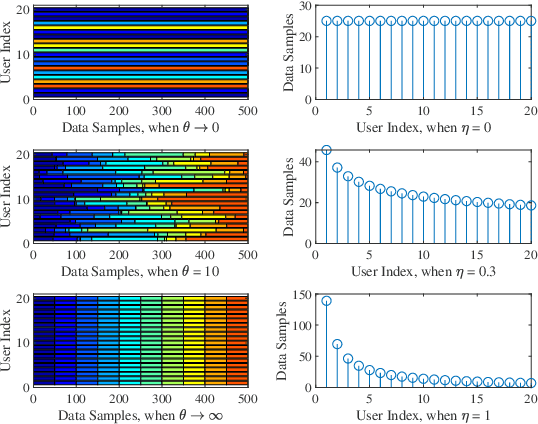
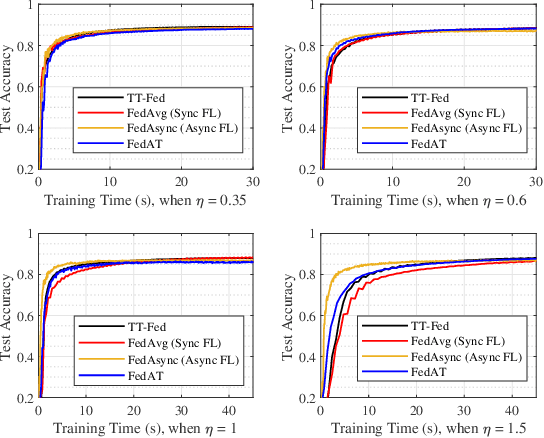
The newly emerging federated learning (FL) framework offers a new way to train machine learning models in a privacy-preserving manner. However, traditional FL algorithms are based on an event-triggered aggregation, which suffers from stragglers and communication overhead issues. To address these issues, in this paper, we present a time-triggered FL algorithm (TT-Fed) over wireless networks, which is a generalized form of classic synchronous and asynchronous FL. Taking the constrained resource and unreliable nature of wireless communication into account, we jointly study the user selection and bandwidth optimization problem to minimize the FL training loss. To solve this joint optimization problem, we provide a thorough convergence analysis for TT-Fed. Based on the obtained analytical convergence upper bound, the optimization problem is decomposed into tractable sub-problems with respect to each global aggregation round, and finally solved by our proposed online search algorithm. Simulation results show that compared to asynchronous FL (FedAsync) and FL with asynchronous user tiers (FedAT) benchmarks, our proposed TT-Fed algorithm improves the converged test accuracy by up to 12.5% and 5%, respectively, under highly imbalanced and non-IID data, while substantially reducing the communication overhead.
SlimFL: Federated Learning with Superposition Coding over Slimmable Neural Networks
Mar 26, 2022
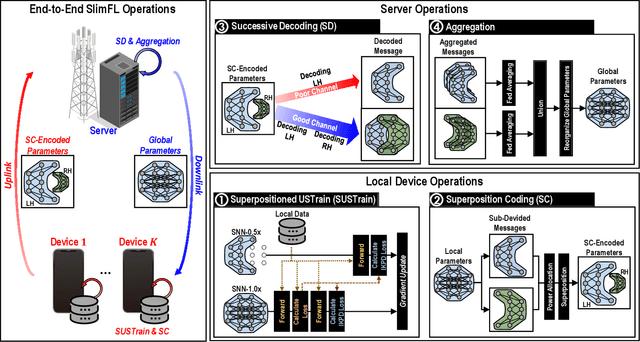
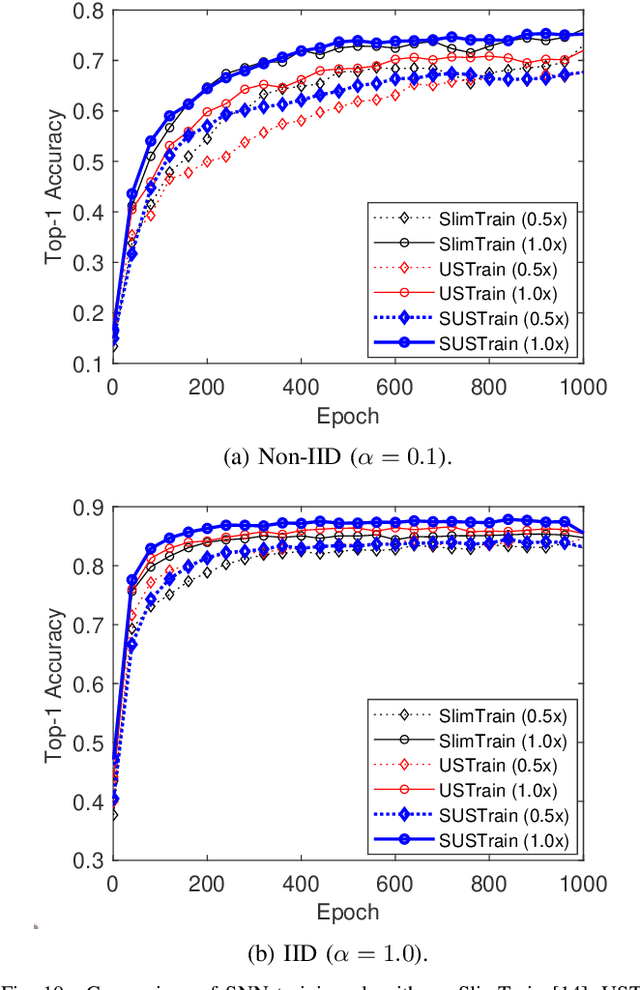
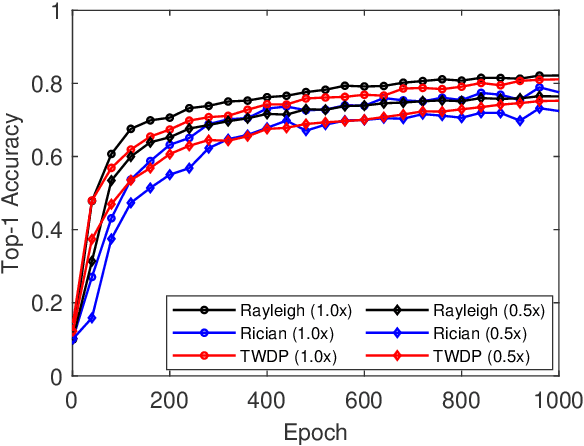
Federated learning (FL) is a key enabler for efficient communication and computing leveraging devices' distributed computing capabilities. However, applying FL in practice is challenging due to the local devices' heterogeneous energy, wireless channel conditions, and non-independently and identically distributed (non-IID) data distributions. To cope with these issues, this paper proposes a novel learning framework by integrating FL and width-adjustable slimmable neural networks (SNN). Integrating FL with SNNs is challenging due to time-varing channel conditions and data distributions. In addition, existing multi-width SNN training algorithms are sensitive to the data distributions across devices, which makes SNN ill-suited for FL. Motivated by this, we propose a communication and energy-efficient SNN-based FL (named SlimFL) that jointly utilizes superposition coding (SC) for global model aggregation and superposition training (ST) for updating local models. By applying SC, SlimFL exchanges the superposition of multiple width configurations decoded as many times as possible for a given communication throughput. Leveraging ST, SlimFL aligns the forward propagation of different width configurations while avoiding inter-width interference during backpropagation. We formally prove the convergence of SlimFL. The result reveals that SlimFL is not only communication-efficient but also deals with the non-IID data distributions and poor channel conditions, which is also corroborated by data-intensive simulations.
Deep Contextual Bandits for Orchestrating Multi-User MISO Systems with Multiple RISs
Feb 16, 2022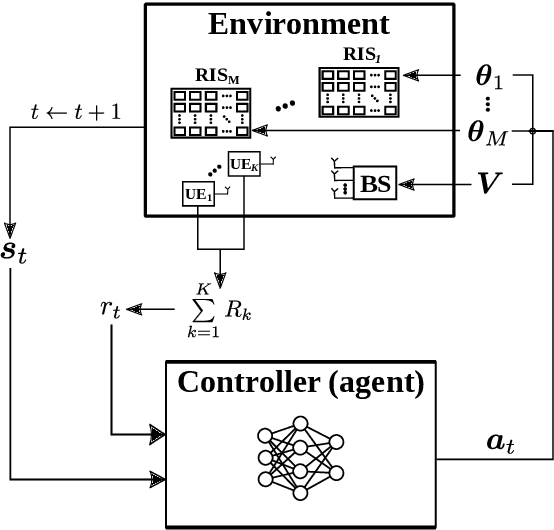
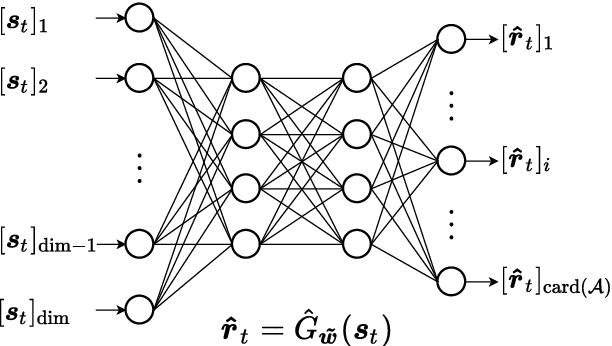
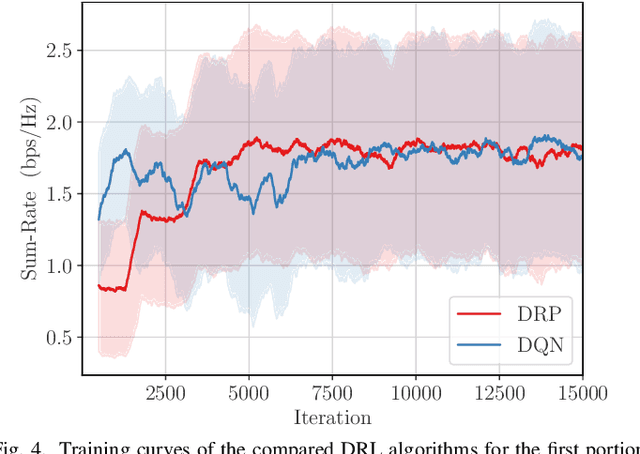
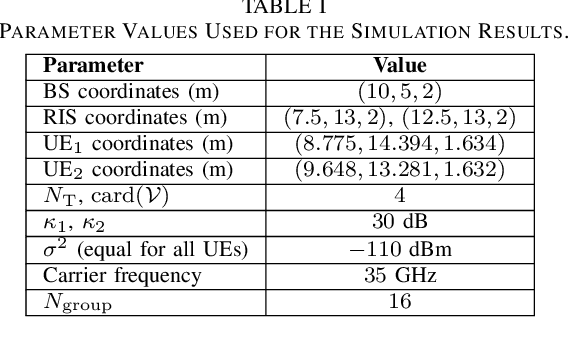
The emergent technology of Reconfigurable Intelligent Surfaces (RISs) has the potential to transform wireless environments into controllable systems, through programmable propagation of information-bearing signals. Techniques stemming from the field of Deep Reinforcement Learning (DRL) have recently gained popularity in maximizing the sum-rate performance in multi-user communication systems empowered by RISs. Such approaches are commonly based on Markov Decision Processes (MDPs). In this paper, we instead investigate the sum-rate design problem under the scope of the Multi-Armed Bandits (MAB) setting, which is a relaxation of the MDP framework. Nevertheless, in many cases, the MAB formulation is more appropriate to the channel and system models under the assumptions typically made in the RIS literature. To this end, we propose a simpler DRL approach for orchestrating multiple metasurfaces in RIS-empowered multi-user Multiple-Input Single-Output (MISO) systems, which we numerically show to perform equally well with a state-of-the-art MDP-based approach, while being less demanding computationally.
Variational Autoencoders for Reliability Optimization in Multi-Access Edge Computing Networks
Jan 25, 2022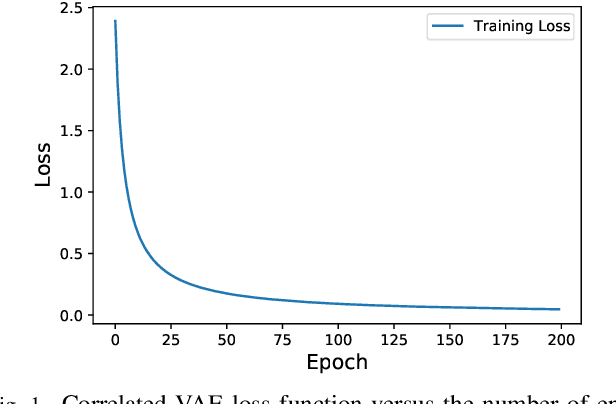
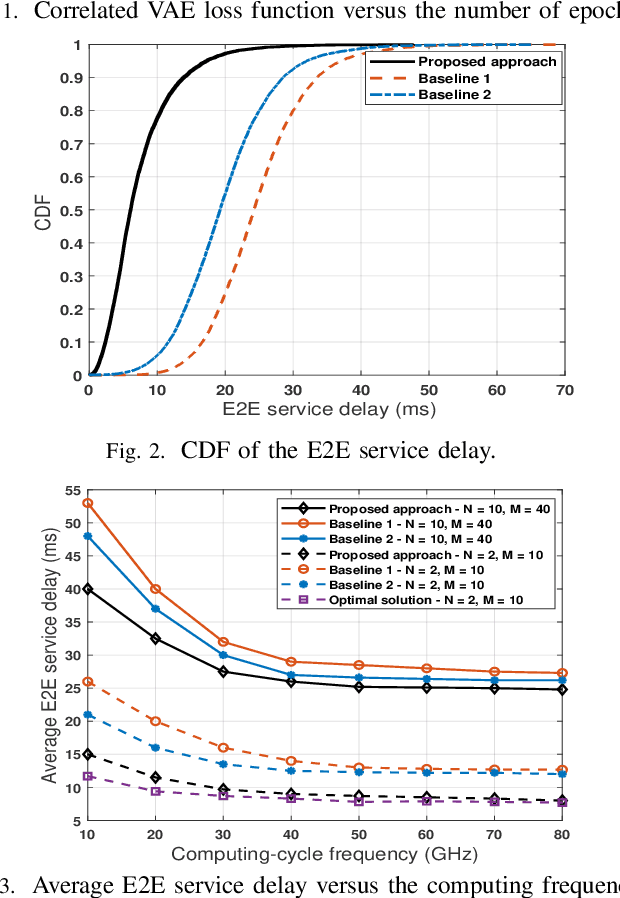
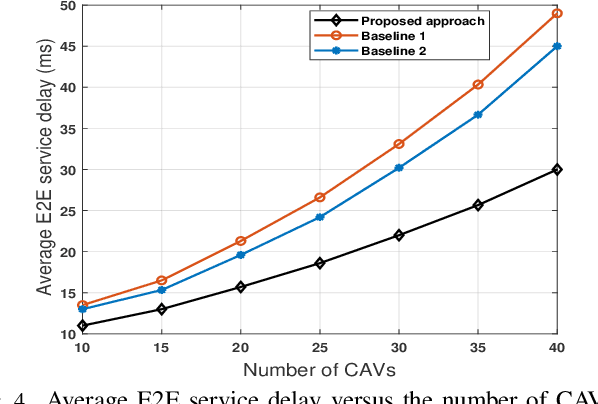
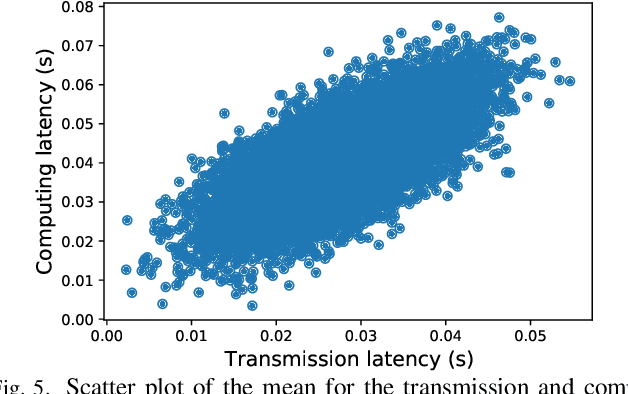
Multi-access edge computing (MEC) is viewed as an integral part of future wireless networks to support new applications with stringent service reliability and latency requirements. However, guaranteeing ultra-reliable and low-latency MEC (URLL MEC) is very challenging due to uncertainties of wireless links, limited communications and computing resources, as well as dynamic network traffic. Enabling URLL MEC mandates taking into account the statistics of the end-to-end (E2E) latency and reliability across the wireless and edge computing systems. In this paper, a novel framework is proposed to optimize the reliability of MEC networks by considering the distribution of E2E service delay, encompassing over-the-air transmission and edge computing latency. The proposed framework builds on correlated variational autoencoders (VAEs) to estimate the full distribution of the E2E service delay. Using this result, a new optimization problem based on risk theory is formulated to maximize the network reliability by minimizing the Conditional Value at Risk (CVaR) as a risk measure of the E2E service delay. To solve this problem, a new algorithm is developed to efficiently allocate users' processing tasks to edge computing servers across the MEC network, while considering the statistics of the E2E service delay learned by VAEs. The simulation results show that the proposed scheme outperforms several baselines that do not account for the risk analyses or statistics of the E2E service delay.
THz-Empowered UAVs in 6G: Opportunities, Challenges, and Trade-Offs
Jan 13, 2022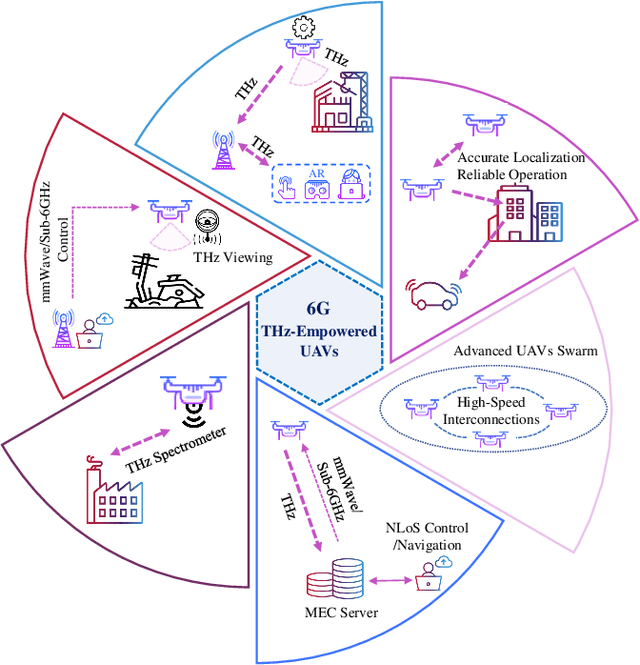
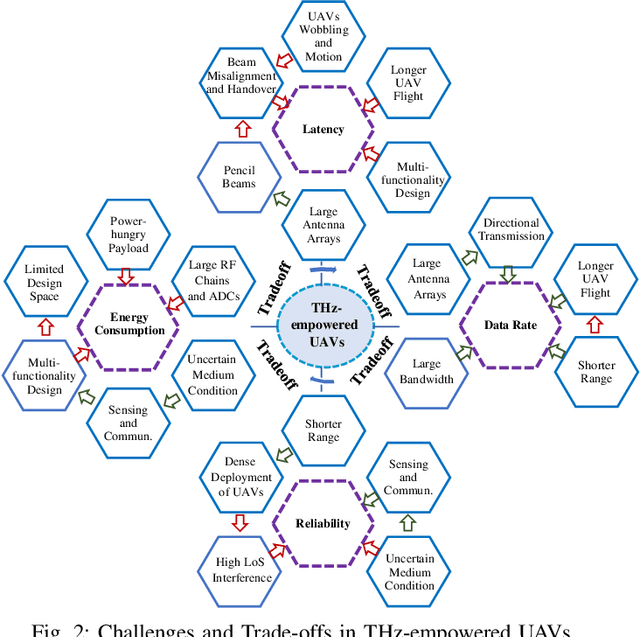
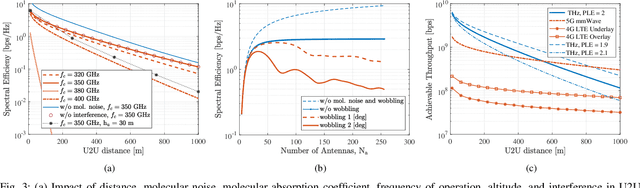
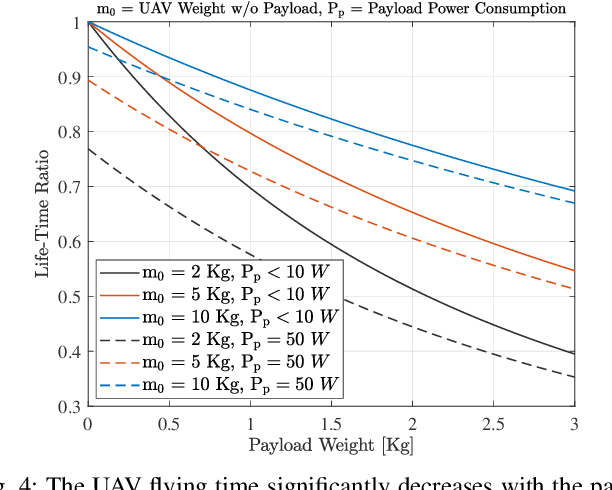
Envisioned use cases of unmanned aerial vehicles (UAVs) impose new service requirements in terms of data rate, latency, and sensing accuracy, to name a few. If such requirements are satisfactorily met, it can create novel applications and enable highly reliable and harmonized integration of UAVs in the 6G network ecosystem. Towards this, terahertz (THz) bands are perceived as a prospective technological enabler for various improved functionalities such as ultra-high throughput and enhanced sensing capabilities. This paper focuses on THzempowered UAVs with the following capabilities: communication, sensing, localization, imaging, and control. We review the potential opportunities and use cases of THz-empowered UAVs, corresponding novel design challenges, and resulting trade-offs. Furthermore, we overview recent advances in UAV deployments regulations, THz standardization, and health aspects related to THz bands. Finally, we take UAV to UAV (U2U) communication as a case-study to provide numerical insights into the impact of various system design parameters and environment factors.