 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Stage Evolutionary Model Merging with Meta Data Driven Curriculum Learning for Sentiment-Specialized Large Language Modeling
Jan 11, 2026The emergence of large language models (LLMs) has significantly transformed natural language processing (NLP), enabling more generalized models to perform various tasks with minimal training. However, traditional sentiment analysis methods, which focus on individual tasks such as sentiment classification or aspect-based analysis, are not practical for real-world applications that usually require handling multiple tasks. While offering flexibility, LLMs in sentiment-specific tasks often fall short of the required accuracy. Techniques like fine-tuning and evolutionary model merging help integrate models into a unified framework, which can improve the learning performance while reducing computational costs. The use of task meta-data and curriculum learning to optimize learning processes remains underexplored, while sentiment analysis is a critical task in NLP that requires high accuracy and scalability across multiple subtasks. In this study, we propose a hybrid learning model called Multi-stage Evolutionary Model Merging with Meta data driven Curriculum Learning (MEM-MCL), to enhance the sentiment analysis in large language modeling. In particular, expert models are created through instruction tuning for specific sentiment tasks and then merged using evolutionary algorithms to form a unified model. The merging process is optimized with weak data to enhance performance across tasks. The curriculum learning is incorporated to provide a learning sequence based on task difficulty, improving knowledge extraction from LLMs. Experiment results demonstrate that the proposed MEM-MCL model outperforms conventional LLMs in a majority of sentiment analysis tasks, achieving superior results across various subtasks.
CIEGAD: Cluster-Conditioned Interpolative and Extrapolative Framework for Geometry-Aware and Domain-Aligned Data Augmentation
Dec 11, 2025



In practical deep learning deployment, the scarcity of data and the imbalance of label distributions often lead to semantically uncovered regions within the real-world data distribution, hindering model training and causing misclassification near class boundaries as well as unstable behaviors in peripheral areas. Although recent large language models (LLMs) show promise for data augmentation, an integrated framework that simultaneously achieves directional control of generation, domain alignment, and quality control has not yet been fully established. To address these challenges, we propose a Cluster-conditioned Interpolative and Extrapolative framework for Geometry-Aware and Domain-aligned data augmentation (CIEGAD), which systematically complements both in-distribution and out-of-distribution semantically uncovered regions. CIEGAD constructs domain profiles through cluster conditioning, allocates generation with a hierarchical frequency-geometric allocation integrating class frequency and geometric indicators, and finely controls generation directions via the coexistence of interpolative and extrapolative synthesis. It further performs quality control through geometry-constrained filtering combined with an LLM-as-a-Judge mechanism. Experiments on multiple classification tasks demonstrate that CIEGAD effectively extends the periphery of real-world data distributions while maintaining high alignment between generated and real-world data as well as semantic diversity. In particular, for long-tailed and multi-class classification tasks, CIEGAD consistently improves F1 and recall, validating the triple harmony of distributional consistency, diversity, and quality. These results indicate that CIEGAD serves as a practically oriented data augmentation framework that complements underrepresented regions while preserving alignment with real-world data.
Disentangling Emotional Bases and Transient Fluctuations: A Low-Rank Sparse Decomposition Approach for Video Affective Analysis
Nov 14, 2025Video-based Affective Computing (VAC), vital for emotion analysis and human-computer interaction, suffers from model instability and representational degradation due to complex emotional dynamics. Since the meaning of different emotional fluctuations may differ under different emotional contexts, the core limitation is the lack of a hierarchical structural mechanism to disentangle distinct affective components, i.e., emotional bases (the long-term emotional tone), and transient fluctuations (the short-term emotional fluctuations). To address this, we propose the Low-Rank Sparse Emotion Understanding Framework (LSEF), a unified model grounded in the Low-Rank Sparse Principle, which theoretically reframes affective dynamics as a hierarchical low-rank sparse compositional process. LSEF employs three plug-and-play modules, i.e., the Stability Encoding Module (SEM) captures low-rank emotional bases; the Dynamic Decoupling Module (DDM) isolates sparse transient signals; and the Consistency Integration Module (CIM) reconstructs multi-scale stability and reactivity coherence. This framework is optimized by a Rank Aware Optimization (RAO) strategy that adaptively balances gradient smoothness and sensitivity. Extensive experiments across multiple datasets confirm that LSEF significantly enhances robustness and dynamic discrimination, which further validates the effectiveness and generality of hierarchical low-rank sparse modeling for understanding affective dynamics.
Time-triggered Federated Learning over Wireless Networks
May 02, 2022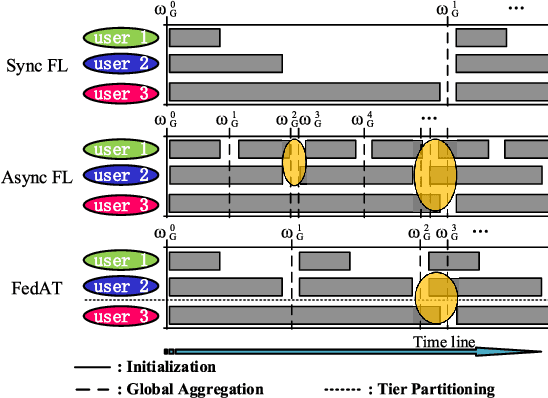
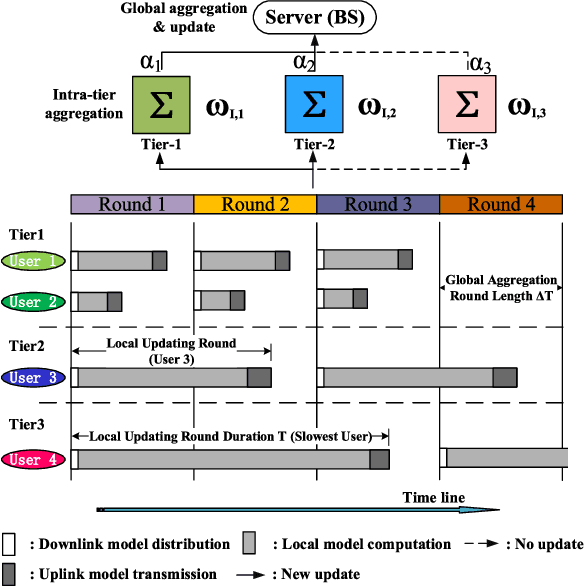
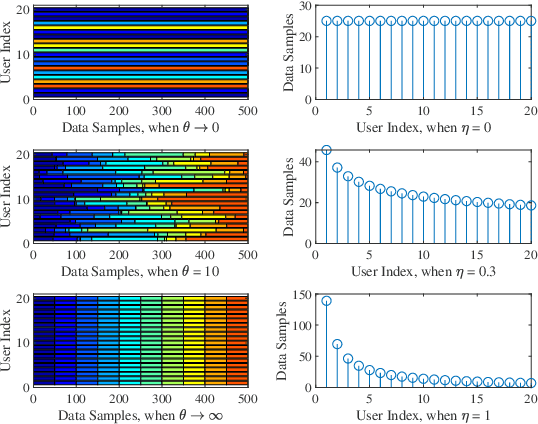
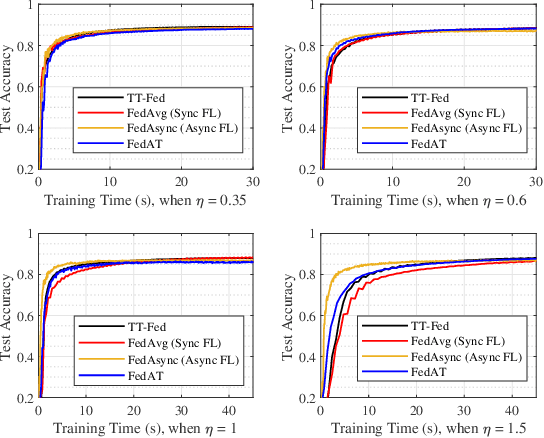
The newly emerging federated learning (FL) framework offers a new way to train machine learning models in a privacy-preserving manner. However, traditional FL algorithms are based on an event-triggered aggregation, which suffers from stragglers and communication overhead issues. To address these issues, in this paper, we present a time-triggered FL algorithm (TT-Fed) over wireless networks, which is a generalized form of classic synchronous and asynchronous FL. Taking the constrained resource and unreliable nature of wireless communication into account, we jointly study the user selection and bandwidth optimization problem to minimize the FL training loss. To solve this joint optimization problem, we provide a thorough convergence analysis for TT-Fed. Based on the obtained analytical convergence upper bound, the optimization problem is decomposed into tractable sub-problems with respect to each global aggregation round, and finally solved by our proposed online search algorithm. Simulation results show that compared to asynchronous FL (FedAsync) and FL with asynchronous user tiers (FedAT) benchmarks, our proposed TT-Fed algorithm improves the converged test accuracy by up to 12.5% and 5%, respectively, under highly imbalanced and non-IID data, while substantially reducing the communication overhead.