 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModular Visual Question Answering via Code Generation
Jun 08, 2023We present a framework that formulates visual question answering as modular code generation. In contrast to prior work on modular approaches to VQA, our approach requires no additional training and relies on pre-trained language models (LMs), visual models pre-trained on image-caption pairs, and fifty VQA examples used for in-context learning. The generated Python programs invoke and compose the outputs of the visual models using arithmetic and conditional logic. Our approach improves accuracy on the COVR dataset by at least 3% and on the GQA dataset by roughly 2% compared to the few-shot baseline that does not employ code generation.
Learning and Verification of Task Structure in Instructional Videos
Mar 23, 2023



Given the enormous number of instructional videos available online, learning a diverse array of multi-step task models from videos is an appealing goal. We introduce a new pre-trained video model, VideoTaskformer, focused on representing the semantics and structure of instructional videos. We pre-train VideoTaskformer using a simple and effective objective: predicting weakly supervised textual labels for steps that are randomly masked out from an instructional video (masked step modeling). Compared to prior work which learns step representations locally, our approach involves learning them globally, leveraging video of the entire surrounding task as context. From these learned representations, we can verify if an unseen video correctly executes a given task, as well as forecast which steps are likely to be taken after a given step. We introduce two new benchmarks for detecting mistakes in instructional videos, to verify if there is an anomalous step and if steps are executed in the right order. We also introduce a long-term forecasting benchmark, where the goal is to predict long-range future steps from a given step. Our method outperforms previous baselines on these tasks, and we believe the tasks will be a valuable way for the community to measure the quality of step representations. Additionally, we evaluate VideoTaskformer on 3 existing benchmarks -- procedural activity recognition, step classification, and step forecasting -- and demonstrate on each that our method outperforms existing baselines and achieves new state-of-the-art performance.
TL;DW? Summarizing Instructional Videos with Task Relevance & Cross-Modal Saliency
Aug 14, 2022
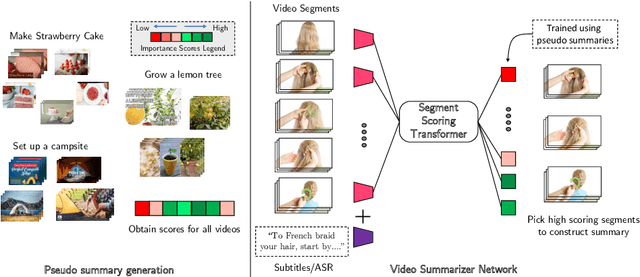
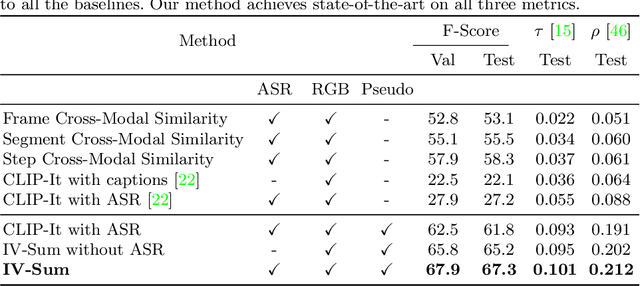
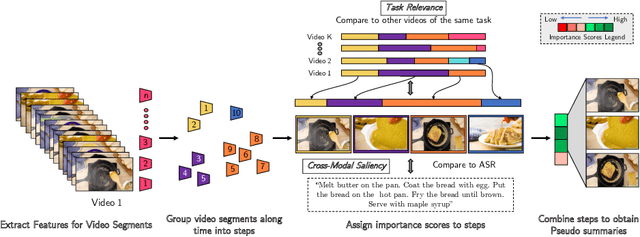
YouTube users looking for instructions for a specific task may spend a long time browsing content trying to find the right video that matches their needs. Creating a visual summary (abridged version of a video) provides viewers with a quick overview and massively reduces search time. In this work, we focus on summarizing instructional videos, an under-explored area of video summarization. In comparison to generic videos, instructional videos can be parsed into semantically meaningful segments that correspond to important steps of the demonstrated task. Existing video summarization datasets rely on manual frame-level annotations, making them subjective and limited in size. To overcome this, we first automatically generate pseudo summaries for a corpus of instructional videos by exploiting two key assumptions: (i) relevant steps are likely to appear in multiple videos of the same task (Task Relevance), and (ii) they are more likely to be described by the demonstrator verbally (Cross-Modal Saliency). We propose an instructional video summarization network that combines a context-aware temporal video encoder and a segment scoring transformer. Using pseudo summaries as weak supervision, our network constructs a visual summary for an instructional video given only video and transcribed speech. To evaluate our model, we collect a high-quality test set, WikiHow Summaries, by scraping WikiHow articles that contain video demonstrations and visual depictions of steps allowing us to obtain the ground-truth summaries. We outperform several baselines and a state-of-the-art video summarization model on this new benchmark.
Multi-Person 3D Motion Prediction with Multi-Range Transformers
Nov 23, 2021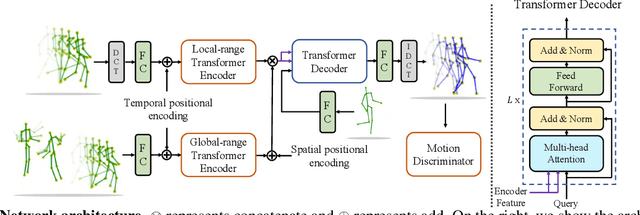
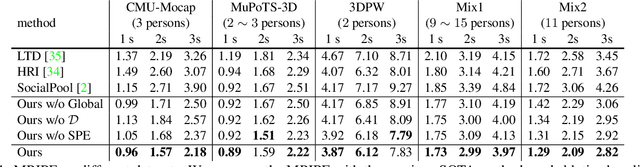

We propose a novel framework for multi-person 3D motion trajectory prediction. Our key observation is that a human's action and behaviors may highly depend on the other persons around. Thus, instead of predicting each human pose trajectory in isolation, we introduce a Multi-Range Transformers model which contains of a local-range encoder for individual motion and a global-range encoder for social interactions. The Transformer decoder then performs prediction for each person by taking a corresponding pose as a query which attends to both local and global-range encoder features. Our model not only outperforms state-of-the-art methods on long-term 3D motion prediction, but also generates diverse social interactions. More interestingly, our model can even predict 15-person motion simultaneously by automatically dividing the persons into different interaction groups. Project page with code is available at https://jiashunwang.github.io/MRT/.
CLIP-It! Language-Guided Video Summarization
Jul 01, 2021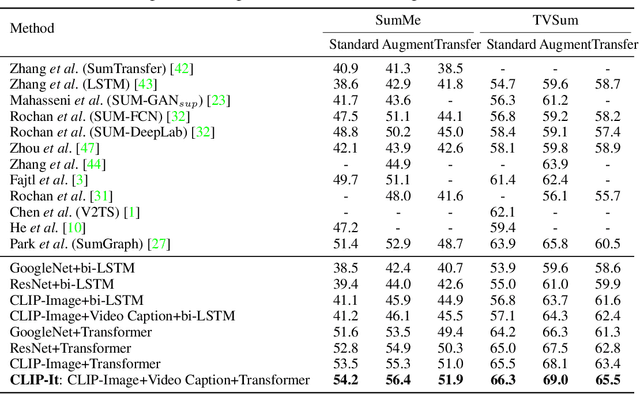
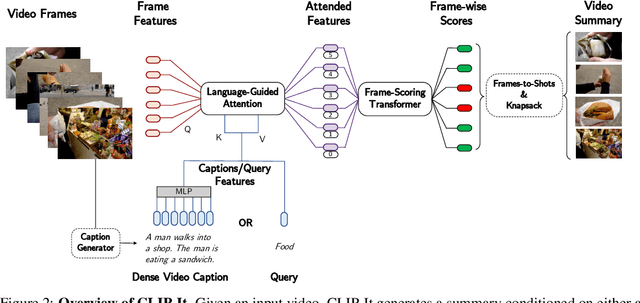
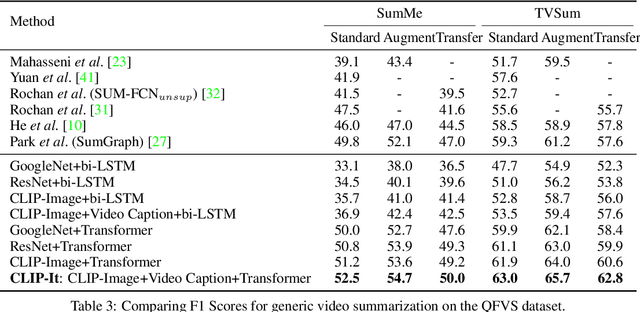
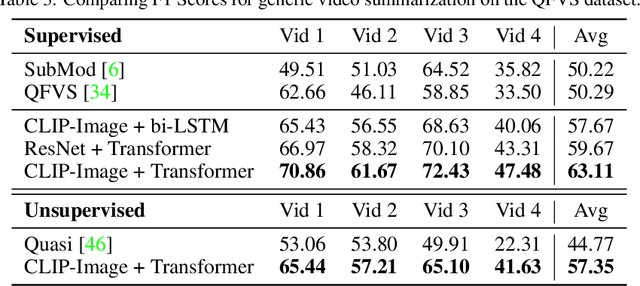
A generic video summary is an abridged version of a video that conveys the whole story and features the most important scenes. Yet the importance of scenes in a video is often subjective, and users should have the option of customizing the summary by using natural language to specify what is important to them. Further, existing models for fully automatic generic summarization have not exploited available language models, which can serve as an effective prior for saliency. This work introduces CLIP-It, a single framework for addressing both generic and query-focused video summarization, typically approached separately in the literature. We propose a language-guided multimodal transformer that learns to score frames in a video based on their importance relative to one another and their correlation with a user-defined query (for query-focused summarization) or an automatically generated dense video caption (for generic video summarization). Our model can be extended to the unsupervised setting by training without ground-truth supervision. We outperform baselines and prior work by a significant margin on both standard video summarization datasets (TVSum and SumMe) and a query-focused video summarization dataset (QFVS). Particularly, we achieve large improvements in the transfer setting, attesting to our method's strong generalization capabilities.
Strumming to the Beat: Audio-Conditioned Contrastive Video Textures
Apr 06, 2021
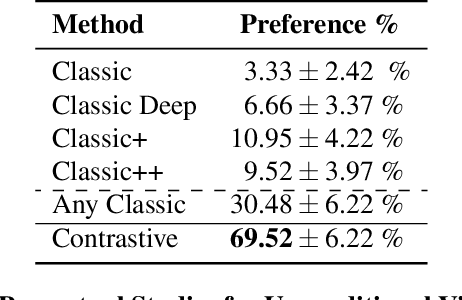

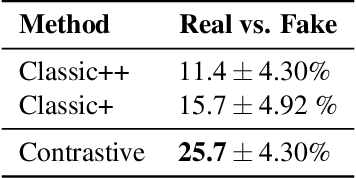
We introduce a non-parametric approach for infinite video texture synthesis using a representation learned via contrastive learning. We take inspiration from Video Textures, which showed that plausible new videos could be generated from a single one by stitching its frames together in a novel yet consistent order. This classic work, however, was constrained by its use of hand-designed distance metrics, limiting its use to simple, repetitive videos. We draw on recent techniques from self-supervised learning to learn this distance metric, allowing us to compare frames in a manner that scales to more challenging dynamics, and to condition on other data, such as audio. We learn representations for video frames and frame-to-frame transition probabilities by fitting a video-specific model trained using contrastive learning. To synthesize a texture, we randomly sample frames with high transition probabilities to generate diverse temporally smooth videos with novel sequences and transitions. The model naturally extends to an audio-conditioned setting without requiring any finetuning. Our model outperforms baselines on human perceptual scores, can handle a diverse range of input videos, and can combine semantic and audio-visual cues in order to synthesize videos that synchronize well with an audio signal.
Seeing the Un-Scene: Learning Amodal Semantic Maps for Room Navigation
Jul 20, 2020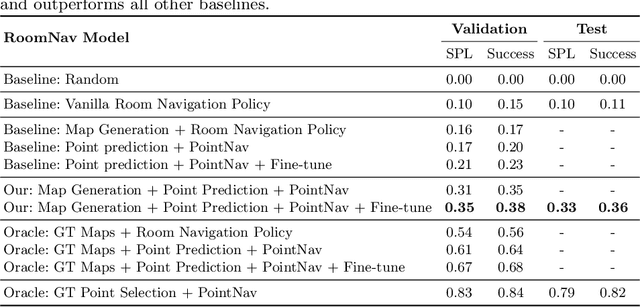
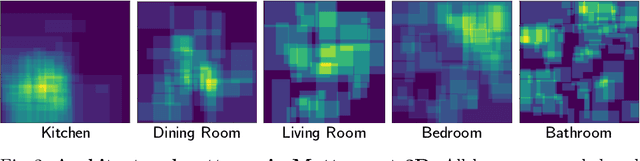
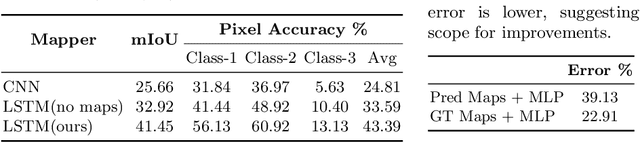
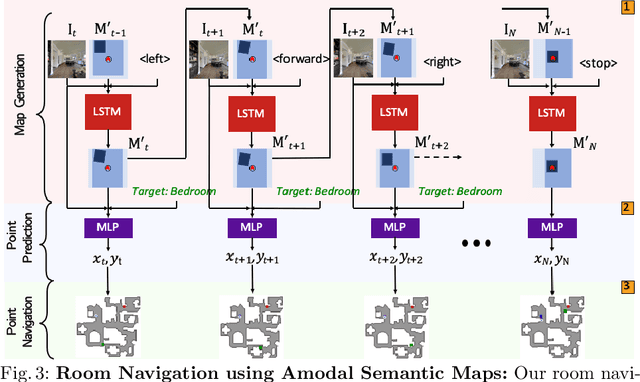
We introduce a learning-based approach for room navigation using semantic maps. Our proposed architecture learns to predict top-down belief maps of regions that lie beyond the agent's field of view while modeling architectural and stylistic regularities in houses. First, we train a model to generate amodal semantic top-down maps indicating beliefs of location, size, and shape of rooms by learning the underlying architectural patterns in houses. Next, we use these maps to predict a point that lies in the target room and train a policy to navigate to the point. We empirically demonstrate that by predicting semantic maps, the model learns common correlations found in houses and generalizes to novel environments. We also demonstrate that reducing the task of room navigation to point navigation improves the performance further.
Out of the Box: Reasoning with Graph Convolution Nets for Factual Visual Question Answering
Nov 01, 2018

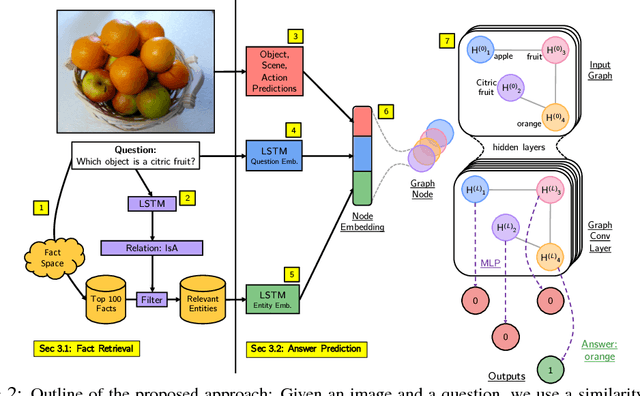
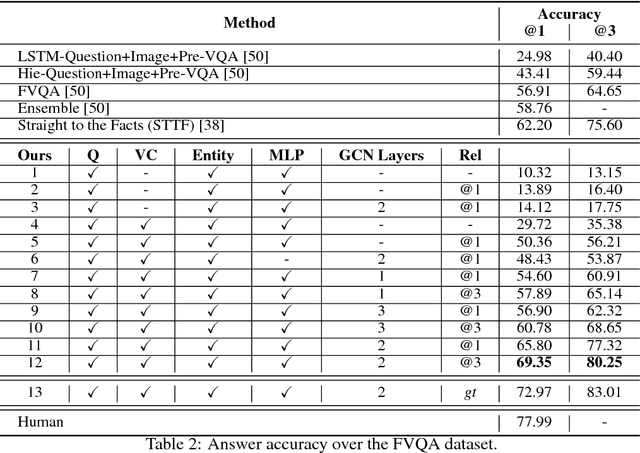
Accurately answering a question about a given image requires combining observations with general knowledge. While this is effortless for humans, reasoning with general knowledge remains an algorithmic challenge. To advance research in this direction a novel `fact-based' visual question answering (FVQA) task has been introduced recently along with a large set of curated facts which link two entities, i.e., two possible answers, via a relation. Given a question-image pair, deep network techniques have been employed to successively reduce the large set of facts until one of the two entities of the final remaining fact is predicted as the answer. We observe that a successive process which considers one fact at a time to form a local decision is sub-optimal. Instead, we develop an entity graph and use a graph convolutional network to `reason' about the correct answer by jointly considering all entities. We show on the challenging FVQA dataset that this leads to an improvement in accuracy of around 7% compared to the state of the art.
Straight to the Facts: Learning Knowledge Base Retrieval for Factual Visual Question Answering
Sep 04, 2018

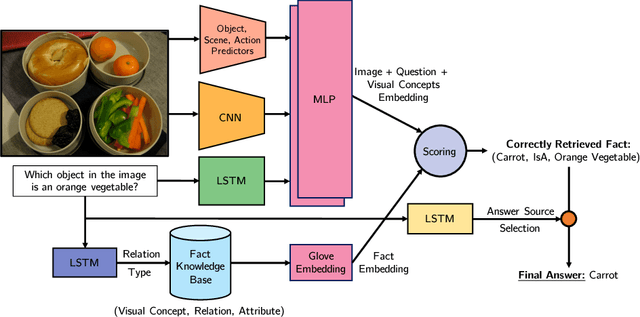

Question answering is an important task for autonomous agents and virtual assistants alike and was shown to support the disabled in efficiently navigating an overwhelming environment. Many existing methods focus on observation-based questions, ignoring our ability to seamlessly combine observed content with general knowledge. To understand interactions with a knowledge base, a dataset has been introduced recently and keyword matching techniques were shown to yield compelling results despite being vulnerable to misconceptions due to synonyms and homographs. To address this issue, we develop a learning-based approach which goes straight to the facts via a learned embedding space. We demonstrate state-of-the-art results on the challenging recently introduced fact-based visual question answering dataset, outperforming competing methods by more than 5%.