 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUDAPDR: Unsupervised Domain Adaptation via LLM Prompting and Distillation of Rerankers
Mar 01, 2023



Many information retrieval tasks require large labeled datasets for fine-tuning. However, such datasets are often unavailable, and their utility for real-world applications can diminish quickly due to domain shifts. To address this challenge, we develop and motivate a method for using large language models (LLMs) to generate large numbers of synthetic queries cheaply. The method begins by generating a small number of synthetic queries using an expensive LLM. After that, a much less expensive one is used to create large numbers of synthetic queries, which are used to fine-tune a family of reranker models. These rerankers are then distilled into a single efficient retriever for use in the target domain. We show that this technique boosts zero-shot accuracy in long-tail domains, even where only 2K synthetic queries are used for fine-tuning, and that it achieves substantially lower latency than standard reranking methods. We make our end-to-end approach, including our synthetic datasets and replication code, publicly available on Github.
Knowledge Distillation $\approx$ Label Smoothing: Fact or Fallacy?
Feb 06, 2023



Contrary to its original interpretation as a facilitator of knowledge transfer from one model to another, some recent studies have suggested that knowledge distillation (KD) is instead a form of regularization. Perhaps the strongest support of all for this claim is found in its apparent similarities with label smoothing (LS). This paper investigates the stated equivalence of these two methods by examining the predictive uncertainties of the models they train. Experiments on four text classification tasks involving teachers and students of different capacities show that: (a) In most settings, KD and LS drive model uncertainty (entropy) in completely opposite directions, and (b) In KD, the student's predictive uncertainty is a direct function of that of its teacher, reinforcing the knowledge transfer view.
PrimeQA: The Prime Repository for State-of-the-Art Multilingual Question Answering Research and Development
Jan 25, 2023



The field of Question Answering (QA) has made remarkable progress in recent years, thanks to the advent of large pre-trained language models, newer realistic benchmark datasets with leaderboards, and novel algorithms for key components such as retrievers and readers. In this paper, we introduce PRIMEQA: a one-stop and open-source QA repository with an aim to democratize QA re-search and facilitate easy replication of state-of-the-art (SOTA) QA methods. PRIMEQA supports core QA functionalities like retrieval and reading comprehension as well as auxiliary capabilities such as question generation.It has been designed as an end-to-end toolkit for various use cases: building front-end applications, replicating SOTA methods on pub-lic benchmarks, and expanding pre-existing methods. PRIMEQA is available at : https://github.com/primeqa.
Moving Beyond Downstream Task Accuracy for Information Retrieval Benchmarking
Dec 02, 2022



Neural information retrieval (IR) systems have progressed rapidly in recent years, in large part due to the release of publicly available benchmarking tasks. Unfortunately, some dimensions of this progress are illusory: the majority of the popular IR benchmarks today focus exclusively on downstream task accuracy and thus conceal the costs incurred by systems that trade away efficiency for quality. Latency, hardware cost, and other efficiency considerations are paramount to the deployment of IR systems in user-facing settings. We propose that IR benchmarks structure their evaluation methodology to include not only metrics of accuracy, but also efficiency considerations such as a query latency and the corresponding cost budget for a reproducible hardware setting. For the popular IR benchmarks MS MARCO and XOR-TyDi, we show how the best choice of IR system varies according to how these efficiency considerations are chosen and weighed. We hope that future benchmarks will adopt these guidelines toward more holistic IR evaluation.
SPARTAN: Sparse Hierarchical Memory for Parameter-Efficient Transformers
Nov 29, 2022



Fine-tuning pre-trained language models (PLMs) achieves impressive performance on a range of downstream tasks, and their sizes have consequently been getting bigger. Since a different copy of the model is required for each task, this paradigm is infeasible for storage-constrained edge devices like mobile phones. In this paper, we propose SPARTAN, a parameter efficient (PE) and computationally fast architecture for edge devices that adds hierarchically organized sparse memory after each Transformer layer. SPARTAN freezes the PLM parameters and fine-tunes only its memory, thus significantly reducing storage costs by re-using the PLM backbone for different tasks. SPARTAN contains two levels of memory, with only a sparse subset of parents being chosen in the first level for each input, and children cells corresponding to those parents being used to compute an output representation. This sparsity combined with other architecture optimizations improves SPARTAN's throughput by over 90% during inference on a Raspberry Pi 4 when compared to PE baselines (adapters) while also outperforming the latter by 0.1 points on the GLUE benchmark. Further, it can be trained 34% faster in a few-shot setting, while performing within 0.9 points of adapters. Qualitative analysis shows that different parent cells in SPARTAN specialize in different topics, thus dividing responsibility efficiently.
GAAMA 2.0: An Integrated System that Answers Boolean and Extractive Questions
Jun 21, 2022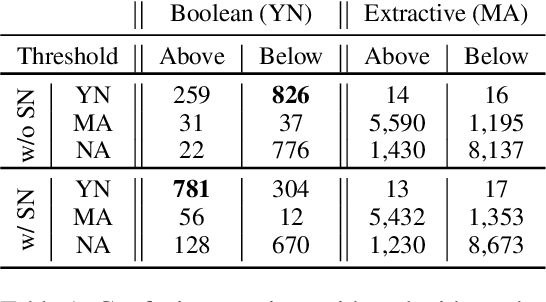
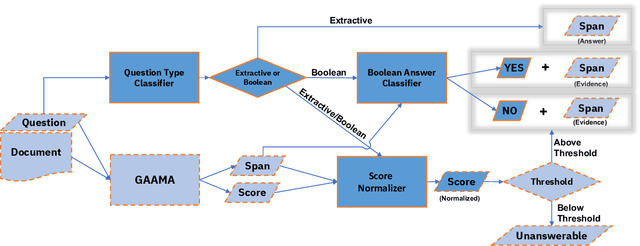


Recent machine reading comprehension datasets include extractive and boolean questions but current approaches do not offer integrated support for answering both question types. We present a multilingual machine reading comprehension system and front-end demo that handles boolean questions by providing both a YES/NO answer and highlighting supporting evidence, and handles extractive questions by highlighting the answer in the passage. Our system, GAAMA 2.0, is ranked first on the Tydi QA leaderboard at the time of this writing. We contrast two different implementations of our approach. The first includes several independent stacks of transformers allowing easy deployment of each component. The second is a single stack of transformers utilizing adapters to reduce GPU memory footprint in a resource-constrained environment.
Not to Overfit or Underfit? A Study of Domain Generalization in Question Answering
May 15, 2022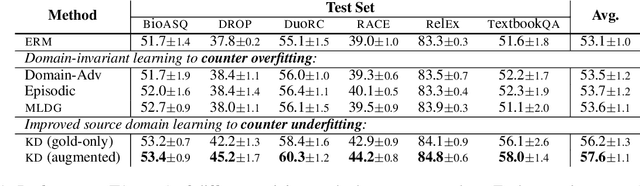
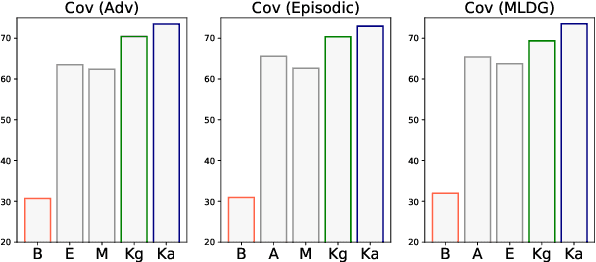
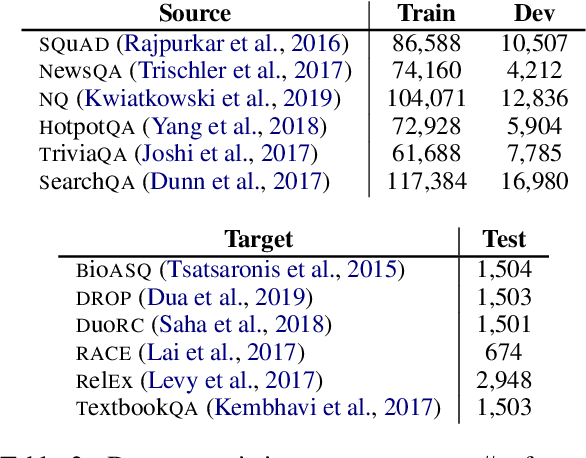
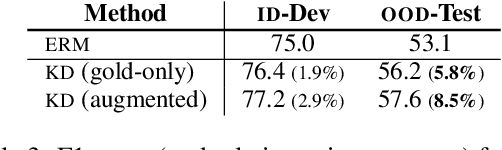
Machine learning models are prone to overfitting their source (training) distributions, which is commonly believed to be why they falter in novel target domains. Here we examine the contrasting view that multi-source domain generalization (DG) is in fact a problem of mitigating source domain underfitting: models not adequately learning the signal in their multi-domain training data. Experiments on a reading comprehension DG benchmark show that as a model gradually learns its source domains better -- using known methods such as knowledge distillation from a larger model -- its zero-shot out-of-domain accuracy improves at an even faster rate. Improved source domain learning also demonstrates superior generalization over three popular domain-invariant learning methods that aim to counter overfitting.
Entity-Conditioned Question Generation for Robust Attention Distribution in Neural Information Retrieval
Apr 24, 2022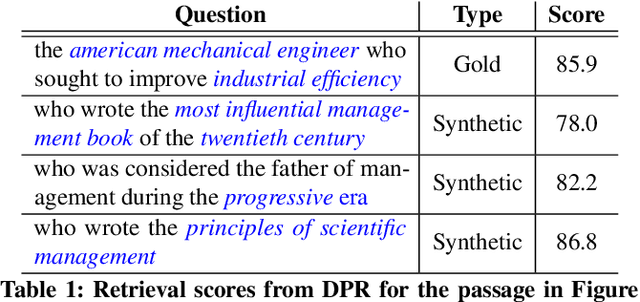
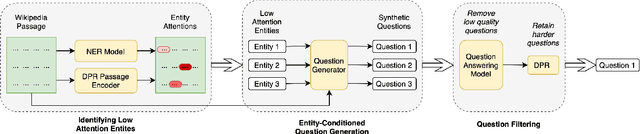

We show that supervised neural information retrieval (IR) models are prone to learning sparse attention patterns over passage tokens, which can result in key phrases including named entities receiving low attention weights, eventually leading to model under-performance. Using a novel targeted synthetic data generation method that identifies poorly attended entities and conditions the generation episodes on those, we teach neural IR to attend more uniformly and robustly to all entities in a given passage. On two public IR benchmarks, we empirically show that the proposed method helps improve both the model's attention patterns and retrieval performance, including in zero-shot settings.
Synthetic Target Domain Supervision for Open Retrieval QA
Apr 20, 2022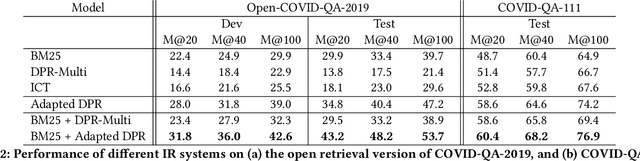
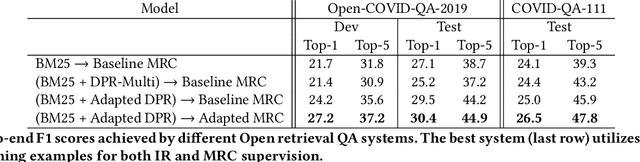
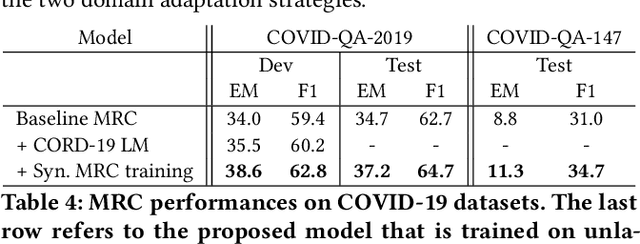
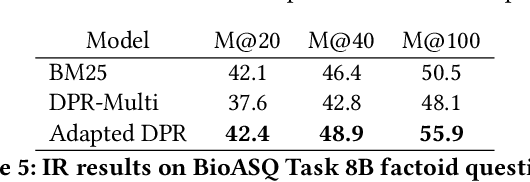
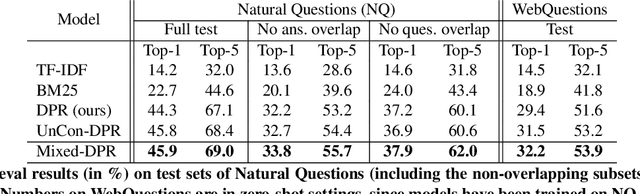
Neural passage retrieval is a new and promising approach in open retrieval question answering. In this work, we stress-test the Dense Passage Retriever (DPR) -- a state-of-the-art (SOTA) open domain neural retrieval model -- on closed and specialized target domains such as COVID-19, and find that it lags behind standard BM25 in this important real-world setting. To make DPR more robust under domain shift, we explore its fine-tuning with synthetic training examples, which we generate from unlabeled target domain text using a text-to-text generator. In our experiments, this noisy but fully automated target domain supervision gives DPR a sizable advantage over BM25 in out-of-domain settings, making it a more viable model in practice. Finally, an ensemble of BM25 and our improved DPR model yields the best results, further pushing the SOTA for open retrieval QA on multiple out-of-domain test sets.
Learning Cross-Lingual IR from an English Retriever
Dec 15, 2021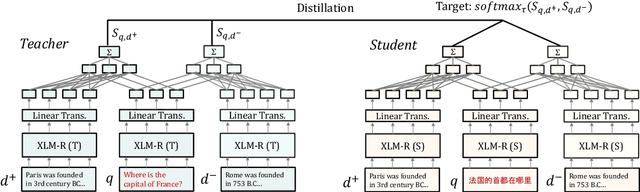
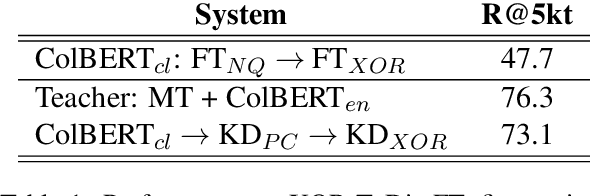
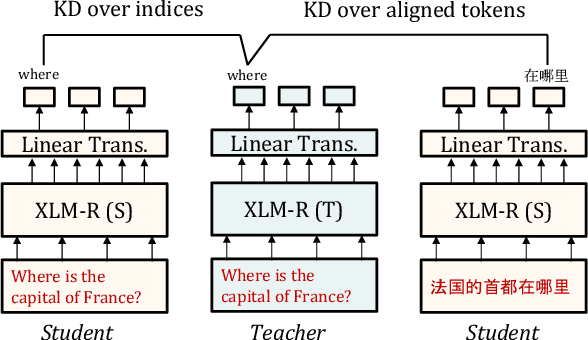
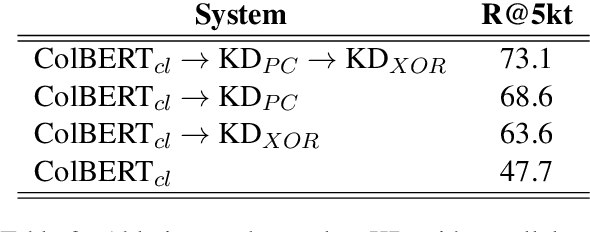
We present a new cross-lingual information retrieval (CLIR) model trained using multi-stage knowledge distillation (KD). The teacher and the student are heterogeneous systems-the former is a pipeline that relies on machine translation and monolingual IR, while the latter executes a single CLIR operation. We show that the student can learn both multilingual representations and CLIR by optimizing two corresponding KD objectives. Learning multilingual representations from an English-only retriever is accomplished using a novel cross-lingual alignment algorithm that greedily re-positions the teacher tokens for alignment. Evaluation on the XOR-TyDi benchmark shows that the proposed model is far more effective than the existing approach of fine-tuning with cross-lingual labeled IR data, with a gain in accuracy of 25.4 Recall@5kt.