 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHandoverSim: A Simulation Framework and Benchmark for Human-to-Robot Object Handovers
May 19, 2022

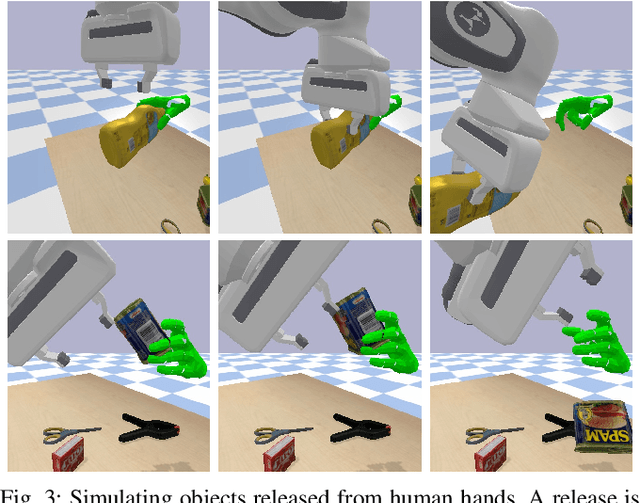

We introduce a new simulation benchmark "HandoverSim" for human-to-robot object handovers. To simulate the giver's motion, we leverage a recent motion capture dataset of hand grasping of objects. We create training and evaluation environments for the receiver with standardized protocols and metrics. We analyze the performance of a set of baselines and show a correlation with a real-world evaluation. Code is open sourced at https://handover-sim.github.io.
Model Predictive Control for Fluid Human-to-Robot Handovers
Mar 31, 2022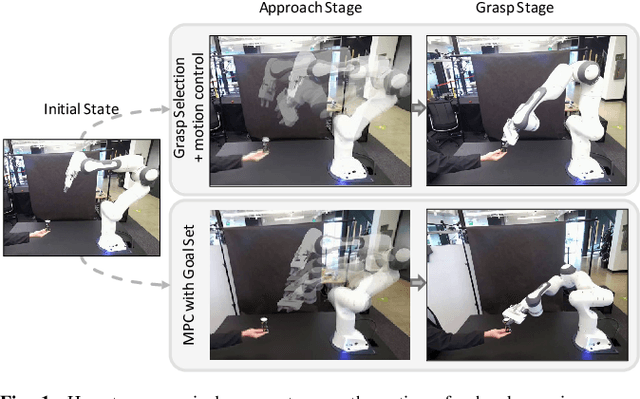


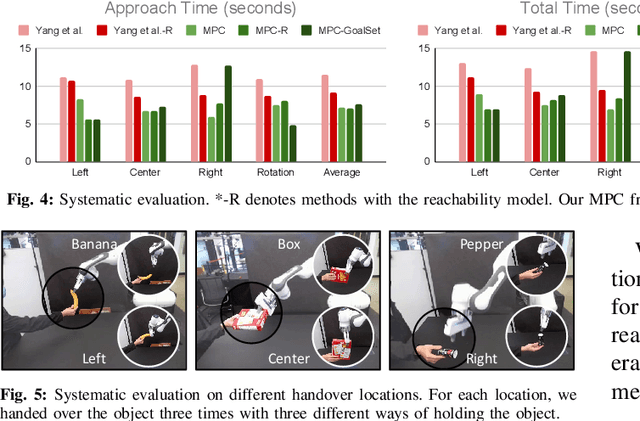
Human-robot handover is a fundamental yet challenging task in human-robot interaction and collaboration. Recently, remarkable progressions have been made in human-to-robot handovers of unknown objects by using learning-based grasp generators. However, how to responsively generate smooth motions to take an object from a human is still an open question. Specifically, planning motions that take human comfort into account is not a part of the human-robot handover process in most prior works. In this paper, we propose to generate smooth motions via an efficient model-predictive control (MPC) framework that integrates perception and complex domain-specific constraints into the optimization problem. We introduce a learning-based grasp reachability model to select candidate grasps which maximize the robot's manipulability, giving it more freedom to satisfy these constraints. Finally, we integrate a neural net force/torque classifier that detects contact events from noisy data. We conducted human-to-robot handover experiments on a diverse set of objects with several users (N=4) and performed a systematic evaluation of each module. The study shows that the users preferred our MPC approach over the baseline system by a large margin. More results and videos are available at https://sites.google.com/nvidia.com/mpc-for-handover.
Assistive Tele-op: Leveraging Transformers to Collect Robotic Task Demonstrations
Dec 09, 2021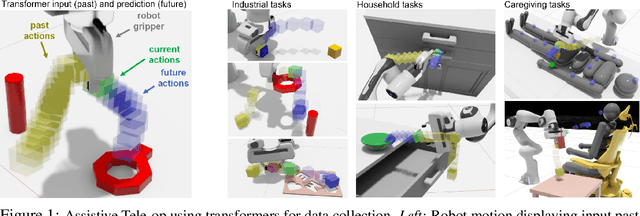
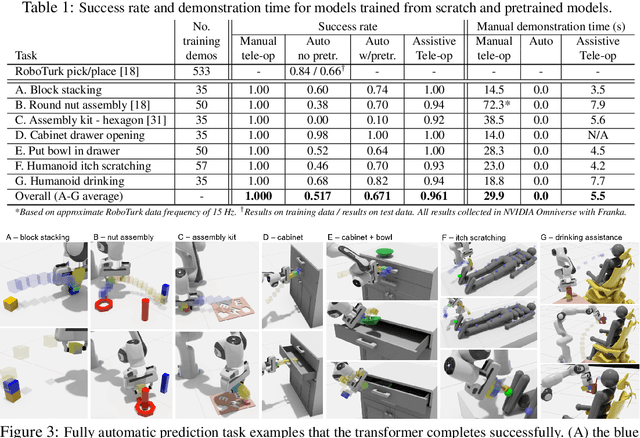
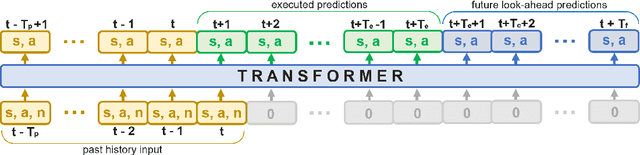
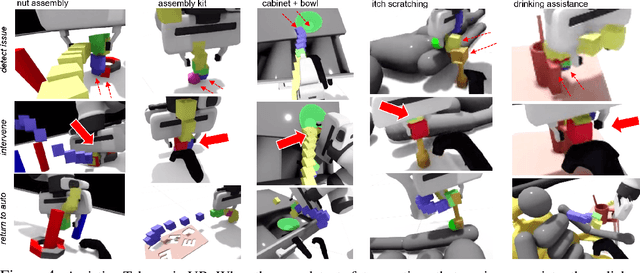
Sharing autonomy between robots and human operators could facilitate data collection of robotic task demonstrations to continuously improve learned models. Yet, the means to communicate intent and reason about the future are disparate between humans and robots. We present Assistive Tele-op, a virtual reality (VR) system for collecting robot task demonstrations that displays an autonomous trajectory forecast to communicate the robot's intent. As the robot moves, the user can switch between autonomous and manual control when desired. This allows users to collect task demonstrations with both a high success rate and with greater ease than manual teleoperation systems. Our system is powered by transformers, which can provide a window of potential states and actions far into the future -- with almost no added computation time. A key insight is that human intent can be injected at any location within the transformer sequence if the user decides that the model-predicted actions are inappropriate. At every time step, the user can (1) do nothing and allow autonomous operation to continue while observing the robot's future plan sequence, or (2) take over and momentarily prescribe a different set of actions to nudge the model back on track. We host the videos and other supplementary material at https://sites.google.com/view/assistive-teleop.
Learning Perceptual Concepts by Bootstrapping from Human Queries
Nov 09, 2021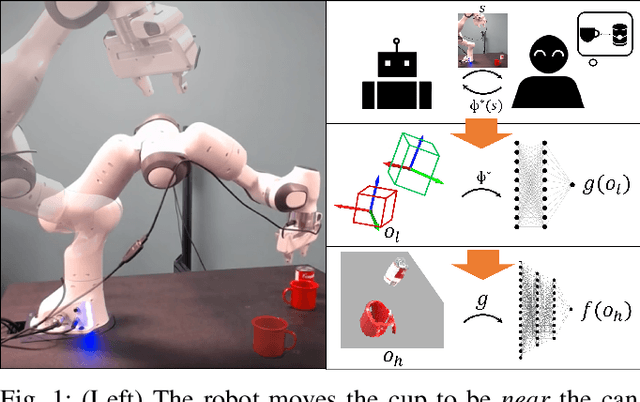
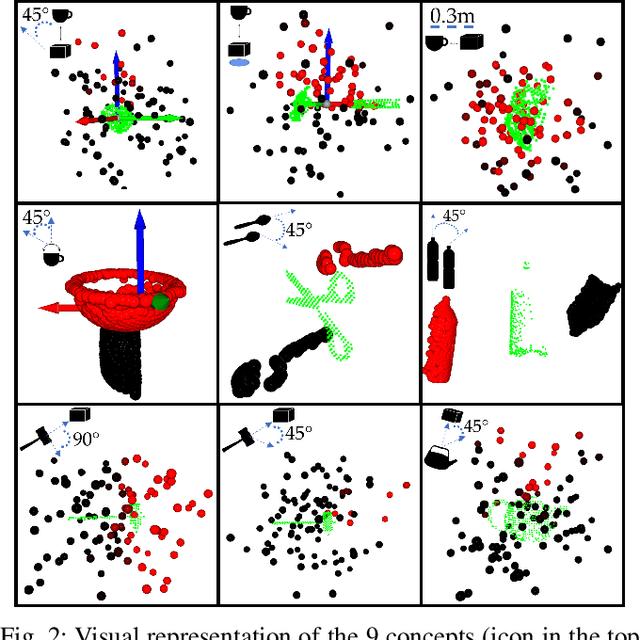
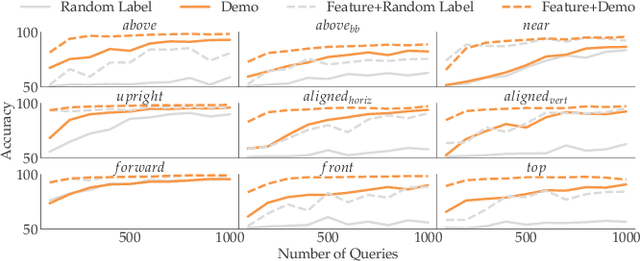
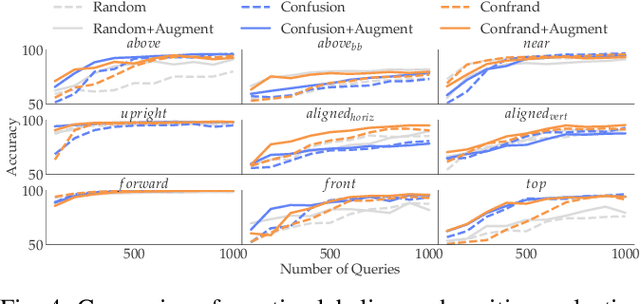
Robots need to be able to learn concepts from their users in order to adapt their capabilities to each user's unique task. But when the robot operates on high-dimensional inputs, like images or point clouds, this is impractical: the robot needs an unrealistic amount of human effort to learn the new concept. To address this challenge, we propose a new approach whereby the robot learns a low-dimensional variant of the concept and uses it to generate a larger data set for learning the concept in the high-dimensional space. This lets it take advantage of semantically meaningful privileged information only accessible at training time, like object poses and bounding boxes, that allows for richer human interaction to speed up learning. We evaluate our approach by learning prepositional concepts that describe object state or multi-object relationships, like above, near, or aligned, which are key to user specification of task goals and execution constraints for robots. Using a simulated human, we show that our approach improves sample complexity when compared to learning concepts directly in the high-dimensional space. We also demonstrate the utility of the learned concepts in motion planning tasks on a 7-DoF Franka Panda robot.
Reactive Human-to-Robot Handovers of Arbitrary Objects
Nov 17, 2020
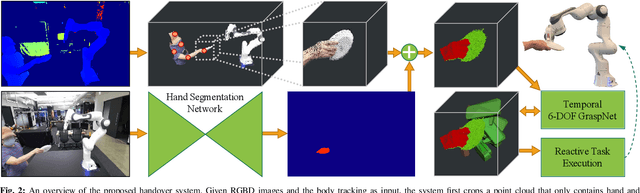

Human-robot object handovers have been an actively studied area of robotics over the past decade; however, very few techniques and systems have addressed the challenge of handing over diverse objects with arbitrary appearance, size, shape, and rigidity. In this paper, we present a vision-based system that enables reactive human-to-robot handovers of unknown objects. Our approach combines closed-loop motion planning with real-time, temporally-consistent grasp generation to ensure reactivity and motion smoothness. Our system is robust to different object positions and orientations, and can grasp both rigid and non-rigid objects. We demonstrate the generalizability, usability, and robustness of our approach on a novel benchmark set of 26 diverse household objects, a user study with naive users (N=6) handing over a subset of 15 objects, and a systematic evaluation examining different ways of handing objects. More results and videos can be found at https://sites.google.com/nvidia.com/handovers-of-arbitrary-objects.
Affordance-Aware Handovers with Human Arm Mobility Constraints
Oct 29, 2020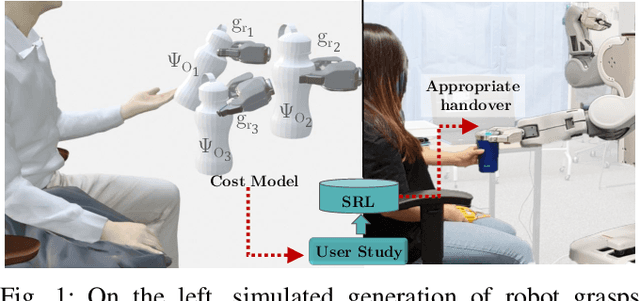
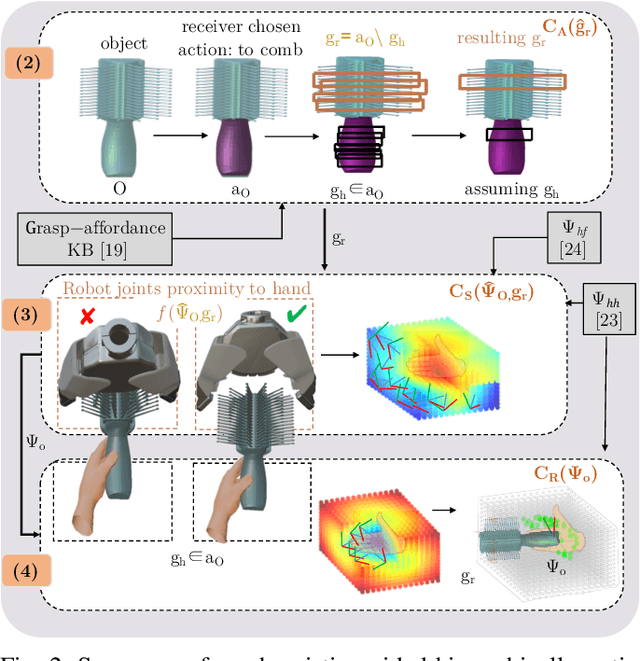
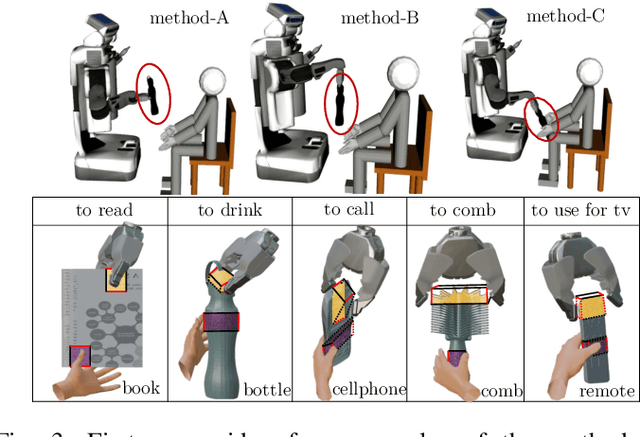
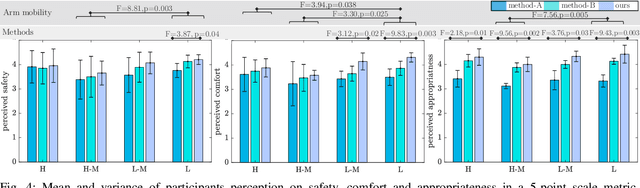
Reasoning about object handover configurations allows an assistive agent to estimate the appropriateness of handover for a receiver with different arm mobility capacities. While there are existing approaches to estimating the effectiveness of handovers, their findings are limited to users without arm mobility impairments and to specific objects. Therefore, current state-of-the-art approaches are unable to hand over novel objects to receivers with different arm mobility capacities. We propose a method that generalises handover behaviours to previously unseen objects, subject to the constraint of a user's arm mobility levels and the task context. We propose a heuristic-guided hierarchically optimised cost whose optimisation adapts object configurations for receivers with low arm mobility. This also ensures that the robot grasps consider the context of the user's upcoming task, i.e., the usage of the object. To understand preferences over handover configurations, we report on the findings of an online study, wherein we presented different handover methods, including ours, to $259$ users with different levels of arm mobility. We encapsulate these preferences in a SRL that is able to reason about the most suitable handover configuration given a receiver's arm mobility and upcoming task. We find that people's preferences over handover methods are correlated to their arm mobility capacities. In experiments with a PR2 robotic platform, we obtained an average handover accuracy of $90.8\%$ when generalising handovers to novel objects.
Human Grasp Classification for Reactive Human-to-Robot Handovers
Mar 12, 2020
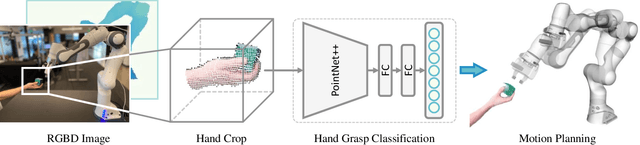

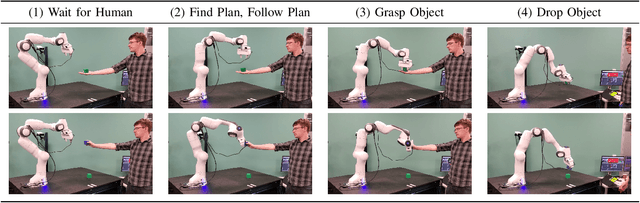
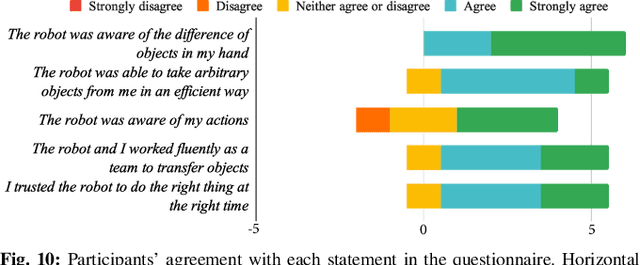
Transfer of objects between humans and robots is a critical capability for collaborative robots. Although there has been a recent surge of interest in human-robot handovers, most prior research focus on robot-to-human handovers. Further, work on the equally critical human-to-robot handovers often assumes humans can place the object in the robot's gripper. In this paper, we propose an approach for human-to-robot handovers in which the robot meets the human halfway, by classifying the human's grasp of the object and quickly planning a trajectory accordingly to take the object from the human's hand according to their intent. To do this, we collect a human grasp dataset which covers typical ways of holding objects with various hand shapes and poses, and learn a deep model on this dataset to classify the hand grasps into one of these categories. We present a planning and execution approach that takes the object from the human hand according to the detected grasp and hand position, and replans as necessary when the handover is interrupted. Through a systematic evaluation, we demonstrate that our system results in more fluent handovers versus two baselines. We also present findings from a user study (N = 9) demonstrating the effectiveness and usability of our approach with naive users in different scenarios. More results and videos can be found at http://wyang.me/handovers.
Vision-and-Dialog Navigation
Jul 19, 2019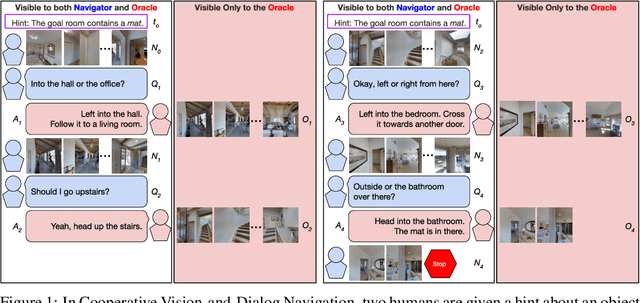
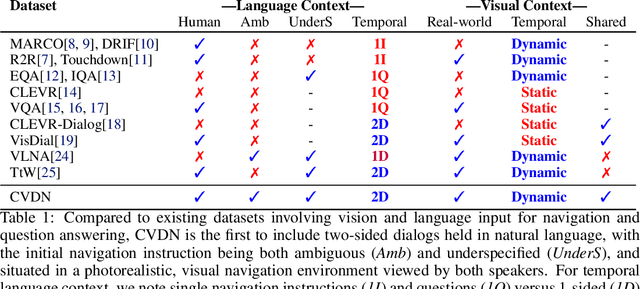
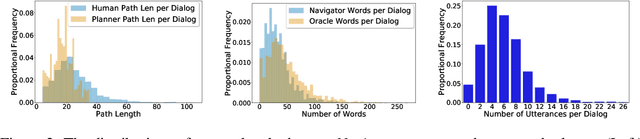

Robots navigating in human environments should use language to ask for assistance and be able to understand human responses. To study this challenge, we introduce Cooperative Vision-and-Dialog Navigation, a dataset of over 2k embodied, human-human dialogs situated in simulated, photorealistic home environments. The Navigator asks questions to their partner, the Oracle, who has privileged access to the best next steps the Navigator should take according to a shortest path planner. To train agents that search an environment for a goal location, we define the Navigation from Dialog History task. An agent, given a target object and a dialog history between humans cooperating to find that object, must infer navigation actions towards the goal in unexplored environments. We establish an initial, multi-modal sequence-to-sequence model and demonstrate that looking farther back in the dialog history improves performance. Sourcecode and a live interface demo can be found at https://github.com/mmurray/cvdn
Desiderata for Planning Systems in General-Purpose Service Robots
Jul 04, 2019
General-purpose service robots are expected to undertake a broad range of tasks at the request of users. Knowledge representation and planning systems are essential to flexible autonomous robots, but the field lacks a unified perspective on which features are essential for general-purpose service robots. Progress towards planning and reasoning for general-purpose service robots is hindered by differing assumptions about users, the environment, and the overall robot system. In this position paper, we propose desiderata for planning and reasoning systems to promote general-purpose service robots. Each proposed item draws on our experience with research on service robots in the office and home and on the demands of these environments. Our desiderata emphasize support for natural human-interfaces as well as for robust fallback methods when interactions with humans and the environment fail. We highlight relevant work towards these goals.
Neural Semantic Parsing with Anonymization for Command Understanding in General-Purpose Service Robots
Jul 02, 2019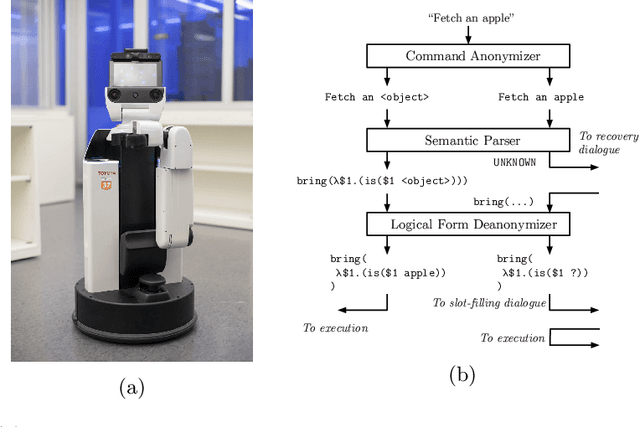
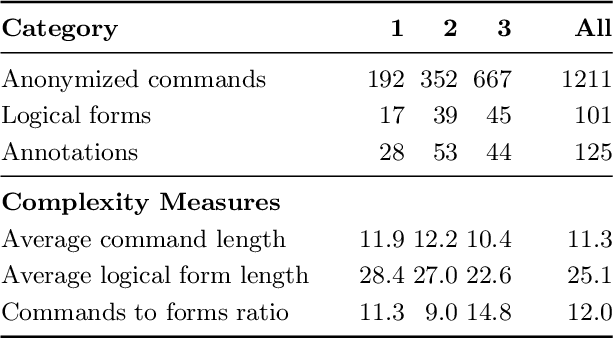
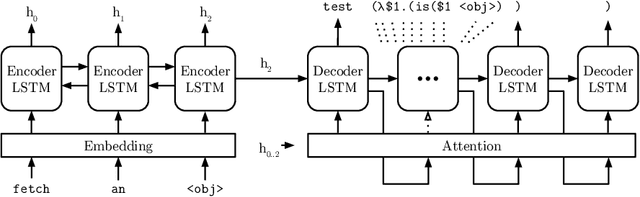

Service robots are envisioned to undertake a wide range of tasks at the request of users. Semantic parsing is one way to convert natural language commands given to these robots into executable representations. Methods for creating semantic parsers, however, rely either on large amounts of data or on engineered lexical features and parsing rules, which has limited their application in robotics. To address this challenge, we propose an approach that leverages neural semantic parsing methods in combination with contextual word embeddings to enable the training of a semantic parser with little data and without domain specific parser engineering. Key to our approach is the use of an anonymized target representation which is more easily learned by the parser. In most cases, this simplified representation can trivially be transformed into an executable format, and in others the parse can be completed through further interaction with the user. We evaluate this approach in the context of the RoboCup@Home General Purpose Service Robot task, where we have collected a corpus of paraphrased versions of commands from the standardized command generator. Our results show that neural semantic parsers can predict the logical form of unseen commands with 89% accuracy. We release our data and the details of our models to encourage further development from the RoboCup and service robotics communities.