 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClarifying the Half Full or Half Empty Question: Multimodal Container Classification
Jul 17, 2023



Multimodal integration is a key component of allowing robots to perceive the world. Multimodality comes with multiple challenges that have to be considered, such as how to integrate and fuse the data. In this paper, we compare different possibilities of fusing visual, tactile and proprioceptive data. The data is directly recorded on the NICOL robot in an experimental setup in which the robot has to classify containers and their content. Due to the different nature of the containers, the use of the modalities can wildly differ between the classes. We demonstrate the superiority of multimodal solutions in this use case and evaluate three fusion strategies that integrate the data at different time steps. We find that the accuracy of the best fusion strategy is 15% higher than the best strategy using only one singular sense.
NICOL: A Neuro-inspired Collaborative Semi-humanoid Robot that Bridges Social Interaction and Reliable Manipulation
May 15, 2023



Robotic platforms that can efficiently collaborate with humans in physical tasks constitute a major goal in robotics. However, many existing robotic platforms are either designed for social interaction or industrial object manipulation tasks. The design of collaborative robots seldom emphasizes both their social interaction and physical collaboration abilities. To bridge this gap, we present the novel semi-humanoid NICOL, the Neuro-Inspired COLlaborator. NICOL is a large, newly designed, scaled-up version of its well-evaluated predecessor, the Neuro-Inspired COmpanion (NICO). While we adopt NICO's head and facial expression display, we extend its manipulation abilities in terms of precision, object size and workspace size. To introduce and evaluate NICOL, we first develop and extend different neural and hybrid neuro-genetic visuomotor approaches initially developed for the NICO to the larger NICOL and its more complex kinematics. Furthermore, we present a novel neuro-genetic approach that improves the grasp accuracy of the NICOL to over 99%, outperforming the state-of-the-art IK solvers KDL, TRACK-IK and BIO-IK. Furthermore, we introduce the social interaction capabilities of NICOL, including the auditory and visual capabilities, but also the face and emotion generation capabilities. Overall, this article presents for the first time the humanoid robot NICOL and, thereby, with the neuro-genetic approaches, contributes to the integration of social robotics and neural visuomotor learning for humanoid robots.
Learning Bidirectional Action-Language Translation with Limited Supervision and Incongruent Extra Input
Jan 09, 2023Human infant learning happens during exploration of the environment, by interaction with objects, and by listening to and repeating utterances casually, which is analogous to unsupervised learning. Only occasionally, a learning infant would receive a matching verbal description of an action it is committing, which is similar to supervised learning. Such a learning mechanism can be mimicked with deep learning. We model this weakly supervised learning paradigm using our Paired Gated Autoencoders (PGAE) model, which combines an action and a language autoencoder. After observing a performance drop when reducing the proportion of supervised training, we introduce the Paired Transformed Autoencoders (PTAE) model, using Transformer-based crossmodal attention. PTAE achieves significantly higher accuracy in language-to-action and action-to-language translations, particularly in realistic but difficult cases when only few supervised training samples are available. We also test whether the trained model behaves realistically with conflicting multimodal input. In accordance with the concept of incongruence in psychology, conflict deteriorates the model output. Conflicting action input has a more severe impact than conflicting language input, and more conflicting features lead to larger interference. PTAE can be trained on mostly unlabelled data where labeled data is scarce, and it behaves plausibly when tested with incongruent input.
Neuro-Symbolic Spatio-Temporal Reasoning
Nov 28, 2022Knowledge about space and time is necessary to solve problems in the physical world: An AI agent situated in the physical world and interacting with objects often needs to reason about positions of and relations between objects; and as soon as the agent plans its actions to solve a task, it needs to consider the temporal aspect (e.g., what actions to perform over time). Spatio-temporal knowledge, however, is required beyond interacting with the physical world, and is also often transferred to the abstract world of concepts through analogies and metaphors (e.g., "a threat that is hanging over our heads"). As spatial and temporal reasoning is ubiquitous, different attempts have been made to integrate this into AI systems. In the area of knowledge representation, spatial and temporal reasoning has been largely limited to modeling objects and relations and developing reasoning methods to verify statements about objects and relations. On the other hand, neural network researchers have tried to teach models to learn spatial relations from data with limited reasoning capabilities. Bridging the gap between these two approaches in a mutually beneficial way could allow us to tackle many complex real-world problems, such as natural language processing, visual question answering, and semantic image segmentation. In this chapter, we view this integration problem from the perspective of Neuro-Symbolic AI. Specifically, we propose a synergy between logical reasoning and machine learning that will be grounded on spatial and temporal knowledge. Describing some successful applications, remaining challenges, and evaluation datasets pertaining to this direction is the main topic of this contribution.
Learning to Autonomously Reach Objects with NICO and Grow-When-Required Networks
Oct 17, 2022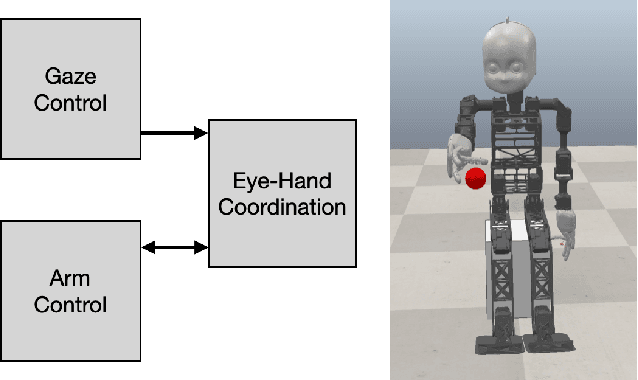
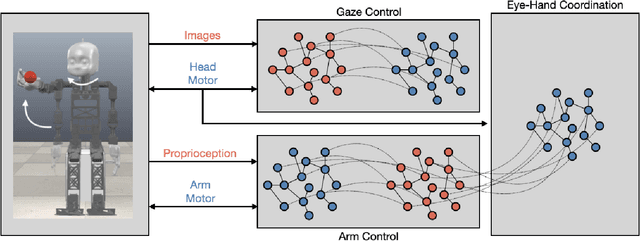
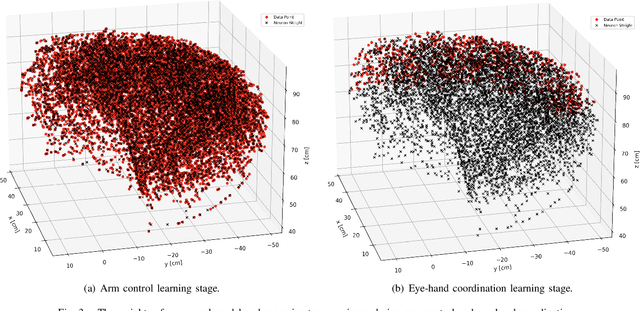
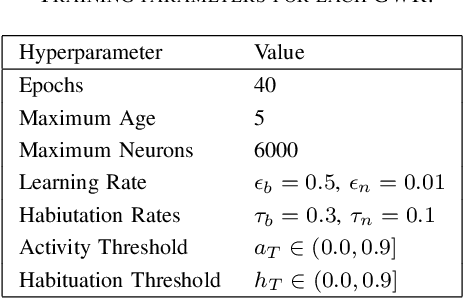
The act of reaching for an object is a fundamental yet complex skill for a robotic agent, requiring a high degree of visuomotor control and coordination. In consideration of dynamic environments, a robot capable of autonomously adapting to novel situations is desired. In this paper, a developmental robotics approach is used to autonomously learn visuomotor coordination on the NICO (Neuro-Inspired COmpanion) platform, for the task of object reaching. The robot interacts with its environment and learns associations between motor commands and temporally correlated sensory perceptions based on Hebbian learning. Multiple Grow-When-Required (GWR) networks are used to learn increasingly more complex motoric behaviors, by first learning how to direct the gaze towards a visual stimulus, followed by learning motor control of the arm, and finally learning how to reach for an object using eye-hand coordination. We demonstrate that the model is able to deal with an unforeseen mechanical change in the NICO's body, showing the adaptability of the proposed approach. In evaluations of our approach, we show that the humanoid robot NICO is able to reach objects with a 76% success rate.
Intelligent problem-solving as integrated hierarchical reinforcement learning
Aug 18, 2022According to cognitive psychology and related disciplines, the development of complex problem-solving behaviour in biological agents depends on hierarchical cognitive mechanisms. Hierarchical reinforcement learning is a promising computational approach that may eventually yield comparable problem-solving behaviour in artificial agents and robots. However, to date the problem-solving abilities of many human and non-human animals are clearly superior to those of artificial systems. Here, we propose steps to integrate biologically inspired hierarchical mechanisms to enable advanced problem-solving skills in artificial agents. Therefore, we first review the literature in cognitive psychology to highlight the importance of compositional abstraction and predictive processing. Then we relate the gained insights with contemporary hierarchical reinforcement learning methods. Interestingly, our results suggest that all identified cognitive mechanisms have been implemented individually in isolated computational architectures, raising the question of why there exists no single unifying architecture that integrates them. As our final contribution, we address this question by providing an integrative perspective on the computational challenges to develop such a unifying architecture. We expect our results to guide the development of more sophisticated cognitively inspired hierarchical machine learning architectures.
* Published as accepted article in Nature Machine Intelligence: https://www.nature.com/articles/s42256-021-00433-9. arXiv admin note: substantial text overlap with arXiv:2012.10147
Learning Flexible Translation between Robot Actions and Language Descriptions
Jul 15, 2022
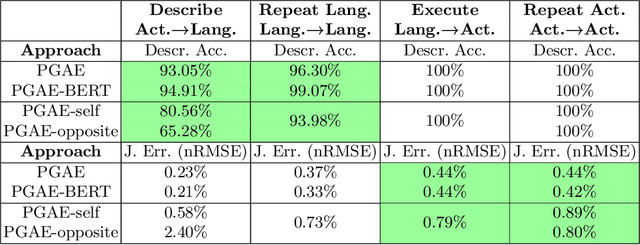

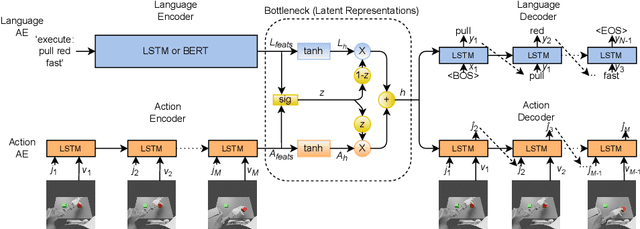
Handling various robot action-language translation tasks flexibly is an essential requirement for natural interaction between a robot and a human. Previous approaches require change in the configuration of the model architecture per task during inference, which undermines the premise of multi-task learning. In this work, we propose the paired gated autoencoders (PGAE) for flexible translation between robot actions and language descriptions in a tabletop object manipulation scenario. We train our model in an end-to-end fashion by pairing each action with appropriate descriptions that contain a signal informing about the translation direction. During inference, our model can flexibly translate from action to language and vice versa according to the given language signal. Moreover, with the option to use a pretrained language model as the language encoder, our model has the potential to recognise unseen natural language input. Another capability of our model is that it can recognise and imitate actions of another agent by utilising robot demonstrations. The experiment results highlight the flexible bidirectional translation capabilities of our approach alongside with the ability to generalise to the actions of the opposite-sitting agent.
Knowing Earlier what Right Means to You: A Comprehensive VQA Dataset for Grounding Relative Directions via Multi-Task Learning
Jul 06, 2022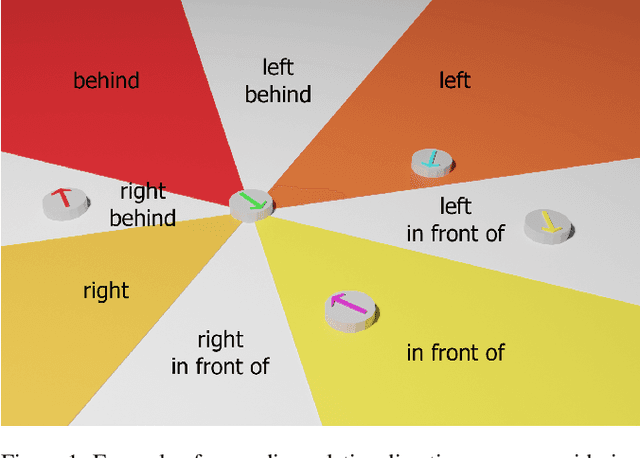
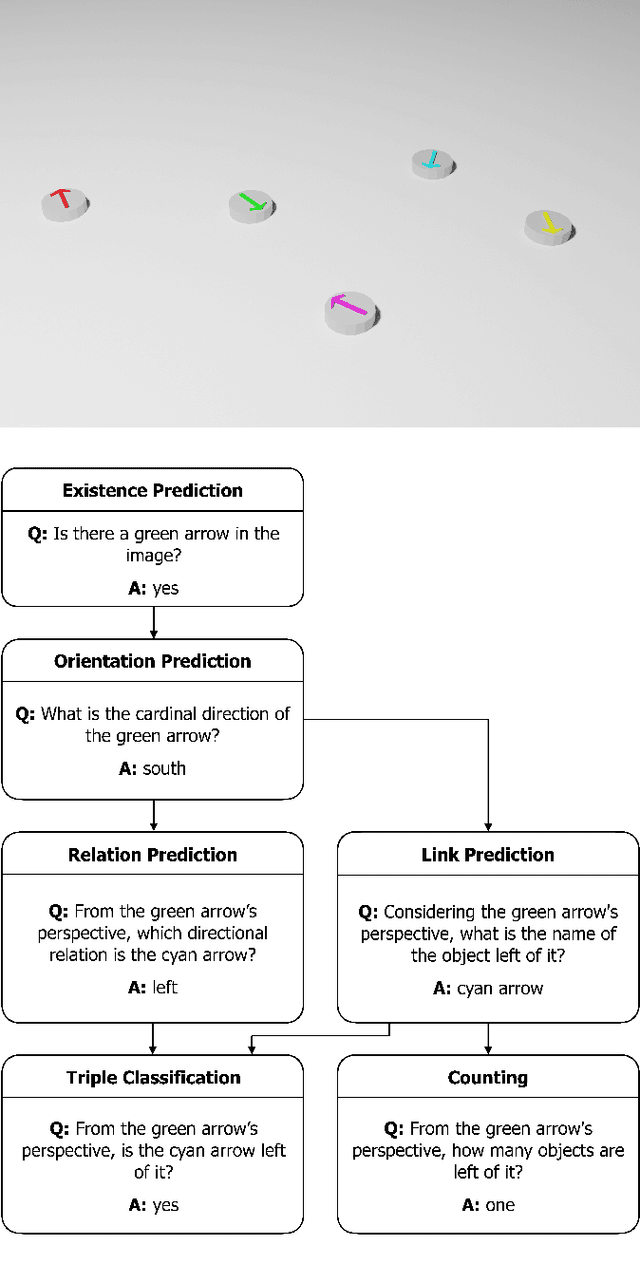

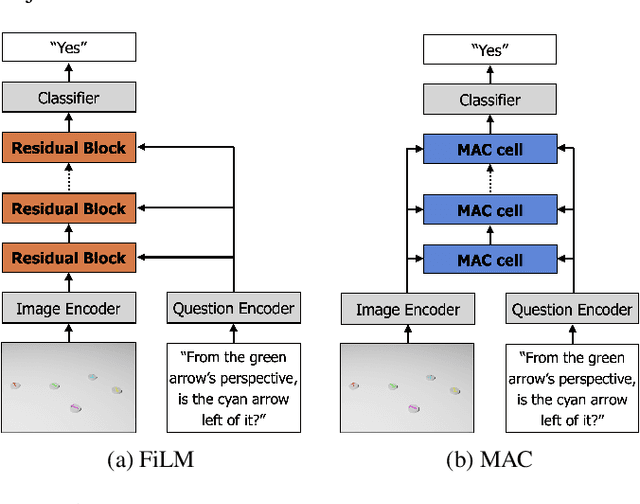
Spatial reasoning poses a particular challenge for intelligent agents and is at the same time a prerequisite for their successful interaction and communication in the physical world. One such reasoning task is to describe the position of a target object with respect to the intrinsic orientation of some reference object via relative directions. In this paper, we introduce GRiD-A-3D, a novel diagnostic visual question-answering (VQA) dataset based on abstract objects. Our dataset allows for a fine-grained analysis of end-to-end VQA models' capabilities to ground relative directions. At the same time, model training requires considerably fewer computational resources compared with existing datasets, yet yields a comparable or even higher performance. Along with the new dataset, we provide a thorough evaluation based on two widely known end-to-end VQA architectures trained on GRiD-A-3D. We demonstrate that within a few epochs, the subtasks required to reason over relative directions, such as recognizing and locating objects in a scene and estimating their intrinsic orientations, are learned in the order in which relative directions are intuitively processed.
What is Right for Me is Not Yet Right for You: A Dataset for Grounding Relative Directions via Multi-Task Learning
May 05, 2022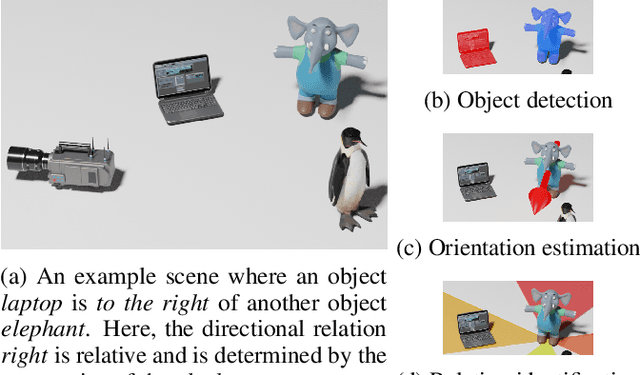


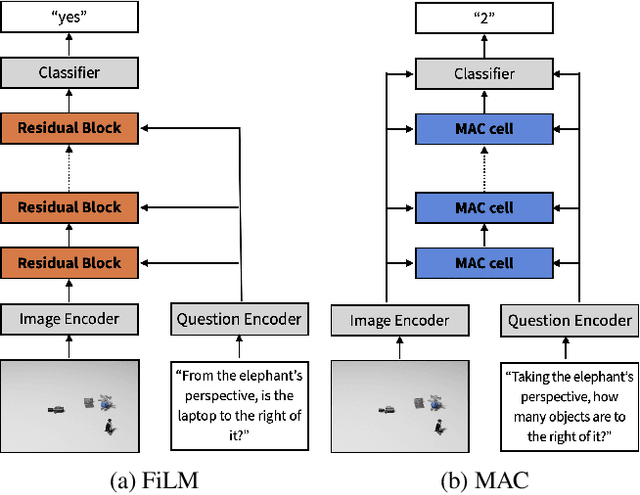
Understanding spatial relations is essential for intelligent agents to act and communicate in the physical world. Relative directions are spatial relations that describe the relative positions of target objects with regard to the intrinsic orientation of reference objects. Grounding relative directions is more difficult than grounding absolute directions because it not only requires a model to detect objects in the image and to identify spatial relation based on this information, but it also needs to recognize the orientation of objects and integrate this information into the reasoning process. We investigate the challenging problem of grounding relative directions with end-to-end neural networks. To this end, we provide GRiD-3D, a novel dataset that features relative directions and complements existing visual question answering (VQA) datasets, such as CLEVR, that involve only absolute directions. We also provide baselines for the dataset with two established end-to-end VQA models. Experimental evaluations show that answering questions on relative directions is feasible when questions in the dataset simulate the necessary subtasks for grounding relative directions. We discover that those subtasks are learned in an order that reflects the steps of an intuitive pipeline for processing relative directions.
Language Model-Based Paired Variational Autoencoders for Robotic Language Learning
Jan 17, 2022
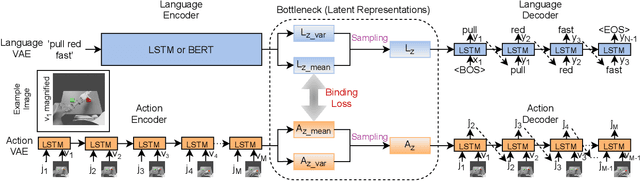
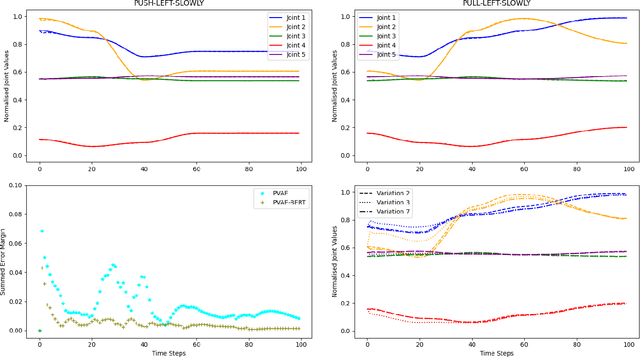
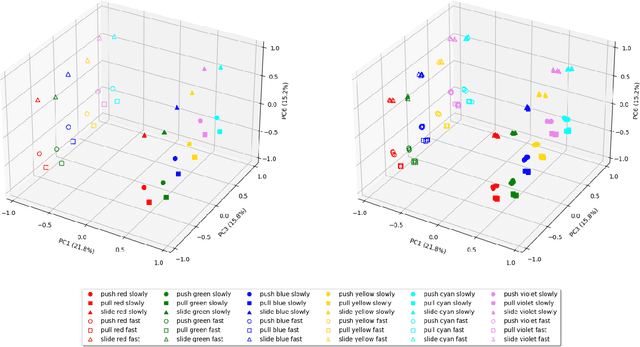
Human infants learn language while interacting with their environment in which their caregivers may describe the objects and actions they perform. Similar to human infants, artificial agents can learn language while interacting with their environment. In this work, first, we present a neural model that bidirectionally binds robot actions and their language descriptions in a simple object manipulation scenario. Building on our previous Paired Variational Autoencoders (PVAE) model, we demonstrate the superiority of the variational autoencoder over standard autoencoders by experimenting with cubes of different colours, and by enabling the production of alternative vocabularies. Additional experiments show that the model's channel-separated visual feature extraction module can cope with objects of different shapes. Next, we introduce PVAE-BERT, which equips the model with a pretrained large-scale language model, i.e., Bidirectional Encoder Representations from Transformers (BERT), enabling the model to go beyond comprehending only the predefined descriptions that the network has been trained on; the recognition of action descriptions generalises to unconstrained natural language as the model becomes capable of understanding unlimited variations of the same descriptions. Our experiments suggest that using a pretrained language model as the language encoder allows our approach to scale up for real-world scenarios with instructions from human users.