 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Adversarial Training with Adaptive Step Size
Jun 06, 2022
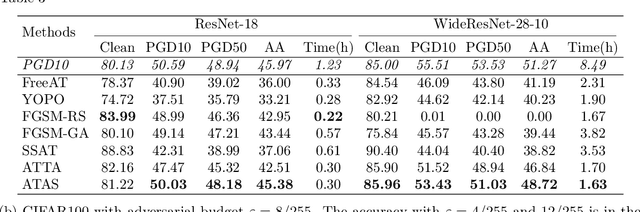
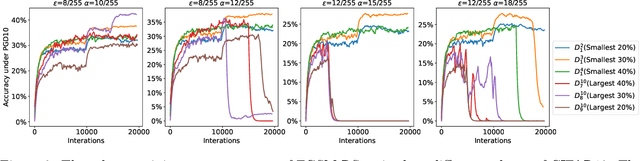
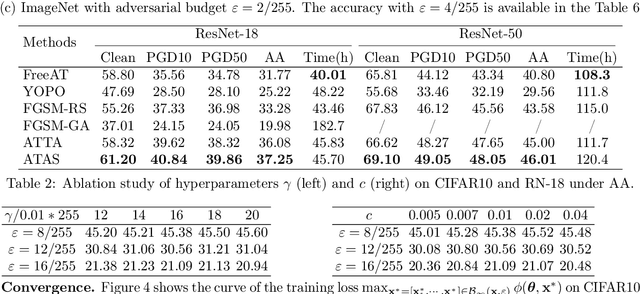
While adversarial training and its variants have shown to be the most effective algorithms to defend against adversarial attacks, their extremely slow training process makes it hard to scale to large datasets like ImageNet. The key idea of recent works to accelerate adversarial training is to substitute multi-step attacks (e.g., PGD) with single-step attacks (e.g., FGSM). However, these single-step methods suffer from catastrophic overfitting, where the accuracy against PGD attack suddenly drops to nearly 0% during training, destroying the robustness of the networks. In this work, we study the phenomenon from the perspective of training instances. We show that catastrophic overfitting is instance-dependent and fitting instances with larger gradient norm is more likely to cause catastrophic overfitting. Based on our findings, we propose a simple but effective method, Adversarial Training with Adaptive Step size (ATAS). ATAS learns an instancewise adaptive step size that is inversely proportional to its gradient norm. The theoretical analysis shows that ATAS converges faster than the commonly adopted non-adaptive counterparts. Empirically, ATAS consistently mitigates catastrophic overfitting and achieves higher robust accuracy on CIFAR10, CIFAR100 and ImageNet when evaluated on various adversarial budgets.
Weakly-supervised Action Transition Learning for Stochastic Human Motion Prediction
May 31, 2022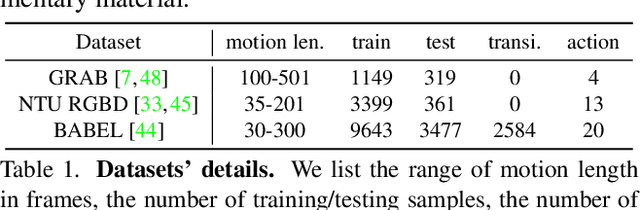
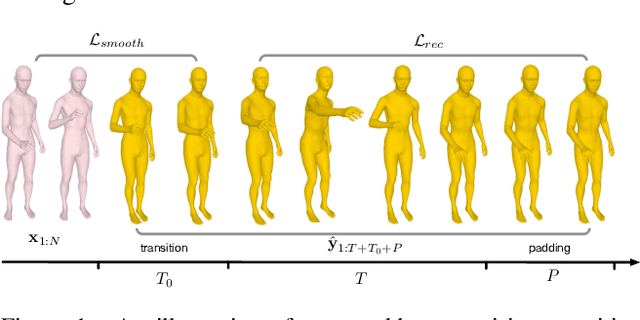
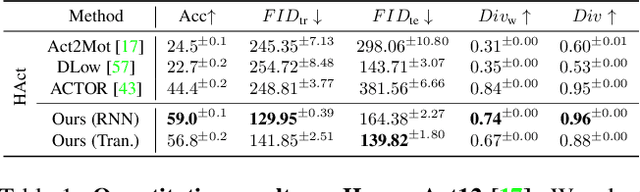
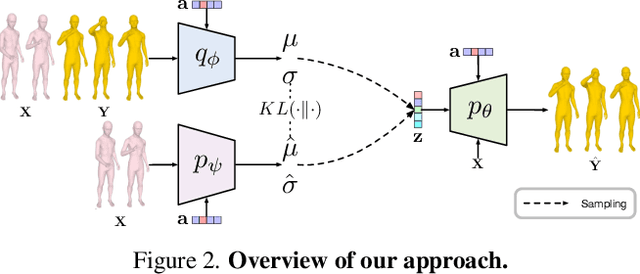
We introduce the task of action-driven stochastic human motion prediction, which aims to predict multiple plausible future motions given a sequence of action labels and a short motion history. This differs from existing works, which predict motions that either do not respect any specific action category, or follow a single action label. In particular, addressing this task requires tackling two challenges: The transitions between the different actions must be smooth; the length of the predicted motion depends on the action sequence and varies significantly across samples. As we cannot realistically expect training data to cover sufficiently diverse action transitions and motion lengths, we propose an effective training strategy consisting of combining multiple motions from different actions and introducing a weak form of supervision to encourage smooth transitions. We then design a VAE-based model conditioned on both the observed motion and the action label sequence, allowing us to generate multiple plausible future motions of varying length. We illustrate the generality of our approach by exploring its use with two different temporal encoding models, namely RNNs and Transformers. Our approach outperforms baseline models constructed by adapting state-of-the-art single action-conditioned motion generation methods and stochastic human motion prediction approaches to our new task of action-driven stochastic motion prediction. Our code is available at https://github.com/wei-mao-2019/WAT.
Knowledge Distillation for 6D Pose Estimation by Keypoint Distribution Alignment
May 30, 2022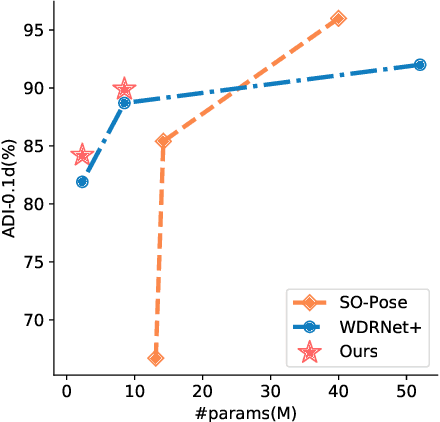
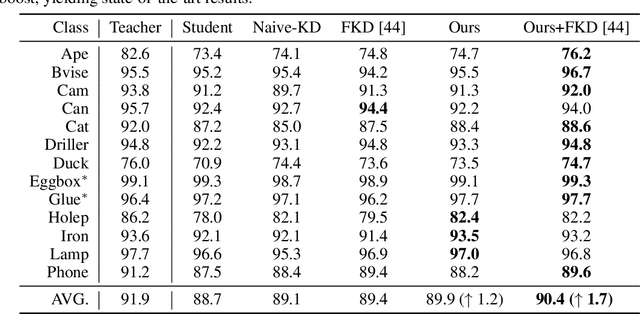

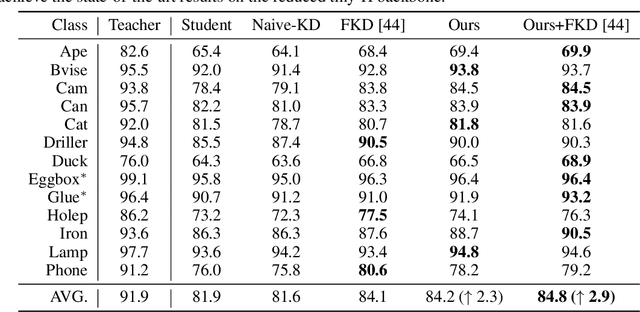
Knowledge distillation facilitates the training of a compact student network by using a deep teacher one. While this has achieved great success in many tasks, it remains completely unstudied for image-based 6D object pose estimation. In this work, we introduce the first knowledge distillation method for 6D pose estimation. Specifically, we follow a standard approach to 6D pose estimation, consisting of predicting the 2D image locations of object keypoints. In this context, we observe the compact student network to struggle predicting precise 2D keypoint locations. Therefore, to address this, instead of training the student with keypoint-to-keypoint supervision, we introduce a strategy based the optimal transport theory that distills the teacher's keypoint \emph{distribution} into the student network, facilitating its training. Our experiments on several benchmarks show that our distillation method yields state-of-the-art results with different compact student models.
MulT: An End-to-End Multitask Learning Transformer
May 17, 2022
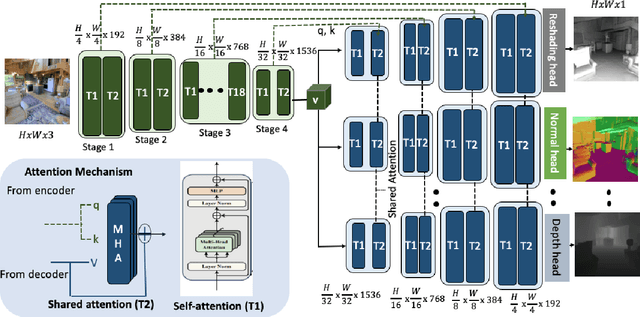
We propose an end-to-end Multitask Learning Transformer framework, named MulT, to simultaneously learn multiple high-level vision tasks, including depth estimation, semantic segmentation, reshading, surface normal estimation, 2D keypoint detection, and edge detection. Based on the Swin transformer model, our framework encodes the input image into a shared representation and makes predictions for each vision task using task-specific transformer-based decoder heads. At the heart of our approach is a shared attention mechanism modeling the dependencies across the tasks. We evaluate our model on several multitask benchmarks, showing that our MulT framework outperforms both the state-of-the art multitask convolutional neural network models and all the respective single task transformer models. Our experiments further highlight the benefits of sharing attention across all the tasks, and demonstrate that our MulT model is robust and generalizes well to new domains. Our project website is at https://ivrl.github.io/MulT/.
Leverage Your Local and Global Representations: A New Self-Supervised Learning Strategy
Apr 13, 2022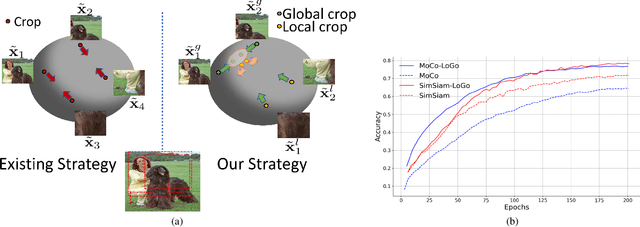
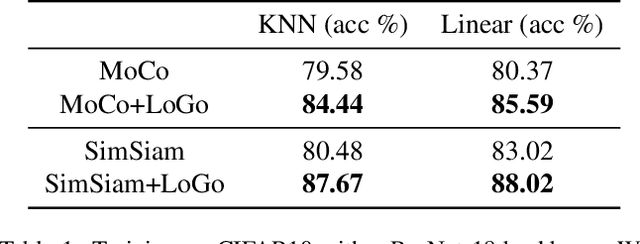
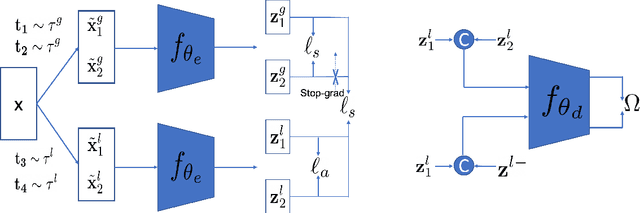
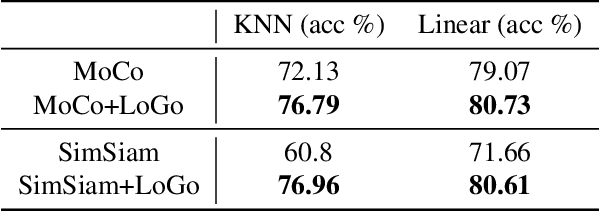
Self-supervised learning (SSL) methods aim to learn view-invariant representations by maximizing the similarity between the features extracted from different crops of the same image regardless of cropping size and content. In essence, this strategy ignores the fact that two crops may truly contain different image information, e.g., background and small objects, and thus tends to restrain the diversity of the learned representations. In this work, we address this issue by introducing a new self-supervised learning strategy, LoGo, that explicitly reasons about Local and Global crops. To achieve view invariance, LoGo encourages similarity between global crops from the same image, as well as between a global and a local crop. However, to correctly encode the fact that the content of smaller crops may differ entirely, LoGo promotes two local crops to have dissimilar representations, while being close to global crops. Our LoGo strategy can easily be applied to existing SSL methods. Our extensive experiments on a variety of datasets and using different self-supervised learning frameworks validate its superiority over existing approaches. Noticeably, we achieve better results than supervised models on transfer learning when using only 1/10 of the data.
Templates for 3D Object Pose Estimation Revisited: Generalization to New Objects and Robustness to Occlusions
Mar 31, 2022


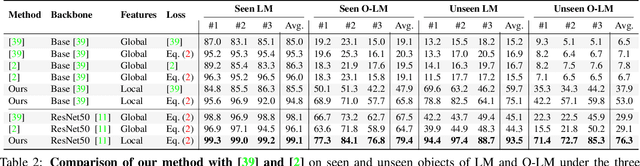
We present a method that can recognize new objects and estimate their 3D pose in RGB images even under partial occlusions. Our method requires neither a training phase on these objects nor real images depicting them, only their CAD models. It relies on a small set of training objects to learn local object representations, which allow us to locally match the input image to a set of "templates", rendered images of the CAD models for the new objects. In contrast with the state-of-the-art methods, the new objects on which our method is applied can be very different from the training objects. As a result, we are the first to show generalization without retraining on the LINEMOD and Occlusion-LINEMOD datasets. Our analysis of the failure modes of previous template-based approaches further confirms the benefits of local features for template matching. We outperform the state-of-the-art template matching methods on the LINEMOD, Occlusion-LINEMOD and T-LESS datasets. Our source code and data are publicly available at https://github.com/nv-nguyen/template-pose
Learning-based Point Cloud Registration for 6D Object Pose Estimation in the Real World
Mar 29, 2022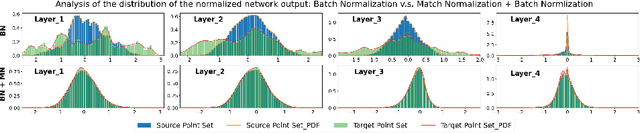
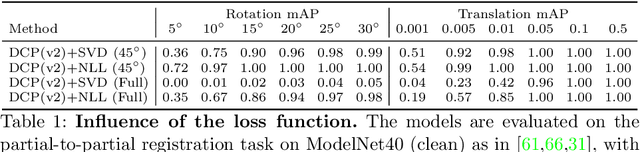
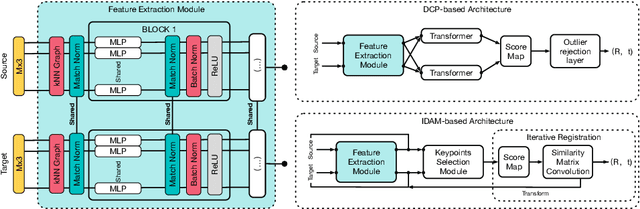
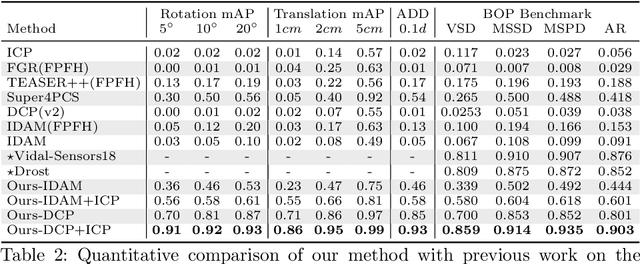
In this work, we tackle the task of estimating the 6D pose of an object from point cloud data. While recent learning-based approaches to addressing this task have shown great success on synthetic datasets, we have observed them to fail in the presence of real-world data. We thus analyze the causes of these failures, which we trace back to the difference between the feature distributions of the source and target point clouds, and the sensitivity of the widely-used SVD-based loss function to the range of rotation between the two point clouds. We address the first challenge by introducing a new normalization strategy, Match Normalization, and the second via the use of a loss function based on the negative log likelihood of point correspondences. Our two contributions are general and can be applied to many existing learning-based 3D object registration frameworks, which we illustrate by implementing them in two of them, DCP and IDAM. Our experiments on the real-scene TUD-L, LINEMOD and Occluded-LINEMOD datasets evidence the benefits of our strategies. They allow for the first time learning-based 3D object registration methods to achieve meaningful results on real-world data. We therefore expect them to be key to the future development of point cloud registration methods.
Perspective Flow Aggregation for Data-Limited 6D Object Pose Estimation
Mar 18, 2022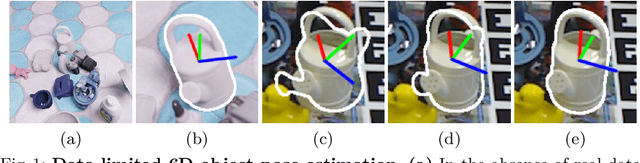

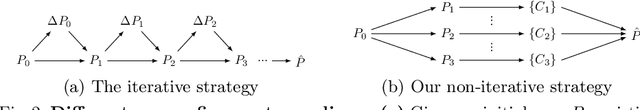
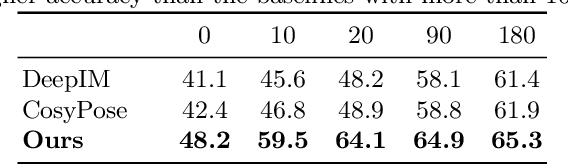
Most recent 6D object pose estimation methods, including unsupervised ones, require many real training images. Unfortunately, for some applications, such as those in space or deep under water, acquiring real images, even unannotated, is virtually impossible. In this paper, we propose a method that can be trained solely on synthetic images, or optionally using a few additional real ones. Given a rough pose estimate obtained from a first network, it uses a second network to predict a dense 2D correspondence field between the image rendered using the rough pose and the real image and infers the required pose correction. This approach is much less sensitive to the domain shift between synthetic and real images than state-of-the-art methods. It performs on par with methods that require annotated real images for training when not using any, and outperforms them considerably when using as few as twenty real images.
Fusing Local Similarities for Retrieval-based 3D Orientation Estimation of Unseen Objects
Mar 16, 2022
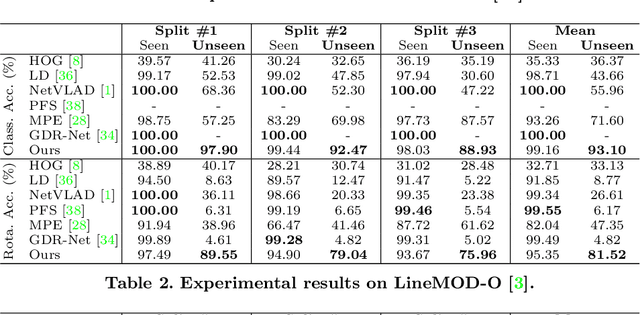
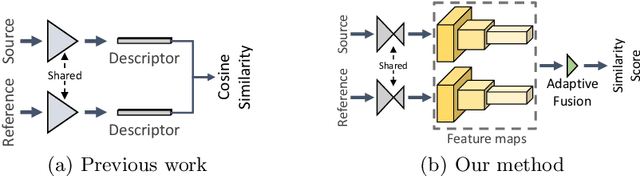
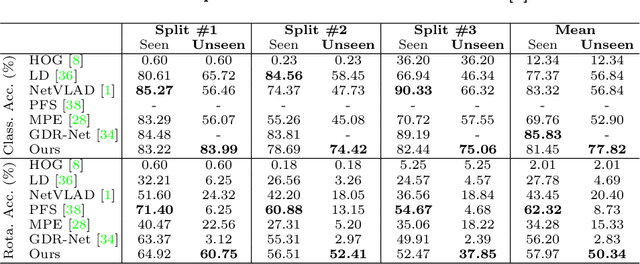
In this paper, we tackle the task of estimating the 3D orientation of previously-unseen objects from monocular images. This task contrasts with the one considered by most existing deep learning methods which typically assume that the testing objects have been observed during training. To handle the unseen objects, we follow a retrieval-based strategy and prevent the network from learning object-specific features by computing multi-scale local similarities between the query image and synthetically-generated reference images. We then introduce an adaptive fusion module that robustly aggregates the local similarities into a global similarity score of pairwise images. Furthermore, we speed up the retrieval process by developing a fast clustering-based retrieval strategy. Our experiments on the LineMOD, LineMOD-Occluded, and T-LESS datasets show that our method yields a significantly better generalization to unseen objects than previous works.
Robust Binary Models by Pruning Randomly-initialized Networks
Feb 03, 2022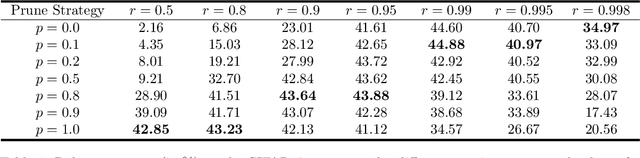
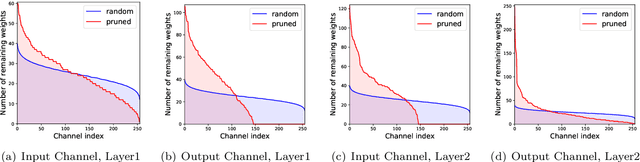

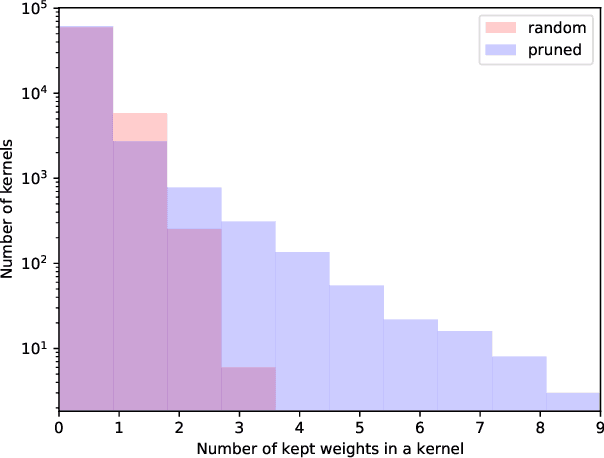
We propose ways to obtain robust models against adversarial attacks from randomly-initialized binary networks. Unlike adversarial training, which learns the model parameters, we in contrast learn the structure of the robust model by pruning a randomly-initialized binary network. Our method confirms the strong lottery ticket hypothesis in the presence of adversarial attacks. Compared to the results obtained in a non-adversarial setting, we in addition improve the performance and compression of the model by 1) using an adaptive pruning strategy for different layers, and 2) using a different initialization scheme such that all model parameters are initialized either to +1 or -1. Our extensive experiments demonstrate that our approach performs not only better than the state-of-the art for robust binary networks; it also achieves comparable or even better performance than full-precision network training methods.