 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Diverse Programs with Instruction Conditioned Reinforced Adversarial Learning
Dec 03, 2018

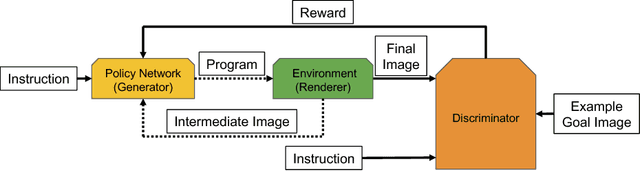
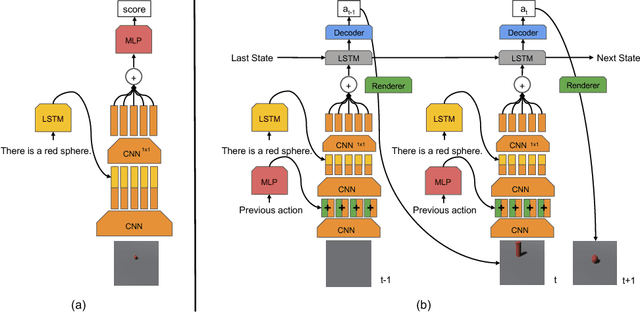
Advances in Deep Reinforcement Learning have led to agents that perform well across a variety of sensory-motor domains. In this work, we study the setting in which an agent must learn to generate programs for diverse scenes conditioned on a given symbolic instruction. Final goals are specified to our agent via images of the scenes. A symbolic instruction consistent with the goal images is used as the conditioning input for our policies. Since a single instruction corresponds to a diverse set of different but still consistent end-goal images, the agent needs to learn to generate a distribution over programs given an instruction. We demonstrate that with simple changes to the reinforced adversarial learning objective, we can learn instruction conditioned policies to achieve the corresponding diverse set of goals. Most importantly, our agent's stochastic policy is shown to more accurately capture the diversity in the goal distribution than a fixed pixel-based reward function baseline. We demonstrate the efficacy of our approach on two domains: (1) drawing MNIST digits with a paint software conditioned on instructions and (2) constructing scenes in a 3D editor that satisfies a certain instruction.
Relational inductive biases, deep learning, and graph networks
Oct 17, 2018
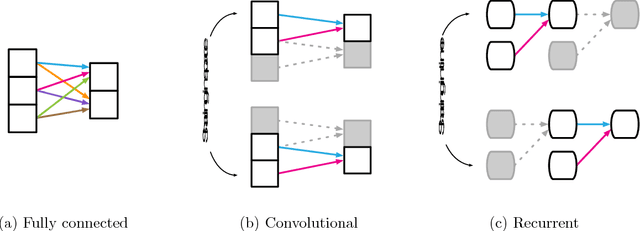
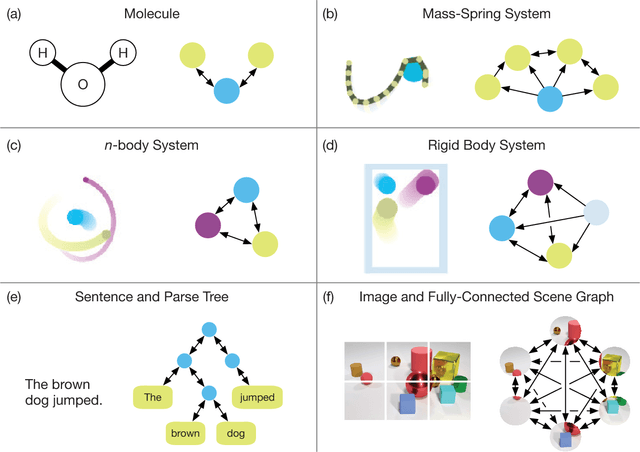
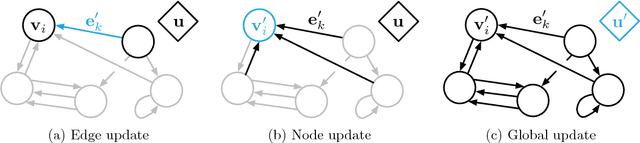
Artificial intelligence (AI) has undergone a renaissance recently, making major progress in key domains such as vision, language, control, and decision-making. This has been due, in part, to cheap data and cheap compute resources, which have fit the natural strengths of deep learning. However, many defining characteristics of human intelligence, which developed under much different pressures, remain out of reach for current approaches. In particular, generalizing beyond one's experiences--a hallmark of human intelligence from infancy--remains a formidable challenge for modern AI. The following is part position paper, part review, and part unification. We argue that combinatorial generalization must be a top priority for AI to achieve human-like abilities, and that structured representations and computations are key to realizing this objective. Just as biology uses nature and nurture cooperatively, we reject the false choice between "hand-engineering" and "end-to-end" learning, and instead advocate for an approach which benefits from their complementary strengths. We explore how using relational inductive biases within deep learning architectures can facilitate learning about entities, relations, and rules for composing them. We present a new building block for the AI toolkit with a strong relational inductive bias--the graph network--which generalizes and extends various approaches for neural networks that operate on graphs, and provides a straightforward interface for manipulating structured knowledge and producing structured behaviors. We discuss how graph networks can support relational reasoning and combinatorial generalization, laying the foundation for more sophisticated, interpretable, and flexible patterns of reasoning. As a companion to this paper, we have released an open-source software library for building graph networks, with demonstrations of how to use them in practice.
Playing the Game of Universal Adversarial Perturbations
Sep 25, 2018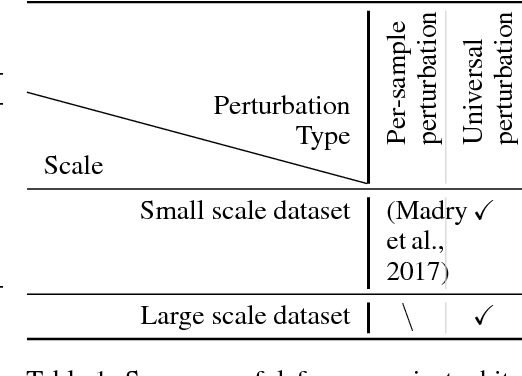

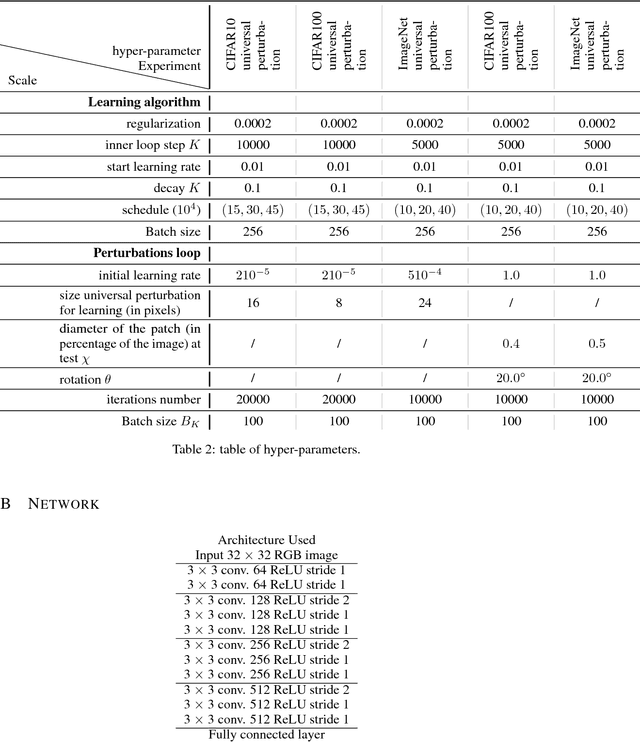
We study the problem of learning classifiers robust to universal adversarial perturbations. While prior work approaches this problem via robust optimization, adversarial training, or input transformation, we instead phrase it as a two-player zero-sum game. In this new formulation, both players simultaneously play the same game, where one player chooses a classifier that minimizes a classification loss whilst the other player creates an adversarial perturbation that increases the same loss when applied to every sample in the training set. By observing that performing a classification (respectively creating adversarial samples) is the best response to the other player, we propose a novel extension of a game-theoretic algorithm, namely fictitious play, to the domain of training robust classifiers. Finally, we empirically show the robustness and versatility of our approach in two defence scenarios where universal attacks are performed on several image classification datasets -- CIFAR10, CIFAR100 and ImageNet.
The Visual QA Devil in the Details: The Impact of Early Fusion and Batch Norm on CLEVR
Sep 11, 2018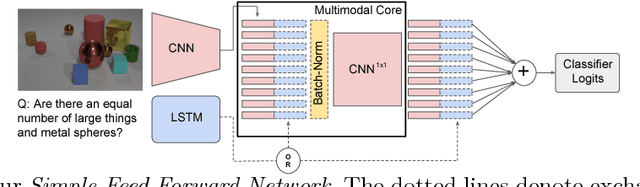
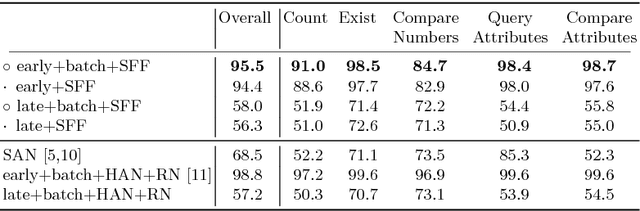
Visual QA is a pivotal challenge for higher-level reasoning, requiring understanding language, vision, and relationships between many objects in a scene. Although datasets like CLEVR are designed to be unsolvable without such complex relational reasoning, some surprisingly simple feed-forward, "holistic" models have recently shown strong performance on this dataset. These models lack any kind of explicit iterative, symbolic reasoning procedure, which are hypothesized to be necessary for counting objects, narrowing down the set of relevant objects based on several attributes, etc. The reason for this strong performance is poorly understood. Hence, our work analyzes such models, and finds that minor architectural elements are crucial to performance. In particular, we find that \textit{early fusion} of language and vision provides large performance improvements. This contrasts with the late fusion approaches popular at the dawn of Visual QA. We propose a simple module we call Multimodal Core, which we hypothesize performs the fundamental operations for multimodal tasks. We believe that understanding why these elements are so important to complex question answering will aid the design of better-performing algorithms for Visual QA while minimizing hand-engineering effort.
Learning Visual Question Answering by Bootstrapping Hard Attention
Aug 01, 2018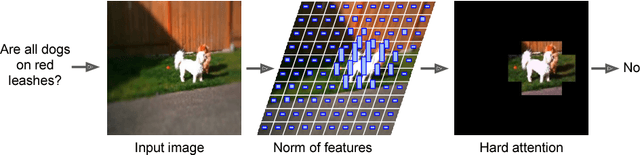
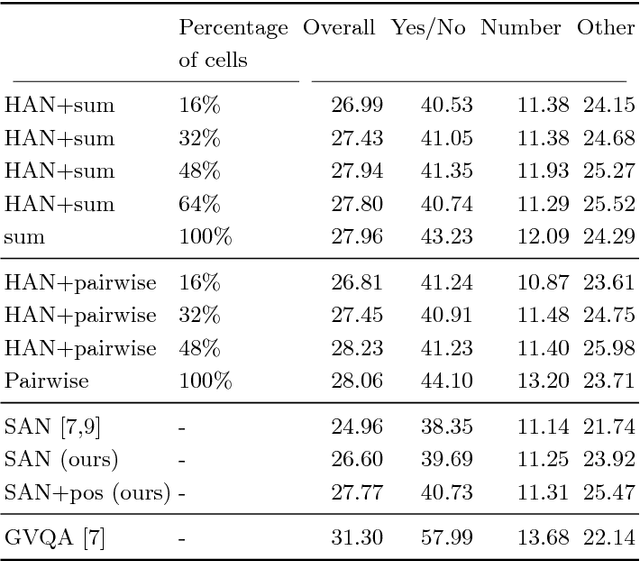
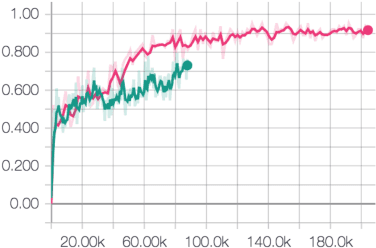
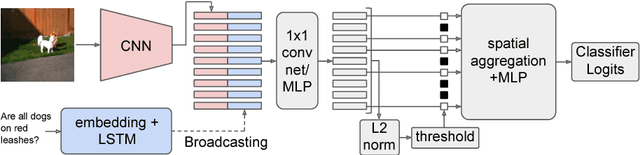
Attention mechanisms in biological perception are thought to select subsets of perceptual information for more sophisticated processing which would be prohibitive to perform on all sensory inputs. In computer vision, however, there has been relatively little exploration of hard attention, where some information is selectively ignored, in spite of the success of soft attention, where information is re-weighted and aggregated, but never filtered out. Here, we introduce a new approach for hard attention and find it achieves very competitive performance on a recently-released visual question answering datasets, equalling and in some cases surpassing similar soft attention architectures while entirely ignoring some features. Even though the hard attention mechanism is thought to be non-differentiable, we found that the feature magnitudes correlate with semantic relevance, and provide a useful signal for our mechanism's attentional selection criterion. Because hard attention selects important features of the input information, it can also be more efficient than analogous soft attention mechanisms. This is especially important for recent approaches that use non-local pairwise operations, whereby computational and memory costs are quadratic in the size of the set of features.
Hyperbolic Attention Networks
May 24, 2018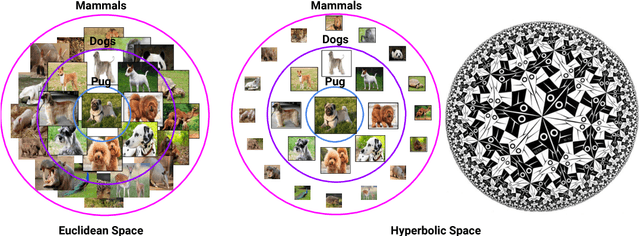
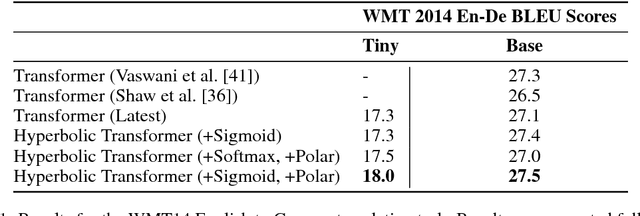
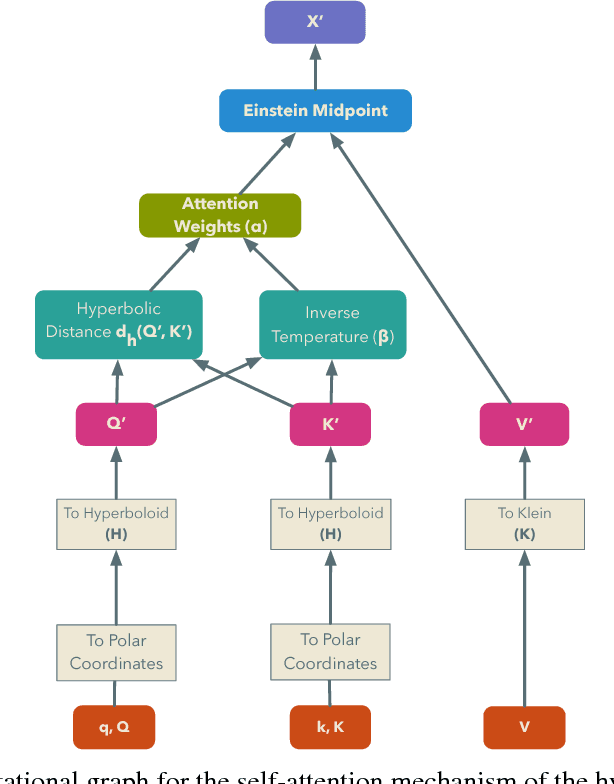
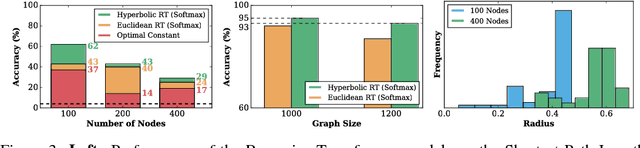
We introduce hyperbolic attention networks to endow neural networks with enough capacity to match the complexity of data with hierarchical and power-law structure. A few recent approaches have successfully demonstrated the benefits of imposing hyperbolic geometry on the parameters of shallow networks. We extend this line of work by imposing hyperbolic geometry on the activations of neural networks. This allows us to exploit hyperbolic geometry to reason about embeddings produced by deep networks. We achieve this by re-expressing the ubiquitous mechanism of soft attention in terms of operations defined for hyperboloid and Klein models. Our method shows improvements in terms of generalization on neural machine translation, learning on graphs and visual question answering tasks while keeping the neural representations compact.
Learning to Navigate in Cities Without a Map
Apr 17, 2018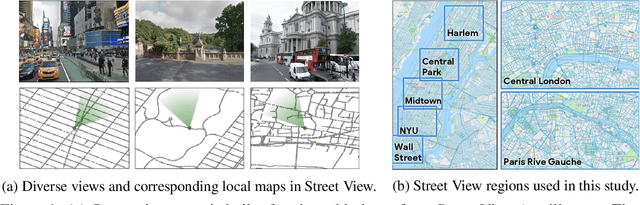
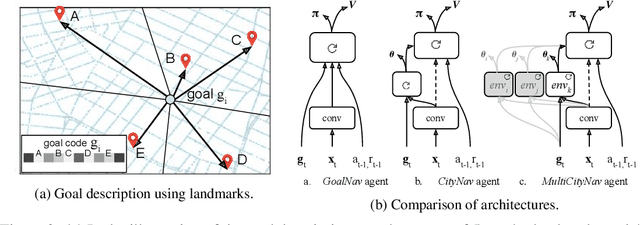
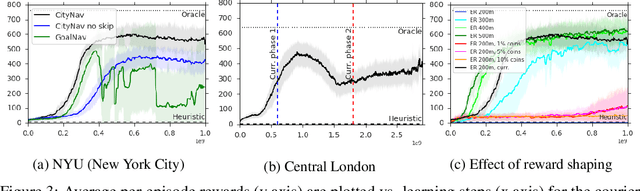
Navigating through unstructured environments is a basic capability of intelligent creatures, and thus is of fundamental interest in the study and development of artificial intelligence. Long-range navigation is a complex cognitive task that relies on developing an internal representation of space, grounded by recognisable landmarks and robust visual processing, that can simultaneously support continuous self-localisation ("I am here") and a representation of the goal ("I am going there"). Building upon recent research that applies deep reinforcement learning to maze navigation problems, we present an end-to-end deep reinforcement learning approach that can be applied on a city scale. Recognising that successful navigation relies on integration of general policies with locale-specific knowledge, we propose a dual pathway architecture that allows locale-specific features to be encapsulated, while still enabling transfer to multiple cities. We present an interactive navigation environment that uses Google StreetView for its photographic content and worldwide coverage, and demonstrate that our learning method allows agents to learn to navigate multiple cities and to traverse to target destinations that may be kilometres away. A video summarizing our research and showing the trained agent in diverse city environments as well as on the transfer task is available at: https://sites.google.com/view/streetlearn.
Long-Term Image Boundary Prediction
Nov 23, 2017
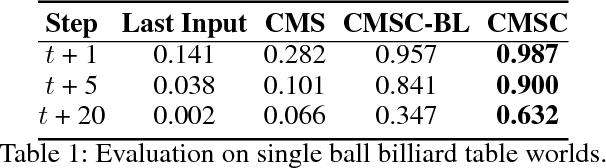
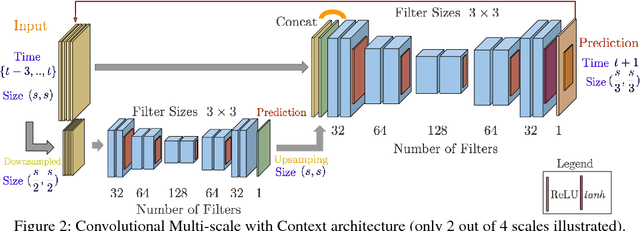

Boundary estimation in images and videos has been a very active topic of research, and organizing visual information into boundaries and segments is believed to be a corner stone of visual perception. While prior work has focused on estimating boundaries for observed frames, our work aims at predicting boundaries of future unobserved frames. This requires our model to learn about the fate of boundaries and corresponding motion patterns -- including a notion of "intuitive physics". We experiment on natural video sequences along with synthetic sequences with deterministic physics-based and agent-based motions. While not being our primary goal, we also show that fusion of RGB and boundary prediction leads to improved RGB predictions.
A simple neural network module for relational reasoning
Jun 05, 2017
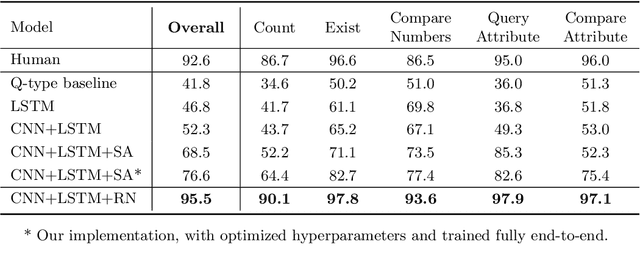
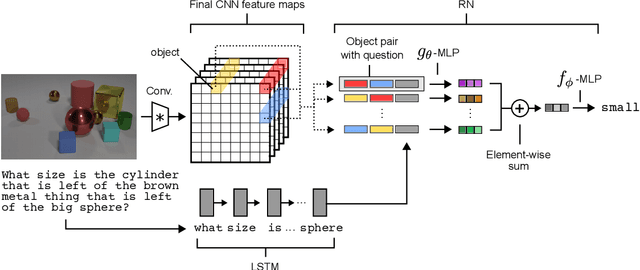

Relational reasoning is a central component of generally intelligent behavior, but has proven difficult for neural networks to learn. In this paper we describe how to use Relation Networks (RNs) as a simple plug-and-play module to solve problems that fundamentally hinge on relational reasoning. We tested RN-augmented networks on three tasks: visual question answering using a challenging dataset called CLEVR, on which we achieve state-of-the-art, super-human performance; text-based question answering using the bAbI suite of tasks; and complex reasoning about dynamic physical systems. Then, using a curated dataset called Sort-of-CLEVR we show that powerful convolutional networks do not have a general capacity to solve relational questions, but can gain this capacity when augmented with RNs. Our work shows how a deep learning architecture equipped with an RN module can implicitly discover and learn to reason about entities and their relations.
Ask Your Neurons: A Deep Learning Approach to Visual Question Answering
Nov 24, 2016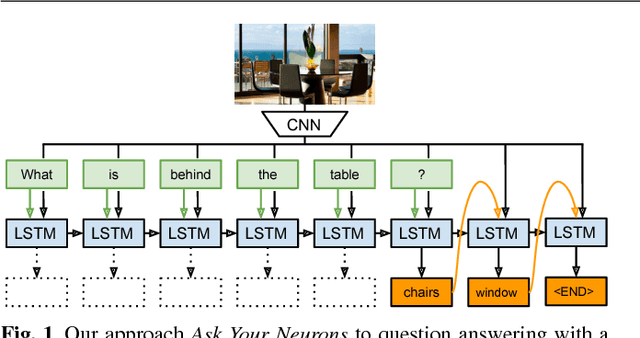
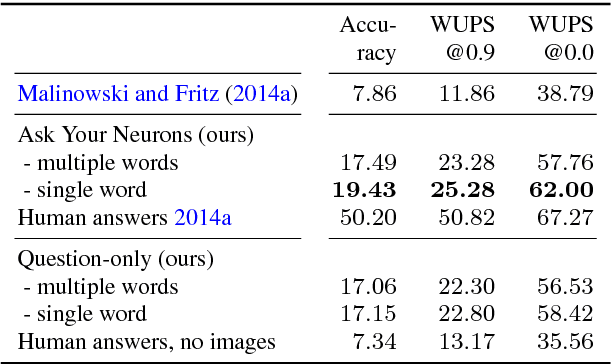
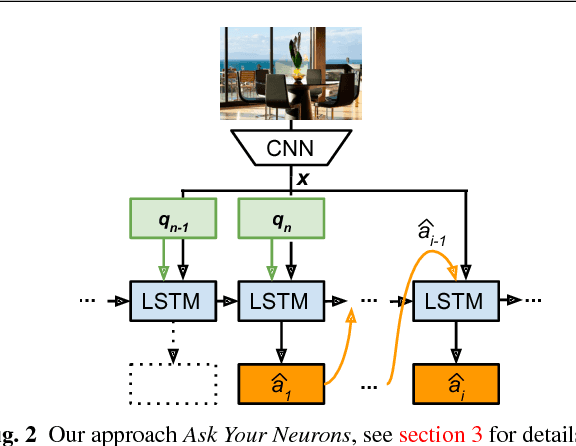
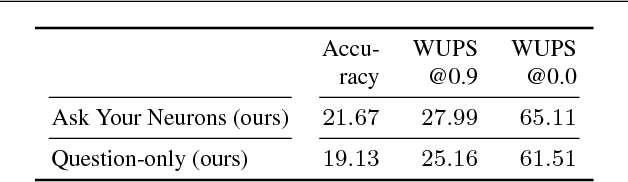
We address a question answering task on real-world images that is set up as a Visual Turing Test. By combining latest advances in image representation and natural language processing, we propose Ask Your Neurons, a scalable, jointly trained, end-to-end formulation to this problem. In contrast to previous efforts, we are facing a multi-modal problem where the language output (answer) is conditioned on visual and natural language inputs (image and question). We provide additional insights into the problem by analyzing how much information is contained only in the language part for which we provide a new human baseline. To study human consensus, which is related to the ambiguities inherent in this challenging task, we propose two novel metrics and collect additional answers which extend the original DAQUAR dataset to DAQUAR-Consensus. Moreover, we also extend our analysis to VQA, a large-scale question answering about images dataset, where we investigate some particular design choices and show the importance of stronger visual models. At the same time, we achieve strong performance of our model that still uses a global image representation. Finally, based on such analysis, we refine our Ask Your Neurons on DAQUAR, which also leads to a better performance on this challenging task.