 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Training with Complementary Labels: On the Benefit of Gradually Informative Attacks
Nov 01, 2022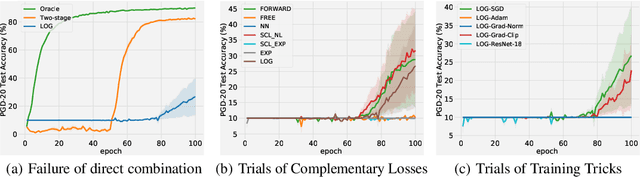
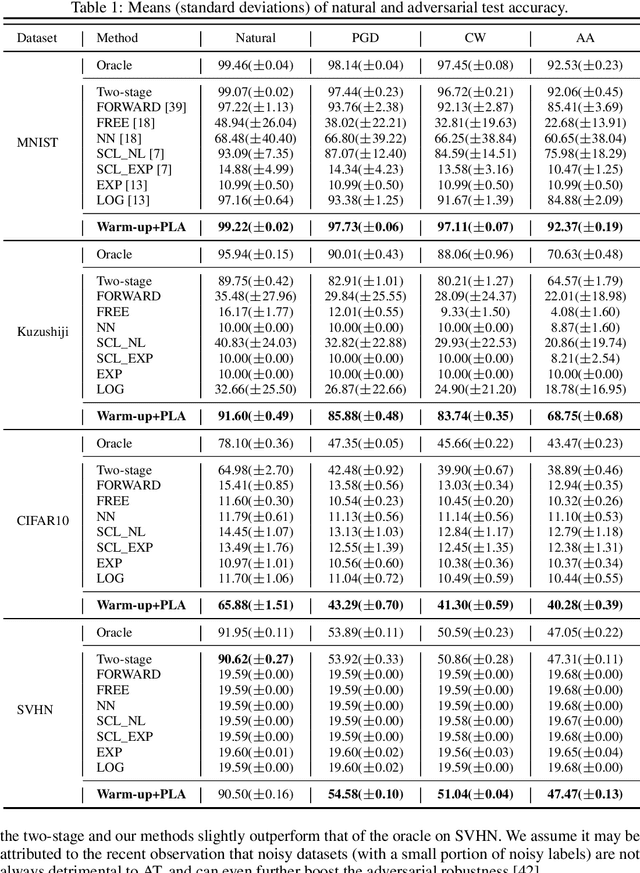
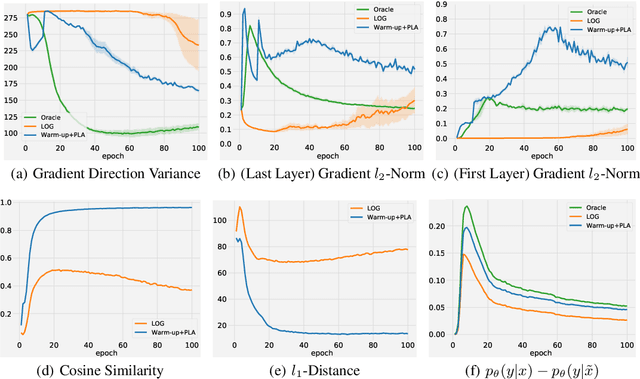

Adversarial training (AT) with imperfect supervision is significant but receives limited attention. To push AT towards more practical scenarios, we explore a brand new yet challenging setting, i.e., AT with complementary labels (CLs), which specify a class that a data sample does not belong to. However, the direct combination of AT with existing methods for CLs results in consistent failure, but not on a simple baseline of two-stage training. In this paper, we further explore the phenomenon and identify the underlying challenges of AT with CLs as intractable adversarial optimization and low-quality adversarial examples. To address the above problems, we propose a new learning strategy using gradually informative attacks, which consists of two critical components: 1) Warm-up Attack (Warm-up) gently raises the adversarial perturbation budgets to ease the adversarial optimization with CLs; 2) Pseudo-Label Attack (PLA) incorporates the progressively informative model predictions into a corrected complementary loss. Extensive experiments are conducted to demonstrate the effectiveness of our method on a range of benchmarked datasets. The code is publicly available at: https://github.com/RoyalSkye/ATCL.
Audio Signal Enhancement with Learning from Positive and Unlabelled Data
Oct 30, 2022



Supervised learning is a mainstream approach to audio signal enhancement (SE) and requires parallel training data consisting of both noisy signals and the corresponding clean signals. Such data can only be synthesised and are thus mismatched with real data, which can result in poor performance. Moreover, it is often difficult/impossible to obtain clean signals, making it difficult/impossible to apply the approach in this case. Here we explore SE using non-parallel training data consisting of noisy signals and noise, which can be easily recorded. We define the positive (P) and the negative (N) classes as signal absence and presence, respectively. We observe that the spectrogram patches of noise clips can be used as P data and those of noisy signal clips as unlabelled data. Thus, learning from positive and unlabelled data enables a convolutional neural network to learn to classify each spectrogram patch as P or N for SE.
Equivariant Disentangled Transformation for Domain Generalization under Combination Shift
Aug 03, 2022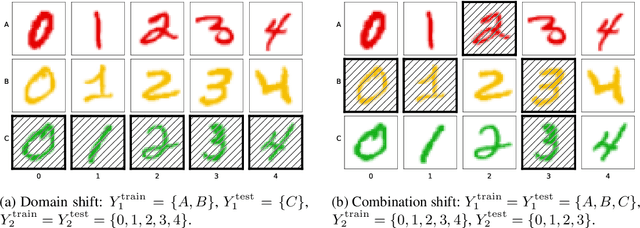
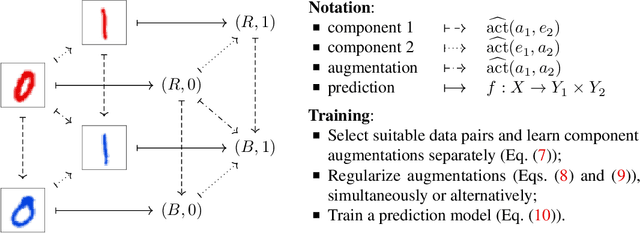
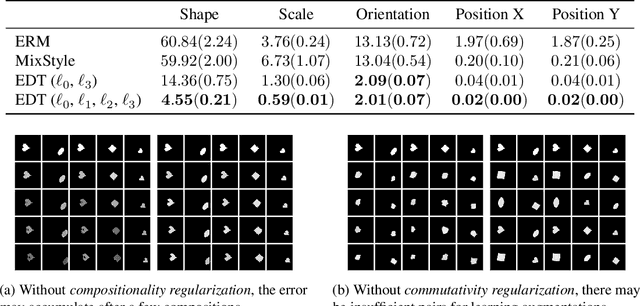
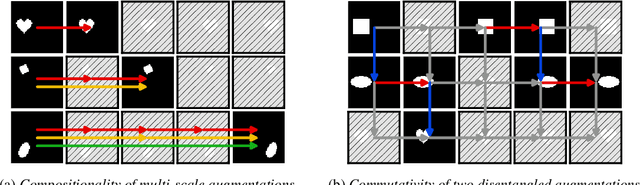
Machine learning systems may encounter unexpected problems when the data distribution changes in the deployment environment. A major reason is that certain combinations of domains and labels are not observed during training but appear in the test environment. Although various invariance-based algorithms can be applied, we find that the performance gain is often marginal. To formally analyze this issue, we provide a unique algebraic formulation of the combination shift problem based on the concepts of homomorphism, equivariance, and a refined definition of disentanglement. The algebraic requirements naturally derive a simple yet effective method, referred to as equivariant disentangled transformation (EDT), which augments the data based on the algebraic structures of labels and makes the transformation satisfy the equivariance and disentanglement requirements. Experimental results demonstrate that invariance may be insufficient, and it is important to exploit the equivariance structure in the combination shift problem.
Adapting to Online Label Shift with Provable Guarantees
Jul 05, 2022
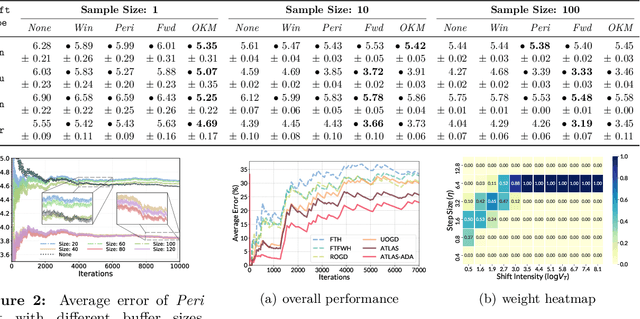
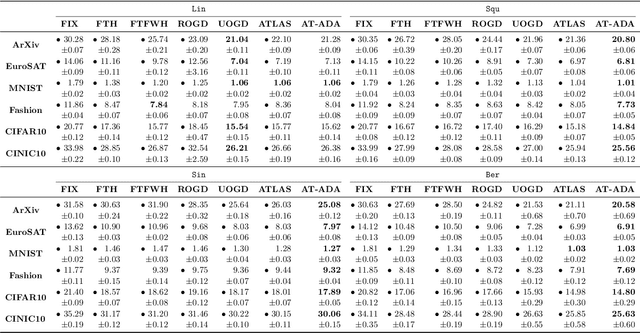
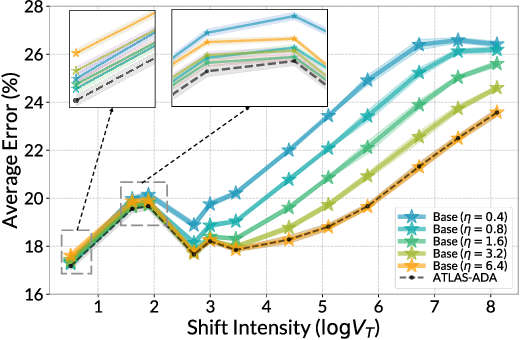
The standard supervised learning paradigm works effectively when training data shares the same distribution as the upcoming testing samples. However, this assumption is often violated in real-world applications, especially when testing data appear in an online fashion. In this paper, we formulate and investigate the problem of online label shift (OLaS): the learner trains an initial model from the labeled offline data and then deploys it to an unlabeled online environment where the underlying label distribution changes over time but the label-conditional density does not. The non-stationarity nature and the lack of supervision make the problem challenging to be tackled. To address the difficulty, we construct a new unbiased risk estimator that utilizes the unlabeled data, which exhibits many benign properties albeit with potential non-convexity. Building upon that, we propose novel online ensemble algorithms to deal with the non-stationarity of the environments. Our approach enjoys optimal dynamic regret, indicating that the performance is competitive with a clairvoyant who knows the online environments in hindsight and then chooses the best decision for each round. The obtained dynamic regret bound scales with the intensity and pattern of label distribution shift, hence exhibiting the adaptivity in the OLaS problem. Extensive experiments are conducted to validate the effectiveness and support our theoretical findings.
Learning from Multiple Unlabeled Datasets with Partial Risk Regularization
Jul 04, 2022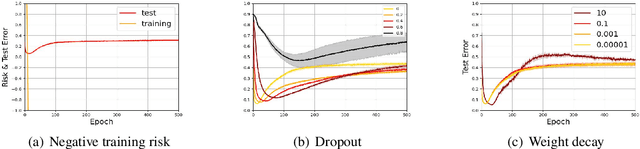
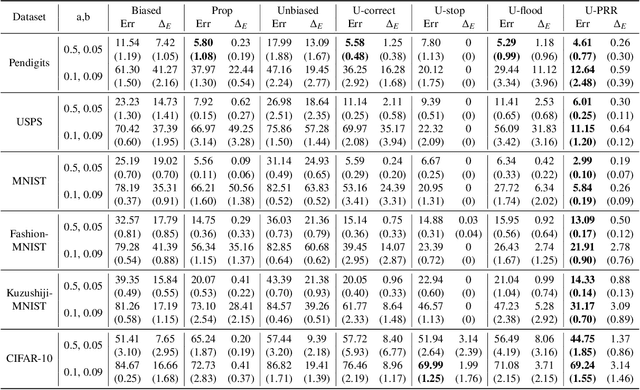
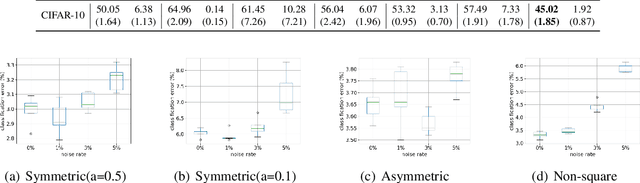
Recent years have witnessed a great success of supervised deep learning, where predictive models were trained from a large amount of fully labeled data. However, in practice, labeling such big data can be very costly and may not even be possible for privacy reasons. Therefore, in this paper, we aim to learn an accurate classifier without any class labels. More specifically, we consider the case where multiple sets of unlabeled data and only their class priors, i.e., the proportions of each class, are available. Under this problem setup, we first derive an unbiased estimator of the classification risk that can be estimated from the given unlabeled sets and theoretically analyze the generalization error of the learned classifier. We then find that the classifier obtained as such tends to cause overfitting as its empirical risks go negative during training. To prevent overfitting, we further propose a partial risk regularization that maintains the partial risks with respect to unlabeled datasets and classes to certain levels. Experiments demonstrate that our method effectively mitigates overfitting and outperforms state-of-the-art methods for learning from multiple unlabeled sets.
The Survival Bandit Problem
Jun 07, 2022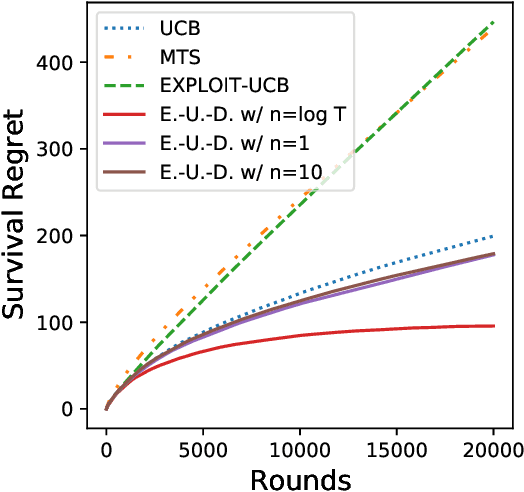
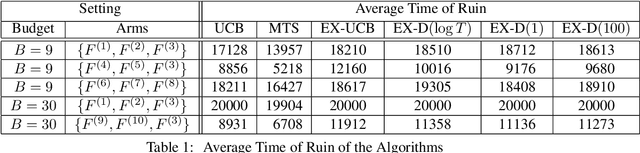
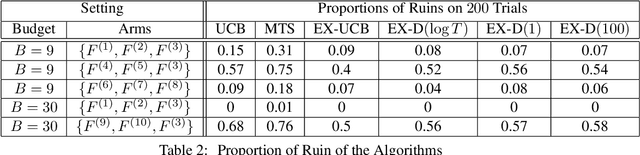
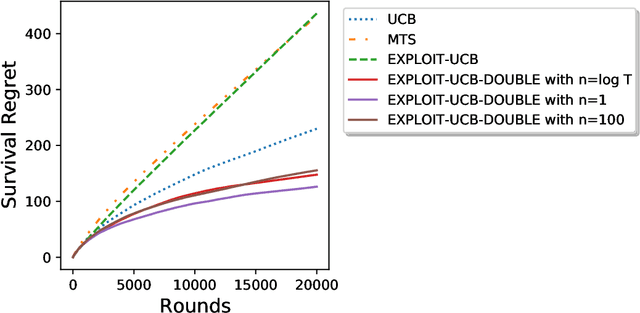
We study the survival bandit problem, a variant of the multi-armed bandit problem introduced in an open problem by Perotto et al. (2019), with a constraint on the cumulative reward; at each time step, the agent receives a (possibly negative) reward and if the cumulative reward becomes lower than a prespecified threshold, the procedure stops, and this phenomenon is called ruin. This is the first paper studying a framework where the ruin might occur but not always. We first discuss that a sublinear regret is unachievable under a naive definition of the regret. Next, we provide tight lower bounds on the probability of ruin (as well as matching policies). Based on this lower bound, we define the survival regret as an objective to minimize and provide a policy achieving a sublinear survival regret (at least in the case of integral rewards) when the time horizon $T$ is known.
Instance-Dependent Label-Noise Learning with Manifold-Regularized Transition Matrix Estimation
Jun 06, 2022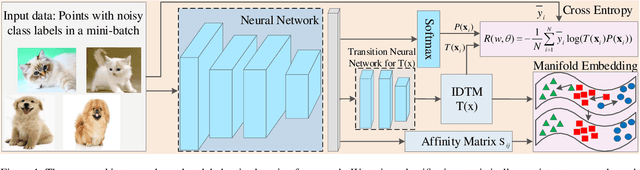
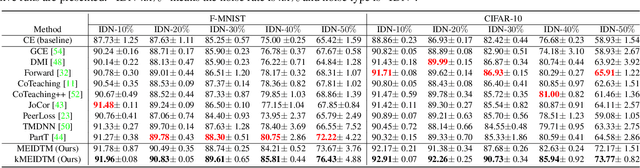
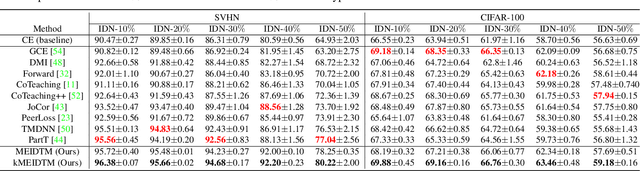
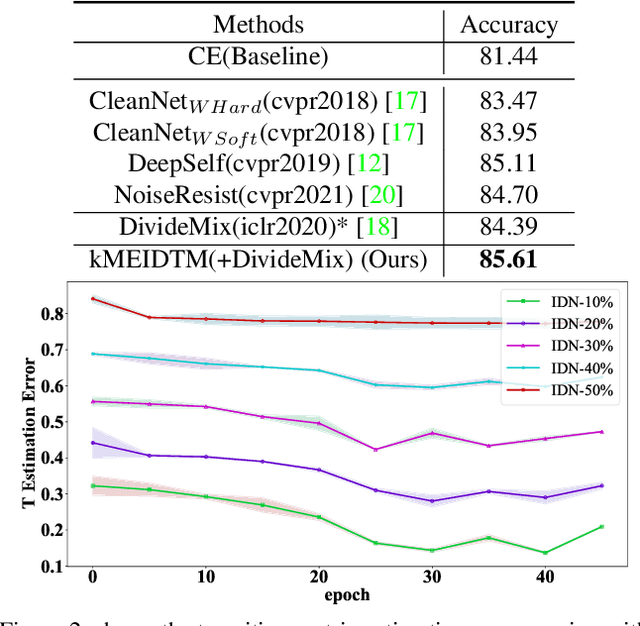
In label-noise learning, estimating the transition matrix has attracted more and more attention as the matrix plays an important role in building statistically consistent classifiers. However, it is very challenging to estimate the transition matrix T(x), where x denotes the instance, because it is unidentifiable under the instance-dependent noise(IDN). To address this problem, we have noticed that, there are psychological and physiological evidences showing that we humans are more likely to annotate instances of similar appearances to the same classes, and thus poor-quality or ambiguous instances of similar appearances are easier to be mislabeled to the correlated or same noisy classes. Therefore, we propose assumption on the geometry of T(x) that "the closer two instances are, the more similar their corresponding transition matrices should be". More specifically, we formulate above assumption into the manifold embedding, to effectively reduce the degree of freedom of T(x) and make it stably estimable in practice. The proposed manifold-regularized technique works by directly reducing the estimation error without hurting the approximation error about the estimation problem of T(x). Experimental evaluations on four synthetic and two real-world datasets demonstrate that our method is superior to state-of-the-art approaches for label-noise learning under the challenging IDN.
Excess risk analysis for epistemic uncertainty with application to variational inference
Jun 02, 2022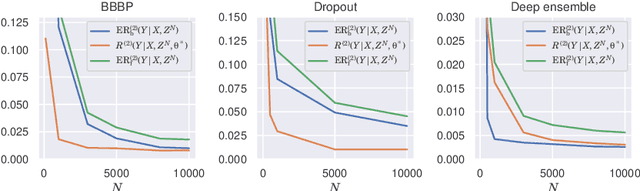
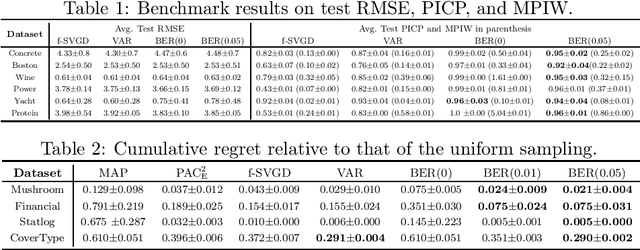
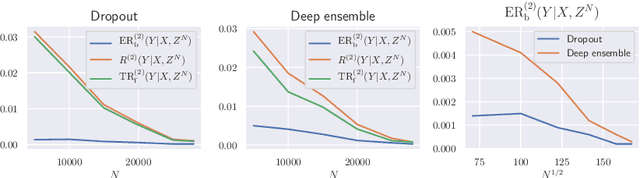
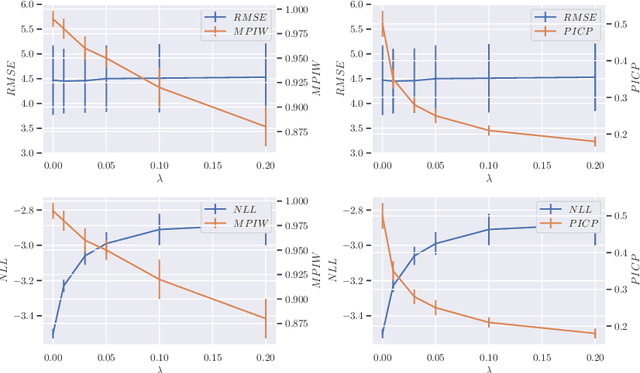
We analyze the epistemic uncertainty (EU) of supervised learning in Bayesian inference by focusing on the excess risk. Existing analysis is limited to the Bayesian setting, which assumes a correct model and exact Bayesian posterior distribution. Thus we cannot apply the existing theory to modern Bayesian algorithms, such as variational inference. To address this, we present a novel EU analysis in the frequentist setting, where data is generated from an unknown distribution. We show a relation between the generalization ability and the widely used EU measurements, such as the variance and entropy of the predictive distribution. Then we show their convergence behaviors theoretically. Finally, we propose new variational inference that directly controls the prediction and EU evaluation performances based on the PAC-Bayesian theory. Numerical experiments show that our algorithm significantly improves the EU evaluation over the existing methods.
Universal approximation property of invertible neural networks
Apr 15, 2022

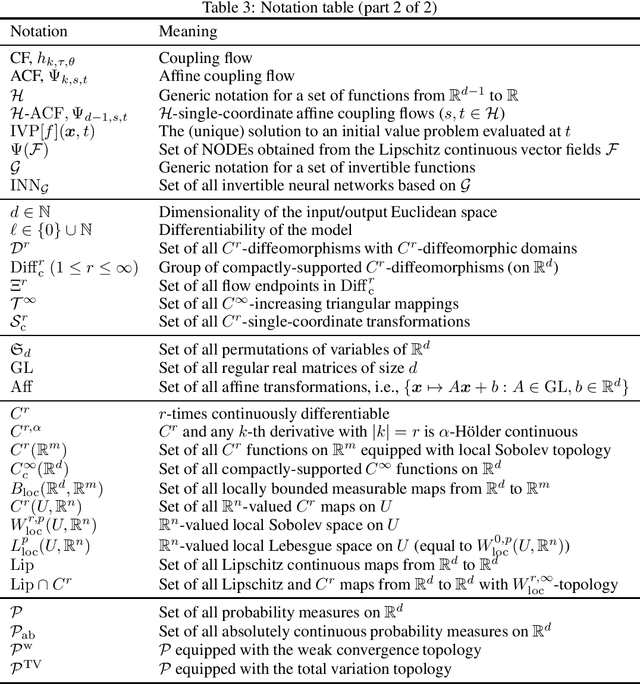
Invertible neural networks (INNs) are neural network architectures with invertibility by design. Thanks to their invertibility and the tractability of Jacobian, INNs have various machine learning applications such as probabilistic modeling, generative modeling, and representation learning. However, their attractive properties often come at the cost of restricting the layer designs, which poses a question on their representation power: can we use these models to approximate sufficiently diverse functions? To answer this question, we have developed a general theoretical framework to investigate the representation power of INNs, building on a structure theorem of differential geometry. The framework simplifies the approximation problem of diffeomorphisms, which enables us to show the universal approximation properties of INNs. We apply the framework to two representative classes of INNs, namely Coupling-Flow-based INNs (CF-INNs) and Neural Ordinary Differential Equations (NODEs), and elucidate their high representation power despite the restrictions on their architectures.
Federated Learning from Only Unlabeled Data with Class-Conditional-Sharing Clients
Apr 07, 2022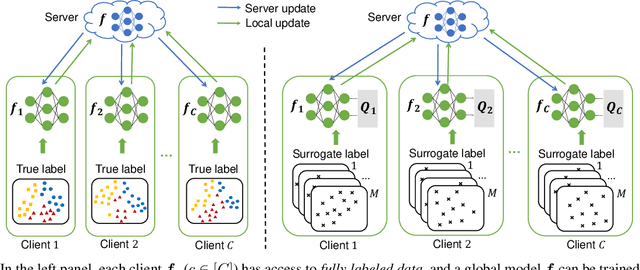
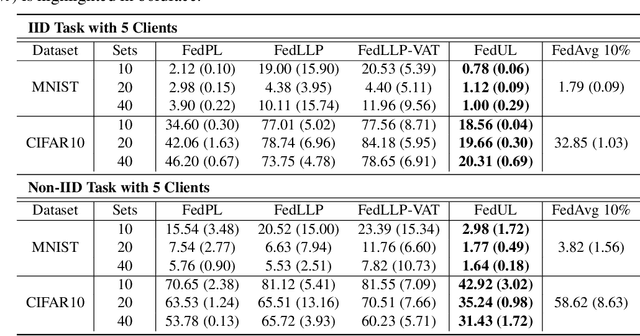
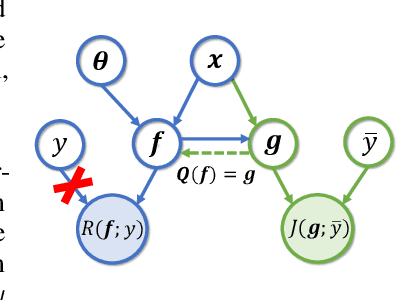
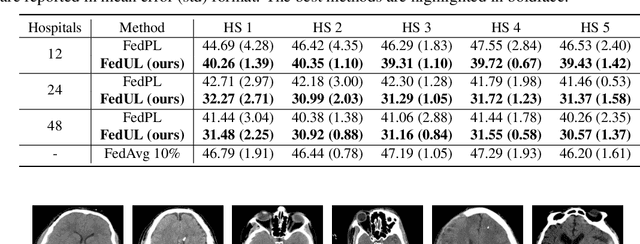
Supervised federated learning (FL) enables multiple clients to share the trained model without sharing their labeled data. However, potential clients might even be reluctant to label their own data, which could limit the applicability of FL in practice. In this paper, we show the possibility of unsupervised FL whose model is still a classifier for predicting class labels, if the class-prior probabilities are shifted while the class-conditional distributions are shared among the unlabeled data owned by the clients. We propose federation of unsupervised learning (FedUL), where the unlabeled data are transformed into surrogate labeled data for each of the clients, a modified model is trained by supervised FL, and the wanted model is recovered from the modified model. FedUL is a very general solution to unsupervised FL: it is compatible with many supervised FL methods, and the recovery of the wanted model can be theoretically guaranteed as if the data have been labeled. Experiments on benchmark and real-world datasets demonstrate the effectiveness of FedUL. Code is available at https://github.com/lunanbit/FedUL.