 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Imitation Learning from Noisy Demonstrations
Oct 31, 2020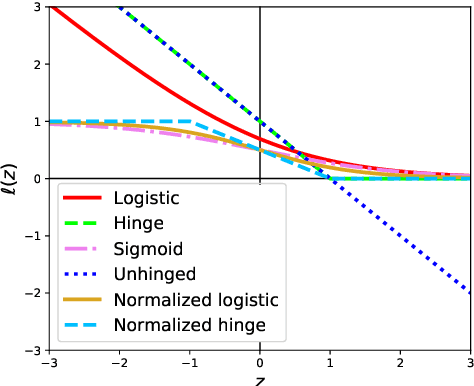
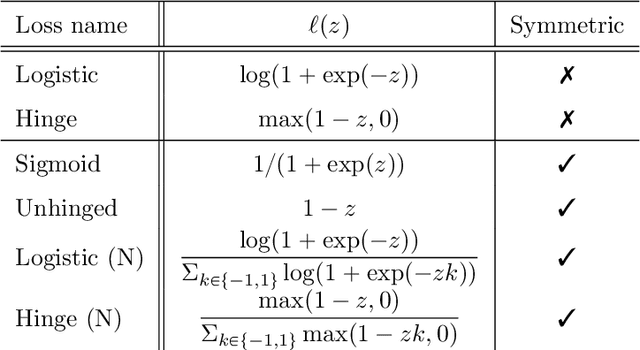
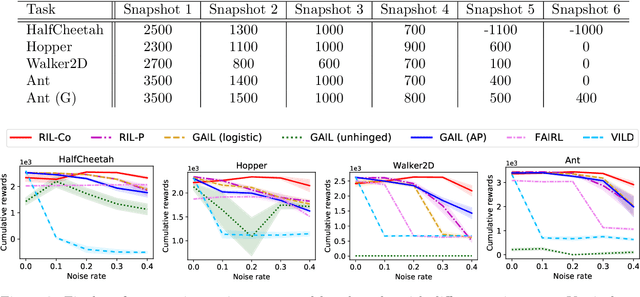
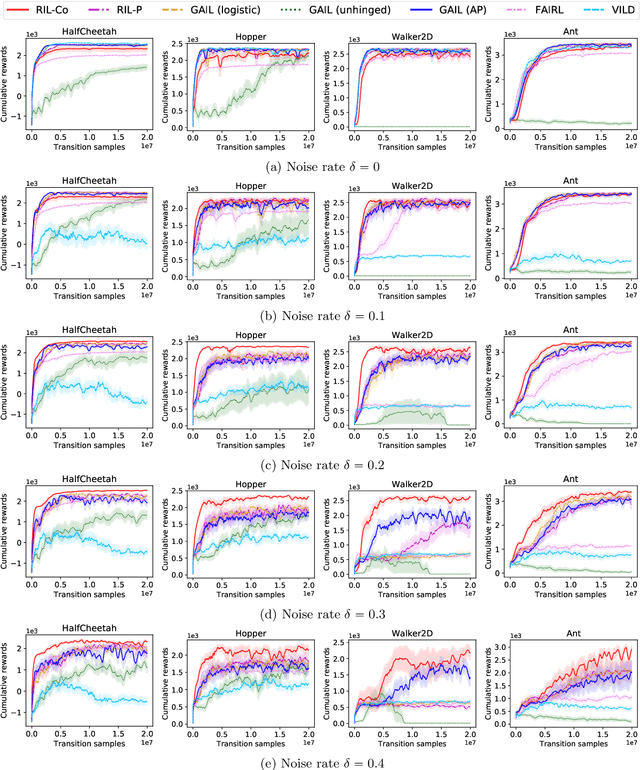
Learning from noisy demonstrations is a practical but highly challenging problem in imitation learning. In this paper, we first theoretically show that robust imitation learning can be achieved by optimizing a classification risk with a symmetric loss. Based on this theoretical finding, we then propose a new imitation learning method that optimizes the classification risk by effectively combining pseudo-labeling with co-training. Unlike existing methods, our method does not require additional labels or strict assumptions about noise distributions. Experimental results on continuous-control benchmarks show that our method is more robust compared to state-of-the-art methods.
Classification with Rejection Based on Cost-sensitive Classification
Oct 31, 2020
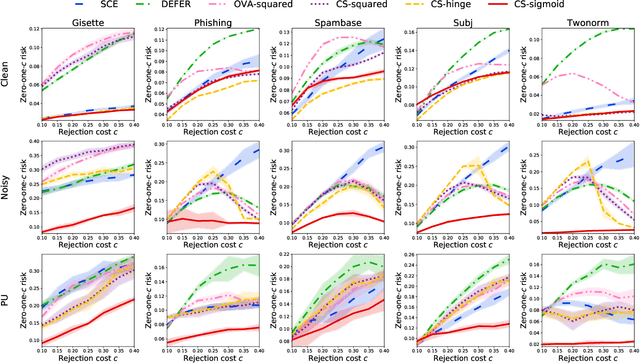
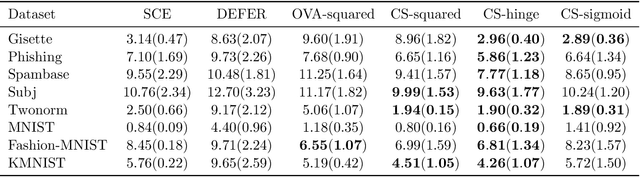

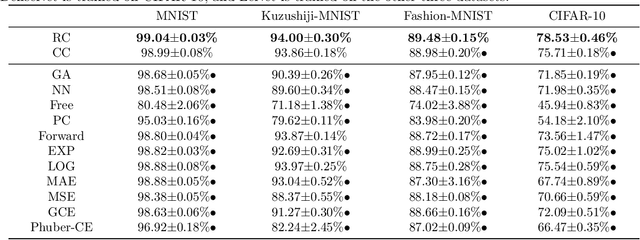
The goal of classification with rejection is to avoid risky misclassification in error-critical applications such as medical diagnosis and product inspection. In this paper, based on the relationship between classification with rejection and cost-sensitive classification, we propose a novel method of classification with rejection by learning an ensemble of cost-sensitive classifiers, which satisfies all the following properties for the first time: (i) it can avoid estimating class-posterior probabilities, resulting in improved classification accuracy. (ii) it allows a flexible choice of losses including non-convex ones, (iii) it does not require complicated modifications when using different losses, (iv) it is applicable to both binary and multiclass cases, and (v) it is theoretically justifiable for any classification-calibrated loss. Experimental results demonstrate the usefulness of our proposed approach in clean-labeled, noisy-labeled, and positive-unlabeled classification.
Maximum Mean Discrepancy is Aware of Adversarial Attacks
Oct 22, 2020

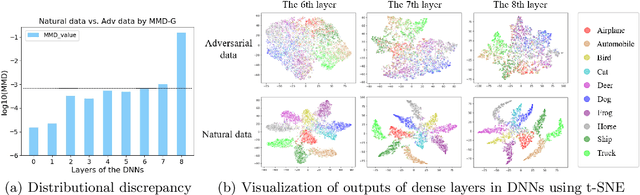

The maximum mean discrepancy (MMD) test, as a representative two-sample test, could in principle detect any distributional discrepancy between two datasets. However, it has been shown that MMD is unaware of adversarial attacks---MMD failed to detect the discrepancy between natural data and adversarial data generated by adversarial attacks. Given this phenomenon, we raise a question: are natural and adversarial data really from different distributions but previous use of MMD on the purpose missed some key factors? The answer is affirmative. We find the previous use missed three factors and accordingly we propose three components: (a) Gaussian kernel has limited representation power, and we replace it with a novel semantic-aware deep kernel; (b) test power of MMD was neglected, and we maximize it in order to optimize our deep kernel; (c) adversarial data may be non-independent, and to this end we apply wild bootstrap for validity of the test power. By taking care of the three factors, we validate that MMD is aware of adversarial attacks, which lights up a novel road for adversarial attack detection based on two-sample tests.
Pointwise Binary Classification with Pairwise Confidence Comparisons
Oct 05, 2020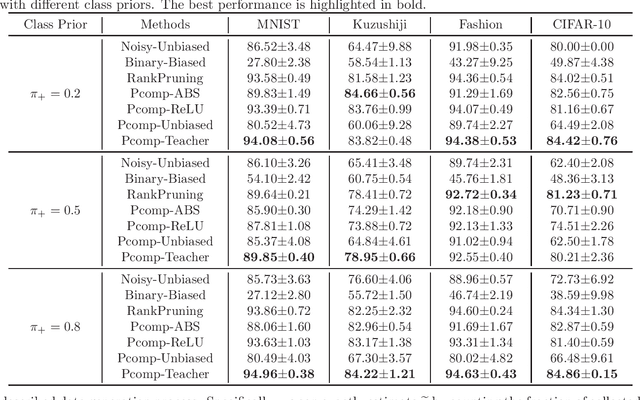

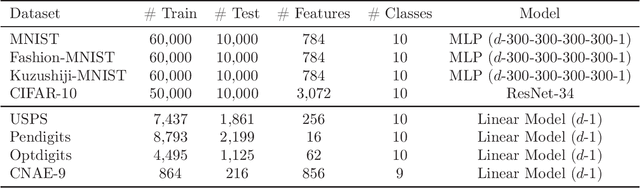
Ordinary (pointwise) binary classification aims to learn a binary classifier from pointwise labeled data. However, such pointwise labels may not be directly accessible due to privacy, confidentiality, or security considerations. In this case, can we still learn an accurate binary classifier? This paper proposes a novel setting, namely pairwise comparison (Pcomp) classification, where we are given only pairs of unlabeled data that we know one is more likely to be positive than the other, instead of pointwise labeled data. Pcomp classification is useful for private or subjective classification tasks. To solve this problem, we present a mathematical formulation for the generation process of pairwise comparison data, based on which we exploit an unbiased risk estimator(URE) to train a binary classifier by empirical risk minimization and establish an estimation error bound. We first prove that a URE can be derived and improve it using correction functions. Then, we start from the noisy-label learning perspective to introduce a progressive URE and improve it by imposing consistency regularization. Finally, experiments validate the effectiveness of our proposed solutions for Pcomp classification.
Geometry-aware Instance-reweighted Adversarial Training
Oct 05, 2020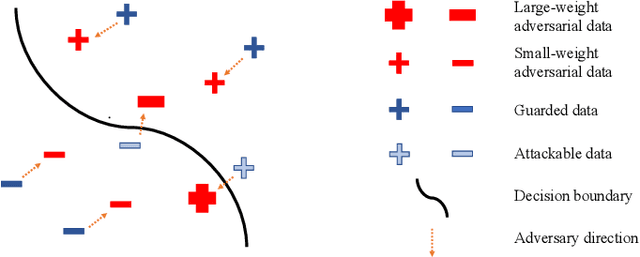

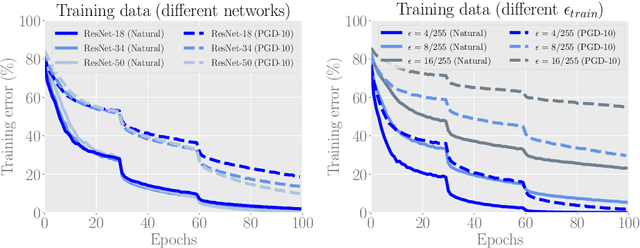

In adversarial machine learning, there was a common belief that robustness and accuracy hurt each other. The belief was challenged by recent studies where we can maintain the robustness and improve the accuracy. However, the other direction, whether we can keep the accuracy while improving the robustness, is conceptually and practically more interesting, since robust accuracy should be lower than standard accuracy for any model. In this paper, we show this direction is also promising. Firstly, we find even over-parameterized deep networks may still have insufficient model capacity, because adversarial training has an overwhelming smoothing effect. Secondly, given limited model capacity, we argue adversarial data should have unequal importance: geometrically speaking, a natural data point closer to/farther from the class boundary is less/more robust, and the corresponding adversarial data point should be assigned with larger/smaller weight. Finally, to implement the idea, we propose geometry-aware instance-reweighted adversarial training, where the weights are based on how difficult it is to attack a natural data point. Experiments show that our proposal boosts the robustness of standard adversarial training; combining two directions, we improve both robustness and accuracy of standard adversarial training.
Provably Consistent Partial-Label Learning
Jul 17, 2020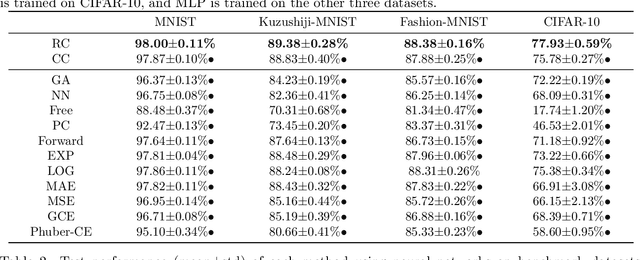
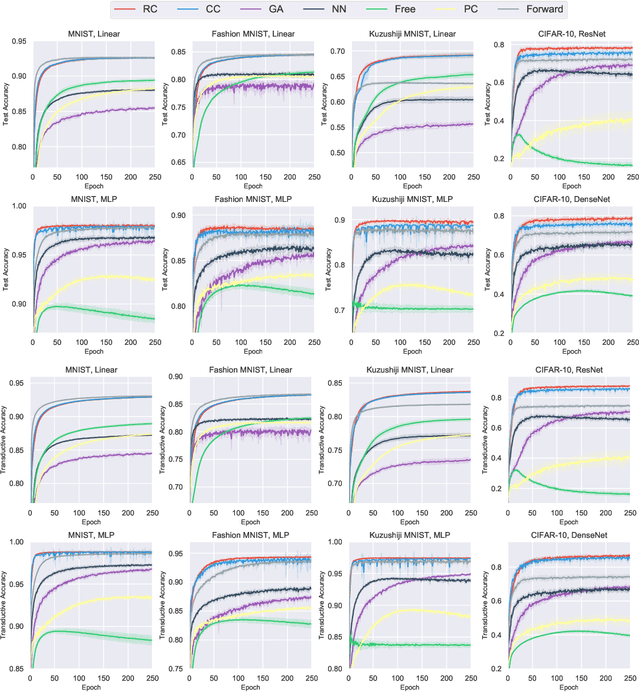
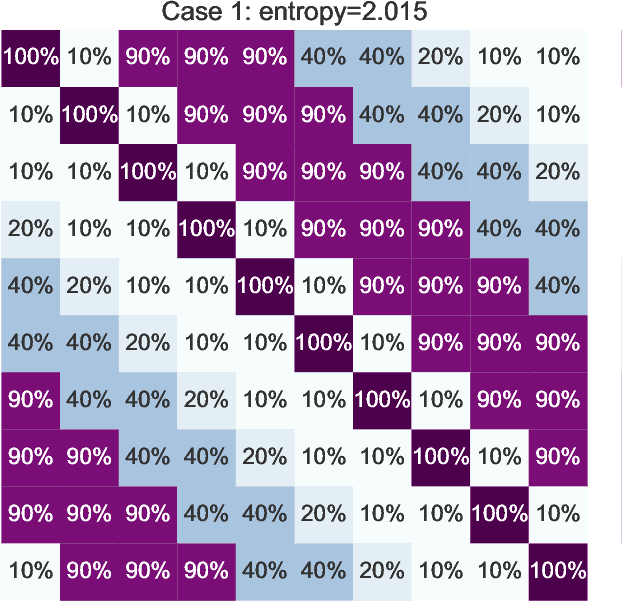
Partial-label learning (PLL) is a multi-class classification problem, where each training example is associated with a set of candidate labels. Even though many practical PLL methods have been proposed in the last two decades, there lacks a theoretical understanding of the consistency of those methods-none of the PLL methods hitherto possesses a generation process of candidate label sets, and then it is still unclear why such a method works on a specific dataset and when it may fail given a different dataset. In this paper, we propose the first generation model of candidate label sets, and develop two novel PLL methods that are guaranteed to be provably consistent, i.e., one is risk-consistent and the other is classifier-consistent. Our methods are advantageous, since they are compatible with any deep network or stochastic optimizer. Furthermore, thanks to the generation model, we would be able to answer the two questions above by testing if the generation model matches given candidate label sets. Experiments on benchmark and real-world datasets validate the effectiveness of the proposed generation model and two PLL methods.
Adai: Separating the Effects of Adaptive Learning Rate and Momentum Inertia
Jul 17, 2020
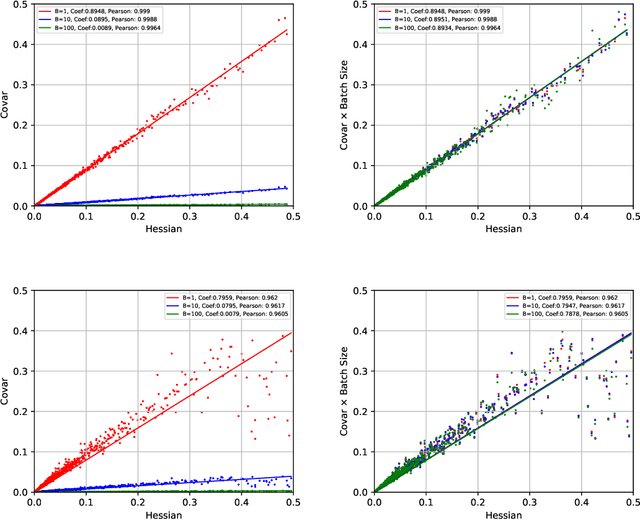
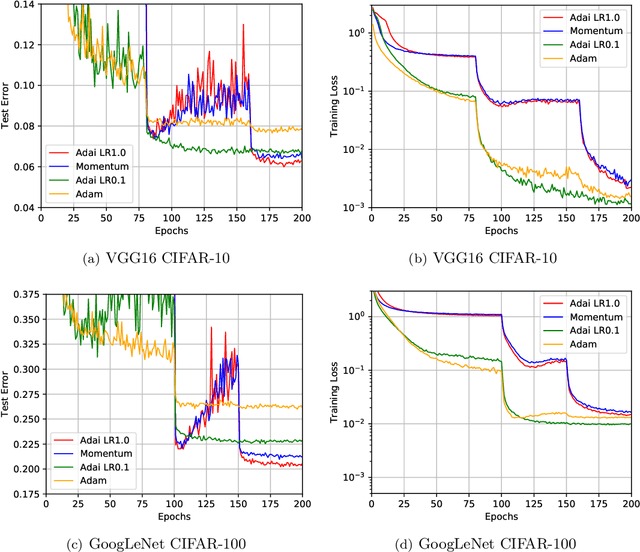
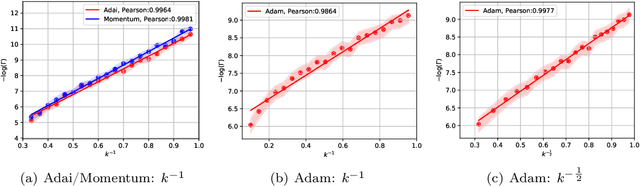
Adaptive Momentum Estimation (Adam), which combines Adaptive Learning Rate and Momentum, is the most popular stochastic optimizer for accelerating training of deep neural networks. But Adam often generalizes significantly worse than Stochastic Gradient Descent (SGD). It is still mathematically unclear how Adaptive Learning Rate and Momentum affect saddle-point escaping and minima selection. Based on the diffusion theoretical framework, we separate the effects of Adaptive Learning Rate and Momentum on saddle-point escaping and minima selection. We find that SGD escapes saddle points very slowly along the directions of small-magnitude eigenvalues of the Hessian. We prove that Adaptive Learning Rate can make learning dynamics near saddle points approximately Hessian-independent, but cannot select flat minima as SGD does. In contrast, Momentum provides a momentum drift effect to help passing through saddle points, and almost does not affect flat minima selection. This mathematically explains why SGD (with Momentum) generalizes better, while Adam generalizes worse but converges faster. Motivated by the diffusion theoretical analysis, we design a novel adaptive optimizer named Adaptive Inertia Estimation (Adai), which uses parameter-wise adaptive inertia to accelerate training and provably favors flat minima as much as SGD. Our real-world experiments demonstrate that Adai can converge similarly fast to Adam, but generalize significantly better. Adai even generalizes better than SGD, when converging fast to Adam is not required. The source is available to the public: \url{https://github.com/zeke-xie/adaptive-inertia-adai}.
A One-step Approach to Covariate Shift Adaptation
Jul 08, 2020
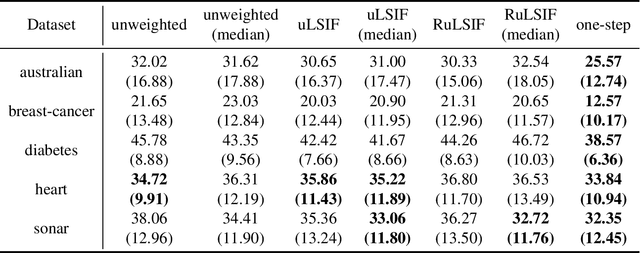
A default assumption in many machine learning scenarios is that the training and test samples are drawn from the same probability distribution. However, such an assumption is often violated in the real world due to non-stationarity of the environment or bias in sample selection. In this work, we consider a prevalent setting called covariate shift, where the input distribution differs between the training and test stages while the conditional distribution of the output given the input remains unchanged. Most of the existing methods for covariate shift adaptation are two-step approaches, which first calculate the importance weights and then conduct importance-weighted empirical risk minimization. In this paper, we propose a novel one-step approach that jointly learns the predictive model and the associated weights in one optimization by minimizing an upper bound of the test risk. We theoretically analyze the proposed method and provide a generalization error bound. We also empirically demonstrate the effectiveness of the proposed method.
Unbiased Risk Estimators Can Mislead: A Case Study of Learning with Complementary Labels
Jul 07, 2020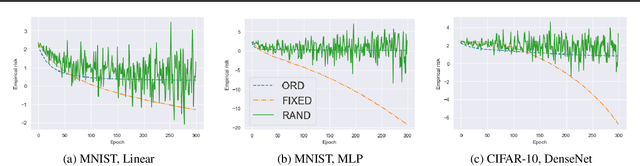
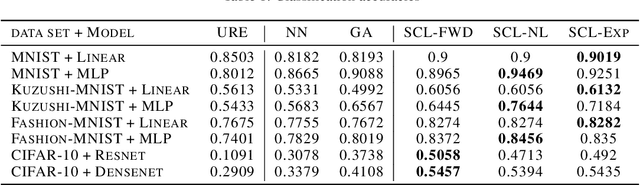
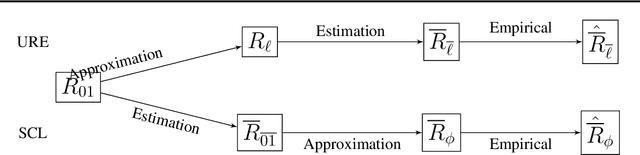
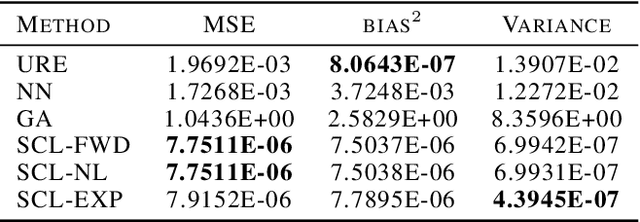
In weakly supervised learning, unbiased risk estimator(URE) is a powerful tool for training classifiers when training and test data are drawn from different distributions. Nevertheless, UREs lead to overfitting in many problem settings when the models are complex like deep networks. In this paper, we investigate reasons for such overfitting by studying a weakly supervised problem called learning with complementary labels. We argue the quality of gradient estimation matters more in risk minimization. Theoretically, we show that a URE gives an unbiased gradient estimator(UGE). Practically, however, UGEs may suffer from huge variance, which causes empirical gradients to be usually far away from true gradients during minimization. To this end, we propose a novel surrogate complementary loss(SCL) framework that trades zero bias with reduced variance and makes empirical gradients more aligned with true gradients in the direction. Thanks to this characteristic, SCL successfully mitigates the overfitting issue and improves URE-based methods.
Generalisation Guarantees for Continual Learning with Orthogonal Gradient Descent
Jul 06, 2020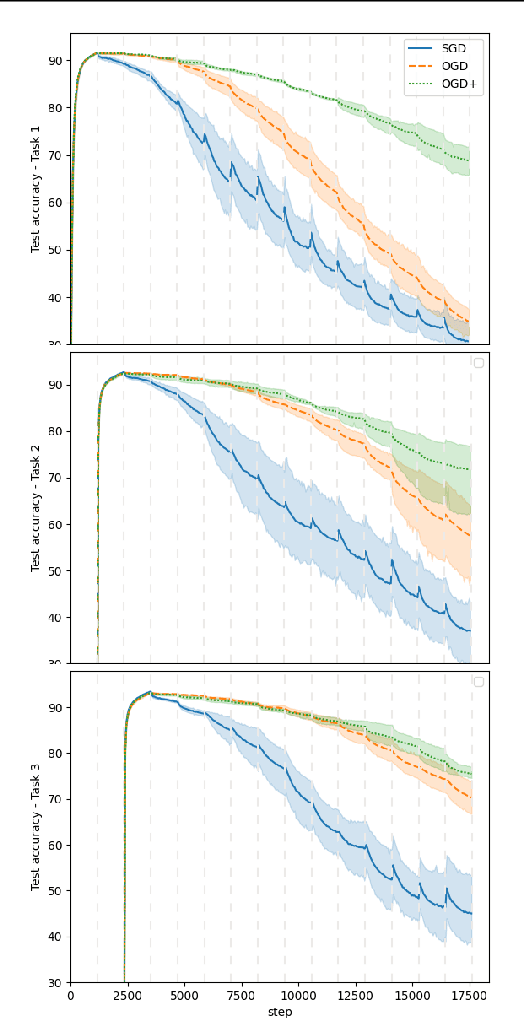
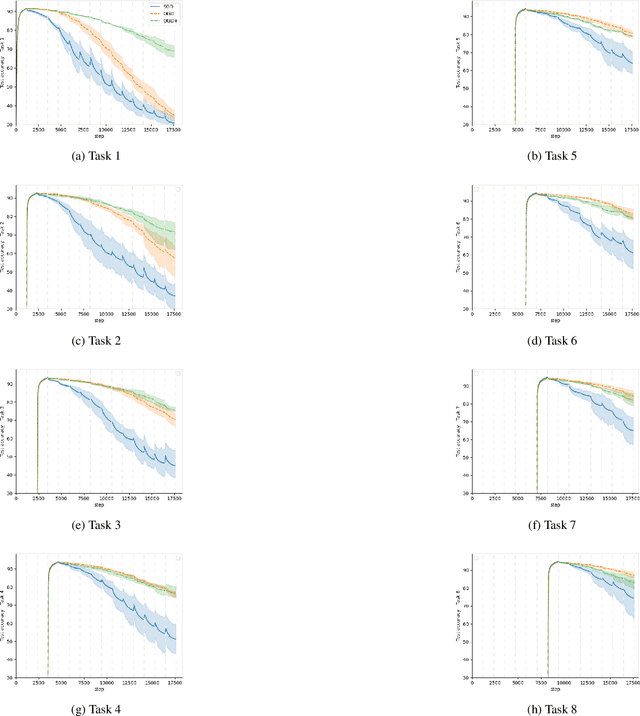
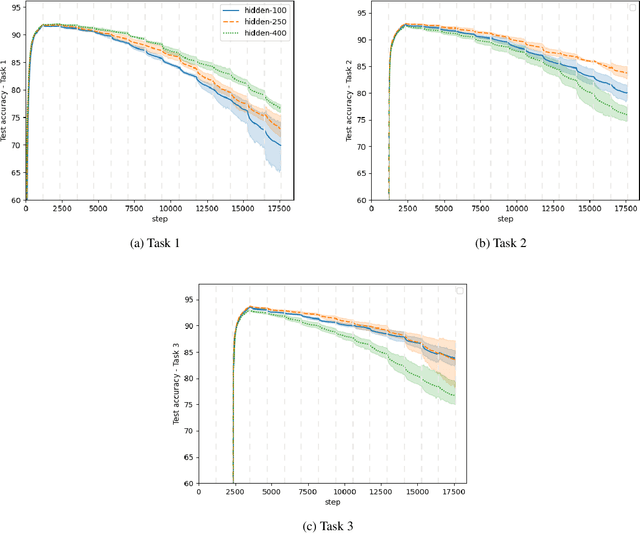
In continual learning settings, deep neural networks are prone to catastrophic forgetting. Orthogonal Gradient Descent (Farajtabar et al., 2019) achieves state-of-the-art results in practice for continual learning, although no theoretical guarantees have been proven yet. We derive the first generalisation guarantees for the algorithm OGD for continual learning, for overparameterized neural networks. We find that OGD is only provably robust to catastrophic forgetting across a single task. We propose OGD+, prove that it is robust to catastrophic forgetting across an arbitrary number of tasks, and that it verifies tighter generalisation bounds. The experiments show that OGD+ outperforms OGD on settings with long range memory dependencies, even though the models are not overparameterized. Also, we derive a closed form expression of the learned models through tasks, as a recursive kernel regression relation, which captures the transferability of knowledge through tasks. Finally, we quantify theoretically the impact of task ordering on the generalisation error, which highlights the importance of the curriculum for lifelong learning.