 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning What to Learn for Video Object Segmentation
May 01, 2020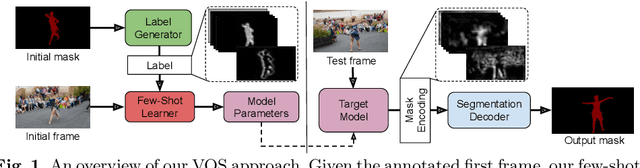

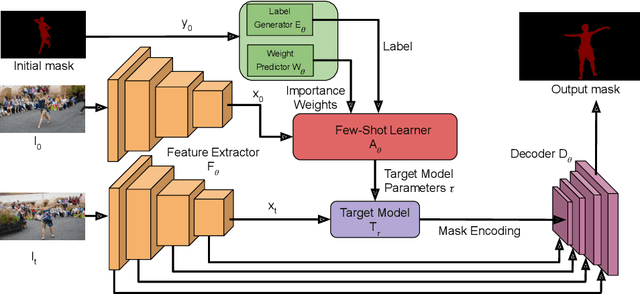
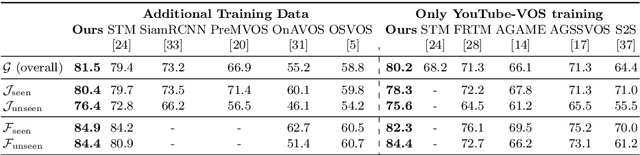
Video object segmentation (VOS) is a highly challenging problem, since the target object is only defined during inference with a given first-frame reference mask. The problem of how to capture and utilize this limited target information remains a fundamental research question. We address this by introducing an end-to-end trainable VOS architecture that integrates a differentiable few-shot learning module. This internal learner is designed to predict a powerful parametric model of the target by minimizing a segmentation error in the first frame. We further go beyond standard few-shot learning techniques by learning what the few-shot learner should learn. This allows us to achieve a rich internal representation of the target in the current frame, significantly increasing the segmentation accuracy of our approach. We perform extensive experiments on multiple benchmarks. Our approach sets a new state-of-the-art on the large-scale YouTube-VOS 2018 dataset by achieving an overall score of 81.5, corresponding to a 2.6% relative improvement over the previous best result.
Learning Human-Object Interaction Detection using Interaction Points
Mar 31, 2020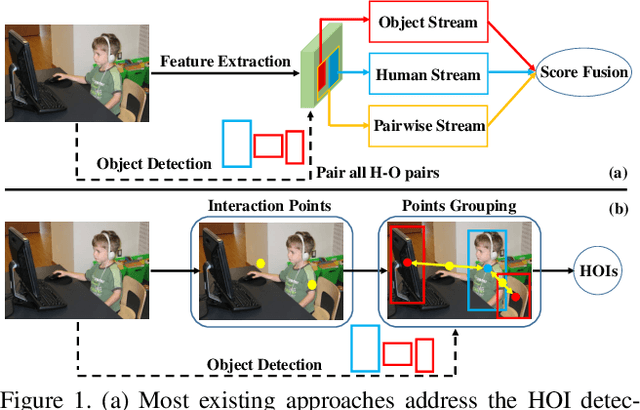
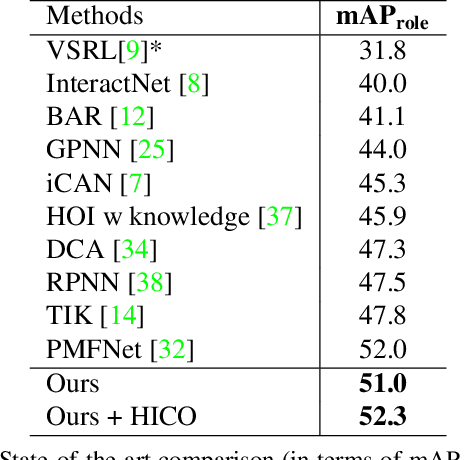
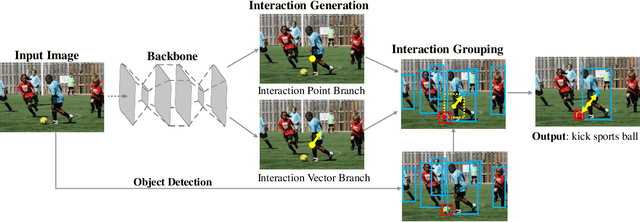
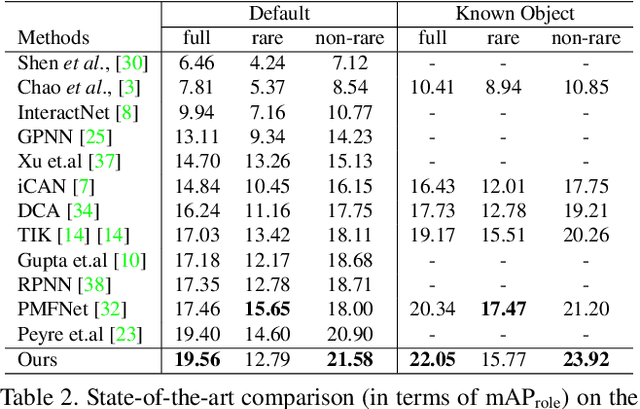
Understanding interactions between humans and objects is one of the fundamental problems in visual classification and an essential step towards detailed scene understanding. Human-object interaction (HOI) detection strives to localize both the human and an object as well as the identification of complex interactions between them. Most existing HOI detection approaches are instance-centric where interactions between all possible human-object pairs are predicted based on appearance features and coarse spatial information. We argue that appearance features alone are insufficient to capture complex human-object interactions. In this paper, we therefore propose a novel fully-convolutional approach that directly detects the interactions between human-object pairs. Our network predicts interaction points, which directly localize and classify the inter-action. Paired with the densely predicted interaction vectors, the interactions are associated with human and object detections to obtain final predictions. To the best of our knowledge, we are the first to propose an approach where HOI detection is posed as a keypoint detection and grouping problem. Experiments are performed on two popular benchmarks: V-COCO and HICO-DET. Our approach sets a new state-of-the-art on both datasets. Code is available at https://github.com/vaesl/IP-Net.
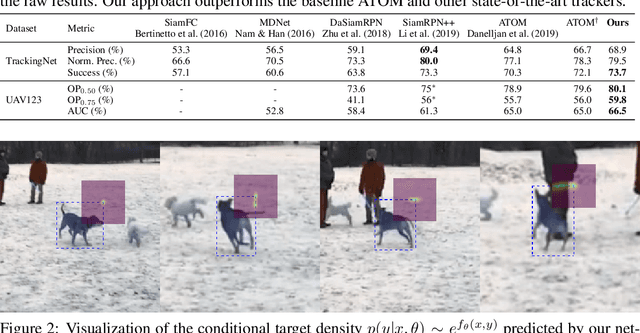
Probabilistic Regression for Visual Tracking
Mar 27, 2020
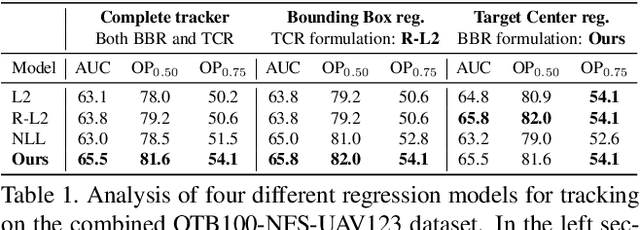

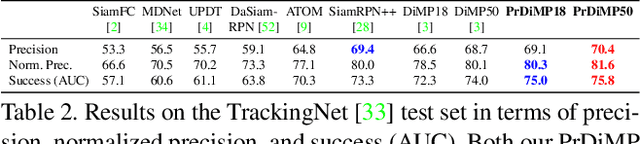
Visual tracking is fundamentally the problem of regressing the state of the target in each video frame. While significant progress has been achieved, trackers are still prone to failures and inaccuracies. It is therefore crucial to represent the uncertainty in the target estimation. Although current prominent paradigms rely on estimating a state-dependent confidence score, this value lacks a clear probabilistic interpretation, complicating its use. In this work, we therefore propose a probabilistic regression formulation and apply it to tracking. Our network predicts the conditional probability density of the target state given an input image. Crucially, our formulation is capable of modeling label noise stemming from inaccurate annotations and ambiguities in the task. The regression network is trained by minimizing the Kullback-Leibler divergence. When applied for tracking, our formulation not only allows a probabilistic representation of the output, but also substantially improves the performance. Our tracker sets a new state-of-the-art on six datasets, achieving 59.8% AUC on LaSOT and 75.8% Success on TrackingNet. The code and models are available at https://github.com/visionml/pytracking.
Learning Fast and Robust Target Models for Video Object Segmentation
Feb 27, 2020

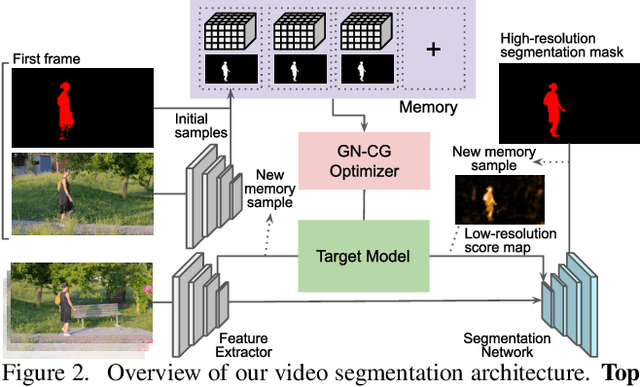
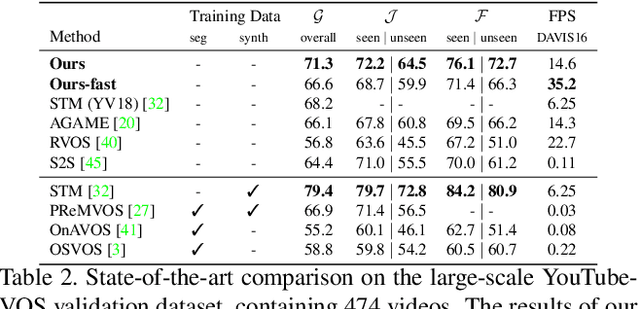
Video object segmentation (VOS) is a highly challenging problem since the initial mask, defining the target object, is only given at test-time. The main difficulty is to effectively handle appearance changes and similar background objects, while maintaining accurate segmentation. Most previous approaches fine-tune segmentation networks on the first frame, resulting in impractical frame-rates and risk of overfitting. More recent methods integrate generative target appearance models, but either achieve limited robustness or require large amounts of training data. We propose a novel VOS architecture consisting of two network components. The target appearance model consists of a light-weight module, learned during the inference stage using fast optimization techniques to predict a coarse but robust target segmentation. The segmentation model is exclusively trained offline, designed to process the coarse scores into high quality segmentation masks. Our method is fast, easily trainable and remains is highly effective in cases of limited training data. We perform extensive experiments on the challenging YouTube-VOS and DAVIS datasets. Our network achieves favorable performance, while operating at significantly higher frame-rates compared to state-of-the-art. Code is available at https://github.com/andr345/frtm-vos.
GLU-Net: Global-Local Universal Network for Dense Flow and Correspondences
Dec 11, 2019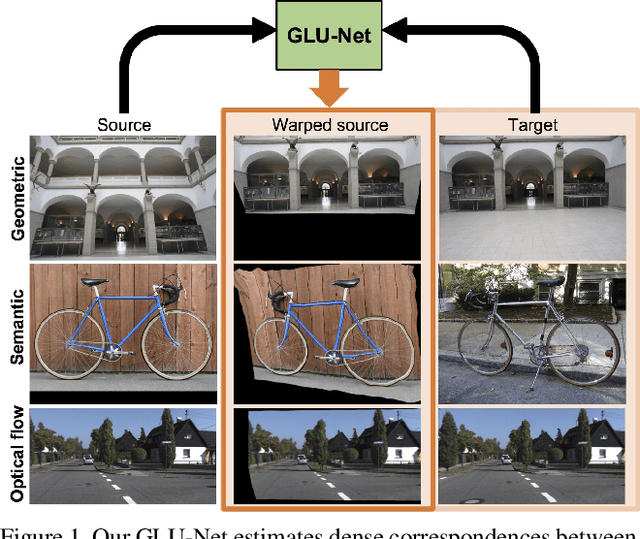
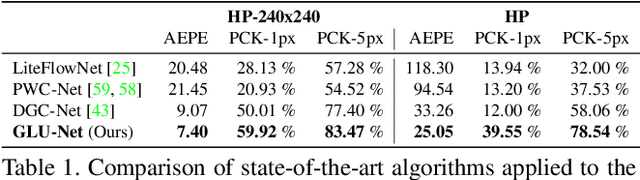
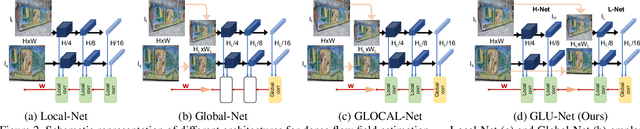
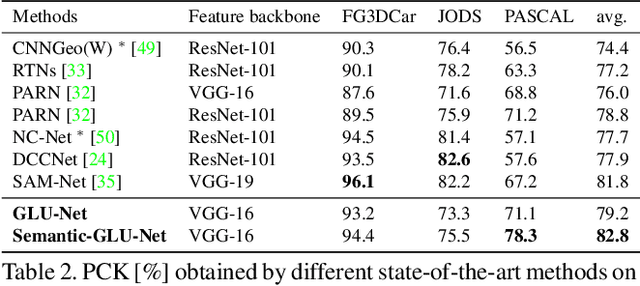
Establishing dense correspondences between a pair of images is an important and general problem, covering geometric matching, optical flow and semantic correspondences. While these applications share fundamental challenges, such as large displacements, pixel-accuracy, and appearance changes, they are currently addressed with specialized network architectures, designed for only one particular task. This severely limits the generalization capabilities of such networks to new scenarios, where e.g. robustness to larger displacements or higher accuracy is required. In this work, we propose a universal network architecture that is directly applicable to all the aforementioned dense correspondence problems. We achieve both high accuracy and robustness to large displacements by investigating the combined use of global and local correlation layers. We further propose an adaptive resolution strategy, allowing our network to operate on virtually any input image resolution. The proposed GLU-Net achieves state-of-the-art performance for geometric and semantic matching as well as optical flow, when using the same network and weights.
AIM 2019 Challenge on Real-World Image Super-Resolution: Methods and Results
Nov 19, 2019
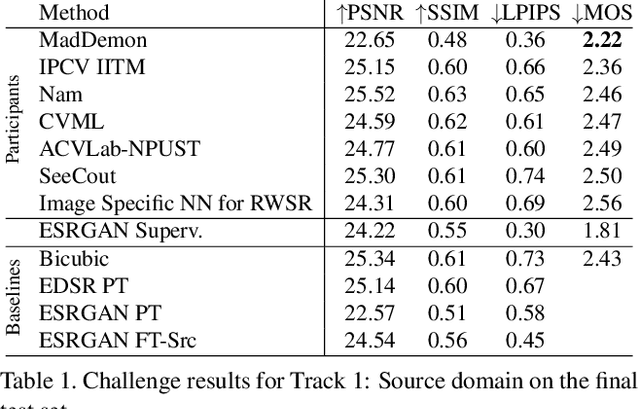
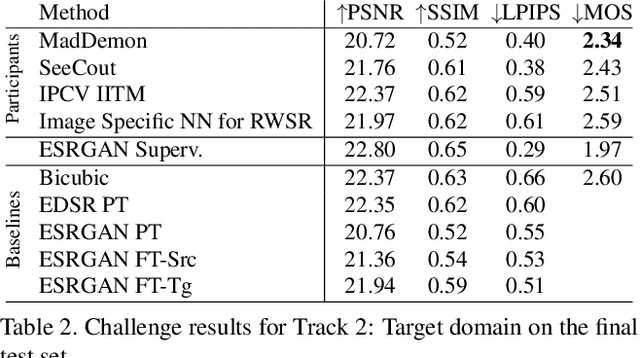

This paper reviews the AIM 2019 challenge on real world super-resolution. It focuses on the participating methods and final results. The challenge addresses the real world setting, where paired true high and low-resolution images are unavailable. For training, only one set of source input images is therefore provided in the challenge. In Track 1: Source Domain the aim is to super-resolve such images while preserving the low level image characteristics of the source input domain. In Track 2: Target Domain a set of high-quality images is also provided for training, that defines the output domain and desired quality of the super-resolved images. To allow for quantitative evaluation, the source input images in both tracks are constructed using artificial, but realistic, image degradations. The challenge is the first of its kind, aiming to advance the state-of-the-art and provide a standard benchmark for this newly emerging task. In total 7 teams competed in the final testing phase, demonstrating new and innovative solutions to the problem.
DCTD: Deep Conditional Target Densities for Accurate Regression
Sep 26, 2019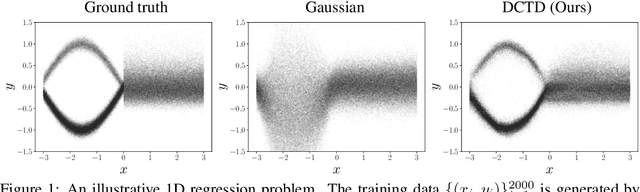


While deep learning-based classification is generally addressed using standardized approaches, a wide variety of techniques are employed for regression. In computer vision, one particularly popular such technique is that of confidence-based regression, which entails predicting a confidence value for each input-target pair (x, y). While this approach has demonstrated impressive results, it requires important task-dependent design choices, and the predicted confidences often lack a natural probabilistic meaning. We address these issues by proposing Deep Conditional Target Densities (DCTD), a novel and general regression method with a clear probabilistic interpretation. DCTD models the conditional target density p(y|x) by using a neural network to directly predict the un-normalized density from (x, y). This model of p(y|x) is trained by minimizing the associated negative log-likelihood, approximated using Monte Carlo sampling. We perform comprehensive experiments on four computer vision regression tasks. Our approach outperforms direct regression, as well as other probabilistic and confidence-based methods. Notably, our regression model achieves a 1.9% AP improvement over Faster-RCNN for object detection on the COCO dataset, and sets a new state-of-the-art on visual tracking when applied for bounding box regression.
Unsupervised Learning for Real-World Super-Resolution
Sep 20, 2019
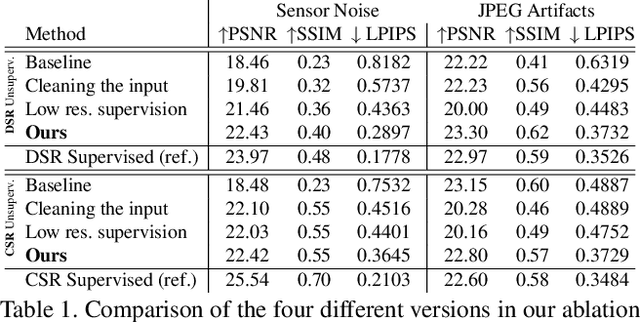

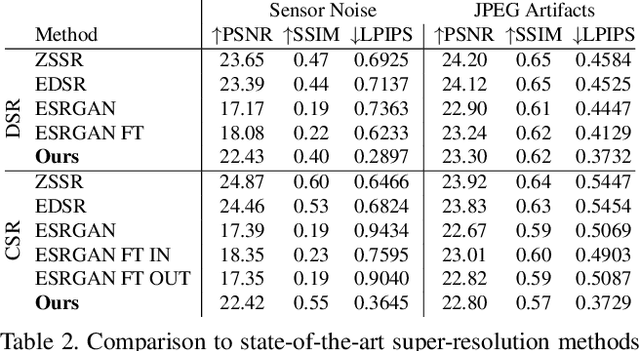
Most current super-resolution methods rely on low and high resolution image pairs to train a network in a fully supervised manner. However, such image pairs are not available in real-world applications. Instead of directly addressing this problem, most works employ the popular bicubic downsampling strategy to artificially generate a corresponding low resolution image. Unfortunately, this strategy introduces significant artifacts, removing natural sensor noise and other real-world characteristics. Super-resolution networks trained on such bicubic images therefore struggle to generalize to natural images. In this work, we propose an unsupervised approach for image super-resolution. Given only unpaired data, we learn to invert the effects of bicubic downsampling in order to restore the natural image characteristics present in the data. This allows us to generate realistic image pairs, faithfully reflecting the distribution of real-world images. Our super-resolution network can therefore be trained with direct pixel-wise supervision in the high resolution domain, while robustly generalizing to real input. We demonstrate the effectiveness of our approach in quantitative and qualitative experiments.
Learning the Model Update for Siamese Trackers
Sep 06, 2019
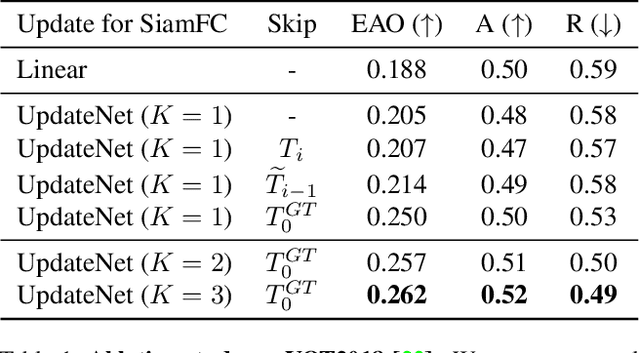
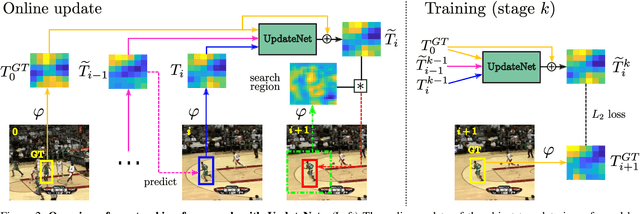
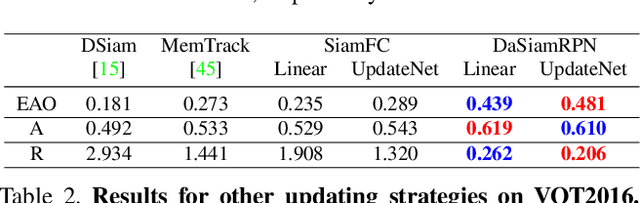
Siamese approaches address the visual tracking problem by extracting an appearance template from the current frame, which is used to localize the target in the next frame. In general, this template is linearly combined with the accumulated template from the previous frame, resulting in an exponential decay of information over time. While such an approach to updating has led to improved results, its simplicity limits the potential gain likely to be obtained by learning to update. Therefore, we propose to replace the handcrafted update function with a method which learns to update. We use a convolutional neural network, called UpdateNet, which given the initial template, the accumulated template and the template of the current frame aims to estimate the optimal template for the next frame. The UpdateNet is compact and can easily be integrated into existing Siamese trackers. We demonstrate the generality of the proposed approach by applying it to two Siamese trackers, SiamFC and DaSiamRPN. Extensive experiments on VOT2016, VOT2018, LaSOT, and TrackingNet datasets demonstrate that our UpdateNet effectively predicts the new target template, outperforming the standard linear update. On the large-scale TrackingNet dataset, our UpdateNet improves the results of DaSiamRPN with an absolute gain of 3.9% in terms of success score.
Multi-Modal Fusion for End-to-End RGB-T Tracking
Aug 30, 2019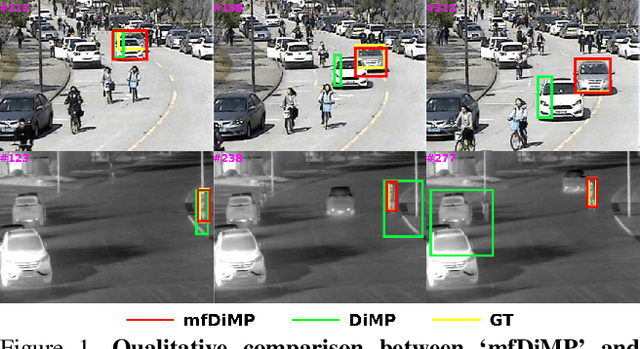
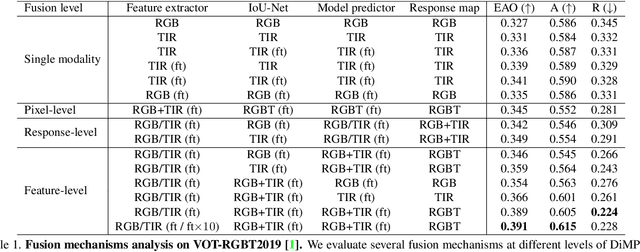
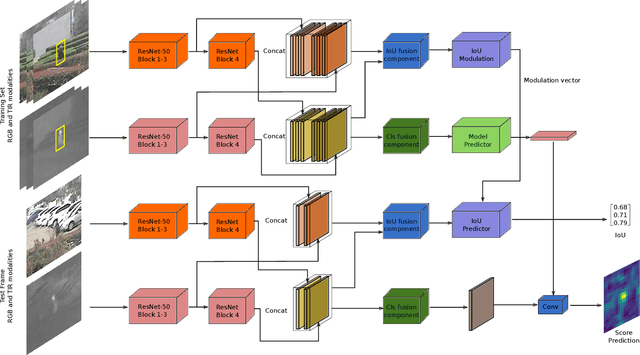
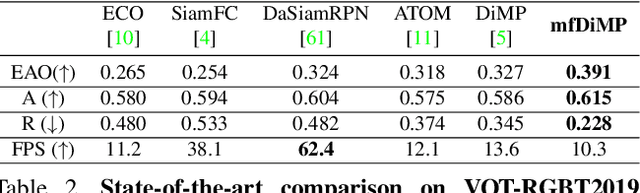
We propose an end-to-end tracking framework for fusing the RGB and TIR modalities in RGB-T tracking. Our baseline tracker is DiMP (Discriminative Model Prediction), which employs a carefully designed target prediction network trained end-to-end using a discriminative loss. We analyze the effectiveness of modality fusion in each of the main components in DiMP, i.e. feature extractor, target estimation network, and classifier. We consider several fusion mechanisms acting at different levels of the framework, including pixel-level, feature-level and response-level. Our tracker is trained in an end-to-end manner, enabling the components to learn how to fuse the information from both modalities. As data to train our model, we generate a large-scale RGB-T dataset by considering an annotated RGB tracking dataset (GOT-10k) and synthesizing paired TIR images using an image-to-image translation approach. We perform extensive experiments on VOT-RGBT2019 dataset and RGBT210 dataset, evaluating each type of modality fusing on each model component. The results show that the proposed fusion mechanisms improve the performance of the single modality counterparts. We obtain our best results when fusing at the feature-level on both the IoU-Net and the model predictor, obtaining an EAO score of 0.391 on VOT-RGBT2019 dataset. With this fusion mechanism we achieve the state-of-the-art performance on RGBT210 dataset.