 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIGLU 2022: Interactive Grounded Language Understanding in a Collaborative Environment at NeurIPS 2022
May 27, 2022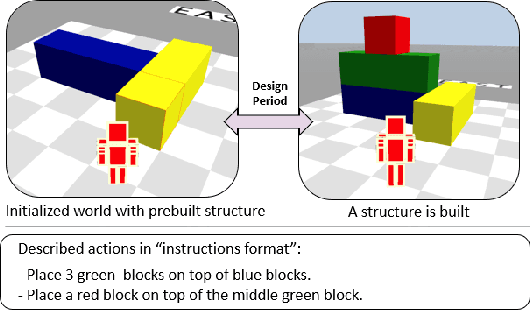

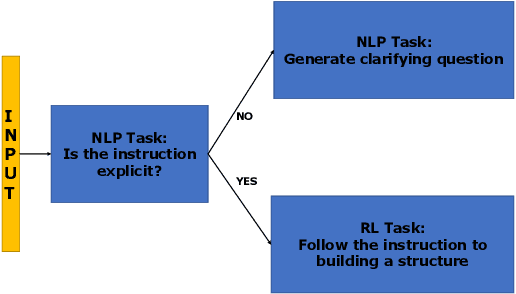
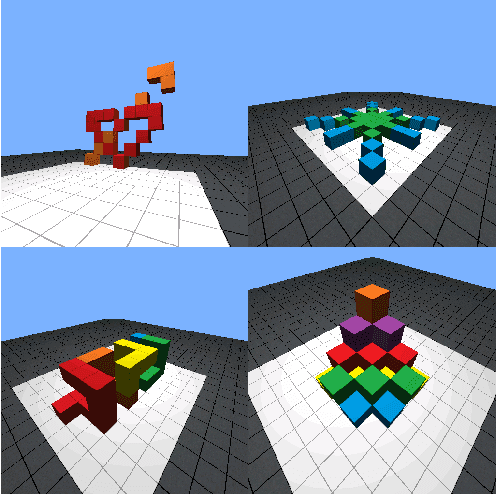
Human intelligence has the remarkable ability to adapt to new tasks and environments quickly. Starting from a very young age, humans acquire new skills and learn how to solve new tasks either by imitating the behavior of others or by following provided natural language instructions. To facilitate research in this direction, we propose IGLU: Interactive Grounded Language Understanding in a Collaborative Environment. The primary goal of the competition is to approach the problem of how to develop interactive embodied agents that learn to solve a task while provided with grounded natural language instructions in a collaborative environment. Understanding the complexity of the challenge, we split it into sub-tasks to make it feasible for participants. This research challenge is naturally related, but not limited, to two fields of study that are highly relevant to the NeurIPS community: Natural Language Understanding and Generation (NLU/G) and Reinforcement Learning (RL). Therefore, the suggested challenge can bring two communities together to approach one of the crucial challenges in AI. Another critical aspect of the challenge is the dedication to perform a human-in-the-loop evaluation as a final evaluation for the agents developed by contestants.
Asking for Knowledge: Training RL Agents to Query External Knowledge Using Language
May 12, 2022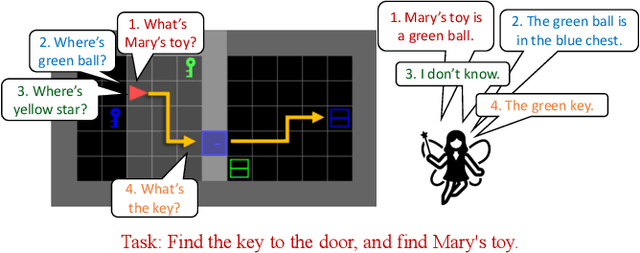
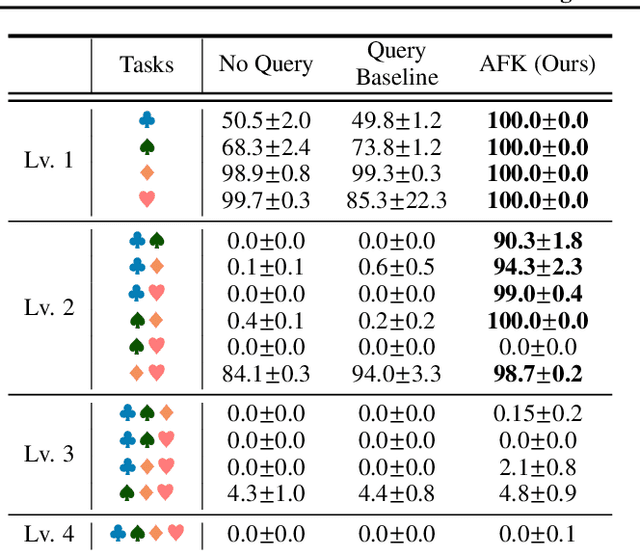


To solve difficult tasks, humans ask questions to acquire knowledge from external sources. In contrast, classical reinforcement learning agents lack such an ability and often resort to exploratory behavior. This is exacerbated as few present-day environments support querying for knowledge. In order to study how agents can be taught to query external knowledge via language, we first introduce two new environments: the grid-world-based Q-BabyAI and the text-based Q-TextWorld. In addition to physical interactions, an agent can query an external knowledge source specialized for these environments to gather information. Second, we propose the "Asking for Knowledge" (AFK) agent, which learns to generate language commands to query for meaningful knowledge that helps solve the tasks. AFK leverages a non-parametric memory, a pointer mechanism and an episodic exploration bonus to tackle (1) a large query language space, (2) irrelevant information, (3) delayed reward for making meaningful queries. Extensive experiments demonstrate that the AFK agent outperforms recent baselines on the challenging Q-BabyAI and Q-TextWorld environments.
ScienceWorld: Is your Agent Smarter than a 5th Grader?
Mar 14, 2022



This paper presents a new benchmark, ScienceWorld, to test agents' scientific reasoning abilities in a new interactive text environment at the level of a standard elementary school science curriculum. Despite the recent transformer-based progress seen in adjacent fields such as question-answering, scientific text processing, and the wider area of natural language processing, we find that current state-of-the-art models are unable to reason about or explain learned science concepts in novel contexts. For instance, models can easily answer what the conductivity of a previously seen material is but struggle when asked how they would conduct an experiment in a grounded, interactive environment to find the conductivity of an unknown material. This begs the question of whether current models are simply retrieving answers by way of seeing a large number of similar input examples or if they have learned to reason about concepts in a reusable manner. We hypothesize that agents need to be grounded in interactive environments to achieve such reasoning capabilities. Our experiments provide empirical evidence supporting this hypothesis -- showing that a 1.5 million parameter agent trained interactively for 100k steps outperforms a 11 billion parameter model statically trained for scientific question-answering and reasoning via millions of expert demonstrations.
One-Shot Learning from a Demonstration with Hierarchical Latent Language
Mar 09, 2022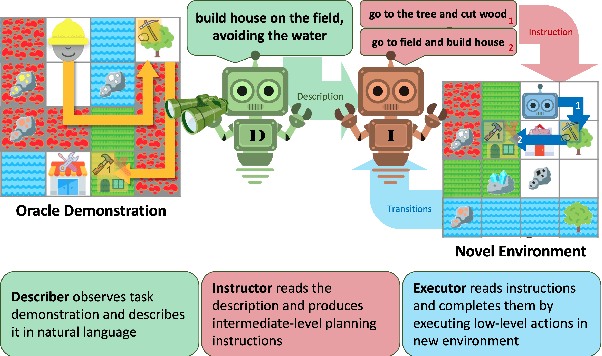
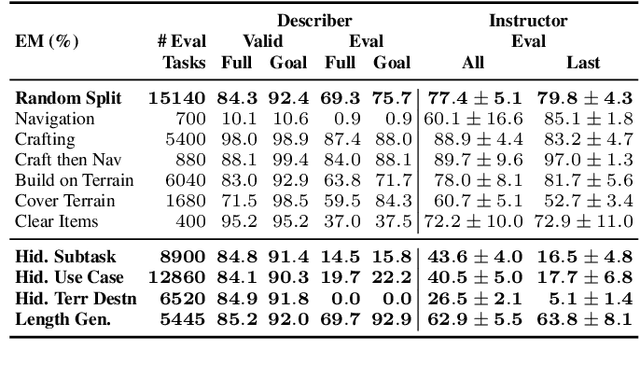
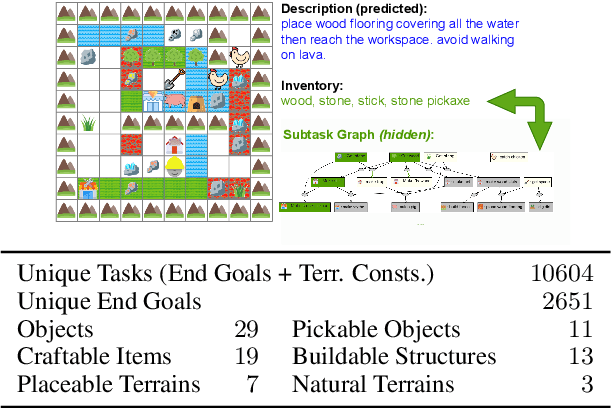
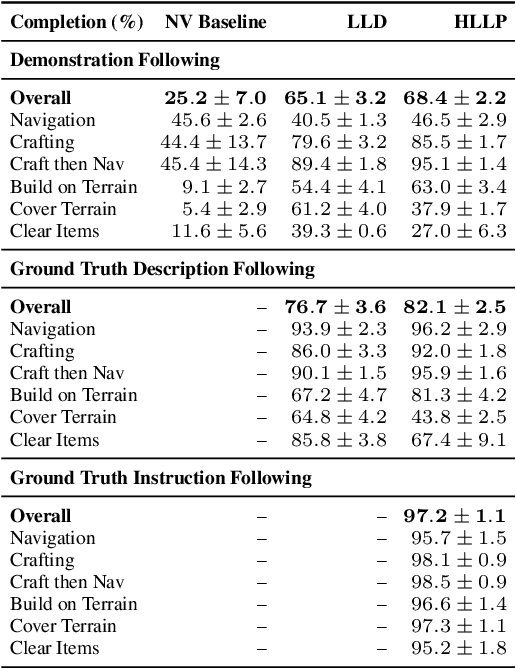
Humans have the capability, aided by the expressive compositionality of their language, to learn quickly by demonstration. They are able to describe unseen task-performing procedures and generalize their execution to other contexts. In this work, we introduce DescribeWorld, an environment designed to test this sort of generalization skill in grounded agents, where tasks are linguistically and procedurally composed of elementary concepts. The agent observes a single task demonstration in a Minecraft-like grid world, and is then asked to carry out the same task in a new map. To enable such a level of generalization, we propose a neural agent infused with hierarchical latent language--both at the level of task inference and subtask planning. Our agent first generates a textual description of the demonstrated unseen task, then leverages this description to replicate it. Through multiple evaluation scenarios and a suite of generalization tests, we find that agents that perform text-based inference are better equipped for the challenge under a random split of tasks.
ALFWorld: Aligning Text and Embodied Environments for Interactive Learning
Oct 08, 2020
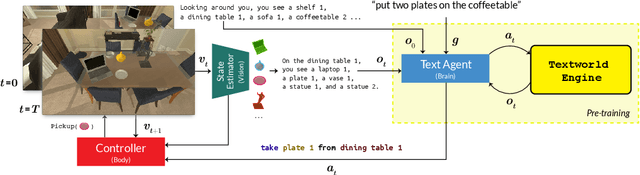

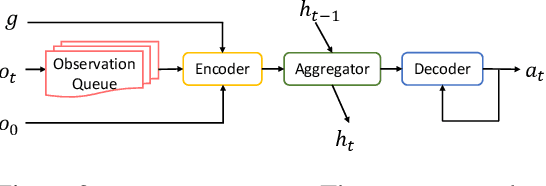
Given a simple request (e.g., Put a washed apple in the kitchen fridge), humans can reason in purely abstract terms by imagining action sequences and scoring their likelihood of success, prototypicality, and efficiency, all without moving a muscle. Once we see the kitchen in question, we can update our abstract plans to fit the scene. Embodied agents require the same abilities, but existing work does not yet provide the infrastructure necessary for both reasoning abstractly and executing concretely. We address this limitation by introducing ALFWorld, a simulator that enables agents to learn abstract, text-based policies in TextWorld (C\^ot\'e et al., 2018) and then execute goals from the ALFRED benchmark (Shridhar et al., 2020) in a rich visual environment. ALFWorld enables the creation of a new BUTLER agent whose abstract knowledge, learned in TextWorld, corresponds directly to concrete, visually grounded actions. In turn, as we demonstrate empirically, this fosters better agent generalization than training only in the visually grounded environment. BUTLER's simple, modular design factors the problem to allow researchers to focus on models for improving every piece of the pipeline (language understanding, planning, navigation, visual scene understanding, and so forth).
Graph Policy Network for Transferable Active Learning on Graphs
Jun 24, 2020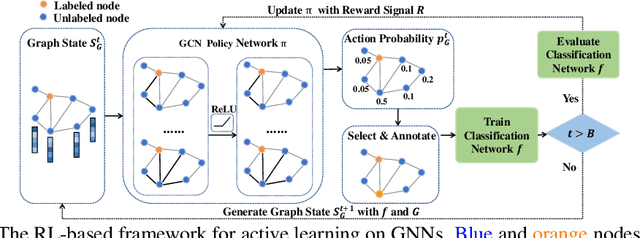
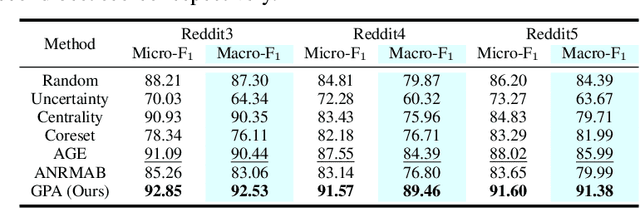
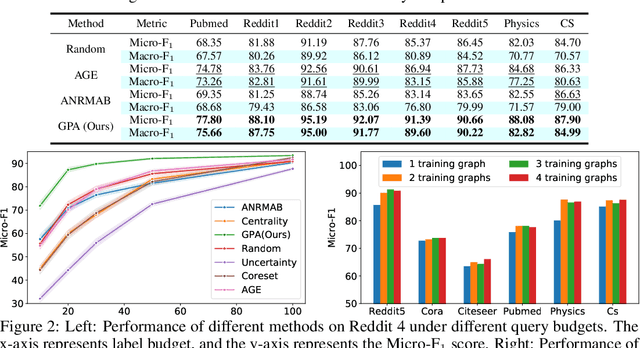

Graph neural networks (GNNs) have been attracting increasing popularity due to their simplicity and effectiveness in a variety of fields. However, a large number of labeled data is generally required to train these networks, which could be very expensive to obtain in some domains. In this paper, we study active learning for GNNs, i.e., how to efficiently label the nodes on a graph to reduce the annotation cost of training GNNs. We formulate the problem as a sequential decision process on graphs and train a GNN-based policy network with reinforcement learning to learn the optimal query strategy. By jointly optimizing over several source graphs with full labels, we learn a transferable active learning policy which can directly generalize to unlabeled target graphs under a zero-shot transfer setting. Experimental results on multiple graphs from different domains prove the effectiveness of our proposed approach in both settings of transferring between graphs in the same domain and across different domains.
Learning Dynamic Knowledge Graphs to Generalize on Text-Based Games
Feb 21, 2020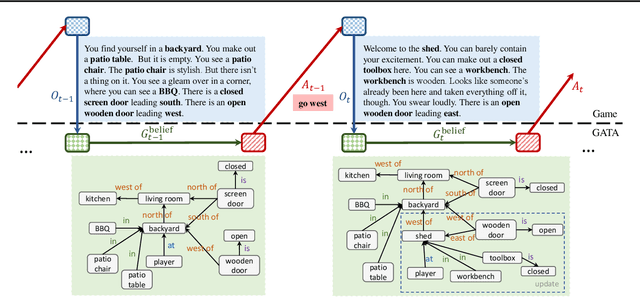

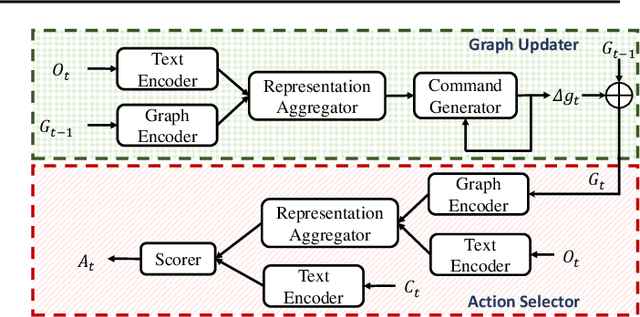
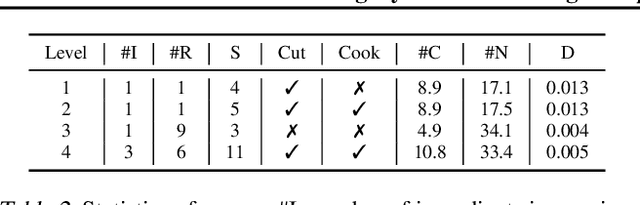
Playing text-based games requires skill in processing natural language and in planning. Although a key goal for agents solving this task is to generalize across multiple games, most previous work has either focused on solving a single game or has tackled generalization with rule-based heuristics. In this work, we investigate how structured information in the form of a knowledge graph (KG) can facilitate effective planning and generalization. We introduce a novel transformer-based sequence-to-sequence model that constructs a "belief" KG from raw text observations of the environment, dynamically updating this belief graph at every game step as it receives new observations. To train this model to build useful graph representations, we introduce and analyze a set of graph-related pre-training tasks. We demonstrate empirically that KG-based representations from our model help agents to converge faster to better policies for multiple text-based games, and further, enable stronger zero-shot performance on unseen games. Experiments on unseen games show that our best agent outperforms text-based baselines by 21.6%.
Interactive Fiction Games: A Colossal Adventure
Sep 11, 2019
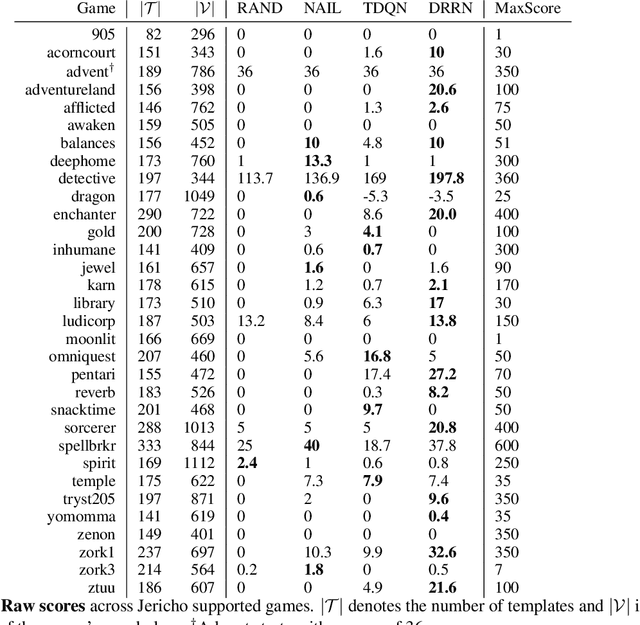
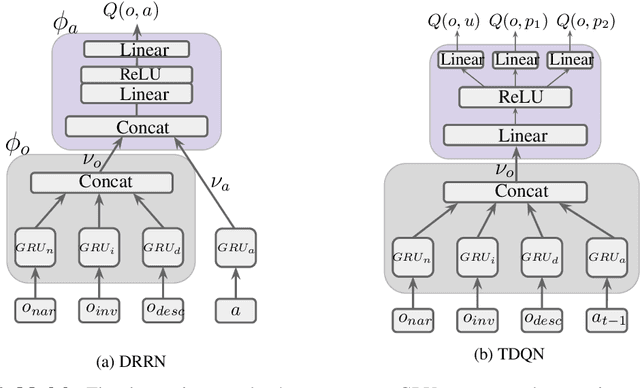

A hallmark of human intelligence is the ability to understand and communicate with language. Interactive Fiction games are fully text-based simulation environments where a player issues text commands to effect change in the environment and progress through the story. We argue that IF games are an excellent testbed for studying language-based autonomous agents. In particular, IF games combine challenges of combinatorial action spaces, language understanding, and commonsense reasoning. To facilitate rapid development of language-based agents, we introduce Jericho, a learning environment for man-made IF games and conduct a comprehensive study of text-agents across a rich set of games, highlighting directions in which agents can improve.
Unsupervised State Representation Learning in Atari
Jun 26, 2019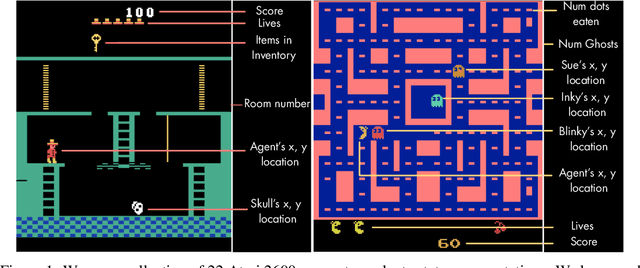
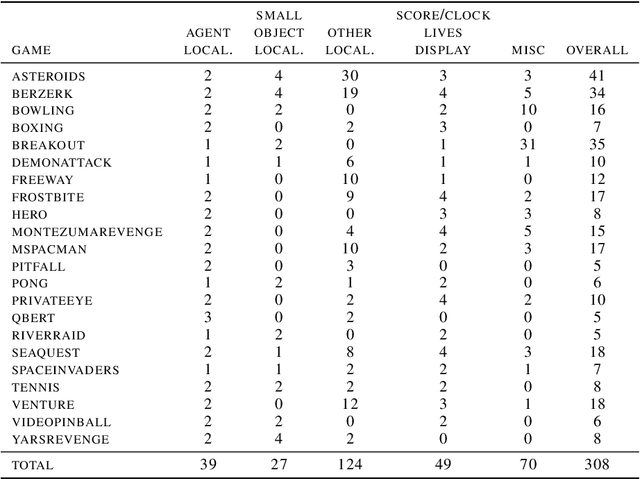
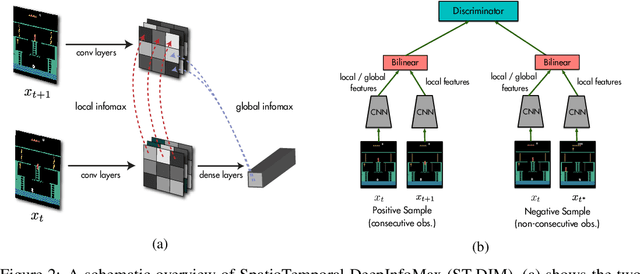
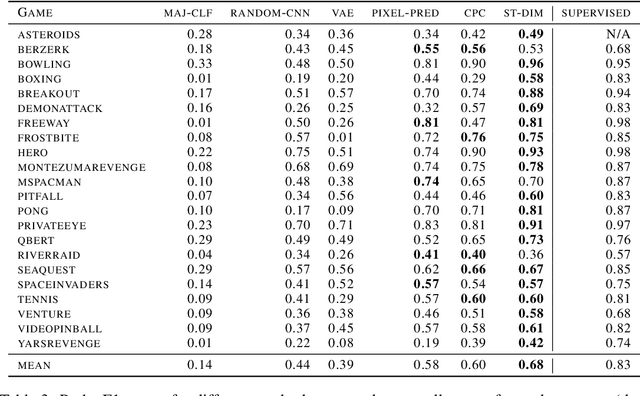
State representation learning, or the ability to capture latent generative factors of an environment, is crucial for building intelligent agents that can perform a wide variety of tasks. Learning such representations without supervision from rewards is a challenging open problem. We introduce a method that learns state representations by maximizing mutual information across spatially and temporally distinct features of a neural encoder of the observations. We also introduce a new benchmark based on Atari 2600 games where we evaluate representations based on how well they capture the ground truth state variables. We believe this new framework for evaluating representation learning models will be crucial for future representation learning research. Finally, we compare our technique with other state-of-the-art generative and contrastive representation learning methods.
Towards Solving Text-based Games by Producing Adaptive Action Spaces
Dec 03, 2018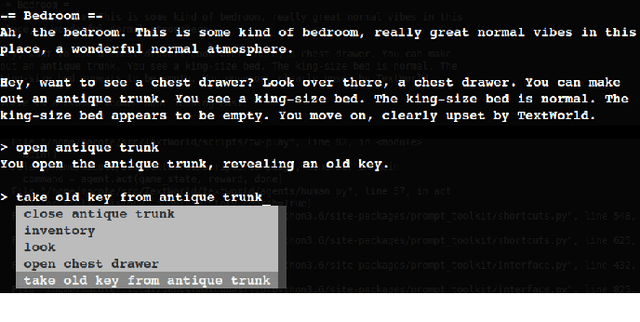

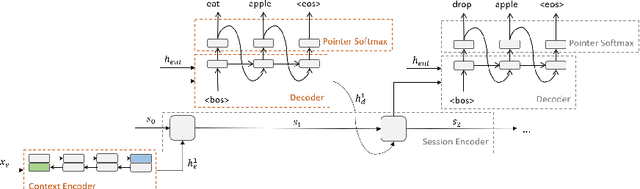
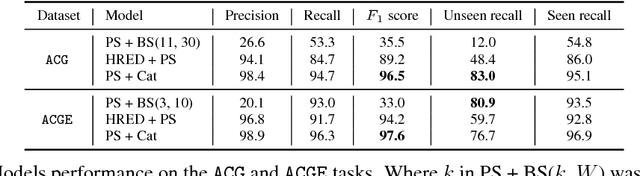
To solve a text-based game, an agent needs to formulate valid text commands for a given context and find the ones that lead to success. Recent attempts at solving text-based games with deep reinforcement learning have focused on the latter, i.e., learning to act optimally when valid actions are known in advance. In this work, we propose to tackle the first task and train a model that generates the set of all valid commands for a given context. We try three generative models on a dataset generated with Textworld. The best model can generate valid commands which were unseen at training and achieve high $F_1$ score on the test set.