 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequence Level Training with Recurrent Neural Networks
May 06, 2016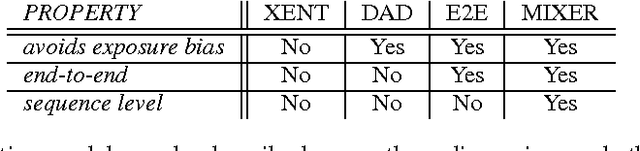
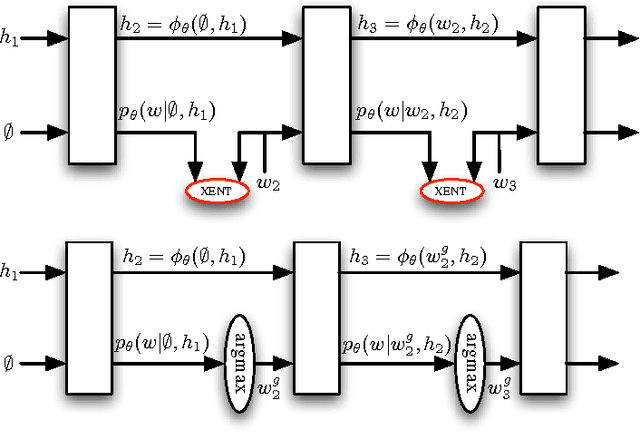
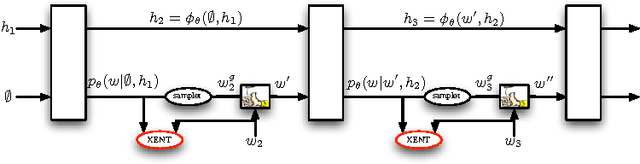
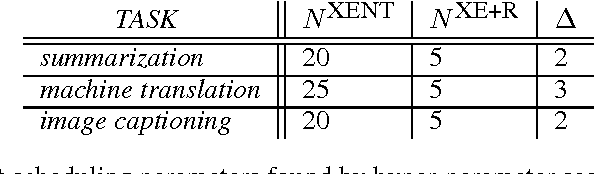
Many natural language processing applications use language models to generate text. These models are typically trained to predict the next word in a sequence, given the previous words and some context such as an image. However, at test time the model is expected to generate the entire sequence from scratch. This discrepancy makes generation brittle, as errors may accumulate along the way. We address this issue by proposing a novel sequence level training algorithm that directly optimizes the metric used at test time, such as BLEU or ROUGE. On three different tasks, our approach outperforms several strong baselines for greedy generation. The method is also competitive when these baselines employ beam search, while being several times faster.
Convolutional networks and learning invariant to homogeneous multiplicative scalings
Feb 16, 2016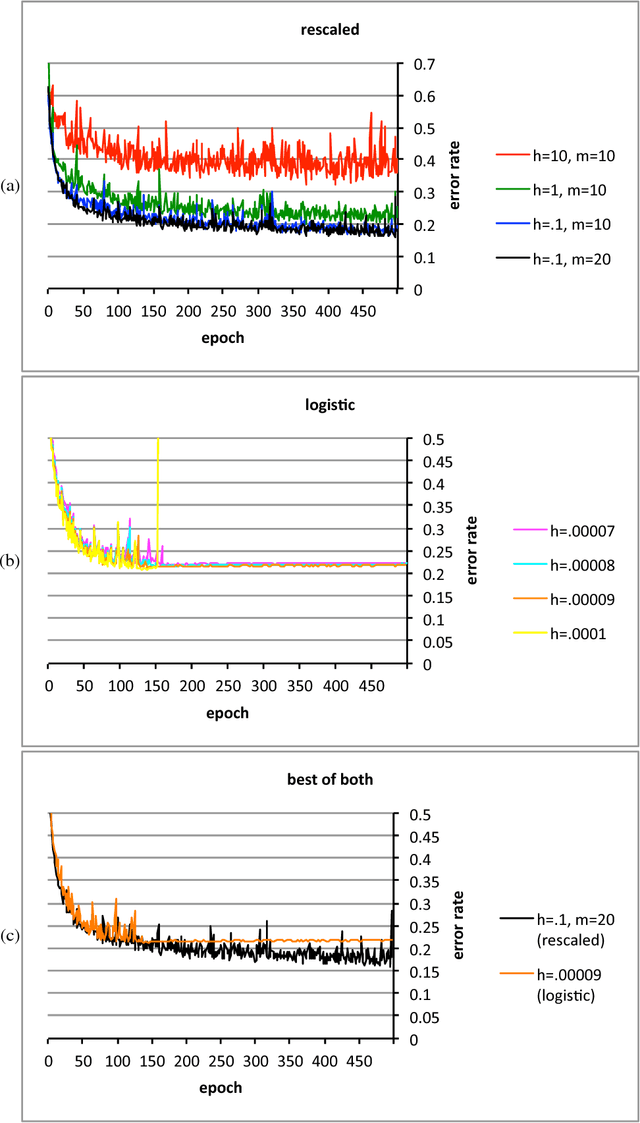
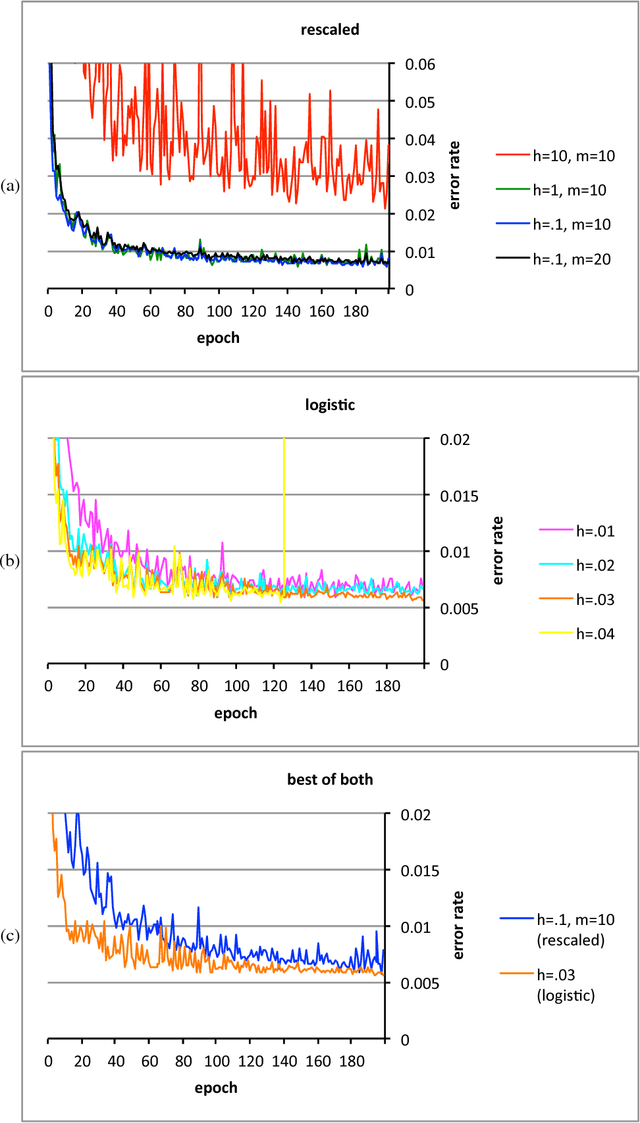
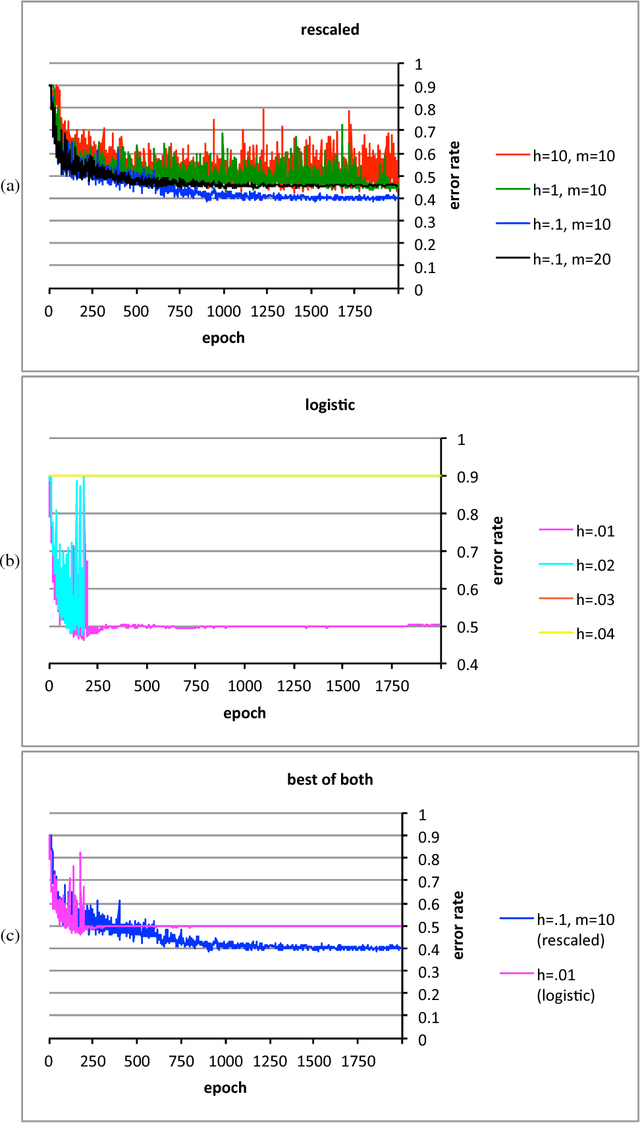
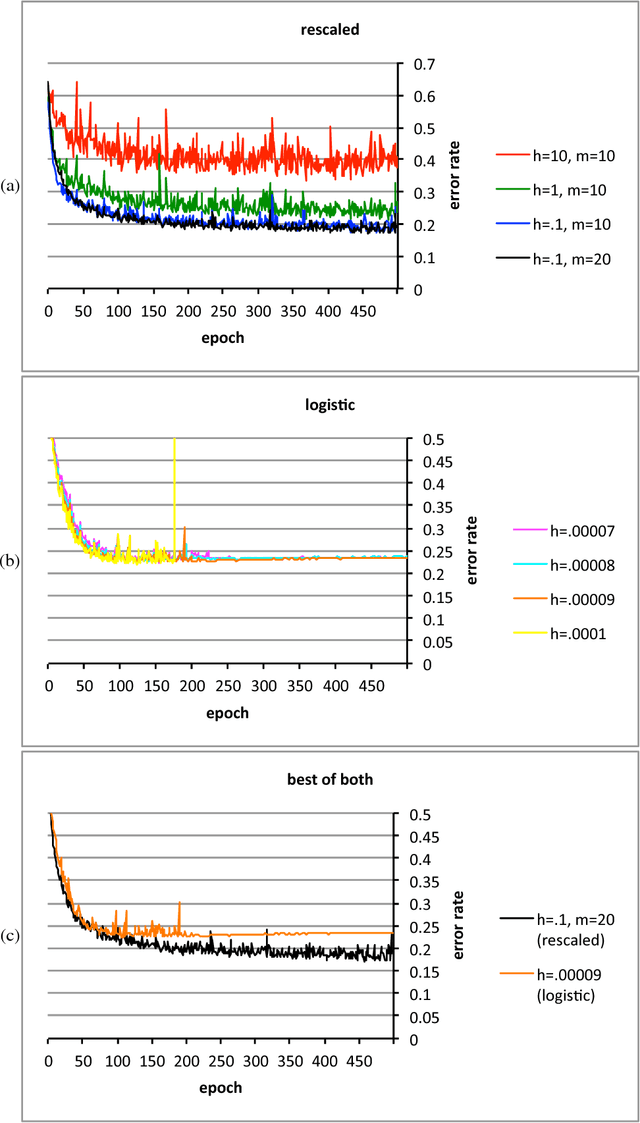
The conventional classification schemes -- notably multinomial logistic regression -- used in conjunction with convolutional networks (convnets) are classical in statistics, designed without consideration for the usual coupling with convnets, stochastic gradient descent, and backpropagation. In the specific application to supervised learning for convnets, a simple scale-invariant classification stage turns out to be more robust than multinomial logistic regression, appears to result in slightly lower errors on several standard test sets, has similar computational costs, and features precise control over the actual rate of learning. "Scale-invariant" means that multiplying the input values by any nonzero scalar leaves the output unchanged.
* 12 pages, 6 figures, 4 tables
Ensemble of Generative and Discriminative Techniques for Sentiment Analysis of Movie Reviews
May 27, 2015

Sentiment analysis is a common task in natural language processing that aims to detect polarity of a text document (typically a consumer review). In the simplest settings, we discriminate only between positive and negative sentiment, turning the task into a standard binary classification problem. We compare several ma- chine learning approaches to this problem, and combine them to achieve the best possible results. We show how to use for this task the standard generative lan- guage models, which are slightly complementary to the state of the art techniques. We achieve strong results on a well-known dataset of IMDB movie reviews. Our results are easily reproducible, as we publish also the code needed to repeat the experiments. This should simplify further advance of the state of the art, as other researchers can combine their techniques with ours with little effort.
Web-Scale Training for Face Identification
Apr 18, 2015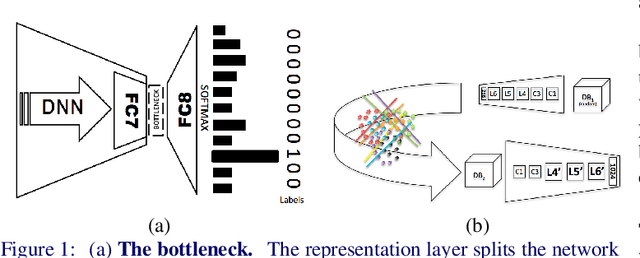
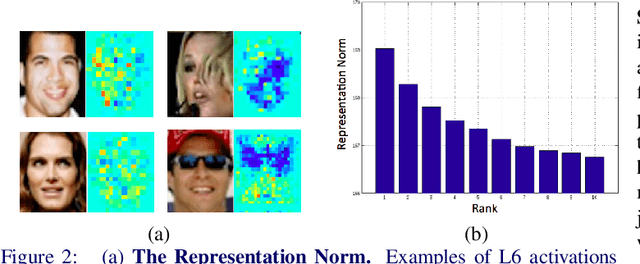
Scaling machine learning methods to very large datasets has attracted considerable attention in recent years, thanks to easy access to ubiquitous sensing and data from the web. We study face recognition and show that three distinct properties have surprising effects on the transferability of deep convolutional networks (CNN): (1) The bottleneck of the network serves as an important transfer learning regularizer, and (2) in contrast to the common wisdom, performance saturation may exist in CNN's (as the number of training samples grows); we propose a solution for alleviating this by replacing the naive random subsampling of the training set with a bootstrapping process. Moreover, (3) we find a link between the representation norm and the ability to discriminate in a target domain, which sheds lights on how such networks represent faces. Based on these discoveries, we are able to improve face recognition accuracy on the widely used LFW benchmark, both in the verification (1:1) and identification (1:N) protocols, and directly compare, for the first time, with the state of the art Commercially-Off-The-Shelf system and show a sizable leap in performance.
Learning Longer Memory in Recurrent Neural Networks
Apr 16, 2015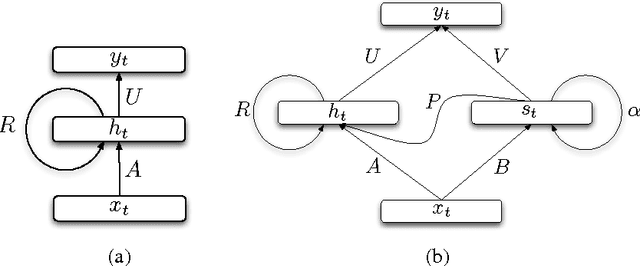
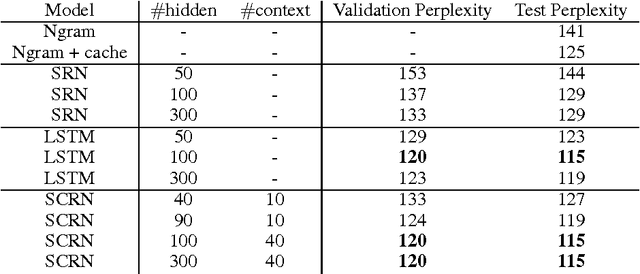
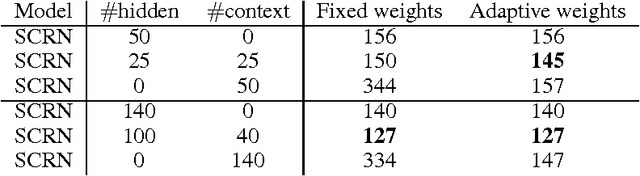
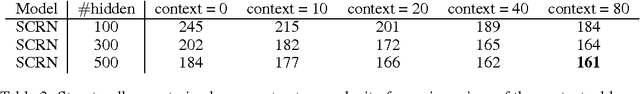
Recurrent neural network is a powerful model that learns temporal patterns in sequential data. For a long time, it was believed that recurrent networks are difficult to train using simple optimizers, such as stochastic gradient descent, due to the so-called vanishing gradient problem. In this paper, we show that learning longer term patterns in real data, such as in natural language, is perfectly possible using gradient descent. This is achieved by using a slight structural modification of the simple recurrent neural network architecture. We encourage some of the hidden units to change their state slowly by making part of the recurrent weight matrix close to identity, thus forming kind of a longer term memory. We evaluate our model in language modeling experiments, where we obtain similar performance to the much more complex Long Short Term Memory (LSTM) networks (Hochreiter & Schmidhuber, 1997).
Predicting Parameters in Deep Learning
Oct 27, 2014

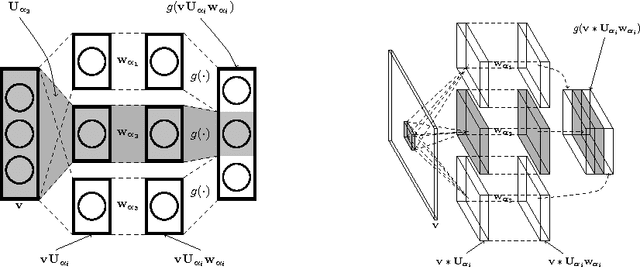
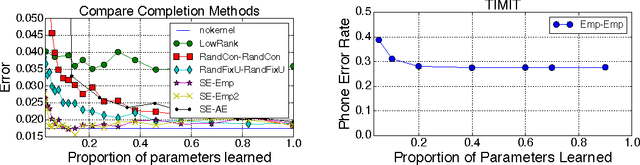
We demonstrate that there is significant redundancy in the parameterization of several deep learning models. Given only a few weight values for each feature it is possible to accurately predict the remaining values. Moreover, we show that not only can the parameter values be predicted, but many of them need not be learned at all. We train several different architectures by learning only a small number of weights and predicting the rest. In the best case we are able to predict more than 95% of the weights of a network without any drop in accuracy.
PANDA: Pose Aligned Networks for Deep Attribute Modeling
May 05, 2014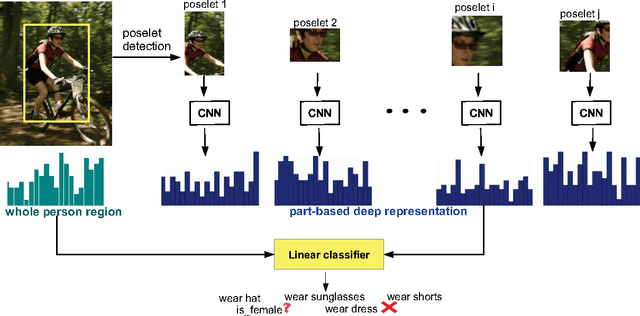



We propose a method for inferring human attributes (such as gender, hair style, clothes style, expression, action) from images of people under large variation of viewpoint, pose, appearance, articulation and occlusion. Convolutional Neural Nets (CNN) have been shown to perform very well on large scale object recognition problems. In the context of attribute classification, however, the signal is often subtle and it may cover only a small part of the image, while the image is dominated by the effects of pose and viewpoint. Discounting for pose variation would require training on very large labeled datasets which are not presently available. Part-based models, such as poselets and DPM have been shown to perform well for this problem but they are limited by shallow low-level features. We propose a new method which combines part-based models and deep learning by training pose-normalized CNNs. We show substantial improvement vs. state-of-the-art methods on challenging attribute classification tasks in unconstrained settings. Experiments confirm that our method outperforms both the best part-based methods on this problem and conventional CNNs trained on the full bounding box of the person.
On Learning Where To Look
Apr 24, 2014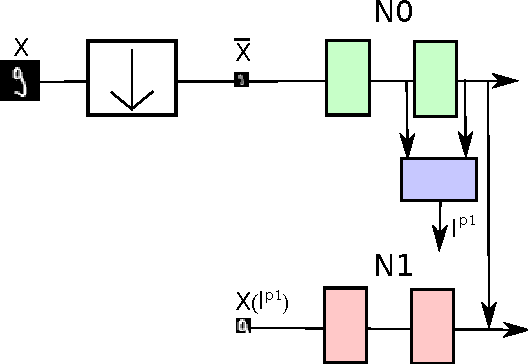


Current automatic vision systems face two major challenges: scalability and extreme variability of appearance. First, the computational time required to process an image typically scales linearly with the number of pixels in the image, therefore limiting the resolution of input images to thumbnail size. Second, variability in appearance and pose of the objects constitute a major hurdle for robust recognition and detection. In this work, we propose a model that makes baby steps towards addressing these challenges. We describe a learning based method that recognizes objects through a series of glimpses. This system performs an amount of computation that scales with the complexity of the input rather than its number of pixels. Moreover, the proposed method is potentially more robust to changes in appearance since its parameters are learned in a data driven manner. Preliminary experiments on a handwritten dataset of digits demonstrate the computational advantages of this approach.
Learning Factored Representations in a Deep Mixture of Experts
Mar 09, 2014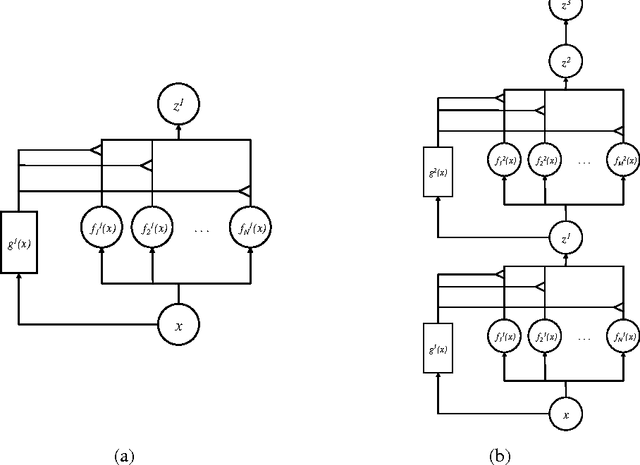
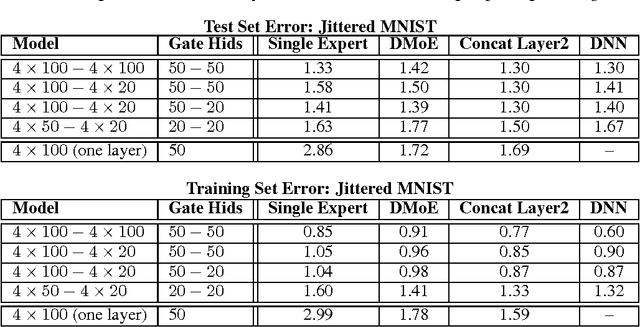
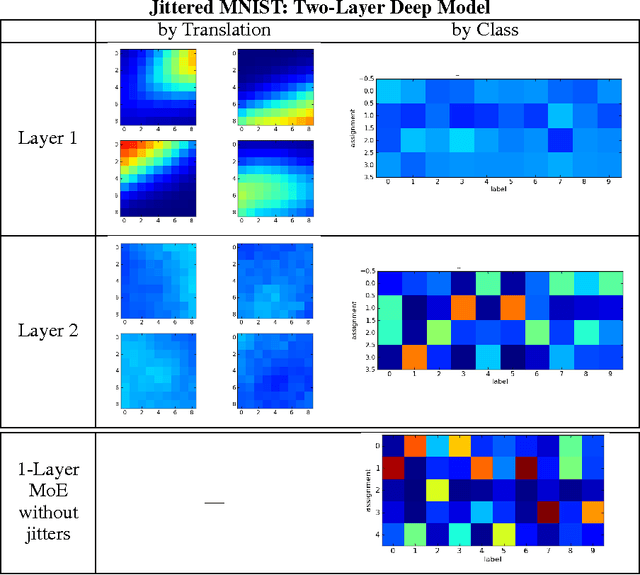
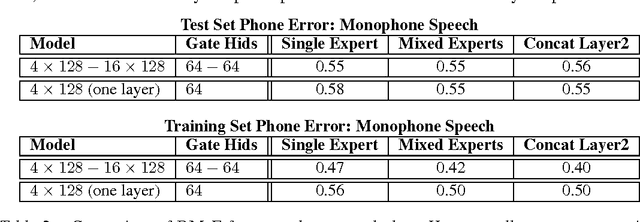
Mixtures of Experts combine the outputs of several "expert" networks, each of which specializes in a different part of the input space. This is achieved by training a "gating" network that maps each input to a distribution over the experts. Such models show promise for building larger networks that are still cheap to compute at test time, and more parallelizable at training time. In this this work, we extend the Mixture of Experts to a stacked model, the Deep Mixture of Experts, with multiple sets of gating and experts. This exponentially increases the number of effective experts by associating each input with a combination of experts at each layer, yet maintains a modest model size. On a randomly translated version of the MNIST dataset, we find that the Deep Mixture of Experts automatically learns to develop location-dependent ("where") experts at the first layer, and class-specific ("what") experts at the second layer. In addition, we see that the different combinations are in use when the model is applied to a dataset of speech monophones. These demonstrate effective use of all expert combinations.
Multi-GPU Training of ConvNets
Feb 18, 2014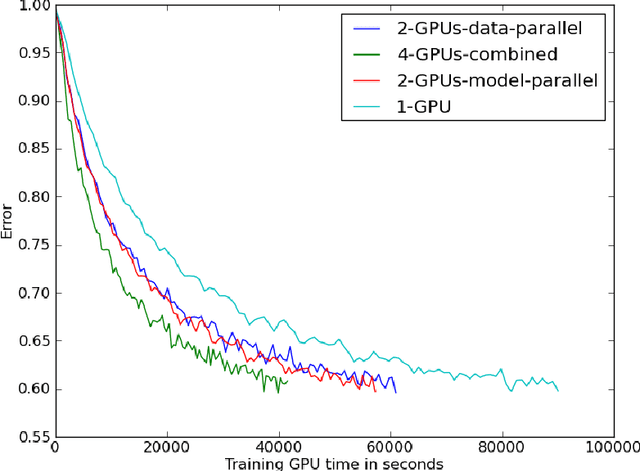
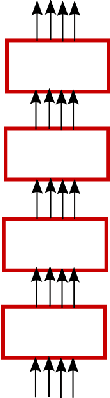
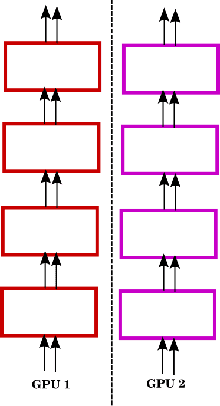
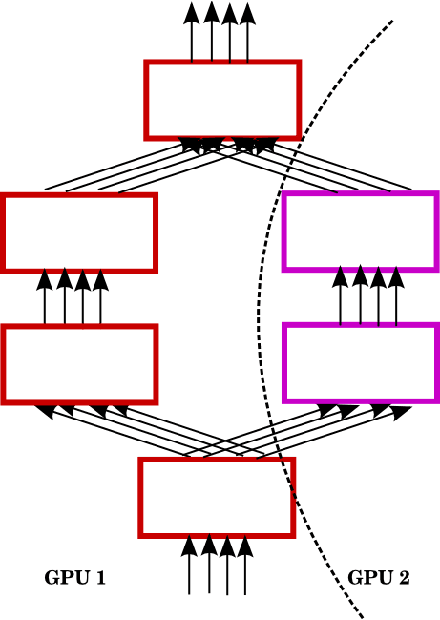
In this work we evaluate different approaches to parallelize computation of convolutional neural networks across several GPUs.