 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMarc Pollefeys
Self-Supervised Learning of Non-Rigid Residual Flow and Ego-Motion
Sep 22, 2020

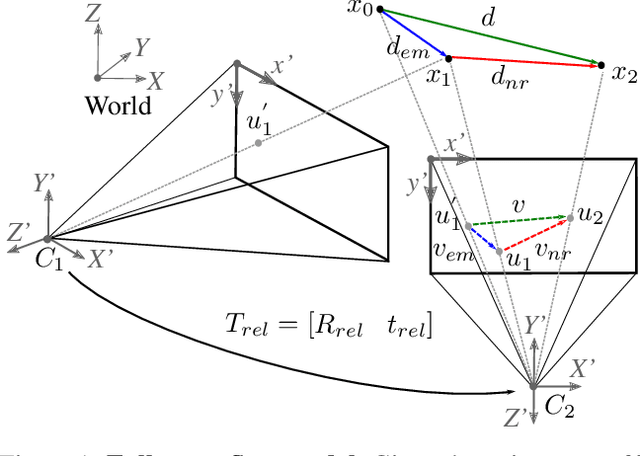
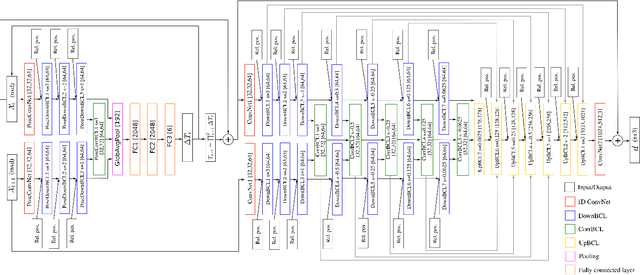
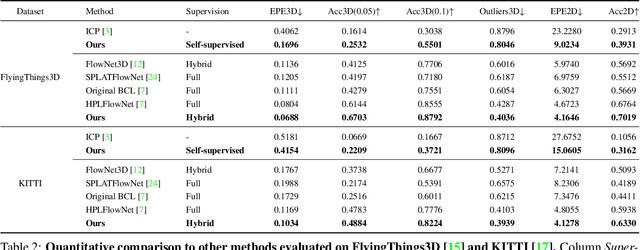
Most of the current scene flow methods choose to model scene flow as a per point translation vector without differentiating between static and dynamic components of 3D motion. In this work we present an alternative method for end-to-end scene flow learning by joint estimation of non-rigid residual flow and ego-motion flow for dynamic 3D scenes. We propose to learn the relative rigid transformation from a pair of point clouds followed by an iterative refinement. We then learn the non-rigid flow from transformed inputs with the deducted rigid part of the flow. Furthermore, we extend the supervised framework with self-supervisory signals based on the temporal consistency property of a point cloud sequence. Our solution allows both training in a supervised mode complemented by self-supervisory loss terms as well as training in a fully self-supervised mode. We demonstrate that decomposition of scene flow into non-rigid flow and ego-motion flow along with an introduction of the self-supervisory signals allowed us to outperform the current state-of-the-art supervised methods.
HoloLens 2 Research Mode as a Tool for Computer Vision Research
Aug 25, 2020
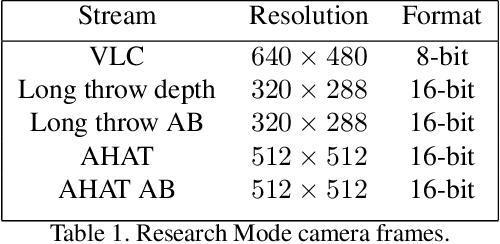


Mixed reality headsets, such as the Microsoft HoloLens 2, are powerful sensing devices with integrated compute capabilities, which makes it an ideal platform for computer vision research. In this technical report, we present HoloLens 2 Research Mode, an API and a set of tools enabling access to the raw sensor streams. We provide an overview of the API and explain how it can be used to build mixed reality applications based on processing sensor data. We also show how to combine the Research Mode sensor data with the built-in eye and hand tracking capabilities provided by HoloLens 2. By releasing the Research Mode API and a set of open-source tools, we aim to foster further research in the fields of computer vision as well as robotics and encourage contributions from the research community.
LIC-Fusion 2.0: LiDAR-Inertial-Camera Odometry with Sliding-Window Plane-Feature Tracking
Aug 17, 2020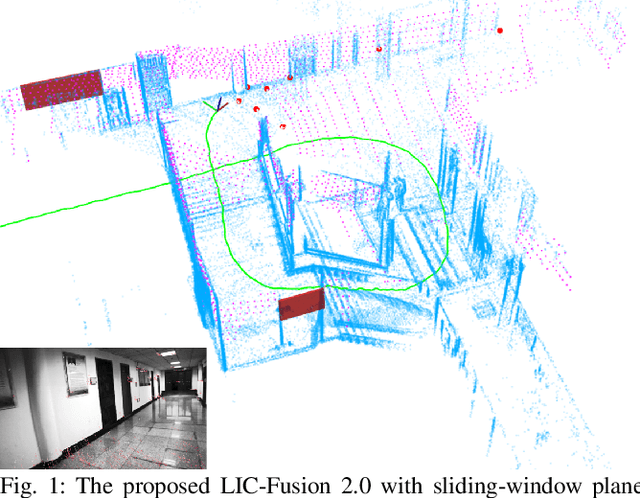
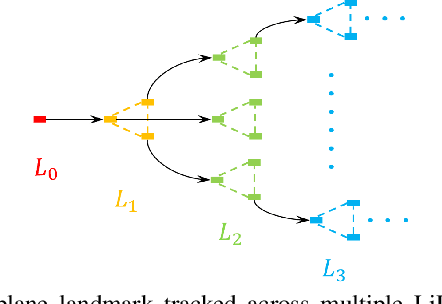


Multi-sensor fusion of multi-modal measurements from commodity inertial, visual and LiDAR sensors to provide robust and accurate 6DOF pose estimation holds great potential in robotics and beyond. In this paper, building upon our prior work (i.e., LIC-Fusion), we develop a sliding-window filter based LiDAR-Inertial-Camera odometry with online spatiotemporal calibration (i.e., LIC-Fusion 2.0), which introduces a novel sliding-window plane-feature tracking for efficiently processing 3D LiDAR point clouds. In particular, after motion compensation for LiDAR points by leveraging IMU data, low-curvature planar points are extracted and tracked across the sliding window. A novel outlier rejection criterion is proposed in the plane-feature tracking for high-quality data association. Only the tracked planar points belonging to the same plane will be used for plane initialization, which makes the plane extraction efficient and robust. Moreover, we perform the observability analysis for the LiDAR-IMU subsystem and report the degenerate cases for spatiotemporal calibration using plane features. While the estimation consistency and identified degenerate motions are validated in Monte-Carlo simulations, different real-world experiments are also conducted to show that the proposed LIC-Fusion 2.0 outperforms its predecessor and other state-of-the-art methods.
KAPLAN: A 3D Point Descriptor for Shape Completion
Jul 31, 2020



We present a novel 3D shape completion method that operates directly on unstructured point clouds, thus avoiding resource-intensive data structures like voxel grids. To this end, we introduce KAPLAN, a 3D point descriptor that aggregates local shape information via a series of 2D convolutions. The key idea is to project the points in a local neighborhood onto multiple planes with different orientations. In each of those planes, point properties like normals or point-to-plane distances are aggregated into a 2D grid and abstracted into a feature representation with an efficient 2D convolutional encoder. Since all planes are encoded jointly, the resulting representation nevertheless can capture their correlations and retains knowledge about the underlying 3D shape, without expensive 3D convolutions. Experiments on public datasets show that KAPLAN achieves state-of-the-art performance for 3D shape completion.
Infrastructure-based Multi-Camera Calibration using Radial Projections
Jul 30, 2020
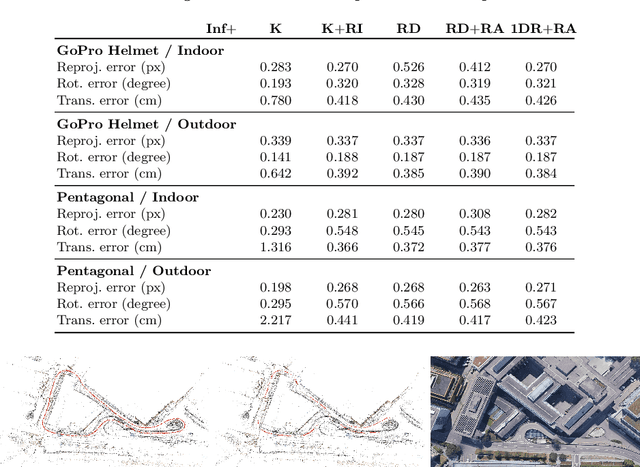
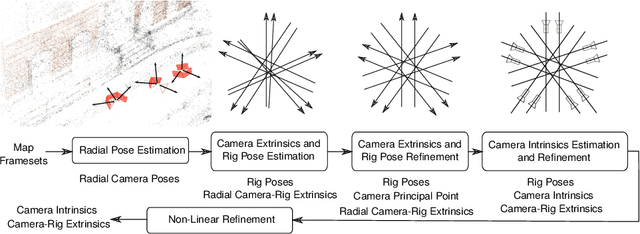

Multi-camera systems are an important sensor platform for intelligent systems such as self-driving cars. Pattern-based calibration techniques can be used to calibrate the intrinsics of the cameras individually. However, extrinsic calibration of systems with little to no visual overlap between the cameras is a challenge. Given the camera intrinsics, infrastucture-based calibration techniques are able to estimate the extrinsics using 3D maps pre-built via SLAM or Structure-from-Motion. In this paper, we propose to fully calibrate a multi-camera system from scratch using an infrastructure-based approach. Assuming that the distortion is mainly radial, we introduce a two-stage approach. We first estimate the camera-rig extrinsics up to a single unknown translation component per camera. Next, we solve for both the intrinsic parameters and the missing translation components. Extensive experiments on multiple indoor and outdoor scenes with multiple multi-camera systems show that our calibration method achieves high accuracy and robustness. In particular, our approach is more robust than the naive approach of first estimating intrinsic parameters and pose per camera before refining the extrinsic parameters of the system. The implementation is available at https://github.com/youkely/InfrasCal.
Online Invariance Selection for Local Feature Descriptors
Jul 23, 2020
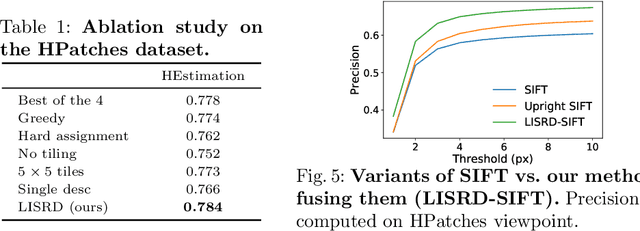
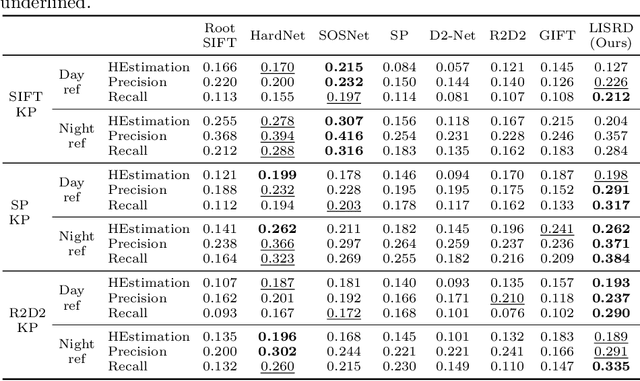
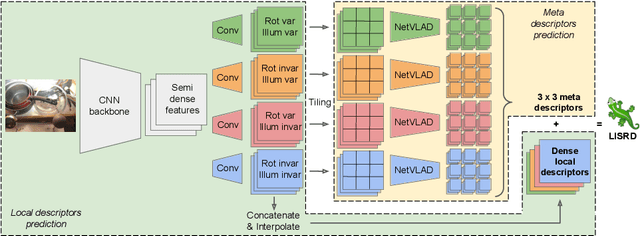
To be invariant, or not to be invariant: that is the question formulated in this work about local descriptors. A limitation of current feature descriptors is the trade-off between generalization and discriminative power: more invariance means less informative descriptors. We propose to overcome this limitation with a disentanglement of invariance in local descriptors and with an online selection of the most appropriate invariance given the context. Our framework consists in a joint learning of multiple local descriptors with different levels of invariance and of meta descriptors encoding the regional variations of an image. The similarity of these meta descriptors across images is used to select the right invariance when matching the local descriptors. Our approach, named Local Invariance Selection at Runtime for Descriptors (LISRD), enables descriptors to adapt to adverse changes in images, while remaining discriminative when invariance is not required. We demonstrate that our method can boost the performance of current descriptors and outperforms state-of-the-art descriptors in several matching tasks, when evaluated on challenging datasets with day-night illumination as well as viewpoint changes.
Privacy-Preserving Visual Feature Descriptors through Adversarial Affine Subspace Embedding
Jun 11, 2020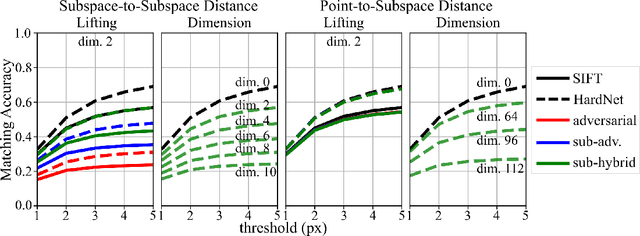

Many computer vision systems require users to upload image features to the cloud for processing and storage. Such features can be exploited to recover sensitive information about the scene or subjects, e.g., by reconstructing the appearance of the original image. To address this privacy concern, we propose a new privacy-preserving feature representation. The core idea of our work is to drop constraints from each feature descriptor by embedding it within an affine subspace containing the original feature as well as one or more adversarial feature samples. Feature matching on the privacy-preserving representation is enabled based on the notion of subspace-to-subspace distance. We experimentally demonstrate the effectiveness of our method and its high practical relevance for applications such as crowd-sourced 3D scene reconstruction and face authentication. Compared to the original features, our approach has only marginal impact on performance but makes it significantly more difficult for an adversary to recover private information.
AdaLAM: Revisiting Handcrafted Outlier Detection
Jun 07, 2020

Local feature matching is a critical component of many computer vision pipelines, including among others Structure-from-Motion, SLAM, and Visual Localization. However, due to limitations in the descriptors, raw matches are often contaminated by a majority of outliers. As a result, outlier detection is a fundamental problem in computer vision, and a wide range of approaches have been proposed over the last decades. In this paper we revisit handcrafted approaches to outlier filtering. Based on best practices, we propose a hierarchical pipeline for effective outlier detection as well as integrate novel ideas which in sum lead to AdaLAM, an efficient and competitive approach to outlier rejection. AdaLAM is designed to effectively exploit modern parallel hardware, resulting in a very fast, yet very accurate, outlier filter. We validate AdaLAM on multiple large and diverse datasets, and we submit to the Image Matching Challenge (CVPR2020), obtaining competitive results with simple baseline descriptors. We show that AdaLAM is more than competitive to current state of the art, both in terms of efficiency and effectiveness.