 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActually Sparse Variational Gaussian Processes
Apr 11, 2023



Gaussian processes (GPs) are typically criticised for their unfavourable scaling in both computational and memory requirements. For large datasets, sparse GPs reduce these demands by conditioning on a small set of inducing variables designed to summarise the data. In practice however, for large datasets requiring many inducing variables, such as low-lengthscale spatial data, even sparse GPs can become computationally expensive, limited by the number of inducing variables one can use. In this work, we propose a new class of inter-domain variational GP, constructed by projecting a GP onto a set of compactly supported B-spline basis functions. The key benefit of our approach is that the compact support of the B-spline basis functions admits the use of sparse linear algebra to significantly speed up matrix operations and drastically reduce the memory footprint. This allows us to very efficiently model fast-varying spatial phenomena with tens of thousands of inducing variables, where previous approaches failed.
Queer In AI: A Case Study in Community-Led Participatory AI
Apr 10, 2023We present Queer in AI as a case study for community-led participatory design in AI. We examine how participatory design and intersectional tenets started and shaped this community's programs over the years. We discuss different challenges that emerged in the process, look at ways this organization has fallen short of operationalizing participatory and intersectional principles, and then assess the organization's impact. Queer in AI provides important lessons and insights for practitioners and theorists of participatory methods broadly through its rejection of hierarchy in favor of decentralization, success at building aid and programs by and for the queer community, and effort to change actors and institutions outside of the queer community. Finally, we theorize how communities like Queer in AI contribute to the participatory design in AI more broadly by fostering cultures of participation in AI, welcoming and empowering marginalized participants, critiquing poor or exploitative participatory practices, and bringing participation to institutions outside of individual research projects. Queer in AI's work serves as a case study of grassroots activism and participatory methods within AI, demonstrating the potential of community-led participatory methods and intersectional praxis, while also providing challenges, case studies, and nuanced insights to researchers developing and using participatory methods.
Finetuning from Offline Reinforcement Learning: Challenges, Trade-offs and Practical Solutions
Mar 30, 2023



Offline reinforcement learning (RL) allows for the training of competent agents from offline datasets without any interaction with the environment. Online finetuning of such offline models can further improve performance. But how should we ideally finetune agents obtained from offline RL training? While offline RL algorithms can in principle be used for finetuning, in practice, their online performance improves slowly. In contrast, we show that it is possible to use standard online off-policy algorithms for faster improvement. However, we find this approach may suffer from policy collapse, where the policy undergoes severe performance deterioration during initial online learning. We investigate the issue of policy collapse and how it relates to data diversity, algorithm choices and online replay distribution. Based on these insights, we propose a conservative policy optimization procedure that can achieve stable and sample-efficient online learning from offline pretraining.
Optimal Transport for Offline Imitation Learning
Mar 24, 2023



With the advent of large datasets, offline reinforcement learning (RL) is a promising framework for learning good decision-making policies without the need to interact with the real environment. However, offline RL requires the dataset to be reward-annotated, which presents practical challenges when reward engineering is difficult or when obtaining reward annotations is labor-intensive. In this paper, we introduce Optimal Transport Reward labeling (OTR), an algorithm that assigns rewards to offline trajectories, with a few high-quality demonstrations. OTR's key idea is to use optimal transport to compute an optimal alignment between an unlabeled trajectory in the dataset and an expert demonstration to obtain a similarity measure that can be interpreted as a reward, which can then be used by an offline RL algorithm to learn the policy. OTR is easy to implement and computationally efficient. On D4RL benchmarks, we show that OTR with a single demonstration can consistently match the performance of offline RL with ground-truth rewards.
Short-term Prediction and Filtering of Solar Power Using State-Space Gaussian Processes
Feb 01, 2023Short-term forecasting of solar photovoltaic energy (PV) production is important for powerplant management. Ideally these forecasts are equipped with error bars, so that downstream decisions can account for uncertainty. To produce predictions with error bars in this setting, we consider Gaussian processes (GPs) for modelling and predicting solar photovoltaic energy production in the UK. A standard application of GP regression on the PV timeseries data is infeasible due to the large data size and non-Gaussianity of PV readings. However, this is made possible by leveraging recent advances in scalable GP inference, in particular, by using the state-space form of GPs, combined with modern variational inference techniques. The resulting model is not only scalable to large datasets but can also handle continuous data streams via Kalman filtering.
One-Shot Transfer of Affordance Regions? AffCorrs!
Sep 16, 2022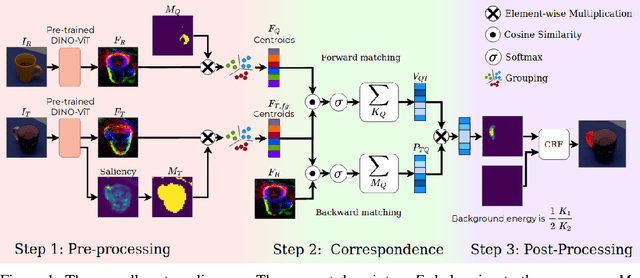
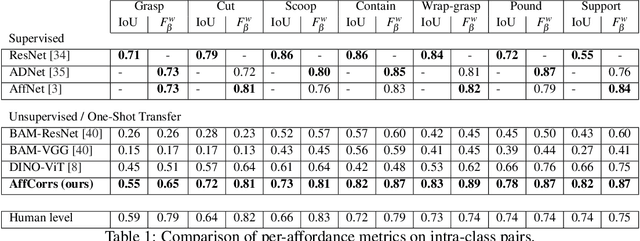


In this work, we tackle one-shot visual search of object parts. Given a single reference image of an object with annotated affordance regions, we segment semantically corresponding parts within a target scene. We propose AffCorrs, an unsupervised model that combines the properties of pre-trained DINO-ViT's image descriptors and cyclic correspondences. We use AffCorrs to find corresponding affordances both for intra- and inter-class one-shot part segmentation. This task is more difficult than supervised alternatives, but enables future work such as learning affordances via imitation and assisted teleoperation.
Bayesian Optimization-based Nonlinear Adaptive PID Controller Design for Robust Mobile Manipulation
Jul 04, 2022
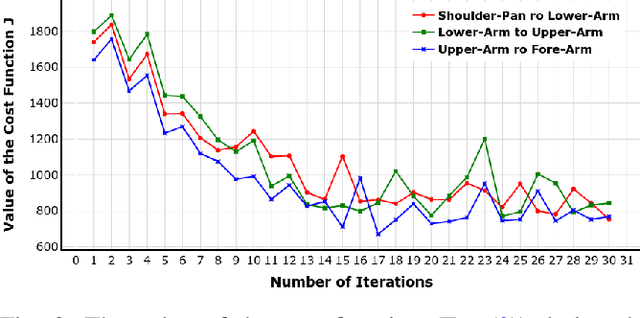
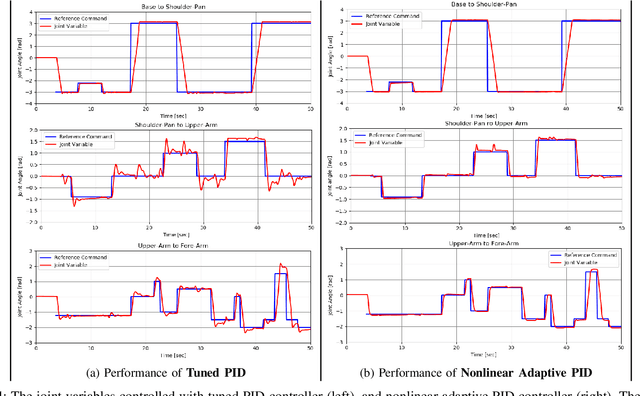
In this paper, we propose to use a nonlinear adaptive PID controller to regulate the joint variables of a mobile manipulator. The motion of the mobile base forces undue disturbances on the joint controllers of the manipulator. In designing a conventional PID controller, one should make a trade-off between the performance and agility of the closed-loop system and its stability margins. The proposed nonlinear adaptive PID controller provides a mechanism to relax the need for such a compromise by adapting the gains according to the magnitude of the error without expert tuning. Therefore, we can achieve agile performance for the system while seeing damped overshoot in the output and track the reference as close as possible, even in the presence of external disturbances and uncertainties in the modeling of the system. We have employed a Bayesian optimization approach to choose the parameters of a nonlinear adaptive PID controller to achieve the best performance in tracking the reference input and rejecting disturbances. The results demonstrate that a well-designed nonlinear adaptive PID controller can effectively regulate a mobile manipulator's joint variables while carrying an unspecified heavy load and an abrupt base movement occurs.
Vector-valued Gaussian Processes on Riemannian Manifolds via Gauge Independent Projected Kernels
Nov 25, 2021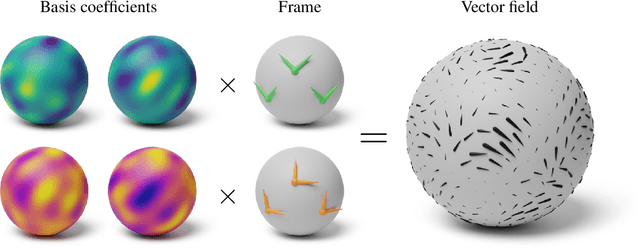


Gaussian processes are machine learning models capable of learning unknown functions in a way that represents uncertainty, thereby facilitating construction of optimal decision-making systems. Motivated by a desire to deploy Gaussian processes in novel areas of science, a rapidly-growing line of research has focused on constructively extending these models to handle non-Euclidean domains, including Riemannian manifolds, such as spheres and tori. We propose techniques that generalize this class to model vector fields on Riemannian manifolds, which are important in a number of application areas in the physical sciences. To do so, we present a general recipe for constructing gauge independent kernels, which induce Gaussian vector fields, i.e. vector-valued Gaussian processes coherent with geometry, from scalar-valued Riemannian kernels. We extend standard Gaussian process training methods, such as variational inference, to this setting. This enables vector-valued Gaussian processes on Riemannian manifolds to be trained using standard methods and makes them accessible to machine learning practitioners.
Gaussian Process Sampling and Optimization with Approximate Upper and Lower Bounds
Oct 22, 2021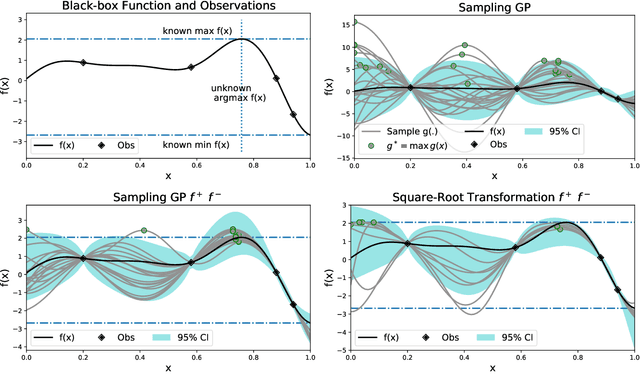
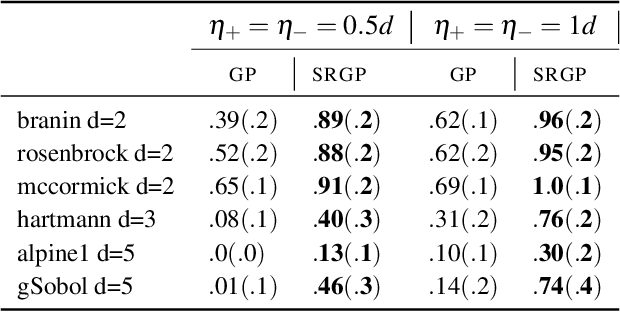
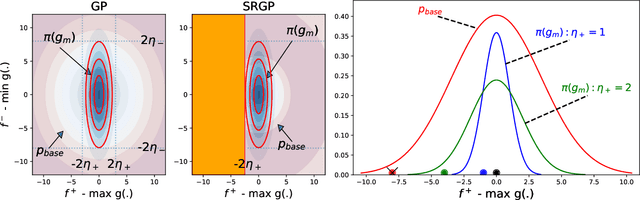
Many functions have approximately-known upper and/or lower bounds, potentially aiding the modeling of such functions. In this paper, we introduce Gaussian process models for functions where such bounds are (approximately) known. More specifically, we propose the first use of such bounds to improve Gaussian process (GP) posterior sampling and Bayesian optimization (BO). That is, we transform a GP model satisfying the given bounds, and then sample and weight functions from its posterior. To further exploit these bounds in BO settings, we present bounded entropy search (BES) to select the point gaining the most information about the underlying function, estimated by the GP samples, while satisfying the output constraints. We characterize the sample variance bounds and show that the decision made by BES is explainable. Our proposed approach is conceptually straightforward and can be used as a plug in extension to existing methods for GP posterior sampling and Bayesian optimization.
Learning to Transfer: A Foliated Theory
Jul 22, 2021
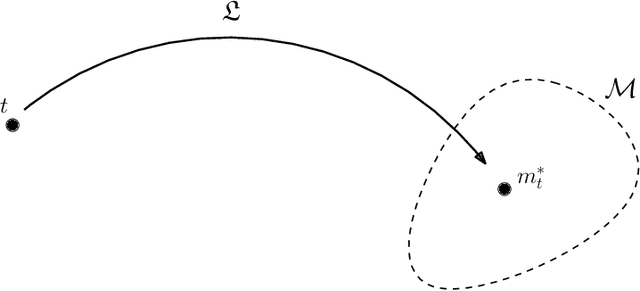
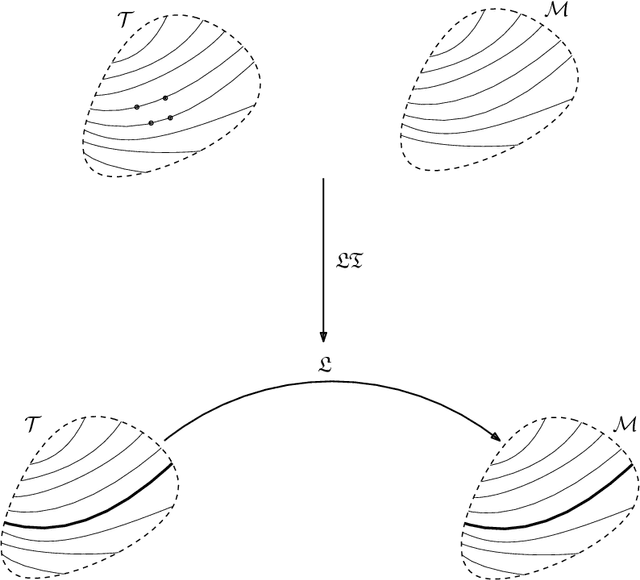
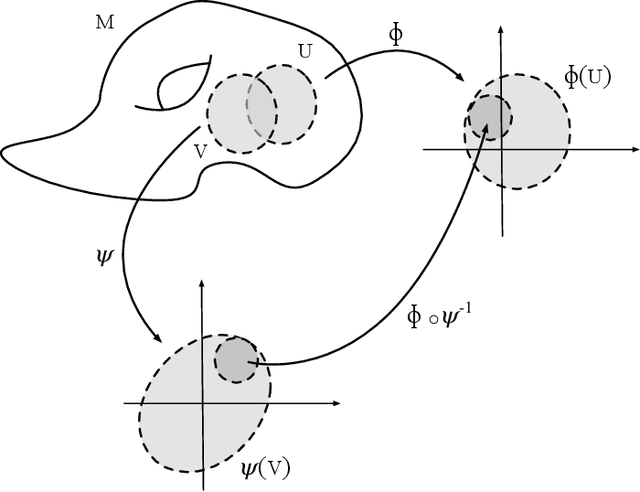
Learning to transfer considers learning solutions to tasks in a such way that relevant knowledge can be transferred from known task solutions to new, related tasks. This is important for general learning, as well as for improving the efficiency of the learning process. While techniques for learning to transfer have been studied experimentally, we still lack a foundational description of the problem that exposes what related tasks are, and how relationships between tasks can be exploited constructively. In this work, we introduce a framework using the differential geometric theory of foliations that provides such a foundation.