 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSOMA: From Surface Observations to Muscle Anatomy
Jun 08, 2026With the growing demand for realistic virtual humans, parametric body models have become a cornerstone of modern medicine, sports, and entertainment applications. However, most of these models are inherently limited: they only capture the 3D surface of the skin, offering no insight into the complex bio-mechanical structures that generate motion. As more applications expand towards biomechanics, the need for virtual human models that go beyond the skin has become increasingly evident. Traditional soft-tissue simulations, such as FEM, are accurate but non-scalable and too computationally expensive for most common applications. Alternatively, existing biomechanical tools can simulate muscular forces and activations, but do not model changes in external shape, restricting how activations correlate with actual observable anatomy. This motivates a novel inverse research problem: recovering muscle deformations directly from visible surface observations - i.e., from the skin, and thus the pose. In this work, we present SOMA (from Surface Observations to Muscle Anatomy), a person-specific model that infers spatio-temporal muscle behavior from surface signals obtained using RGB cameras, and SKIM, a subject-specific soft-tissue deformation dataset. To the best of our knowledge, this is the first method that attempts to recover muscle deformations from multi-view RGB data. We show how our method provides anatomically grounded animations without the complexity of traditional simulations, leading to a scalable and cost-effective solution. Data and code are available.
Step2Motion: Locomotion Reconstruction from Pressure Sensing Insoles
Oct 26, 2025Human motion is fundamentally driven by continuous physical interaction with the environment. Whether walking, running, or simply standing, the forces exchanged between our feet and the ground provide crucial insights for understanding and reconstructing human movement. Recent advances in wearable insole devices offer a compelling solution for capturing these forces in diverse, real-world scenarios. Sensor insoles pose no constraint on the users' motion (unlike mocap suits) and are unaffected by line-of-sight limitations (in contrast to optical systems). These qualities make sensor insoles an ideal choice for robust, unconstrained motion capture, particularly in outdoor environments. Surprisingly, leveraging these devices with recent motion reconstruction methods remains largely unexplored. Aiming to fill this gap, we present Step2Motion, the first approach to reconstruct human locomotion from multi-modal insole sensors. Our method utilizes pressure and inertial data-accelerations and angular rates-captured by the insoles to reconstruct human motion. We evaluate the effectiveness of our approach across a range of experiments to show its versatility for diverse locomotion styles, from simple ones like walking or jogging up to moving sideways, on tiptoes, slightly crouching, or dancing.
FRAME: Floor-aligned Representation for Avatar Motion from Egocentric Video
Mar 29, 2025



Egocentric motion capture with a head-mounted body-facing stereo camera is crucial for VR and AR applications but presents significant challenges such as heavy occlusions and limited annotated real-world data. Existing methods rely on synthetic pretraining and struggle to generate smooth and accurate predictions in real-world settings, particularly for lower limbs. Our work addresses these limitations by introducing a lightweight VR-based data collection setup with on-board, real-time 6D pose tracking. Using this setup, we collected the most extensive real-world dataset for ego-facing ego-mounted cameras to date in size and motion variability. Effectively integrating this multimodal input -- device pose and camera feeds -- is challenging due to the differing characteristics of each data source. To address this, we propose FRAME, a simple yet effective architecture that combines device pose and camera feeds for state-of-the-art body pose prediction through geometrically sound multimodal integration and can run at 300 FPS on modern hardware. Lastly, we showcase a novel training strategy to enhance the model's generalization capabilities. Our approach exploits the problem's geometric properties, yielding high-quality motion capture free from common artifacts in prior works. Qualitative and quantitative evaluations, along with extensive comparisons, demonstrate the effectiveness of our method. Data, code, and CAD designs will be available at https://vcai.mpi-inf.mpg.de/projects/FRAME/
BimArt: A Unified Approach for the Synthesis of 3D Bimanual Interaction with Articulated Objects
Dec 06, 2024



We present BimArt, a novel generative approach for synthesizing 3D bimanual hand interactions with articulated objects. Unlike prior works, we do not rely on a reference grasp, a coarse hand trajectory, or separate modes for grasping and articulating. To achieve this, we first generate distance-based contact maps conditioned on the object trajectory with an articulation-aware feature representation, revealing rich bimanual patterns for manipulation. The learned contact prior is then used to guide our hand motion generator, producing diverse and realistic bimanual motions for object movement and articulation. Our work offers key insights into feature representation and contact prior for articulated objects, demonstrating their effectiveness in taming the complex, high-dimensional space of bimanual hand-object interactions. Through comprehensive quantitative experiments, we demonstrate a clear step towards simplified and high-quality hand-object animations that excel over the state-of-the-art in motion quality and diversity.
A Survey on Reinforcement Learning Methods in Character Animation
Mar 07, 2022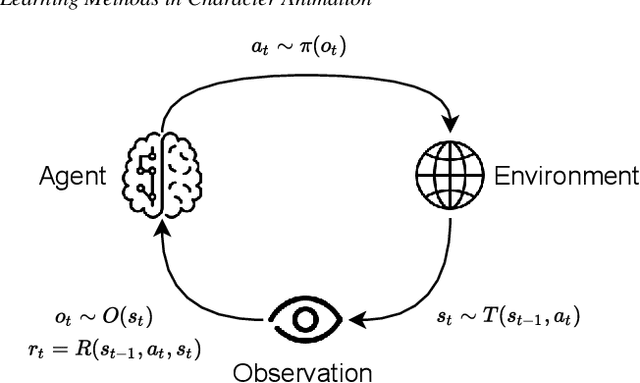
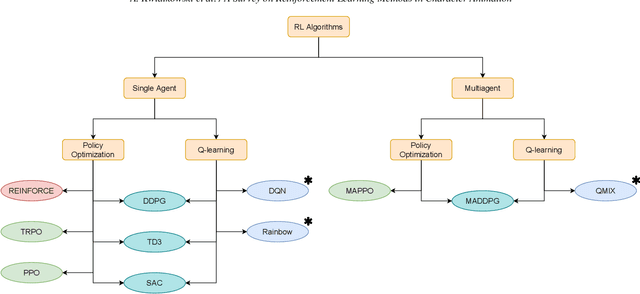
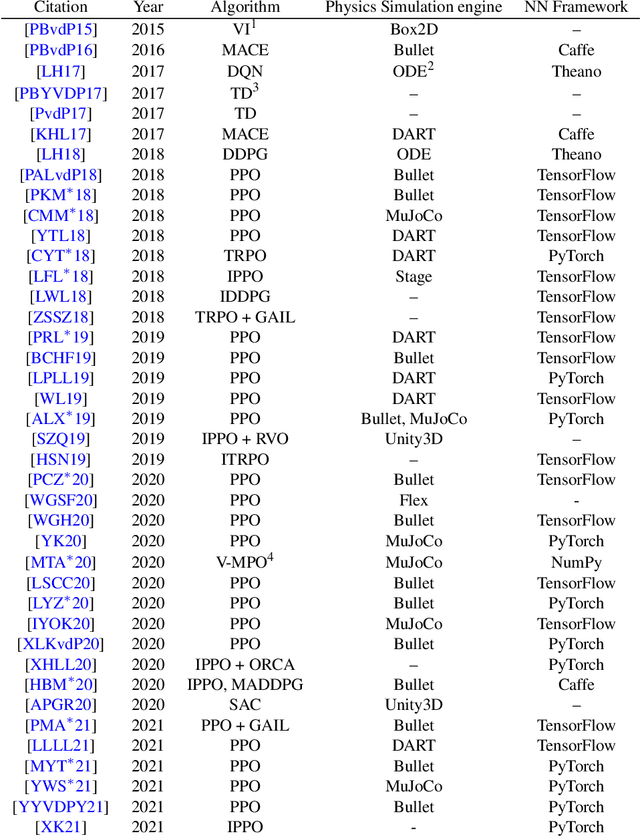
Reinforcement Learning is an area of Machine Learning focused on how agents can be trained to make sequential decisions, and achieve a particular goal within an arbitrary environment. While learning, they repeatedly take actions based on their observation of the environment, and receive appropriate rewards which define the objective. This experience is then used to progressively improve the policy controlling the agent's behavior, typically represented by a neural network. This trained module can then be reused for similar problems, which makes this approach promising for the animation of autonomous, yet reactive characters in simulators, video games or virtual reality environments. This paper surveys the modern Deep Reinforcement Learning methods and discusses their possible applications in Character Animation, from skeletal control of a single, physically-based character to navigation controllers for individual agents and virtual crowds. It also describes the practical side of training DRL systems, comparing the different frameworks available to build such agents.