 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified Source-Free Domain Adaptation
Mar 12, 2024In the pursuit of transferring a source model to a target domain without access to the source training data, Source-Free Domain Adaptation (SFDA) has been extensively explored across various scenarios, including closed-set, open-set, partial-set, and generalized settings. Existing methods, focusing on specific scenarios, not only address only a subset of challenges but also necessitate prior knowledge of the target domain, significantly limiting their practical utility and deployability. In light of these considerations, we introduce a more practical yet challenging problem, termed unified SFDA, which comprehensively incorporates all specific scenarios in a unified manner. To tackle this unified SFDA problem, we propose a novel approach called Latent Causal Factors Discovery (LCFD). In contrast to previous alternatives that emphasize learning the statistical description of reality, we formulate LCFD from a causality perspective. The objective is to uncover the causal relationships between latent variables and model decisions, enhancing the reliability and robustness of the learned model against domain shifts. To integrate extensive world knowledge, we leverage a pre-trained vision-language model such as CLIP. This aids in the formation and discovery of latent causal factors in the absence of supervision in the variation of distribution and semantics, coupled with a newly designed information bottleneck with theoretical guarantees. Extensive experiments demonstrate that LCFD can achieve new state-of-the-art results in distinct SFDA settings, as well as source-free out-of-distribution generalization.Our code and data are available at https://github.com/tntek/source-free-domain-adaptation.
Source-Free Domain Adaptation with Frozen Multimodal Foundation Model
Nov 27, 2023



Source-Free Domain Adaptation (SFDA) aims to adapt a source model for a target domain, with only access to unlabeled target training data and the source model pre-trained on a supervised source domain. Relying on pseudo labeling and/or auxiliary supervision, conventional methods are inevitably error-prone. To mitigate this limitation, in this work we for the first time explore the potentials of off-the-shelf vision-language (ViL) multimodal models (e.g.,CLIP) with rich whilst heterogeneous knowledge. We find that directly applying the ViL model to the target domain in a zero-shot fashion is unsatisfactory, as it is not specialized for this particular task but largely generic. To make it task specific, we propose a novel Distilling multimodal Foundation model(DIFO)approach. Specifically, DIFO alternates between two steps during adaptation: (i) Customizing the ViL model by maximizing the mutual information with the target model in a prompt learning manner, (ii) Distilling the knowledge of this customized ViL model to the target model. For more fine-grained and reliable distillation, we further introduce two effective regularization terms, namely most-likely category encouragement and predictive consistency. Extensive experiments show that DIFO significantly outperforms the state-of-the-art alternatives. Our source code will be released.
Spatial-Temporal Transformer based Video Compression Framework
Sep 21, 2023Learned video compression (LVC) has witnessed remarkable advancements in recent years. Similar as the traditional video coding, LVC inherits motion estimation/compensation, residual coding and other modules, all of which are implemented with neural networks (NNs). However, within the framework of NNs and its training mechanism using gradient backpropagation, most existing works often struggle to consistently generate stable motion information, which is in the form of geometric features, from the input color features. Moreover, the modules such as the inter-prediction and residual coding are independent from each other, making it inefficient to fully reduce the spatial-temporal redundancy. To address the above problems, in this paper, we propose a novel Spatial-Temporal Transformer based Video Compression (STT-VC) framework. It contains a Relaxed Deformable Transformer (RDT) with Uformer based offsets estimation for motion estimation and compensation, a Multi-Granularity Prediction (MGP) module based on multi-reference frames for prediction refinement, and a Spatial Feature Distribution prior based Transformer (SFD-T) for efficient temporal-spatial joint residual compression. Specifically, RDT is developed to stably estimate the motion information between frames by thoroughly investigating the relationship between the similarity based geometric motion feature extraction and self-attention. MGP is designed to fuse the multi-reference frame information by effectively exploring the coarse-grained prediction feature generated with the coded motion information. SFD-T is to compress the residual information by jointly exploring the spatial feature distributions in both residual and temporal prediction to further reduce the spatial-temporal redundancy. Experimental results demonstrate that our method achieves the best result with 13.5% BD-Rate saving over VTM.
MSMix:An Interpolation-Based Text Data Augmentation Method Manifold Swap Mixup
May 31, 2023



To solve the problem of poor performance of deep neural network models due to insufficient data, a simple yet effective interpolation-based data augmentation method is proposed: MSMix (Manifold Swap Mixup). This method feeds two different samples to the same deep neural network model, and then randomly select a specific layer and partially replace hidden features at that layer of one of the samples by the counterpart of the other. The mixed hidden features are fed to the model and go through the rest of the network. Two different selection strategies are also proposed to obtain richer hidden representation. Experiments are conducted on three Chinese intention recognition datasets, and the results show that the MSMix method achieves better results than other methods in both full-sample and small-sample configurations.
Efficient Transformer-based 3D Object Detection with Dynamic Token Halting
Mar 09, 2023Balancing efficiency and accuracy is a long-standing problem for deploying deep learning models. The trade-off is even more important for real-time safety-critical systems like autonomous vehicles. In this paper, we propose an effective approach for accelerating transformer-based 3D object detectors by dynamically halting tokens at different layers depending on their contribution to the detection task. Although halting a token is a non-differentiable operation, our method allows for differentiable end-to-end learning by leveraging an equivalent differentiable forward-pass. Furthermore, our framework allows halted tokens to be reused to inform the model's predictions through a straightforward token recycling mechanism. Our method significantly improves the Pareto frontier of efficiency versus accuracy when compared with the existing approaches. By halting tokens and increasing model capacity, we are able to improve the baseline model's performance without increasing the model's latency on the Waymo Open Dataset.
Bit Allocation using Optimization
Sep 20, 2022
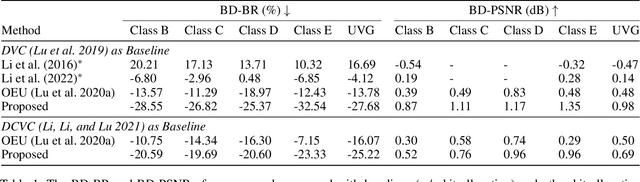


In this paper, we consider the problem of bit allocation in neural video compression (NVC). Due to the frame reference structure, current NVC methods using the same R-D (Rate-Distortion) trade-off parameter $\lambda$ for all frames are suboptimal, which brings the need for bit allocation. Unlike previous methods based on heuristic and empirical R-D models, we propose to solve this problem by gradient-based optimization. Specifically, we first propose a continuous bit implementation method based on Semi-Amortized Variational Inference (SAVI). Then, we propose a pixel-level implicit bit allocation method using iterative optimization by changing the SAVI target. Moreover, we derive the precise R-D model based on the differentiable trait of NVC. And we show the optimality of our method by proofing its equivalence to the bit allocation with precise R-D model. Experimental results show that our approach significantly improves NVC methods and outperforms existing bit allocation methods. Our approach is plug-and-play for all differentiable NVC methods, and it can be directly adopted on existing pre-trained models.
BOME! Bilevel Optimization Made Easy: A Simple First-Order Approach
Sep 19, 2022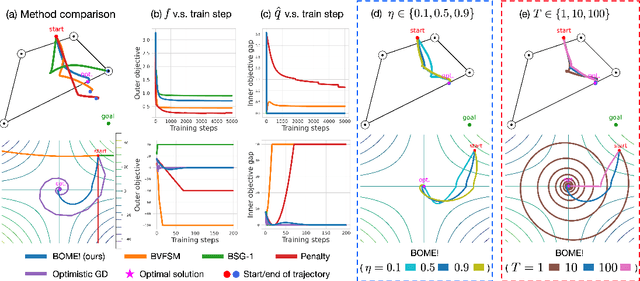
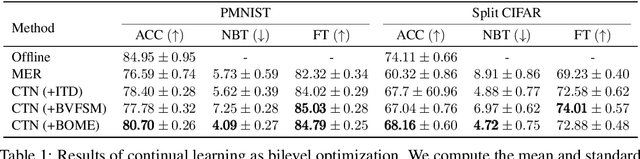
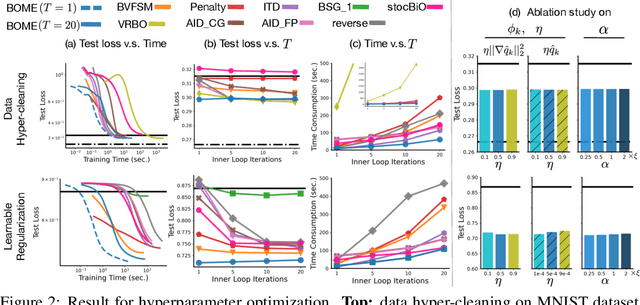
Bilevel optimization (BO) is useful for solving a variety of important machine learning problems including but not limited to hyperparameter optimization, meta-learning, continual learning, and reinforcement learning. Conventional BO methods need to differentiate through the low-level optimization process with implicit differentiation, which requires expensive calculations related to the Hessian matrix. There has been a recent quest for first-order methods for BO, but the methods proposed to date tend to be complicated and impractical for large-scale deep learning applications. In this work, we propose a simple first-order BO algorithm that depends only on first-order gradient information, requires no implicit differentiation, and is practical and efficient for large-scale non-convex functions in deep learning. We provide non-asymptotic convergence analysis of the proposed method to stationary points for non-convex objectives and present empirical results that show its superior practical performance.
First Hitting Diffusion Models
Sep 02, 2022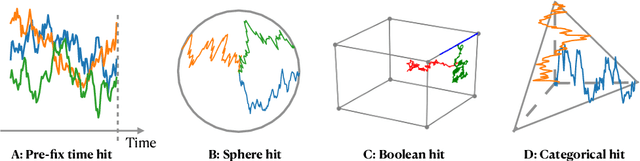
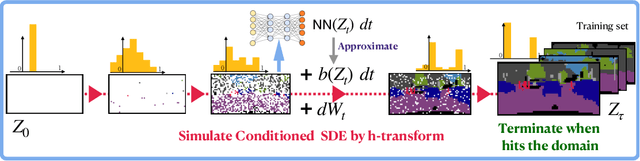
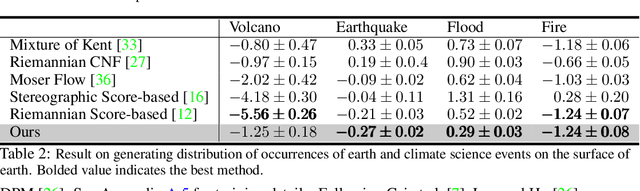
We propose a family of First Hitting Diffusion Models (FHDM), deep generative models that generate data with a diffusion process that terminates at a random first hitting time. This yields an extension of the standard fixed-time diffusion models that terminate at a pre-specified deterministic time. Although standard diffusion models are designed for continuous unconstrained data, FHDM is naturally designed to learn distributions on continuous as well as a range of discrete and structure domains. Moreover, FHDM enables instance-dependent terminate time and accelerates the diffusion process to sample higher quality data with fewer diffusion steps. Technically, we train FHDM by maximum likelihood estimation on diffusion trajectories augmented from observed data with conditional first hitting processes (i.e., bridge) derived based on Doob's $h$-transform, deviating from the commonly used time-reversal mechanism. We apply FHDM to generate data in various domains such as point cloud (general continuous distribution), climate and geographical events on earth (continuous distribution on the sphere), unweighted graphs (distribution of binary matrices), and segmentation maps of 2D images (high-dimensional categorical distribution). We observe considerable improvement compared with the state-of-the-art approaches in both quality and speed.
Future Gradient Descent for Adapting the Temporal Shifting Data Distribution in Online Recommendation Systems
Sep 02, 2022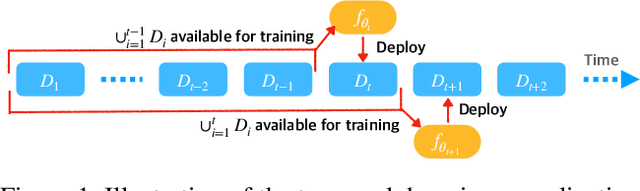
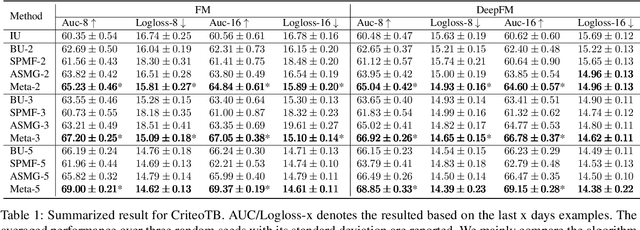
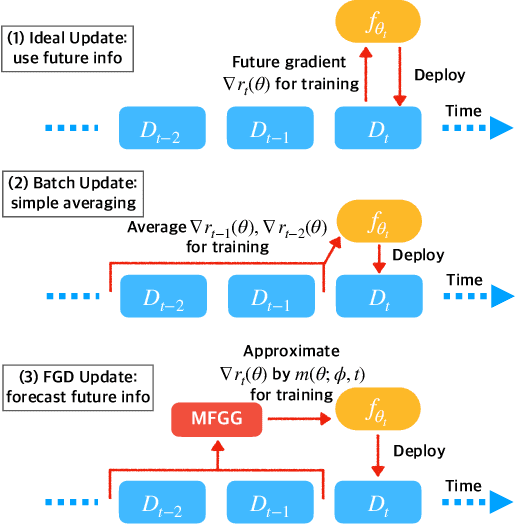
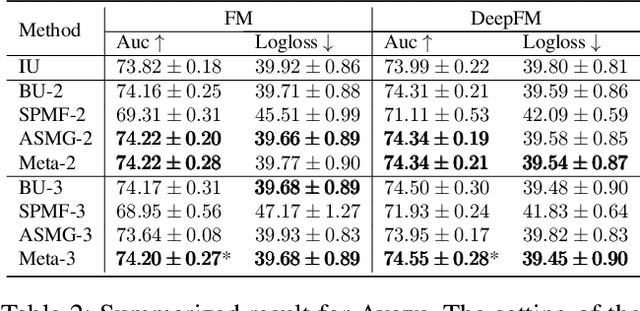
One of the key challenges of learning an online recommendation model is the temporal domain shift, which causes the mismatch between the training and testing data distribution and hence domain generalization error. To overcome, we propose to learn a meta future gradient generator that forecasts the gradient information of the future data distribution for training so that the recommendation model can be trained as if we were able to look ahead at the future of its deployment. Compared with Batch Update, a widely used paradigm, our theory suggests that the proposed algorithm achieves smaller temporal domain generalization error measured by a gradient variation term in a local regret. We demonstrate the empirical advantage by comparing with various representative baselines.
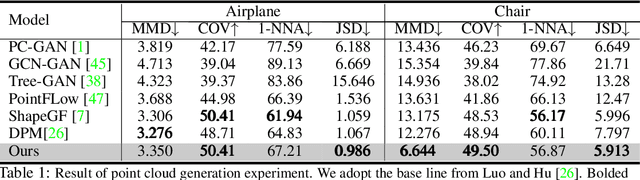
Diffusion-based Molecule Generation with Informative Prior Bridges
Sep 02, 2022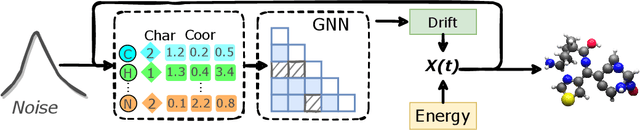
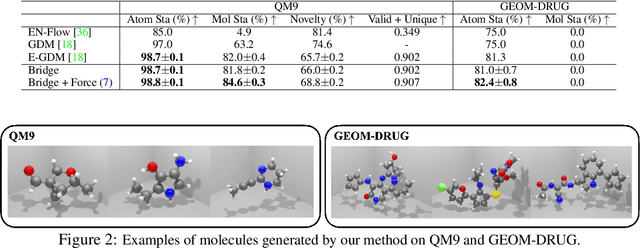


AI-based molecule generation provides a promising approach to a large area of biomedical sciences and engineering, such as antibody design, hydrolase engineering, or vaccine development. Because the molecules are governed by physical laws, a key challenge is to incorporate prior information into the training procedure to generate high-quality and realistic molecules. We propose a simple and novel approach to steer the training of diffusion-based generative models with physical and statistics prior information. This is achieved by constructing physically informed diffusion bridges, stochastic processes that guarantee to yield a given observation at the fixed terminal time. We develop a Lyapunov function based method to construct and determine bridges, and propose a number of proposals of informative prior bridges for both high-quality molecule generation and uniformity-promoted 3D point cloud generation. With comprehensive experiments, we show that our method provides a powerful approach to the 3D generation task, yielding molecule structures with better quality and stability scores and more uniformly distributed point clouds of high qualities.