 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentially Private Adaptive Optimization with Delayed Preconditioners
Dec 01, 2022Privacy noise may negate the benefits of using adaptive optimizers in differentially private model training. Prior works typically address this issue by using auxiliary information (e.g., public data) to boost the effectiveness of adaptive optimization. In this work, we explore techniques to estimate and efficiently adapt to gradient geometry in private adaptive optimization without auxiliary data. Motivated by the observation that adaptive methods can tolerate stale preconditioners, we propose differentially private adaptive training with delayed preconditioners (DP^2), a simple method that constructs delayed but less noisy preconditioners to better realize the benefits of adaptivity. Theoretically, we provide convergence guarantees for our method for both convex and non-convex problems, and analyze trade-offs between delay and privacy noise reduction. Empirically, we explore DP^2 across several real-world datasets, demonstrating that it can improve convergence speed by as much as 4x relative to non-adaptive baselines and match the performance of state-of-the-art optimization methods that require auxiliary data.
Large Language Models with Controllable Working Memory
Nov 09, 2022



Large language models (LLMs) have led to a series of breakthroughs in natural language processing (NLP), owing to their excellent understanding and generation abilities. Remarkably, what further sets these models apart is the massive amounts of world knowledge they internalize during pretraining. While many downstream applications provide the model with an informational context to aid its performance on the underlying task, how the model's world knowledge interacts with the factual information presented in the context remains under explored. As a desirable behavior, an LLM should give precedence to the context whenever it contains task-relevant information that conflicts with the model's memorized knowledge. This enables model predictions to be grounded in the context, which can then be used to update or correct specific model predictions without frequent retraining. By contrast, when the context is irrelevant to the task, the model should ignore it and fall back on its internal knowledge. In this paper, we undertake a first joint study of the aforementioned two properties, namely controllability and robustness, in the context of LLMs. We demonstrate that state-of-the-art T5 and PaLM (both pretrained and finetuned) could exhibit poor controllability and robustness, which do not scale with increasing model size. As a solution, we propose a novel method - Knowledge Aware FineTuning (KAFT) - to strengthen both controllability and robustness by incorporating counterfactual and irrelevant contexts to standard supervised datasets. Our comprehensive evaluation showcases the utility of KAFT across model architectures and sizes.
Learning to Navigate Wikipedia by Taking Random Walks
Oct 31, 2022A fundamental ability of an intelligent web-based agent is seeking out and acquiring new information. Internet search engines reliably find the correct vicinity but the top results may be a few links away from the desired target. A complementary approach is navigation via hyperlinks, employing a policy that comprehends local content and selects a link that moves it closer to the target. In this paper, we show that behavioral cloning of randomly sampled trajectories is sufficient to learn an effective link selection policy. We demonstrate the approach on a graph version of Wikipedia with 38M nodes and 387M edges. The model is able to efficiently navigate between nodes 5 and 20 steps apart 96% and 92% of the time, respectively. We then use the resulting embeddings and policy in downstream fact verification and question answering tasks where, in combination with basic TF-IDF search and ranking methods, they are competitive results to the state-of-the-art methods.
Efficient Nearest Neighbor Search for Cross-Encoder Models using Matrix Factorization
Oct 23, 2022Efficient k-nearest neighbor search is a fundamental task, foundational for many problems in NLP. When the similarity is measured by dot-product between dual-encoder vectors or $\ell_2$-distance, there already exist many scalable and efficient search methods. But not so when similarity is measured by more accurate and expensive black-box neural similarity models, such as cross-encoders, which jointly encode the query and candidate neighbor. The cross-encoders' high computational cost typically limits their use to reranking candidates retrieved by a cheaper model, such as dual encoder or TF-IDF. However, the accuracy of such a two-stage approach is upper-bounded by the recall of the initial candidate set, and potentially requires additional training to align the auxiliary retrieval model with the cross-encoder model. In this paper, we present an approach that avoids the use of a dual-encoder for retrieval, relying solely on the cross-encoder. Retrieval is made efficient with CUR decomposition, a matrix decomposition approach that approximates all pairwise cross-encoder distances from a small subset of rows and columns of the distance matrix. Indexing items using our approach is computationally cheaper than training an auxiliary dual-encoder model through distillation. Empirically, for k > 10, our approach provides test-time recall-vs-computational cost trade-offs superior to the current widely-used methods that re-rank items retrieved using a dual-encoder or TF-IDF.
Longtonotes: OntoNotes with Longer Coreference Chains
Oct 07, 2022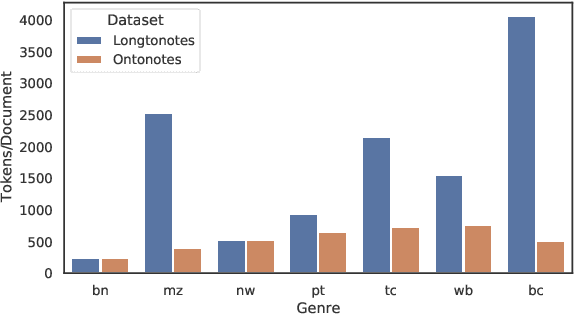
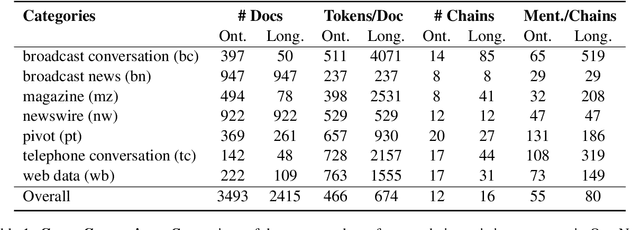
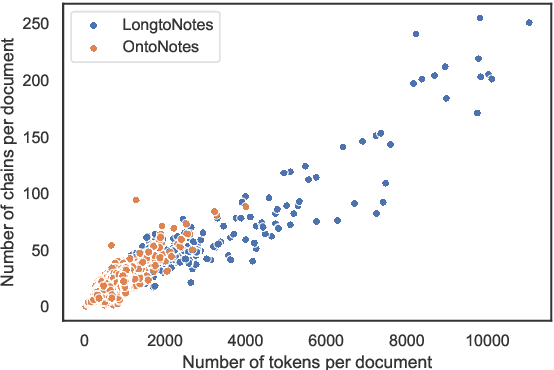
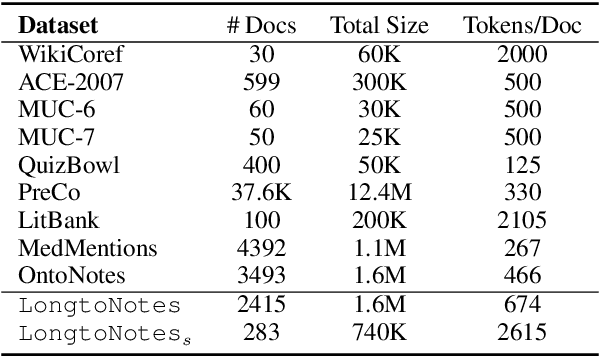
Ontonotes has served as the most important benchmark for coreference resolution. However, for ease of annotation, several long documents in Ontonotes were split into smaller parts. In this work, we build a corpus of coreference-annotated documents of significantly longer length than what is currently available. We do so by providing an accurate, manually-curated, merging of annotations from documents that were split into multiple parts in the original Ontonotes annotation process. The resulting corpus, which we call LongtoNotes contains documents in multiple genres of the English language with varying lengths, the longest of which are up to 8x the length of documents in Ontonotes, and 2x those in Litbank. We evaluate state-of-the-art neural coreference systems on this new corpus, analyze the relationships between model architectures/hyperparameters and document length on performance and efficiency of the models, and demonstrate areas of improvement in long-document coreference modeling revealed by our new corpus. Our data and code is available at: https://github.com/kumar-shridhar/LongtoNotes.
Generalization Properties of Retrieval-based Models
Oct 06, 2022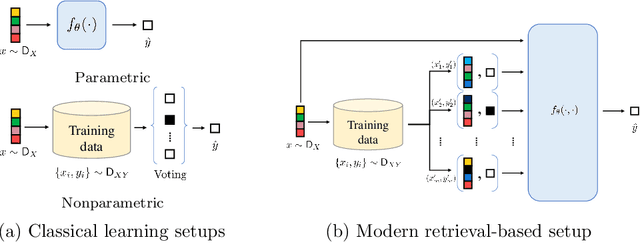
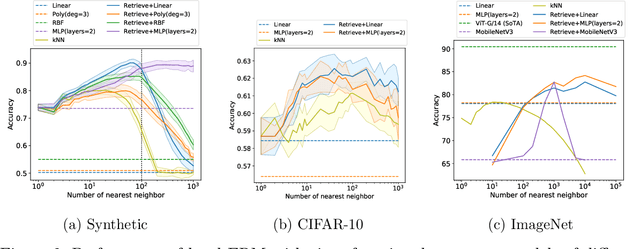
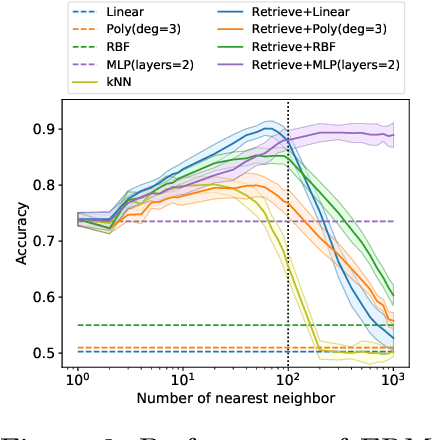
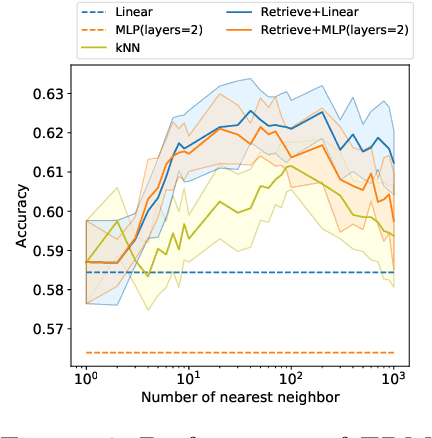
Many modern high-performing machine learning models such as GPT-3 primarily rely on scaling up models, e.g., transformer networks. Simultaneously, a parallel line of work aims to improve the model performance by augmenting an input instance with other (labeled) instances during inference. Examples of such augmentations include task-specific prompts and similar examples retrieved from the training data by a nonparametric component. Remarkably, retrieval-based methods have enjoyed success on a wide range of problems, ranging from standard natural language processing and vision tasks to protein folding, as demonstrated by many recent efforts, including WebGPT and AlphaFold. Despite growing literature showcasing the promise of these models, the theoretical underpinning for such models remains underexplored. In this paper, we present a formal treatment of retrieval-based models to characterize their generalization ability. In particular, we focus on two classes of retrieval-based classification approaches: First, we analyze a local learning framework that employs an explicit local empirical risk minimization based on retrieved examples for each input instance. Interestingly, we show that breaking down the underlying learning task into local sub-tasks enables the model to employ a low complexity parametric component to ensure good overall accuracy. The second class of retrieval-based approaches we explore learns a global model using kernel methods to directly map an input instance and retrieved examples to a prediction, without explicitly solving a local learning task.
A Fourier Approach to Mixture Learning
Oct 06, 2022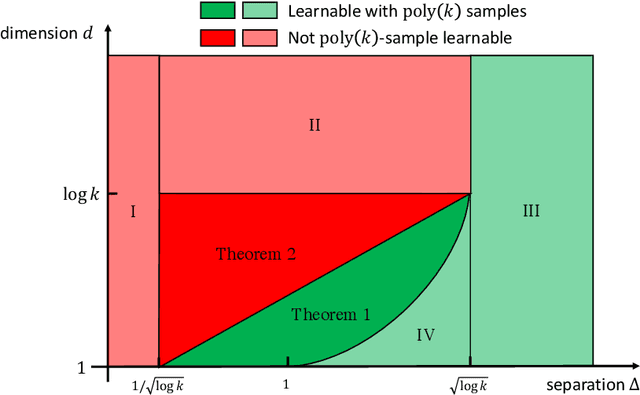

We revisit the problem of learning mixtures of spherical Gaussians. Given samples from mixture $\frac{1}{k}\sum_{j=1}^{k}\mathcal{N}(\mu_j, I_d)$, the goal is to estimate the means $\mu_1, \mu_2, \ldots, \mu_k \in \mathbb{R}^d$ up to a small error. The hardness of this learning problem can be measured by the separation $\Delta$ defined as the minimum distance between all pairs of means. Regev and Vijayaraghavan (2017) showed that with $\Delta = \Omega(\sqrt{\log k})$ separation, the means can be learned using $\mathrm{poly}(k, d)$ samples, whereas super-polynomially many samples are required if $\Delta = o(\sqrt{\log k})$ and $d = \Omega(\log k)$. This leaves open the low-dimensional regime where $d = o(\log k)$. In this work, we give an algorithm that efficiently learns the means in $d = O(\log k/\log\log k)$ dimensions under separation $d/\sqrt{\log k}$ (modulo doubly logarithmic factors). This separation is strictly smaller than $\sqrt{\log k}$, and is also shown to be necessary. Along with the results of Regev and Vijayaraghavan (2017), our work almost pins down the critical separation threshold at which efficient parameter learning becomes possible for spherical Gaussian mixtures. More generally, our algorithm runs in time $\mathrm{poly}(k)\cdot f(d, \Delta, \epsilon)$, and is thus fixed-parameter tractable in parameters $d$, $\Delta$ and $\epsilon$. Our approach is based on estimating the Fourier transform of the mixture at carefully chosen frequencies, and both the algorithm and its analysis are simple and elementary. Our positive results can be easily extended to learning mixtures of non-Gaussian distributions, under a mild condition on the Fourier spectrum of the distribution.
Teacher Guided Training: An Efficient Framework for Knowledge Transfer
Aug 14, 2022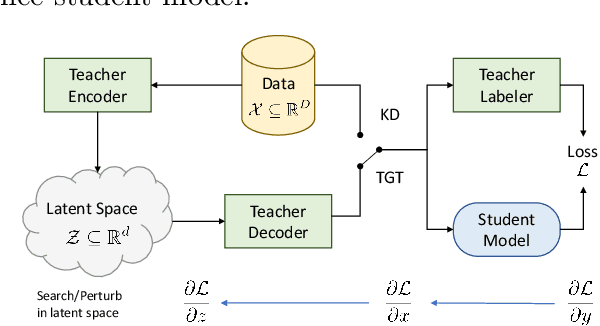
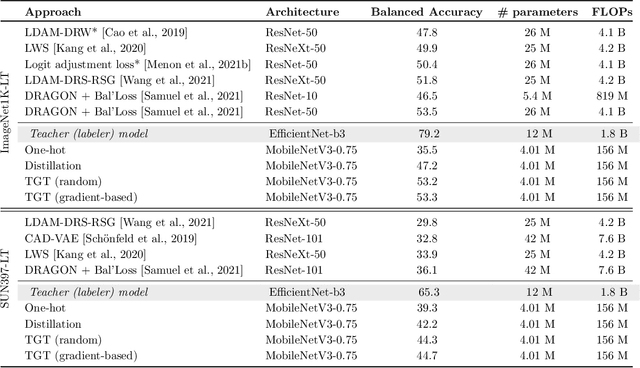
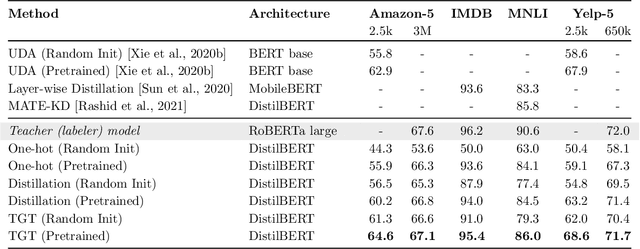
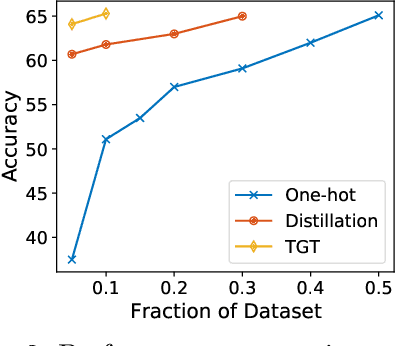
The remarkable performance gains realized by large pretrained models, e.g., GPT-3, hinge on the massive amounts of data they are exposed to during training. Analogously, distilling such large models to compact models for efficient deployment also necessitates a large amount of (labeled or unlabeled) training data. In this paper, we propose the teacher-guided training (TGT) framework for training a high-quality compact model that leverages the knowledge acquired by pretrained generative models, while obviating the need to go through a large volume of data. TGT exploits the fact that the teacher has acquired a good representation of the underlying data domain, which typically corresponds to a much lower dimensional manifold than the input space. Furthermore, we can use the teacher to explore input space more efficiently through sampling or gradient-based methods; thus, making TGT especially attractive for limited data or long-tail settings. We formally capture this benefit of proposed data-domain exploration in our generalization bounds. We find that TGT can improve accuracy on several image classification benchmarks as well as a range of text classification and retrieval tasks.
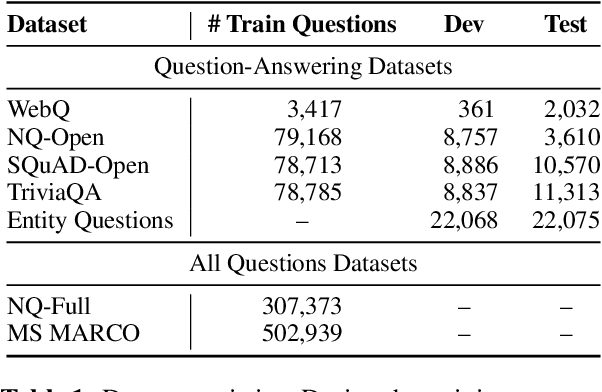
Questions Are All You Need to Train a Dense Passage Retriever
Jun 21, 2022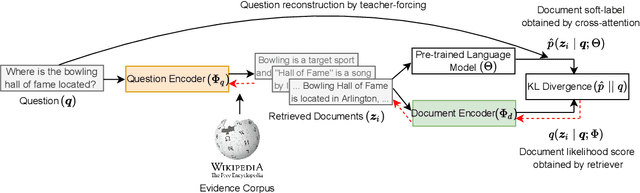
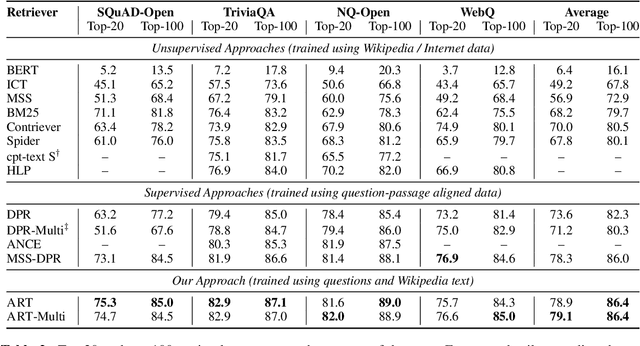
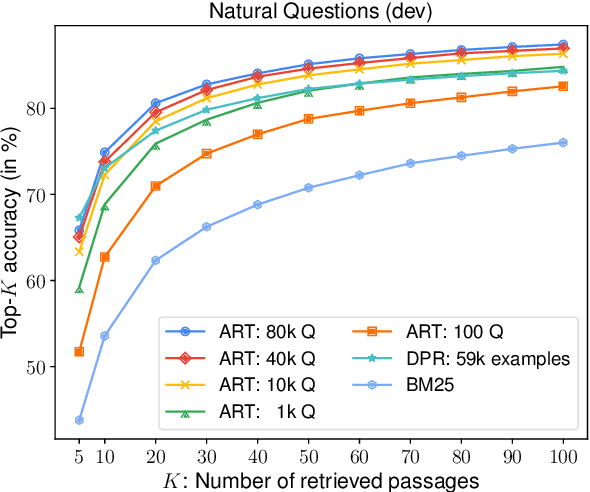
We introduce ART, a new corpus-level autoencoding approach for training dense retrieval models that does not require any labeled training data. Dense retrieval is a central challenge for open-domain tasks, such as Open QA, where state-of-the-art methods typically require large supervised datasets with custom hard-negative mining and denoising of positive examples. ART, in contrast, only requires access to unpaired inputs and outputs (e.g. questions and potential answer documents). It uses a new document-retrieval autoencoding scheme, where (1) an input question is used to retrieve a set of evidence documents, and (2) the documents are then used to compute the probability of reconstructing the original question. Training for retrieval based on question reconstruction enables effective unsupervised learning of both document and question encoders, which can be later incorporated into complete Open QA systems without any further finetuning. Extensive experiments demonstrate that ART obtains state-of-the-art results on multiple QA retrieval benchmarks with only generic initialization from a pre-trained language model, removing the need for labeled data and task-specific losses.
StreamingQA: A Benchmark for Adaptation to New Knowledge over Time in Question Answering Models
May 23, 2022
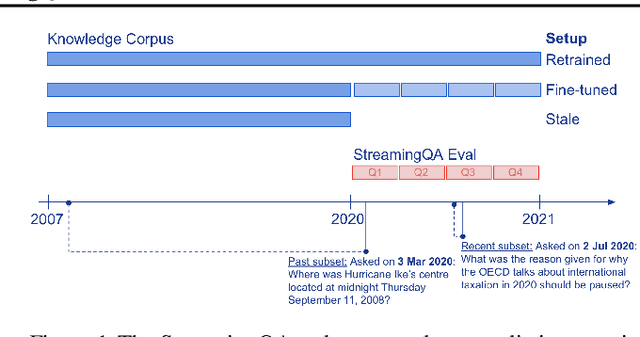

Knowledge and language understanding of models evaluated through question answering (QA) has been usually studied on static snapshots of knowledge, like Wikipedia. However, our world is dynamic, evolves over time, and our models' knowledge becomes outdated. To study how semi-parametric QA models and their underlying parametric language models (LMs) adapt to evolving knowledge, we construct a new large-scale dataset, StreamingQA, with human written and generated questions asked on a given date, to be answered from 14 years of time-stamped news articles. We evaluate our models quarterly as they read new articles not seen in pre-training. We show that parametric models can be updated without full retraining, while avoiding catastrophic forgetting. For semi-parametric models, adding new articles into the search space allows for rapid adaptation, however, models with an outdated underlying LM under-perform those with a retrained LM. For questions about higher-frequency named entities, parametric updates are particularly beneficial. In our dynamic world, the StreamingQA dataset enables a more realistic evaluation of QA models, and our experiments highlight several promising directions for future research.