 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Learning of Visual-Audio Saliency Prediction and Sound Source Localization on Multi-face Videos
Nov 05, 2021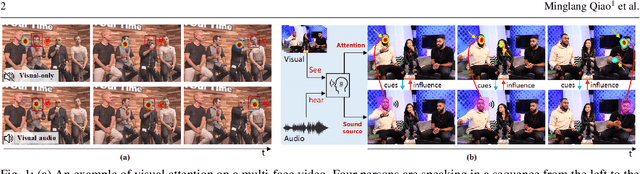
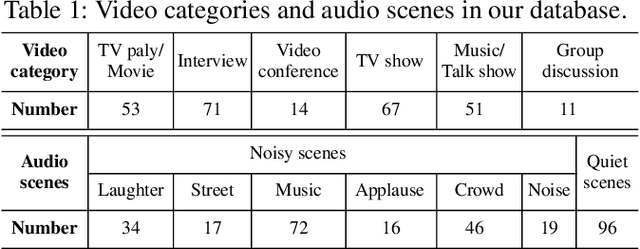

Visual and audio events simultaneously occur and both attract attention. However, most existing saliency prediction works ignore the influence of audio and only consider vision modality. In this paper, we propose a multitask learning method for visual-audio saliency prediction and sound source localization on multi-face video by leveraging visual, audio and face information. Specifically, we first introduce a large-scale database of multi-face video in visual-audio condition (MVVA), containing eye-tracking data and sound source annotations. Using this database, we find that sound influences human attention, and conversly attention offers a cue to determine sound source on multi-face video. Guided by these findings, a visual-audio multi-task network (VAM-Net) is introduced to predict saliency and locate sound source. VAM-Net consists of three branches corresponding to visual, audio and face modalities. Visual branch has a two-stream architecture to capture spatial and temporal information. Face and audio branches encode audio signals and faces, respectively. Finally, a spatio-temporal multi-modal graph (STMG) is constructed to model the interaction among multiple faces. With joint optimization of these branches, the intrinsic correlation of the tasks of saliency prediction and sound source localization is utilized and their performance is boosted by each other. Experiments show that the proposed method outperforms 12 state-of-the-art saliency prediction methods, and achieves competitive results in sound source localization.
Domain Adaptation for Underwater Image Enhancement
Aug 22, 2021



Recently, learning-based algorithms have shown impressive performance in underwater image enhancement. Most of them resort to training on synthetic data and achieve outstanding performance. However, these methods ignore the significant domain gap between the synthetic and real data (i.e., interdomain gap), and thus the models trained on synthetic data often fail to generalize well to real underwater scenarios. Furthermore, the complex and changeable underwater environment also causes a great distribution gap among the real data itself (i.e., intra-domain gap). However, almost no research focuses on this problem and thus their techniques often produce visually unpleasing artifacts and color distortions on various real images. Motivated by these observations, we propose a novel Two-phase Underwater Domain Adaptation network (TUDA) to simultaneously minimize the inter-domain and intra-domain gap. Concretely, a new dual-alignment network is designed in the first phase, including a translation part for enhancing realism of input images, followed by an enhancement part. With performing image-level and feature-level adaptation in two parts by jointly adversarial learning, the network can better build invariance across domains and thus bridge the inter-domain gap. In the second phase, we perform an easy-hard classification of real data according to the assessed quality of enhanced images, where a rank-based underwater quality assessment method is embedded. By leveraging implicit quality information learned from rankings, this method can more accurately assess the perceptual quality of enhanced images. Using pseudo labels from the easy part, an easy-hard adaptation technique is then conducted to effectively decrease the intra-domain gap between easy and hard samples.
Learning to Predict Salient Faces: A Novel Visual-Audio Saliency Model
Mar 29, 2021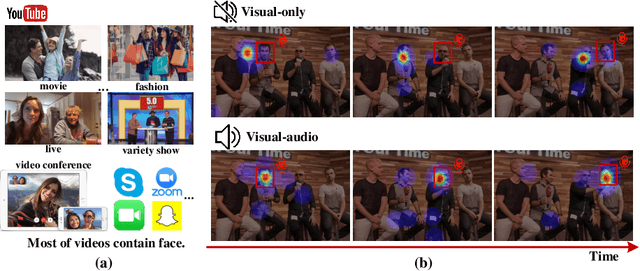
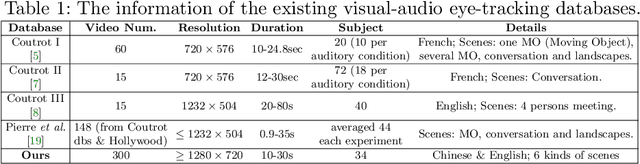
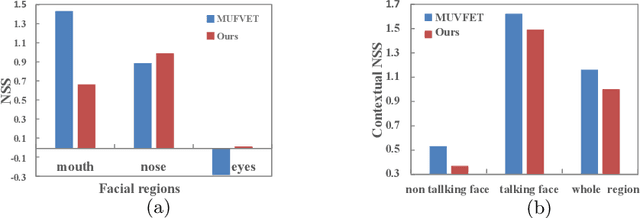
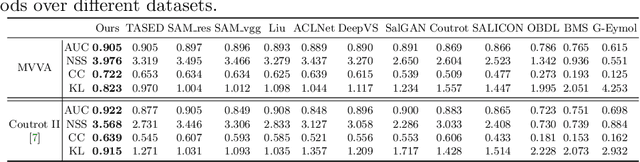
Recently, video streams have occupied a large proportion of Internet traffic, most of which contain human faces. Hence, it is necessary to predict saliency on multiple-face videos, which can provide attention cues for many content based applications. However, most of multiple-face saliency prediction works only consider visual information and ignore audio, which is not consistent with the naturalistic scenarios. Several behavioral studies have established that sound influences human attention, especially during the speech turn-taking in multiple-face videos. In this paper, we thoroughly investigate such influences by establishing a large-scale eye-tracking database of Multiple-face Video in Visual-Audio condition (MVVA). Inspired by the findings of our investigation, we propose a novel multi-modal video saliency model consisting of three branches: visual, audio and face. The visual branch takes the RGB frames as the input and encodes them into visual feature maps. The audio and face branches encode the audio signal and multiple cropped faces, respectively. A fusion module is introduced to integrate the information from three modalities, and to generate the final saliency map. Experimental results show that the proposed method outperforms 11 state-of-the-art saliency prediction works. It performs closer to human multi-modal attention.
Spatial Attention-based Non-reference Perceptual Quality Prediction Network for Omnidirectional Images
Mar 10, 2021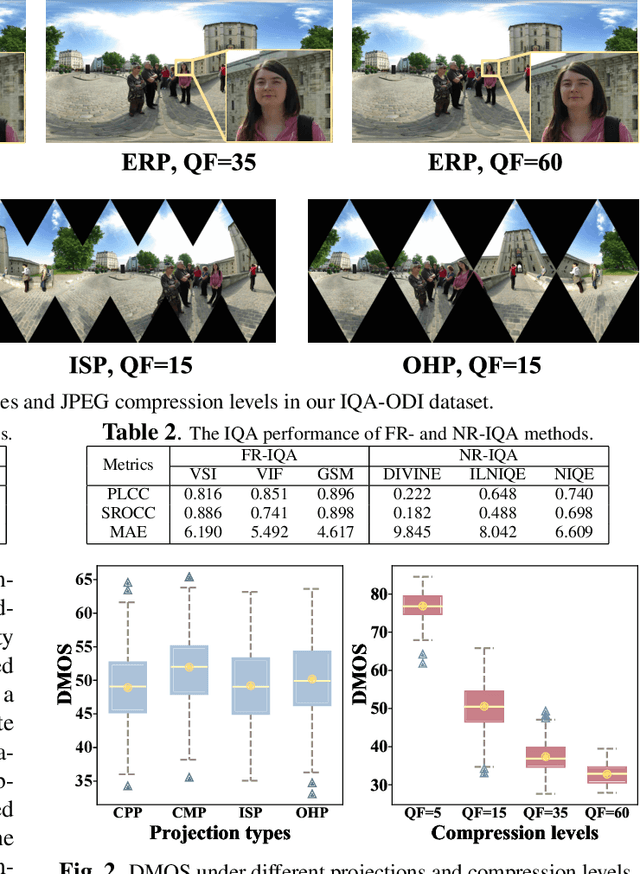
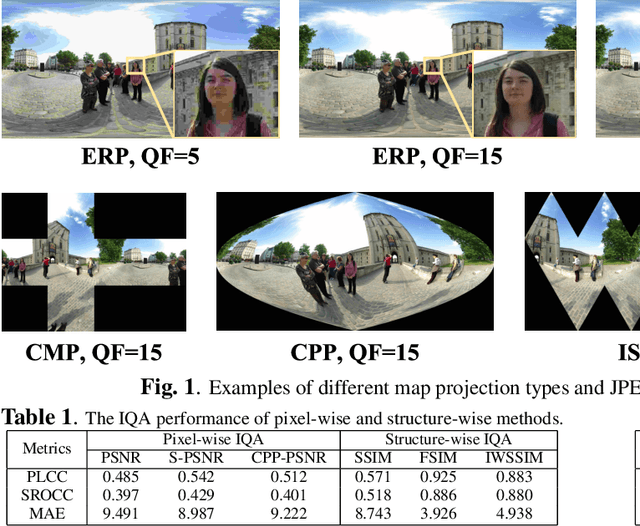
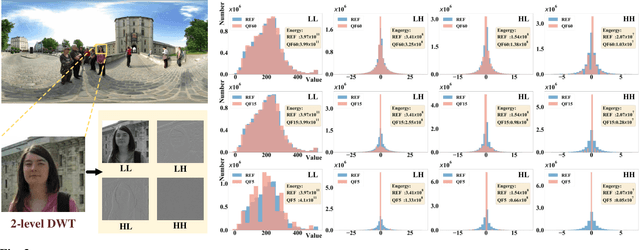
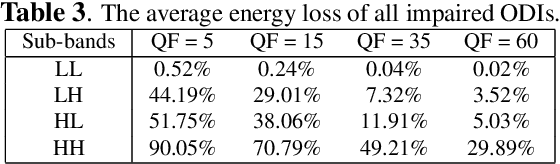
Due to the strong correlation between visual attention and perceptual quality, many methods attempt to use human saliency information for image quality assessment. Although this mechanism can get good performance, the networks require human saliency labels, which is not easily accessible for omnidirectional images (ODI). To alleviate this issue, we propose a spatial attention-based perceptual quality prediction network for non-reference quality assessment on ODIs (SAP-net). To drive our SAP-net, we establish a large-scale IQA dataset of ODIs (IQA-ODI), which is composed of subjective scores of 200 subjects on 1,080 ODIs. In IQA-ODI, there are 120 high quality ODIs as reference, and 960 ODIs with impairments in both JPEG compression and map projection. Without any human saliency labels, our network can adaptively estimate human perceptual quality on impaired ODIs through a self-attention manner, which significantly promotes the prediction performance of quality scores. Moreover, our method greatly reduces the computational complexity in quality assessment task on ODIs. Extensive experiments validate that our network outperforms 9 state-of-the-art methods for quality assessment on ODIs. The dataset and code have been available on \url{ https://github.com/yanglixiaoshen/SAP-Net}.
Multi-level Wavelet-based Generative Adversarial Network for Perceptual Quality Enhancement of Compressed Video
Aug 02, 2020
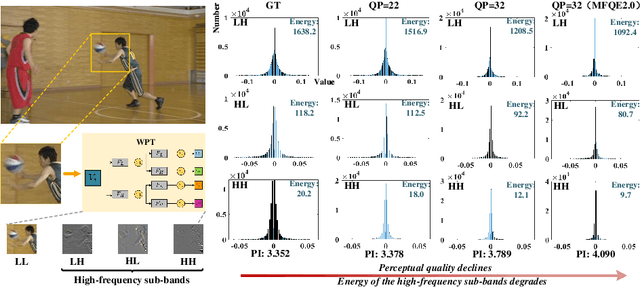
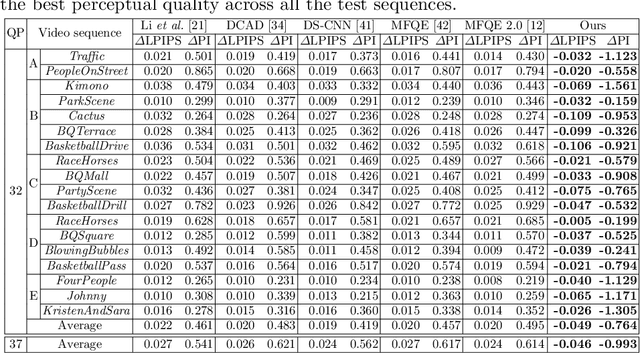
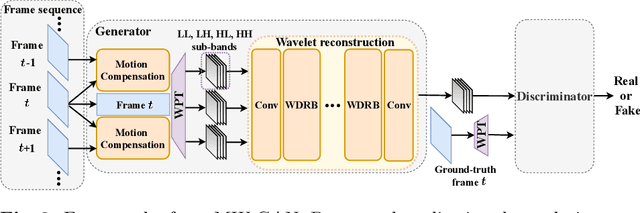
The past few years have witnessed fast development in video quality enhancement via deep learning. Existing methods mainly focus on enhancing the objective quality of compressed video while ignoring its perceptual quality. In this paper, we focus on enhancing the perceptual quality of compressed video. Our main observation is that enhancing the perceptual quality mostly relies on recovering high-frequency sub-bands in wavelet domain. Accordingly, we propose a novel generative adversarial network (GAN) based on multi-level wavelet packet transform (WPT) to enhance the perceptual quality of compressed video, which is called multi-level wavelet-based GAN (MW-GAN). In MW-GAN, we first apply motion compensation with a pyramid architecture to obtain temporal information. Then, we propose a wavelet reconstruction network with wavelet-dense residual blocks (WDRB) to recover the high-frequency details. In addition, the adversarial loss of MW-GAN is added via WPT to further encourage high-frequency details recovery for video frames. Experimental results demonstrate the superiority of our method.
Early Exit Or Not: Resource-Efficient Blind Quality Enhancement for Compressed Images
Jul 09, 2020
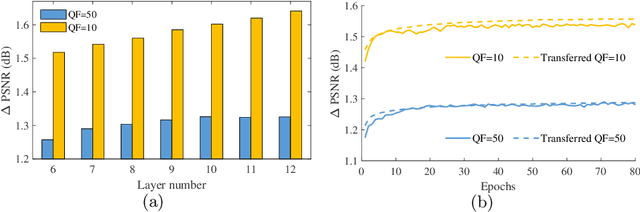
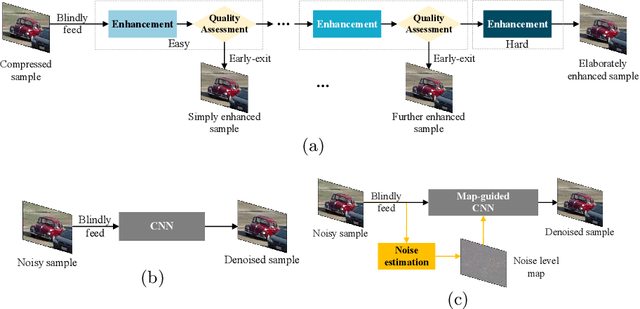
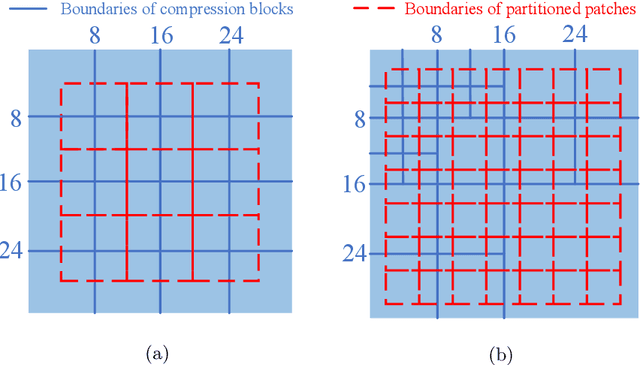
Lossy image compression is pervasively conducted to save communication bandwidth, resulting in undesirable compression artifacts. Recently, extensive approaches have been proposed to reduce image compression artifacts at the decoder side; however, they require a series of architecture-identical models to process images with different quality, which are inefficient and resource-consuming. Besides, it is common in practice that compressed images are with unknown quality and it is intractable for existing approaches to select a suitable model for blind quality enhancement. In this paper, we propose a resource-efficient blind quality enhancement (RBQE) approach for compressed images. Specifically, our approach blindly and progressively enhances the quality of compressed images through a dynamic deep neural network (DNN), in which an early-exit strategy is embedded. Then, our approach can automatically decide to terminate or continue enhancement according to the assessed quality of enhanced images. Consequently, slight artifacts can be removed in a simpler and faster process, while the severe artifacts can be further removed in a more elaborate process. Extensive experiments demonstrate that our RBQE approach achieves state-of-the-art performance in terms of both blind quality enhancement and resource efficiency.
Wavelet Domain Style Transfer for an Effective Perception-distortion Tradeoff in Single Image Super-Resolution
Oct 09, 2019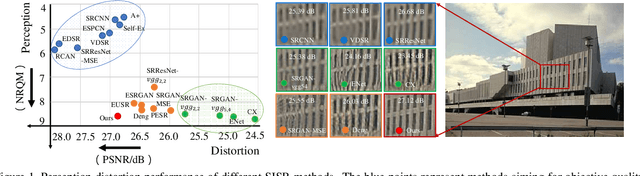
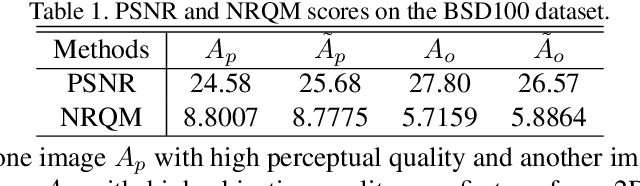
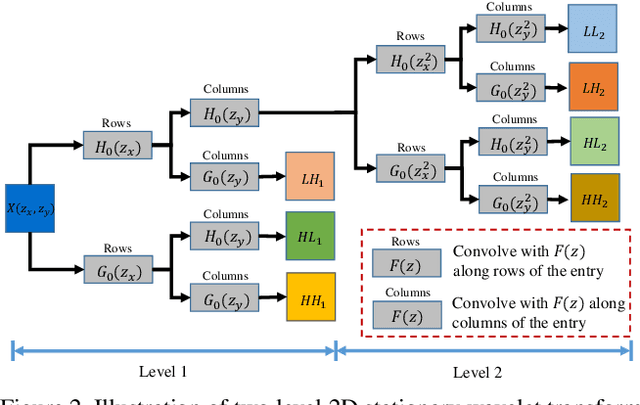
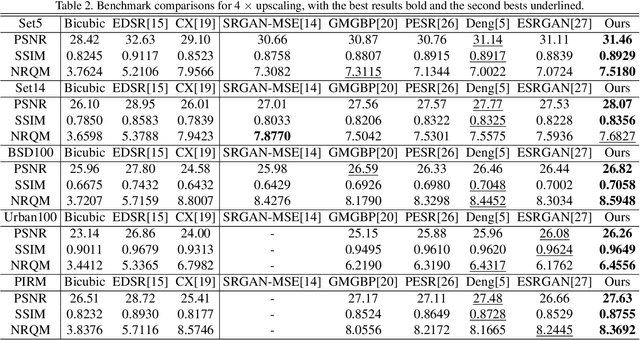
In single image super-resolution (SISR), given a low-resolution (LR) image, one wishes to find a high-resolution (HR) version of it which is both accurate and photo-realistic. Recently, it has been shown that there exists a fundamental tradeoff between low distortion and high perceptual quality, and the generative adversarial network (GAN) is demonstrated to approach the perception-distortion (PD) bound effectively. In this paper, we propose a novel method based on wavelet domain style transfer (WDST), which achieves a better PD tradeoff than the GAN based methods. Specifically, we propose to use 2D stationary wavelet transform (SWT) to decompose one image into low-frequency and high-frequency sub-bands. For the low-frequency sub-band, we improve its objective quality through an enhancement network. For the high-frequency sub-band, we propose to use WDST to effectively improve its perceptual quality. By feat of the perfect reconstruction property of wavelets, these sub-bands can be re-combined to obtain an image which has simultaneously high objective and perceptual quality. The numerical results on various datasets show that our method achieves the best trade-off between the distortion and perceptual quality among the existing state-of-the-art SISR methods.
Removing Rain in Videos: A Large-scale Database and A Two-stream ConvLSTM Approach
Jun 06, 2019

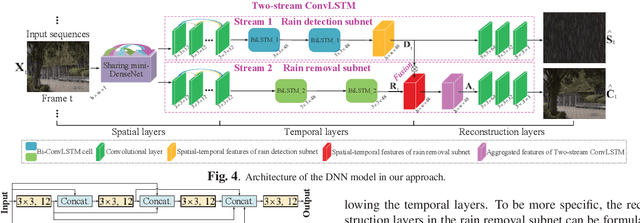
Rain removal has recently attracted increasing research attention, as it is able to enhance the visibility of rain videos. However, the existing learning based rain removal approaches for videos suffer from insufficient training data, especially when applying deep learning to remove rain. In this paper, we establish a large-scale video database for rain removal (LasVR), which consists of 316 rain videos. Then, we observe from our database that there exist the temporal correlation of clean content and similar patterns of rain across video frames. According to these two observations, we propose a two-stream convolutional long- and short- term memory (ConvLSTM) approach for rain removal in videos. The first stream is composed of the subnet for rain detection, while the second stream is the subnet of rain removal that leverages the features from the rain detection subnet. Finally, the experimental results on both synthetic and real rain videos show the proposed approach performs better than other state-of-the-art approaches.
Arena: A General Evaluation Platform and Building Toolkit for Multi-Agent Intelligence
May 30, 2019

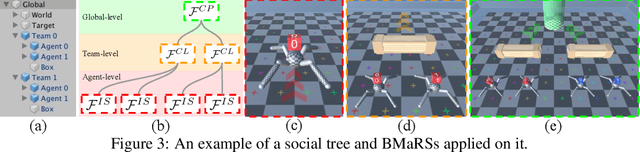
Learning agents that are not only capable of taking tests but are also innovating are becoming a hot topic in artificial intelligence (AI). One of the most promising paths towards this vision is multi-agent learning, where agents act as the environment for each other, and improving each agent means proposing new problems for others. However, the existing evaluation platforms are either not compatible with multi-agent settings, or limited to a specific game. That is, there is not yet a general evaluation platform for research on multi-agent intelligence. To this end, we introduce Arena, a general evaluation platform for multi-agent intelligence with 35 games of diverse logic and representations. Furthermore, multi-agent intelligence is still at the stage where many problems remain unexplored. Therefore, we provide a building toolkit for researchers to easily invent and build novel multi-agent problems from the provided games set based on a GUI-configurable social tree and five basic multi-agent reward schemes. Finally, we provide python implementations of five state-of-the-art deep multi-agent reinforcement learning baselines. Along with the baseline implementations, we release a set of 100 best agents/teams that we can train with different training schemes for each game, as the base for evaluating agents with population performance. As such, the research community can perform comparisons under a stable and uniform standard.
Mega-Reward: Achieving Human-Level Play without Extrinsic Rewards
May 30, 2019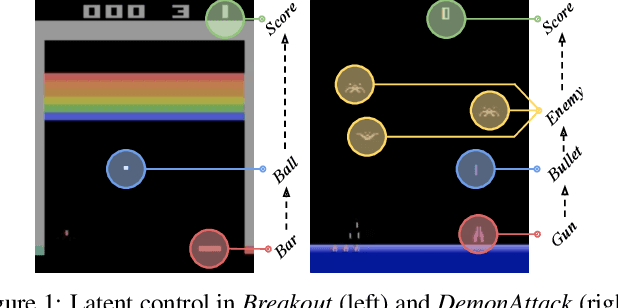

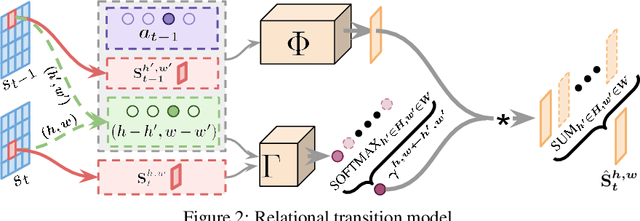
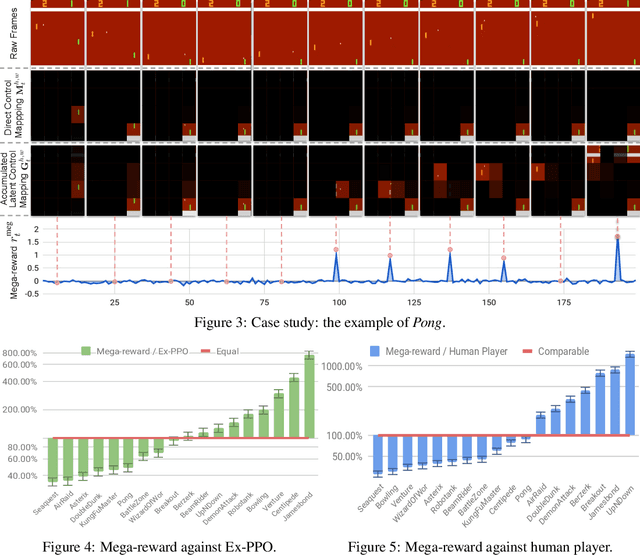
Intrinsic rewards are introduced to simulate how human intelligence works; they are usually evaluated by intrinsically-motivated play, i.e., playing games without extrinsic rewards but evaluated with extrinsic rewards. However, none of the existing intrinsic reward approaches can achieve human-level performance under this very challenging setting of intrinsically-motivated play. In this work, we propose a novel megalomania-driven intrinsic reward (called \emph{mega-reward}), which, to our knowledge, is the first approach that achieves human-level performance in intrinsically-motivated play. Intuitively, mega-reward comes from the observation that infants' intelligence develops when they try to gain more control on entities in an environment; therefore, mega-reward aims to maximize the control capabilities of agents on given entities in a given environment. To formalize mega-reward, a relational transition model is proposed to bridge the gaps between direct and latent control. Experimental studies show that mega-reward can (i) greatly outperform all state-of-the-art intrinsic reward approaches, (ii) generally achieves the same level of performance as Ex-PPO and professional human-level scores; and (iii) has also superior performance when it is incorporated with extrinsic reward.