 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models are Zero-Shot Reasoners
May 24, 2022
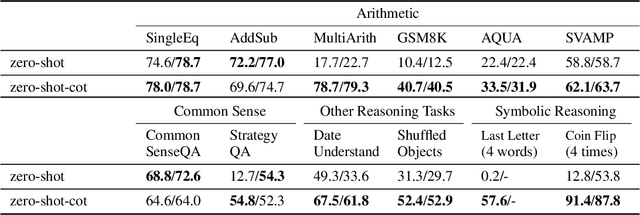
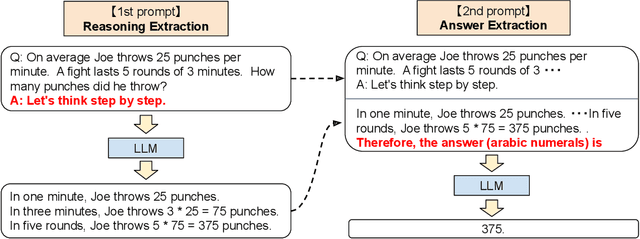
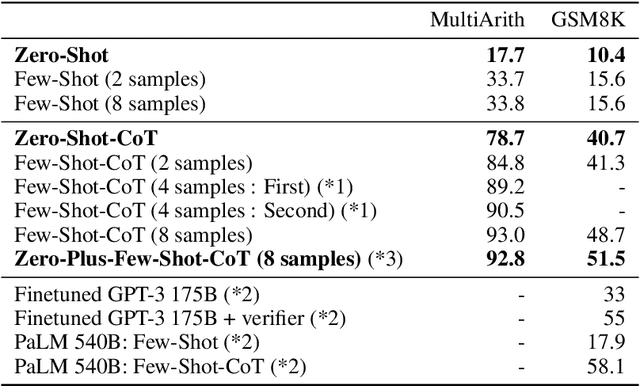
Pretrained large language models (LLMs) are widely used in many sub-fields of natural language processing (NLP) and generally known as excellent few-shot learners with task-specific exemplars. Notably, chain of thought (CoT) prompting, a recent technique for eliciting complex multi-step reasoning through step-by-step answer examples, achieved the state-of-the-art performances in arithmetics and symbolic reasoning, difficult system-2 tasks that do not follow the standard scaling laws for LLMs. While these successes are often attributed to LLMs' ability for few-shot learning, we show that LLMs are decent zero-shot reasoners by simply adding ``Let's think step by step'' before each answer. Experimental results demonstrate that our Zero-shot-CoT, using the same single prompt template, significantly outperforms zero-shot LLM performances on diverse benchmark reasoning tasks including arithmetics (MultiArith, GSM8K, AQUA-RAT, SVAMP), symbolic reasoning (Last Letter, Coin Flip), and other logical reasoning tasks (Date Understanding, Tracking Shuffled Objects), without any hand-crafted few-shot examples, e.g. increasing the accuracy on MultiArith from 17.7% to 78.7% and GSM8K from 10.4% to 40.7% with an off-the-shelf 175B parameter model. The versatility of this single prompt across very diverse reasoning tasks hints at untapped and understudied fundamental zero-shot capabilities of LLMs, suggesting high-level, multi-task broad cognitive capabilities may be extracted through simple prompting. We hope our work not only serves as the minimal strongest zero-shot baseline for the challenging reasoning benchmarks, but also highlights the importance of carefully exploring and analyzing the enormous zero-shot knowledge hidden inside LLMs before crafting finetuning datasets or few-shot exemplars.
A Few Thousand Translations Go a Long Way! Leveraging Pre-trained Models for African News Translation
May 04, 2022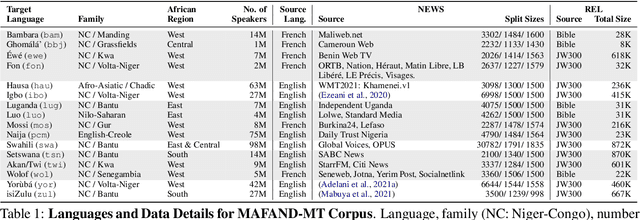
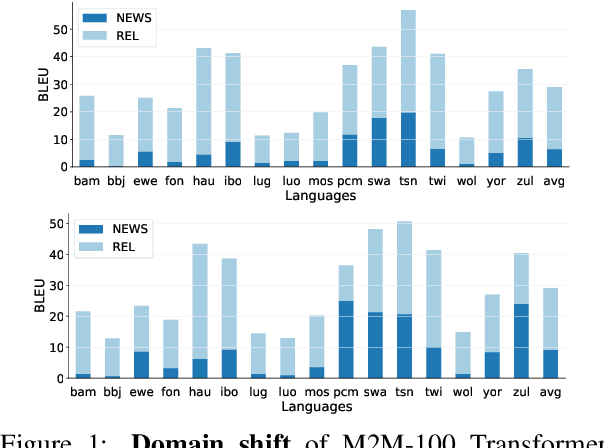

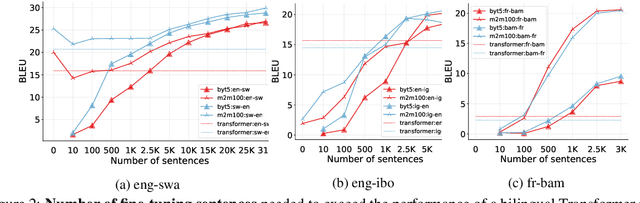
Recent advances in the pre-training of language models leverage large-scale datasets to create multilingual models. However, low-resource languages are mostly left out in these datasets. This is primarily because many widely spoken languages are not well represented on the web and therefore excluded from the large-scale crawls used to create datasets. Furthermore, downstream users of these models are restricted to the selection of languages originally chosen for pre-training. This work investigates how to optimally leverage existing pre-trained models to create low-resource translation systems for 16 African languages. We focus on two questions: 1) How can pre-trained models be used for languages not included in the initial pre-training? and 2) How can the resulting translation models effectively transfer to new domains? To answer these questions, we create a new African news corpus covering 16 languages, of which eight languages are not part of any existing evaluation dataset. We demonstrate that the most effective strategy for transferring both to additional languages and to additional domains is to fine-tune large pre-trained models on small quantities of high-quality translation data.
Can Wikipedia Help Offline Reinforcement Learning?
Jan 28, 2022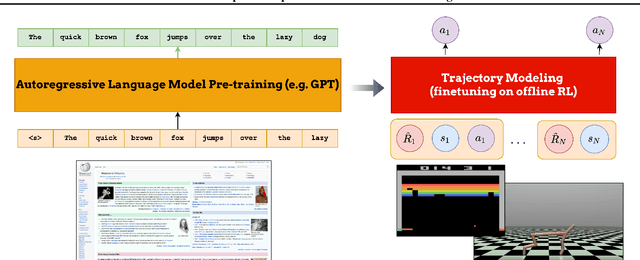
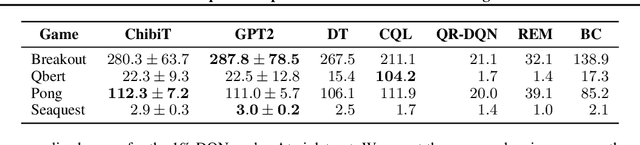
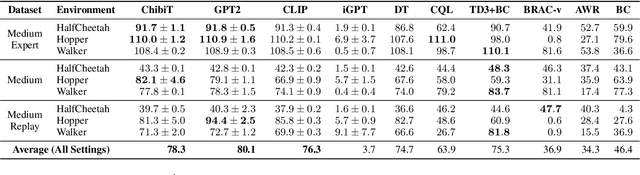
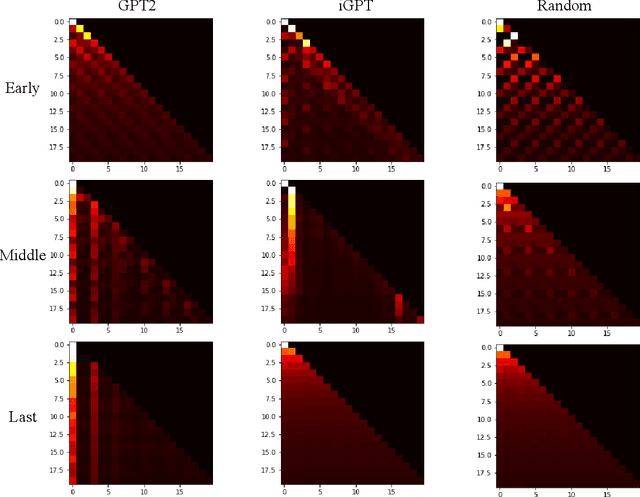
Fine-tuning reinforcement learning (RL) models has been challenging because of a lack of large scale off-the-shelf datasets as well as high variance in transferability among different environments. Recent work has looked at tackling offline RL from the perspective of sequence modeling with improved results as result of the introduction of the Transformer architecture. However, when the model is trained from scratch, it suffers from slow convergence speeds. In this paper, we look to take advantage of this formulation of reinforcement learning as sequence modeling and investigate the transferability of pre-trained sequence models on other domains (vision, language) when finetuned on offline RL tasks (control, games). To this end, we also propose techniques to improve transfer between these domains. Results show consistent performance gains in terms of both convergence speed and reward on a variety of environments, accelerating training by 3-6x and achieving state-of-the-art performance in a variety of tasks using Wikipedia-pretrained and GPT2 language models. We hope that this work not only brings light to the potentials of leveraging generic sequence modeling techniques and pre-trained models for RL, but also inspires future work on sharing knowledge between generative modeling tasks of completely different domains.
AfroMT: Pretraining Strategies and Reproducible Benchmarks for Translation of 8 African Languages
Sep 10, 2021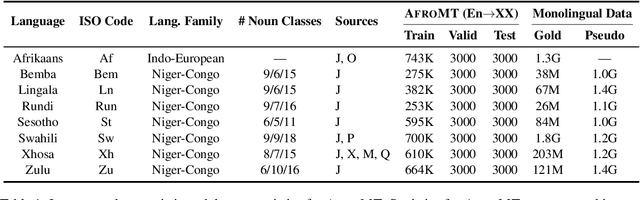
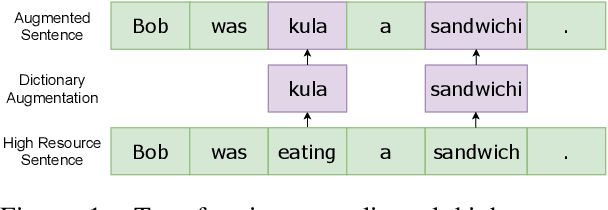
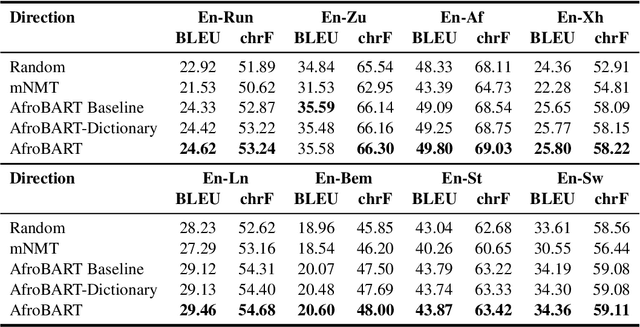
Reproducible benchmarks are crucial in driving progress of machine translation research. However, existing machine translation benchmarks have been mostly limited to high-resource or well-represented languages. Despite an increasing interest in low-resource machine translation, there are no standardized reproducible benchmarks for many African languages, many of which are used by millions of speakers but have less digitized textual data. To tackle these challenges, we propose AfroMT, a standardized, clean, and reproducible machine translation benchmark for eight widely spoken African languages. We also develop a suite of analysis tools for system diagnosis taking into account the unique properties of these languages. Furthermore, we explore the newly considered case of low-resource focused pretraining and develop two novel data augmentation-based strategies, leveraging word-level alignment information and pseudo-monolingual data for pretraining multilingual sequence-to-sequence models. We demonstrate significant improvements when pretraining on 11 languages, with gains of up to 2 BLEU points over strong baselines. We also show gains of up to 12 BLEU points over cross-lingual transfer baselines in data-constrained scenarios. All code and pretrained models will be released as further steps towards larger reproducible benchmarks for African languages.
PARADISE: Exploiting Parallel Data for Multilingual Sequence-to-Sequence Pretraining
Aug 04, 2021

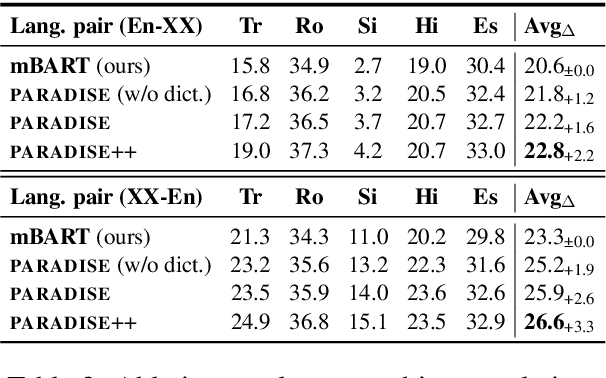
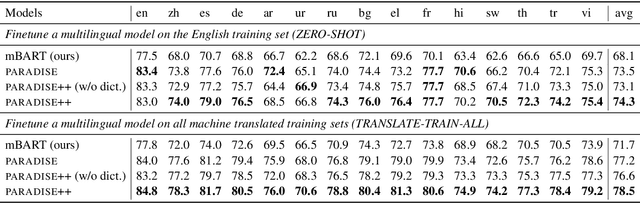
Despite the success of multilingual sequence-to-sequence pretraining, most existing approaches rely on monolingual corpora, and do not make use of the strong cross-lingual signal contained in parallel data. In this paper, we present PARADISE (PARAllel & Denoising Integration in SEquence-to-sequence models), which extends the conventional denoising objective used to train these models by (i) replacing words in the noised sequence according to a multilingual dictionary, and (ii) predicting the reference translation according to a parallel corpus instead of recovering the original sequence. Our experiments on machine translation and cross-lingual natural language inference show an average improvement of 2.0 BLEU points and 6.7 accuracy points from integrating parallel data into pretraining, respectively, obtaining results that are competitive with several popular models at a fraction of their computational cost.
LEWIS: Levenshtein Editing for Unsupervised Text Style Transfer
May 18, 2021
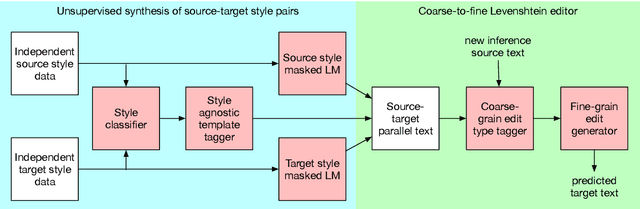
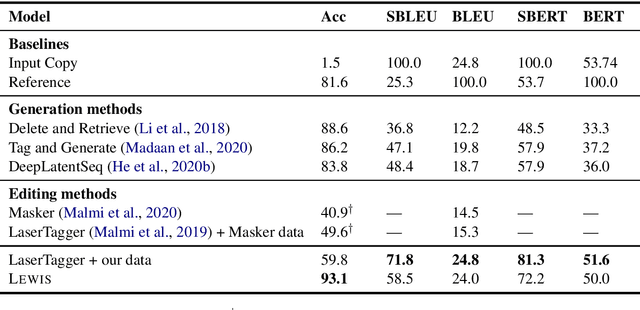

Many types of text style transfer can be achieved with only small, precise edits (e.g. sentiment transfer from I had a terrible time... to I had a great time...). We propose a coarse-to-fine editor for style transfer that transforms text using Levenshtein edit operations (e.g. insert, replace, delete). Unlike prior single-span edit methods, our method concurrently edits multiple spans in the source text. To train without parallel style text pairs (e.g. pairs of +/- sentiment statements), we propose an unsupervised data synthesis procedure. We first convert text to style-agnostic templates using style classifier attention (e.g. I had a SLOT time...), then fill in slots in these templates using fine-tuned pretrained language models. Our method outperforms existing generation and editing style transfer methods on sentiment (Yelp, Amazon) and politeness (Polite) transfer. In particular, multi-span editing achieves higher performance and more diverse output than single-span editing. Moreover, compared to previous methods on unsupervised data synthesis, our method results in higher quality parallel style pairs and improves model performance.
Subformer: Exploring Weight Sharing for Parameter Efficiency in Generative Transformers
Jan 01, 2021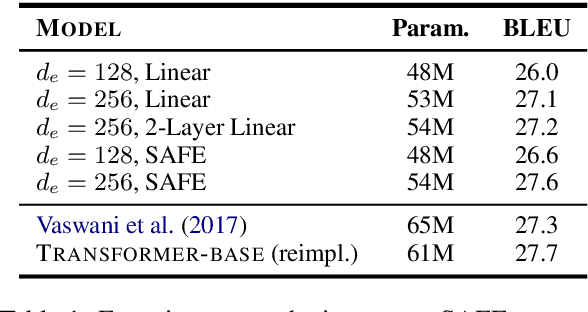
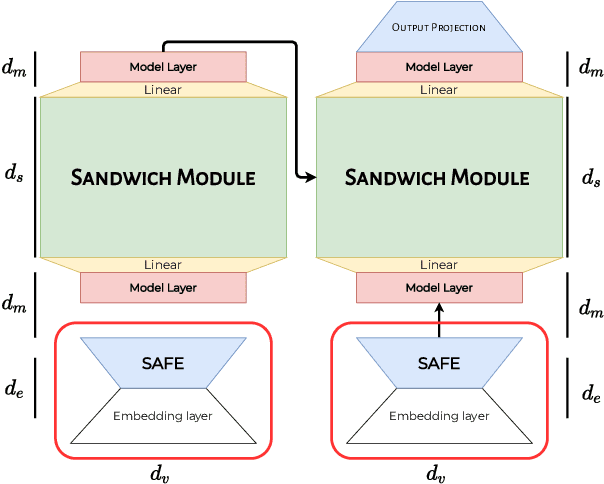
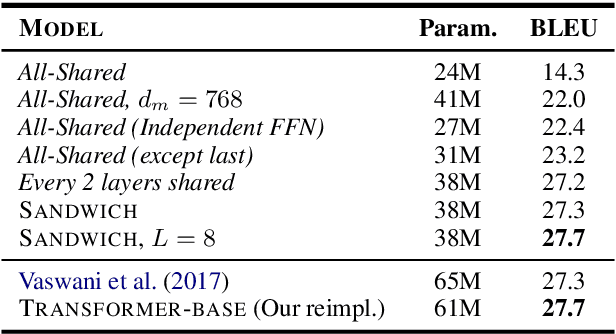

The advent of the Transformer can arguably be described as a driving force behind many of the recent advances in natural language processing. However, despite their sizeable performance improvements, as recently shown, the model is severely over-parameterized, being parameter inefficient and computationally expensive to train. Inspired by the success of parameter-sharing in pretrained deep contextualized word representation encoders, we explore parameter-sharing methods in Transformers, with a specific focus on encoder-decoder models for sequence-to-sequence tasks such as neural machine translation. We perform an analysis of different parameter sharing/reduction methods and develop the Subformer, a parameter efficient Transformer-based model which combines the newly proposed Sandwich-style parameter sharing technique - designed to overcome the deficiencies in naive cross-layer parameter sharing for generative models - and self-attentive embedding factorization (SAFE). Experiments on machine translation, abstractive summarization, and language modeling show that the Subformer can outperform the Transformer even when using significantly fewer parameters.
VCDM: Leveraging Variational Bi-encoding and Deep Contextualized Word Representations for Improved Definition Modeling
Oct 07, 2020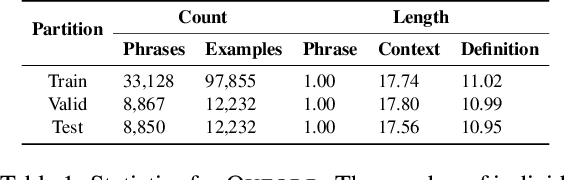
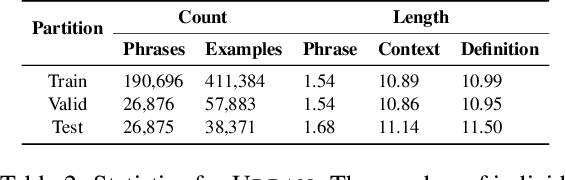
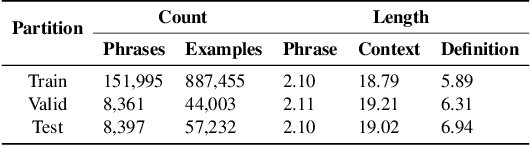

In this paper, we tackle the task of definition modeling, where the goal is to learn to generate definitions of words and phrases. Existing approaches for this task are discriminative, combining distributional and lexical semantics in an implicit rather than direct way. To tackle this issue we propose a generative model for the task, introducing a continuous latent variable to explicitly model the underlying relationship between a phrase used within a context and its definition. We rely on variational inference for estimation and leverage contextualized word embeddings for improved performance. Our approach is evaluated on four existing challenging benchmarks with the addition of two new datasets, "Cambridge" and the first non-English corpus "Robert", which we release to complement our empirical study. Our Variational Contextual Definition Modeler (VCDM) achieves state-of-the-art performance in terms of automatic and human evaluation metrics, demonstrating the effectiveness of our approach.
Variational Inference for Learning Representations of Natural Language Edits
May 18, 2020
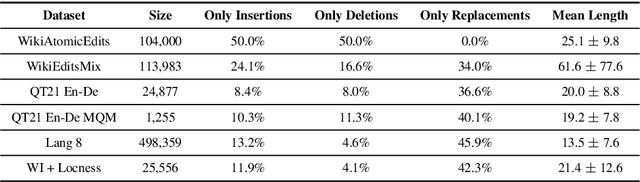
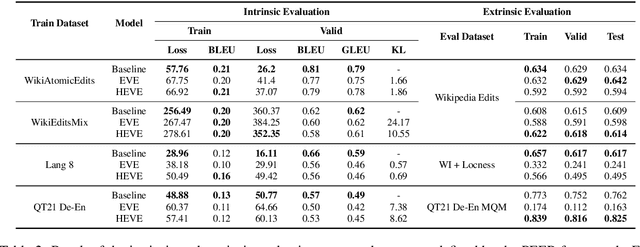
Document editing has become a pervasive component of production of information, with version control systems enabling edits to be efficiently stored and applied. In light of this, the task of learning distributed representations of edits has been recently proposed. With this in mind, we propose a novel approach that employs variational inference to learn a continuous latent space of vector representations to capture the underlying semantic information with regard to the document editing process. We achieve this by introducing a latent variable to explicitly model the aforementioned features. This latent variable is then combined with a document representation to guide the generation of an edited-version of this document. Additionally, to facilitate standardized automatic evaluation of edit representations, which has heavily relied on direct human input thus far, we also propose a suite of downstream tasks, PEER, specifically designed to measure the quality of edit representations in the context of Natural Language Processing.
Combining Pretrained High-Resource Embeddings and Subword Representations for Low-Resource Languages
Mar 11, 2020
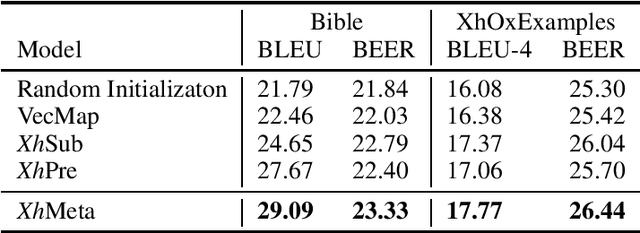
The contrast between the need for large amounts of data for current Natural Language Processing (NLP) techniques, and the lack thereof, is accentuated in the case of African languages, most of which are considered low-resource. To help circumvent this issue, we explore techniques exploiting the qualities of morphologically rich languages (MRLs), while leveraging pretrained word vectors in well-resourced languages. In our exploration, we show that a meta-embedding approach combining both pretrained and morphologically-informed word embeddings performs best in the downstream task of Xhosa-English translation.