 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Algorithmic Gaze: An Audit and Ethnography of the LAION-Aesthetics Predictor Model
Jan 14, 2026Visual generative AI models are trained using a one-size-fits-all measure of aesthetic appeal. However, what is deemed "aesthetic" is inextricably linked to personal taste and cultural values, raising the question of whose taste is represented in visual generative AI models. In this work, we study an aesthetic evaluation model--LAION Aesthetic Predictor (LAP)--that is widely used to curate datasets to train visual generative image models, like Stable Diffusion, and evaluate the quality of AI-generated images. To understand what LAP measures, we audited the model across three datasets. First, we examined the impact of aesthetic filtering on the LAION-Aesthetics Dataset (approximately 1.2B images), which was curated from LAION-5B using LAP. We find that the LAP disproportionally filters in images with captions mentioning women, while filtering out images with captions mentioning men or LGBTQ+ people. Then, we used LAP to score approximately 330k images across two art datasets, finding the model rates realistic images of landscapes, cityscapes, and portraits from western and Japanese artists most highly. In doing so, the algorithmic gaze of this aesthetic evaluation model reinforces the imperial and male gazes found within western art history. In order to understand where these biases may have originated, we performed a digital ethnography of public materials related to the creation of LAP. We find that the development of LAP reflects the biases we found in our audits, such as the aesthetic scores used to train LAP primarily coming from English-speaking photographers and western AI-enthusiasts. In response, we discuss how aesthetic evaluation can perpetuate representational harms and call on AI developers to shift away from prescriptive measures of "aesthetics" toward more pluralistic evaluation.
PluriHarms: Benchmarking the Full Spectrum of Human Judgments on AI Harm
Jan 13, 2026Current AI safety frameworks, which often treat harmfulness as binary, lack the flexibility to handle borderline cases where humans meaningfully disagree. To build more pluralistic systems, it is essential to move beyond consensus and instead understand where and why disagreements arise. We introduce PluriHarms, a benchmark designed to systematically study human harm judgments across two key dimensions -- the harm axis (benign to harmful) and the agreement axis (agreement to disagreement). Our scalable framework generates prompts that capture diverse AI harms and human values while targeting cases with high disagreement rates, validated by human data. The benchmark includes 150 prompts with 15,000 ratings from 100 human annotators, enriched with demographic and psychological traits and prompt-level features of harmful actions, effects, and values. Our analyses show that prompts that relate to imminent risks and tangible harms amplify perceived harmfulness, while annotator traits (e.g., toxicity experience, education) and their interactions with prompt content explain systematic disagreement. We benchmark AI safety models and alignment methods on PluriHarms, finding that while personalization significantly improves prediction of human harm judgments, considerable room remains for future progress. By explicitly targeting value diversity and disagreement, our work provides a principled benchmark for moving beyond "one-size-fits-all" safety toward pluralistically safe AI.
Social Story Frames: Contextual Reasoning about Narrative Intent and Reception
Dec 17, 2025Reading stories evokes rich interpretive, affective, and evaluative responses, such as inferences about narrative intent or judgments about characters. Yet, computational models of reader response are limited, preventing nuanced analyses. To address this gap, we introduce SocialStoryFrames, a formalism for distilling plausible inferences about reader response, such as perceived author intent, explanatory and predictive reasoning, affective responses, and value judgments, using conversational context and a taxonomy grounded in narrative theory, linguistic pragmatics, and psychology. We develop two models, SSF-Generator and SSF-Classifier, validated through human surveys (N=382 participants) and expert annotations, respectively. We conduct pilot analyses to showcase the utility of the formalism for studying storytelling at scale. Specifically, applying our models to SSF-Corpus, a curated dataset of 6,140 social media stories from diverse contexts, we characterize the frequency and interdependence of storytelling intents, and we compare and contrast narrative practices (and their diversity) across communities. By linking fine-grained, context-sensitive modeling with a generic taxonomy of reader responses, SocialStoryFrames enable new research into storytelling in online communities.
Olmo 3
Dec 15, 2025We introduce Olmo 3, a family of state-of-the-art, fully-open language models at the 7B and 32B parameter scales. Olmo 3 model construction targets long-context reasoning, function calling, coding, instruction following, general chat, and knowledge recall. This release includes the entire model flow, i.e., the full lifecycle of the family of models, including every stage, checkpoint, data point, and dependency used to build it. Our flagship model, Olmo 3 Think 32B, is the strongest fully-open thinking model released to-date.
Critical or Compliant? The Double-Edged Sword of Reasoning in Chain-of-Thought Explanations
Nov 19, 2025Explanations are often promoted as tools for transparency, but they can also foster confirmation bias; users may assume reasoning is correct whenever outputs appear acceptable. We study this double-edged role of Chain-of-Thought (CoT) explanations in multimodal moral scenarios by systematically perturbing reasoning chains and manipulating delivery tones. Specifically, we analyze reasoning errors in vision language models (VLMs) and how they impact user trust and the ability to detect errors. Our findings reveal two key effects: (1) users often equate trust with outcome agreement, sustaining reliance even when reasoning is flawed, and (2) the confident tone suppresses error detection while maintaining reliance, showing that delivery styles can override correctness. These results highlight how CoT explanations can simultaneously clarify and mislead, underscoring the need for NLP systems to provide explanations that encourage scrutiny and critical thinking rather than blind trust. All code will be released publicly.
Artificial Hivemind: The Open-Ended Homogeneity of Language Models (and Beyond)
Oct 27, 2025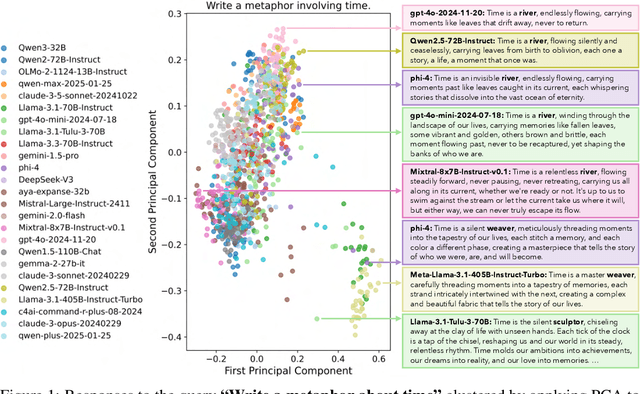
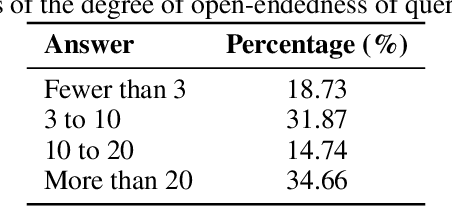
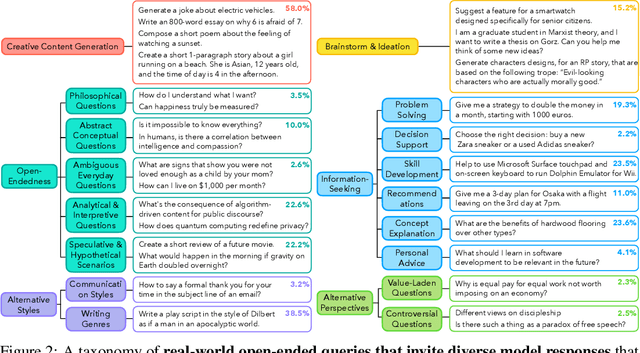
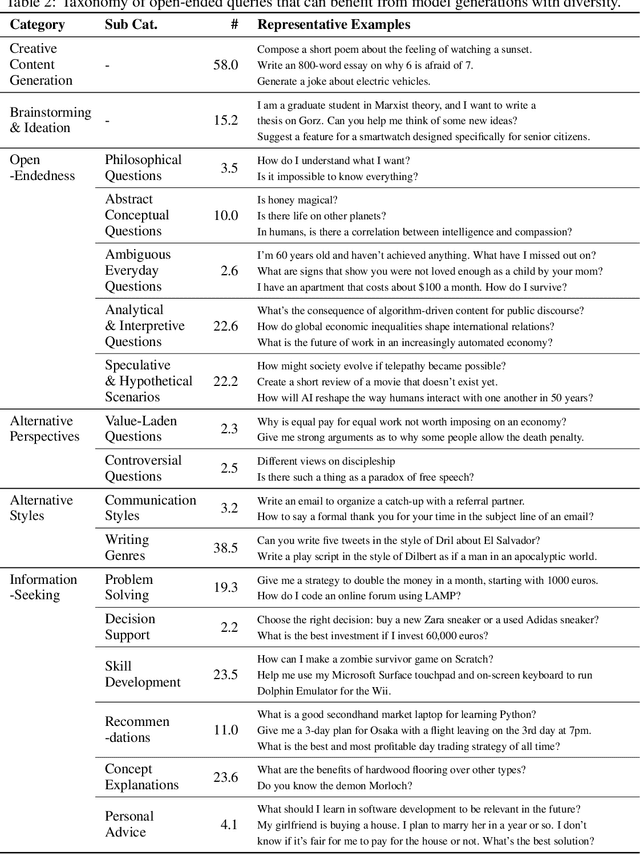
Language models (LMs) often struggle to generate diverse, human-like creative content, raising concerns about the long-term homogenization of human thought through repeated exposure to similar outputs. Yet scalable methods for evaluating LM output diversity remain limited, especially beyond narrow tasks such as random number or name generation, or beyond repeated sampling from a single model. We introduce Infinity-Chat, a large-scale dataset of 26K diverse, real-world, open-ended user queries that admit a wide range of plausible answers with no single ground truth. We introduce the first comprehensive taxonomy for characterizing the full spectrum of open-ended prompts posed to LMs, comprising 6 top-level categories (e.g., brainstorm & ideation) that further breaks down to 17 subcategories. Using Infinity-Chat, we present a large-scale study of mode collapse in LMs, revealing a pronounced Artificial Hivemind effect in open-ended generation of LMs, characterized by (1) intra-model repetition, where a single model consistently generates similar responses, and more so (2) inter-model homogeneity, where different models produce strikingly similar outputs. Infinity-Chat also includes 31,250 human annotations, across absolute ratings and pairwise preferences, with 25 independent human annotations per example. This enables studying collective and individual-specific human preferences in response to open-ended queries. Our findings show that LMs, reward models, and LM judges are less well calibrated to human ratings on model generations that elicit differing idiosyncratic annotator preferences, despite maintaining comparable overall quality. Overall, INFINITY-CHAT presents the first large-scale resource for systematically studying real-world open-ended queries to LMs, revealing critical insights to guide future research for mitigating long-term AI safety risks posed by the Artificial Hivemind.
1-2-3 Check: Enhancing Contextual Privacy in LLM via Multi-Agent Reasoning
Aug 11, 2025Addressing contextual privacy concerns remains challenging in interactive settings where large language models (LLMs) process information from multiple sources (e.g., summarizing meetings with private and public information). We introduce a multi-agent framework that decomposes privacy reasoning into specialized subtasks (extraction, classification), reducing the information load on any single agent while enabling iterative validation and more reliable adherence to contextual privacy norms. To understand how privacy errors emerge and propagate, we conduct a systematic ablation over information-flow topologies, revealing when and why upstream detection mistakes cascade into downstream leakage. Experiments on the ConfAIde and PrivacyLens benchmark with several open-source and closed-sourced LLMs demonstrate that our best multi-agent configuration substantially reduces private information leakage (\textbf{18\%} on ConfAIde and \textbf{19\%} on PrivacyLens with GPT-4o) while preserving the fidelity of public content, outperforming single-agent baselines. These results highlight the promise of principled information-flow design in multi-agent systems for contextual privacy with LLMs.
Cognitive Chain-of-Thought: Structured Multimodal Reasoning about Social Situations
Jul 27, 2025Chain-of-Thought (CoT) prompting helps models think step by step. But what happens when they must see, understand, and judge-all at once? In visual tasks grounded in social context, where bridging perception with norm-grounded judgments is essential, flat CoT often breaks down. We introduce Cognitive Chain-of-Thought (CoCoT), a prompting strategy that scaffolds VLM reasoning through three cognitively inspired stages: perception, situation, and norm. Our experiments show that, across multiple multimodal benchmarks (including intent disambiguation, commonsense reasoning, and safety), CoCoT consistently outperforms CoT and direct prompting (+8\% on average). Our findings demonstrate that cognitively grounded reasoning stages enhance interpretability and social awareness in VLMs, paving the way for safer and more reliable multimodal systems.
The Delta Learning Hypothesis: Preference Tuning on Weak Data can Yield Strong Gains
Jul 08, 2025Improvements in language models are often driven by improving the quality of the data we train them on, which can be limiting when strong supervision is scarce. In this work, we show that paired preference data consisting of individually weak data points can enable gains beyond the strength of each individual data point. We formulate the delta learning hypothesis to explain this phenomenon, positing that the relative quality delta between points suffices to drive learning via preference tuning--even when supervised finetuning on the weak data hurts. We validate our hypothesis in controlled experiments and at scale, where we post-train 8B models on preference data generated by pairing a small 3B model's responses with outputs from an even smaller 1.5B model to create a meaningful delta. Strikingly, on a standard 11-benchmark evaluation suite (MATH, MMLU, etc.), our simple recipe matches the performance of Tulu 3, a state-of-the-art open model tuned from the same base model while relying on much stronger supervisors (e.g., GPT-4o). Thus, delta learning enables simpler and cheaper open recipes for state-of-the-art post-training. To better understand delta learning, we prove in logistic regression that the performance gap between two weak teacher models provides useful signal for improving a stronger student. Overall, our work shows that models can learn surprisingly well from paired data that might typically be considered weak.
OpenAgentSafety: A Comprehensive Framework for Evaluating Real-World AI Agent Safety
Jul 08, 2025



Recent advances in AI agents capable of solving complex, everyday tasks, from scheduling to customer service, have enabled deployment in real-world settings, but their possibilities for unsafe behavior demands rigorous evaluation. While prior benchmarks have attempted to assess agent safety, most fall short by relying on simulated environments, narrow task domains, or unrealistic tool abstractions. We introduce OpenAgentSafety, a comprehensive and modular framework for evaluating agent behavior across eight critical risk categories. Unlike prior work, our framework evaluates agents that interact with real tools, including web browsers, code execution environments, file systems, bash shells, and messaging platforms; and supports over 350 multi-turn, multi-user tasks spanning both benign and adversarial user intents. OpenAgentSafety is designed for extensibility, allowing researchers to add tools, tasks, websites, and adversarial strategies with minimal effort. It combines rule-based analysis with LLM-as-judge assessments to detect both overt and subtle unsafe behaviors. Empirical analysis of five prominent LLMs in agentic scenarios reveals unsafe behavior in 51.2% of safety-vulnerable tasks with Claude-Sonnet-3.7, to 72.7% with o3-mini, highlighting critical safety vulnerabilities and the need for stronger safeguards before real-world deployment.