 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinking Knowledge to Care: Knowledge Graph-Augmented Medical Follow-Up Question Generation
Mar 01, 2026Clinical diagnosis is time-consuming, requiring intensive interactions between patients and medical professionals. While large language models (LLMs) could ease the pre-diagnostic workload, their limited domain knowledge hinders effective medical question generation. We introduce a Knowledge Graph-augmented LLM with active in-context learning to generate relevant and important follow-up questions, KG-Followup, serving as a critical module for the pre-diagnostic assessment. The structured medical domain knowledge graph serves as a seamless patch-up to provide professional domain expertise upon which the LLM can reason. Experiments demonstrate that KG-Followup outperforms state-of-the-art methods by 5% - 8% on relevant benchmarks in recall.
1-2-3 Check: Enhancing Contextual Privacy in LLM via Multi-Agent Reasoning
Aug 11, 2025Addressing contextual privacy concerns remains challenging in interactive settings where large language models (LLMs) process information from multiple sources (e.g., summarizing meetings with private and public information). We introduce a multi-agent framework that decomposes privacy reasoning into specialized subtasks (extraction, classification), reducing the information load on any single agent while enabling iterative validation and more reliable adherence to contextual privacy norms. To understand how privacy errors emerge and propagate, we conduct a systematic ablation over information-flow topologies, revealing when and why upstream detection mistakes cascade into downstream leakage. Experiments on the ConfAIde and PrivacyLens benchmark with several open-source and closed-sourced LLMs demonstrate that our best multi-agent configuration substantially reduces private information leakage (\textbf{18\%} on ConfAIde and \textbf{19\%} on PrivacyLens with GPT-4o) while preserving the fidelity of public content, outperforming single-agent baselines. These results highlight the promise of principled information-flow design in multi-agent systems for contextual privacy with LLMs.
Fact-Aware Multimodal Retrieval Augmentation for Accurate Medical Radiology Report Generation
Jul 21, 2024



Multimodal foundation models hold significant potential for automating radiology report generation, thereby assisting clinicians in diagnosing cardiac diseases. However, generated reports often suffer from serious factual inaccuracy. In this paper, we introduce a fact-aware multimodal retrieval-augmented pipeline in generating accurate radiology reports (FactMM-RAG). We first leverage RadGraph to mine factual report pairs, then integrate factual knowledge to train a universal multimodal retriever. Given a radiology image, our retriever can identify high-quality reference reports to augment multimodal foundation models, thus enhancing the factual completeness and correctness of report generation. Experiments on two benchmark datasets show that our multimodal retriever outperforms state-of-the-art retrievers on both language generation and radiology-specific metrics, up to 6.5% and 2% score in F1CheXbert and F1RadGraph. Further analysis indicates that employing our factually-informed training strategy imposes an effective supervision signal, without relying on explicit diagnostic label guidance, and successfully propagates fact-aware capabilities from the multimodal retriever to the multimodal foundation model in radiology report generation.
ED-Copilot: Reduce Emergency Department Wait Time with Language Model Diagnostic Assistance
Feb 21, 2024In the emergency department (ED), patients undergo triage and multiple laboratory tests before diagnosis. This process is time-consuming, and causes ED crowding which significantly impacts patient mortality, medical errors, staff burnout, etc. This work proposes (time) cost-effective diagnostic assistance that explores the potential of artificial intelligence (AI) systems in assisting ED clinicians to make time-efficient and accurate diagnoses. Using publicly available patient data, we collaborate with ED clinicians to curate MIMIC-ED-Assist, a benchmark that measures the ability of AI systems in suggesting laboratory tests that minimize ED wait times, while correctly predicting critical outcomes such as death. We develop ED-Copilot which sequentially suggests patient-specific laboratory tests and makes diagnostic predictions. ED-Copilot uses a pre-trained bio-medical language model to encode patient information and reinforcement learning to minimize ED wait time and maximize prediction accuracy of critical outcomes. On MIMIC-ED-Assist, ED-Copilot improves prediction accuracy over baselines while halving average wait time from four hours to two hours. Ablation studies demonstrate the importance of model scale and use of a bio-medical language model. Further analyses reveal the necessity of personalized laboratory test suggestions for diagnosing patients with severe cases, as well as the potential of ED-Copilot in providing ED clinicians with informative laboratory test recommendations. Our code is available at https://github.com/cxcscmu/ED-Copilot.
Few-shot Text Classification with Dual Contrastive Consistency
Sep 29, 2022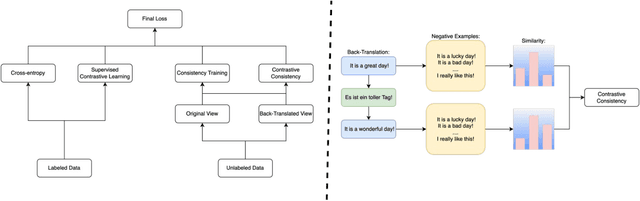
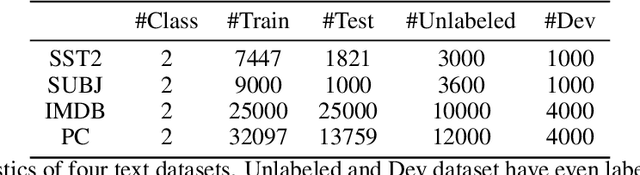
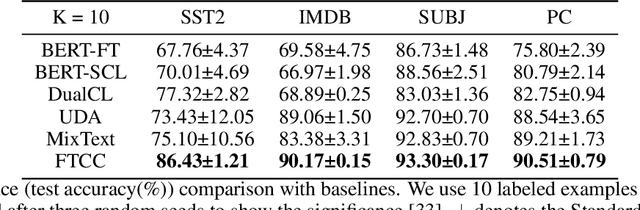

In this paper, we explore how to utilize pre-trained language model to perform few-shot text classification where only a few annotated examples are given for each class. Since using traditional cross-entropy loss to fine-tune language model under this scenario causes serious overfitting and leads to sub-optimal generalization of model, we adopt supervised contrastive learning on few labeled data and consistency-regularization on vast unlabeled data. Moreover, we propose a novel contrastive consistency to further boost model performance and refine sentence representation. After conducting extensive experiments on four datasets, we demonstrate that our model (FTCC) can outperform state-of-the-art methods and has better robustness.