 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMOSAIC: Modular Orchestration for Structured Agentic Intelligence and Composition
May 30, 2026Automated data science is a structured model-selection problem. A solution must choose data transformations, feature representations, architecture, training procedure, evaluation protocol, and refinement strategy for a task. AutoML systems automate parts of this process, but typically search within predefined pipeline, model, and hyperparameter spaces. LLM-based agents offer greater flexibility through retrieval, code generation, and execution feedback, yet their modelling decisions are often unstructured, difficult to verify, and hard to reuse. We introduce \textsc{MOSAIC} (Modular Orchestration for Structured Agentic Intelligence and Composition), a structured agentic framework for memory-grounded model selection and workflow construction. Given a task and dataset, \textsc{MOSAIC} builds a semantic task profile, retrieves prior cases and source-code modules, and constructs a blueprint: an intermediate representation specifying selected modelling components, composition, interface constraints, and execution requirements. This blueprint turns model selection into a staged, context-grounded search and grounds LLM-based code generation in retrieved evidence rather than unconstrained synthesis. Candidate models are validated by execution and refined using diagnostic feedback, training traces, task metrics, and a failure-aware reinforcement learning policy. We instantiate \textsc{MOSAIC} on financial time-series forecasting and generation, where models must satisfy predictive accuracy, distributional fidelity, execution reliability, and downstream financial criteria such as risk and tail behaviour. Experiments against AutoML and agentic baselines show that \textsc{MOSAIC} improves task performance, execution success, and decision traceability, demonstrating the value of treating automated data science as structured, reusable, and execution-grounded model selection.
Global linear convergence of entropy-regularized softmax policy gradient beyond tabular MDPs
May 24, 2026We study the global convergence of policy gradient for infinite-horizon entropy-regularized Markov decision processes (MDPs) with continuous state and action spaces. We consider log-linear softmax policies with linear function approximation, which extend the tabular softmax parameterization while retaining a tractable policy class. Under $Q^π_τ$-realizability for the regularized state-action value function, we first establish a non-uniform Polyak--Łojasiewicz (PŁ) inequality. The non-uniformity arises through degeneracy of constants associated with the policy geometry, namely the Fisher information matrix or an uncentered feature covariance matrix. We then identify two feature regimes under which this non-uniform constant can be bounded along the gradient flow. For full-affine-span features, we prove radial unboundedness of the KL regularizer and show that the smallest eigenvalue of the Fisher information matrix remains bounded below by an initialization-dependent positive constant. For simplex-valued features, we prove an analogous radial unboundedness result in the subspace orthogonal to the all-ones vector and obtain a uniform lower bound for the smallest eigenvalue of the uncentered covariance matrix. These results imply global linear convergence of the regularized objective along the gradient flow, i.e. suboptimality decaying as $\mathcal{O}(e^{-Ct})$ for some $C>0$. Our analysis extends the global convergence theory of entropy-regularized softmax policy gradient beyond the tabular setting of Agarwal et al. (2020); Bhandari and Russo (2024); Mei et al. (2020).
Individualised Counterfactual Examples Using Conformal Prediction Intervals
May 28, 2025



Counterfactual explanations for black-box models aim to pr ovide insight into an algorithmic decision to its recipient. For a binary classification problem an individual counterfactual details which features might be changed for the model to infer the opposite class. High-dimensional feature spaces that are typical of machine learning classification models admit many possible counterfactual examples to a decision, and so it is important to identify additional criteria to select the most useful counterfactuals. In this paper, we explore the idea that the counterfactuals should be maximally informative when considering the knowledge of a specific individual about the underlying classifier. To quantify this information gain we explicitly model the knowledge of the individual, and assess the uncertainty of predictions which the individual makes by the width of a conformal prediction interval. Regions of feature space where the prediction interval is wide correspond to areas where the confidence in decision making is low, and an additional counterfactual example might be more informative to an individual. To explore and evaluate our individualised conformal prediction interval counterfactuals (CPICFs), first we present a synthetic data set on a hypercube which allows us to fully visualise the decision boundary, conformal intervals via three different methods, and resultant CPICFs. Second, in this synthetic data set we explore the impact of a single CPICF on the knowledge of an individual locally around the original query. Finally, in both our synthetic data set and a complex real world dataset with a combination of continuous and discrete variables, we measure the utility of these counterfactuals via data augmentation, testing the performance on a held out set.
$ε$-Policy Gradient for Online Pricing
May 06, 2024Combining model-based and model-free reinforcement learning approaches, this paper proposes and analyzes an $\epsilon$-policy gradient algorithm for the online pricing learning task. The algorithm extends $\epsilon$-greedy algorithm by replacing greedy exploitation with gradient descent step and facilitates learning via model inference. We optimize the regret of the proposed algorithm by quantifying the exploration cost in terms of the exploration probability $\epsilon$ and the exploitation cost in terms of the gradient descent optimization and gradient estimation errors. The algorithm achieves an expected regret of order $\mathcal{O}(\sqrt{T})$ (up to a logarithmic factor) over $T$ trials.
A Fisher-Rao gradient flow for entropy-regularised Markov decision processes in Polish spaces
Oct 04, 2023We study the global convergence of a Fisher-Rao policy gradient flow for infinite-horizon entropy-regularised Markov decision processes with Polish state and action space. The flow is a continuous-time analogue of a policy mirror descent method. We establish the global well-posedness of the gradient flow and demonstrate its exponential convergence to the optimal policy. Moreover, we prove the flow is stable with respect to gradient evaluation, offering insights into the performance of a natural policy gradient flow with log-linear policy parameterisation. To overcome challenges stemming from the lack of the convexity of the objective function and the discontinuity arising from the entropy regulariser, we leverage the performance difference lemma and the duality relationship between the gradient and mirror descent flows.
The AI Revolution: Opportunities and Challenges for the Finance Sector
Aug 31, 2023This report examines Artificial Intelligence (AI) in the financial sector, outlining its potential to revolutionise the industry and identify its challenges. It underscores the criticality of a well-rounded understanding of AI, its capabilities, and its implications to effectively leverage its potential while mitigating associated risks. The potential of AI potential extends from augmenting existing operations to paving the way for novel applications in the finance sector. The application of AI in the financial sector is transforming the industry. Its use spans areas from customer service enhancements, fraud detection, and risk management to credit assessments and high-frequency trading. However, along with these benefits, AI also presents several challenges. These include issues related to transparency, interpretability, fairness, accountability, and trustworthiness. The use of AI in the financial sector further raises critical questions about data privacy and security. A further issue identified in this report is the systemic risk that AI can introduce to the financial sector. Being prone to errors, AI can exacerbate existing systemic risks, potentially leading to financial crises. Regulation is crucial to harnessing the benefits of AI while mitigating its potential risks. Despite the global recognition of this need, there remains a lack of clear guidelines or legislation for AI use in finance. This report discusses key principles that could guide the formation of effective AI regulation in the financial sector, including the need for a risk-based approach, the inclusion of ethical considerations, and the importance of maintaining a balance between innovation and consumer protection. The report provides recommendations for academia, the finance industry, and regulators.
Insurance pricing on price comparison websites via reinforcement learning
Aug 14, 2023

The emergence of price comparison websites (PCWs) has presented insurers with unique challenges in formulating effective pricing strategies. Operating on PCWs requires insurers to strike a delicate balance between competitive premiums and profitability, amidst obstacles such as low historical conversion rates, limited visibility of competitors' actions, and a dynamic market environment. In addition to this, the capital intensive nature of the business means pricing below the risk levels of customers can result in solvency issues for the insurer. To address these challenges, this paper introduces reinforcement learning (RL) framework that learns the optimal pricing policy by integrating model-based and model-free methods. The model-based component is used to train agents in an offline setting, avoiding cold-start issues, while model-free algorithms are then employed in a contextual bandit (CB) manner to dynamically update the pricing policy to maximise the expected revenue. This facilitates quick adaptation to evolving market dynamics and enhances algorithm efficiency and decision interpretability. The paper also highlights the importance of evaluating pricing policies using an offline dataset in a consistent fashion and demonstrates the superiority of the proposed methodology over existing off-the-shelf RL/CB approaches. We validate our methodology using synthetic data, generated to reflect private commercially available data within real-world insurers, and compare against 6 other benchmark approaches. Our hybrid agent outperforms these benchmarks in terms of sample efficiency and cumulative reward with the exception of an agent that has access to perfect market information which would not be available in a real-world set-up.
TAPAS: a Toolbox for Adversarial Privacy Auditing of Synthetic Data
Nov 12, 2022
Personal data collected at scale promises to improve decision-making and accelerate innovation. However, sharing and using such data raises serious privacy concerns. A promising solution is to produce synthetic data, artificial records to share instead of real data. Since synthetic records are not linked to real persons, this intuitively prevents classical re-identification attacks. However, this is insufficient to protect privacy. We here present TAPAS, a toolbox of attacks to evaluate synthetic data privacy under a wide range of scenarios. These attacks include generalizations of prior works and novel attacks. We also introduce a general framework for reasoning about privacy threats to synthetic data and showcase TAPAS on several examples.
Optimal scheduling of entropy regulariser for continuous-time linear-quadratic reinforcement learning
Aug 11, 2022This work uses the entropy-regularised relaxed stochastic control perspective as a principled framework for designing reinforcement learning (RL) algorithms. Herein agent interacts with the environment by generating noisy controls distributed according to the optimal relaxed policy. The noisy policies, on the one hand, explore the space and hence facilitate learning but, on the other hand, introduce bias by assigning a positive probability to non-optimal actions. This exploration-exploitation trade-off is determined by the strength of entropy regularisation. We study algorithms resulting from two entropy regularisation formulations: the exploratory control approach, where entropy is added to the cost objective, and the proximal policy update approach, where entropy penalises the divergence of policies between two consecutive episodes. We analyse the finite horizon continuous-time linear-quadratic (LQ) RL problem for which both algorithms yield a Gaussian relaxed policy. We quantify the precise difference between the value functions of a Gaussian policy and its noisy evaluation and show that the execution noise must be independent across time. By tuning the frequency of sampling from relaxed policies and the parameter governing the strength of entropy regularisation, we prove that the regret, for both learning algorithms, is of the order $\mathcal{O}(\sqrt{N}) $ (up to a logarithmic factor) over $N$ episodes, matching the best known result from the literature.
Synthetic Data -- what, why and how?
May 06, 2022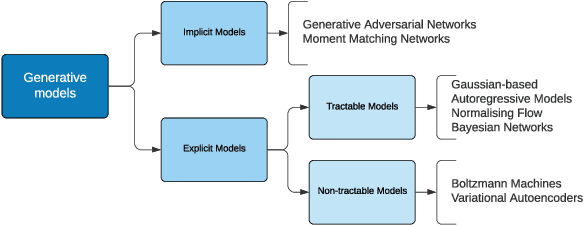
This explainer document aims to provide an overview of the current state of the rapidly expanding work on synthetic data technologies, with a particular focus on privacy. The article is intended for a non-technical audience, though some formal definitions have been given to provide clarity to specialists. This article is intended to enable the reader to quickly become familiar with the notion of synthetic data, as well as understand some of the subtle intricacies that come with it. We do believe that synthetic data is a very useful tool, and our hope is that this report highlights that, while drawing attention to nuances that can easily be overlooked in its deployment.