 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Hilbert--Galerkin Methods for Infinite-Dimensional PDEs and Optimal Control
Mar 19, 2026We develop deep learning-based approximation methods for fully nonlinear second-order PDEs on separable Hilbert spaces, such as HJB equations for infinite-dimensional control, by parameterizing solutions via Hilbert--Galerkin Neural Operators (HGNOs). We prove the first Universal Approximation Theorems (UATs) which are sufficiently powerful to address these problems, based on novel topologies for Hessian terms and corresponding novel continuity assumptions on the fully nonlinear operator. These topologies are non-sequential and non-metrizable, making the problem delicate. In particular, we prove UATs for functions on Hilbert spaces, together with their Fréchet derivatives up to second order, and for unbounded operators applied to the first derivative, ensuring that HGNOs are able to approximate all the PDE terms. For control problems, we further prove UATs for optimal feedback controls in terms of our approximating value function HGNO. We develop numerical training methods, which we call Deep Hilbert--Galerkin and Hilbert Actor-Critic (reinforcement learning) Methods, for these problems by minimizing the $L^2_μ(H)$-norm of the residual of the PDE on the whole Hilbert space, not just a projected PDE to finite dimensions. This is the first paper to propose such an approach. The models considered arise in many applied sciences, such as functional differential equations in physics and Kolmogorov and HJB PDEs related to controlled PDEs, SPDEs, path-dependent systems, partially observed stochastic systems, and mean-field SDEs. We numerically solve examples of Kolmogorov and HJB PDEs related to the optimal control of deterministic and stochastic heat and Burgers' equations, demonstrating the promise of our deep learning-based approach.
The Exponentially Weighted Signature
Mar 19, 2026The signature is a canonical representation of a multidimensional path over an interval. However, it treats all historical information uniformly, offering no intrinsic mechanism for contextualising the relevance of the past. To address this, we introduce the Exponentially Weighted Signature (EWS), generalising the Exponentially Fading Memory (EFM) signature from diagonal to general bounded linear operators. These operators enable cross-channel coupling at the level of temporal weighting together with richer memory dynamics including oscillatory, growth, and regime-dependent behaviour, while preserving the algebraic strengths of the classical signature. We show that the EWS is the unique solution to a linear controlled differential equation on the tensor algebra, and that it generalises both state-space models and the Laplace and Fourier transforms of the path. The group-like structure of the EWS enables efficient computation and makes the framework amenable to gradient-based learning, with the full semigroup action parametrised by and learned through its generator. We use this framework to empirically demonstrate the expressivity gap between the EWS and both the signature and EFM on two SDE-based regression tasks.
Neural Actor-Critic Methods for Hamilton-Jacobi-Bellman PDEs: Asymptotic Analysis and Numerical Studies
Jul 08, 2025We mathematically analyze and numerically study an actor-critic machine learning algorithm for solving high-dimensional Hamilton-Jacobi-Bellman (HJB) partial differential equations from stochastic control theory. The architecture of the critic (the estimator for the value function) is structured so that the boundary condition is always perfectly satisfied (rather than being included in the training loss) and utilizes a biased gradient which reduces computational cost. The actor (the estimator for the optimal control) is trained by minimizing the integral of the Hamiltonian over the domain, where the Hamiltonian is estimated using the critic. We show that the training dynamics of the actor and critic neural networks converge in a Sobolev-type space to a certain infinite-dimensional ordinary differential equation (ODE) as the number of hidden units in the actor and critic $\rightarrow \infty$. Further, under a convexity-like assumption on the Hamiltonian, we prove that any fixed point of this limit ODE is a solution of the original stochastic control problem. This provides an important guarantee for the algorithm's performance in light of the fact that finite-width neural networks may only converge to a local minimizers (and not optimal solutions) due to the non-convexity of their loss functions. In our numerical studies, we demonstrate that the algorithm can solve stochastic control problems accurately in up to 200 dimensions. In particular, we construct a series of increasingly complex stochastic control problems with known analytic solutions and study the algorithm's numerical performance on them. These problems range from a linear-quadratic regulator equation to highly challenging equations with non-convex Hamiltonians, allowing us to identify and analyze the strengths and limitations of this neural actor-critic method for solving HJB equations.
Understanding Transfer Learning via Mean-field Analysis
Oct 23, 2024



We propose a novel framework for exploring generalization errors of transfer learning through the lens of differential calculus on the space of probability measures. In particular, we consider two main transfer learning scenarios, $\alpha$-ERM and fine-tuning with the KL-regularized empirical risk minimization and establish generic conditions under which the generalization error and the population risk convergence rates for these scenarios are studied. Based on our theoretical results, we show the benefits of transfer learning with a one-hidden-layer neural network in the mean-field regime under some suitable integrability and regularity assumptions on the loss and activation functions.
Generalization Error of the Tilted Empirical Risk
Sep 28, 2024The generalization error (risk) of a supervised statistical learning algorithm quantifies its prediction ability on previously unseen data. Inspired by exponential tilting, Li et al. (2021) proposed the tilted empirical risk as a non-linear risk metric for machine learning applications such as classification and regression problems. In this work, we examine the generalization error of the tilted empirical risk. In particular, we provide uniform and information-theoretic bounds on the tilted generalization error, defined as the difference between the population risk and the tilted empirical risk, with a convergence rate of $O(1/\sqrt{n})$ where $n$ is the number of training samples. Furthermore, we study the solution to the KL-regularized expected tilted empirical risk minimization problem and derive an upper bound on the expected tilted generalization error with a convergence rate of $O(1/n)$.
Generalization Error of Graph Neural Networks in the Mean-field Regime
Feb 10, 2024



This work provides a theoretical framework for assessing the generalization error of graph classification tasks via graph neural networks in the over-parameterized regime, where the number of parameters surpasses the quantity of data points. We explore two widely utilized types of graph neural networks: graph convolutional neural networks and message passing graph neural networks. Prior to this study, existing bounds on the generalization error in the over-parametrized regime were uninformative, limiting our understanding of over-parameterized network performance. Our novel approach involves deriving upper bounds within the mean-field regime for evaluating the generalization error of these graph neural networks. We establish upper bounds with a convergence rate of $O(1/n)$, where $n$ is the number of graph samples. These upper bounds offer a theoretical assurance of the networks' performance on unseen data in the challenging over-parameterized regime and overall contribute to our understanding of their performance.
Mean-field Analysis of Generalization Errors
Jun 20, 2023We propose a novel framework for exploring weak and $L_2$ generalization errors of algorithms through the lens of differential calculus on the space of probability measures. Specifically, we consider the KL-regularized empirical risk minimization problem and establish generic conditions under which the generalization error convergence rate, when training on a sample of size $n$, is $\mathcal{O}(1/n)$. In the context of supervised learning with a one-hidden layer neural network in the mean-field regime, these conditions are reflected in suitable integrability and regularity assumptions on the loss and activation functions.
Global Convergence of Deep Galerkin and PINNs Methods for Solving Partial Differential Equations
May 10, 2023Numerically solving high-dimensional partial differential equations (PDEs) is a major challenge. Conventional methods, such as finite difference methods, are unable to solve high-dimensional PDEs due to the curse-of-dimensionality. A variety of deep learning methods have been recently developed to try and solve high-dimensional PDEs by approximating the solution using a neural network. In this paper, we prove global convergence for one of the commonly-used deep learning algorithms for solving PDEs, the Deep Galerkin Method (DGM). DGM trains a neural network approximator to solve the PDE using stochastic gradient descent. We prove that, as the number of hidden units in the single-layer network goes to infinity (i.e., in the ``wide network limit"), the trained neural network converges to the solution of an infinite-dimensional linear ordinary differential equation (ODE). The PDE residual of the limiting approximator converges to zero as the training time $\rightarrow \infty$. Under mild assumptions, this convergence also implies that the neural network approximator converges to the solution of the PDE. A closely related class of deep learning methods for PDEs is Physics Informed Neural Networks (PINNs). Using the same mathematical techniques, we can prove a similar global convergence result for the PINN neural network approximators. Both proofs require analyzing a kernel function in the limit ODE governing the evolution of the limit neural network approximator. A key technical challenge is that the kernel function, which is a composition of the PDE operator and the neural tangent kernel (NTK) operator, lacks a spectral gap, therefore requiring a careful analysis of its properties.
TAPAS: a Toolbox for Adversarial Privacy Auditing of Synthetic Data
Nov 12, 2022
Personal data collected at scale promises to improve decision-making and accelerate innovation. However, sharing and using such data raises serious privacy concerns. A promising solution is to produce synthetic data, artificial records to share instead of real data. Since synthetic records are not linked to real persons, this intuitively prevents classical re-identification attacks. However, this is insufficient to protect privacy. We here present TAPAS, a toolbox of attacks to evaluate synthetic data privacy under a wide range of scenarios. These attacks include generalizations of prior works and novel attacks. We also introduce a general framework for reasoning about privacy threats to synthetic data and showcase TAPAS on several examples.
Hedging option books using neural-SDE market models
May 31, 2022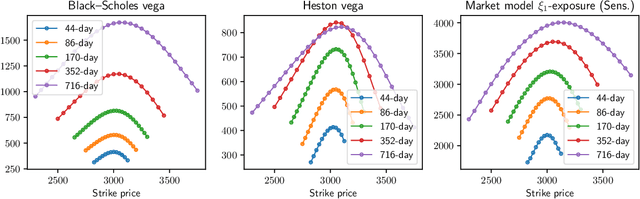

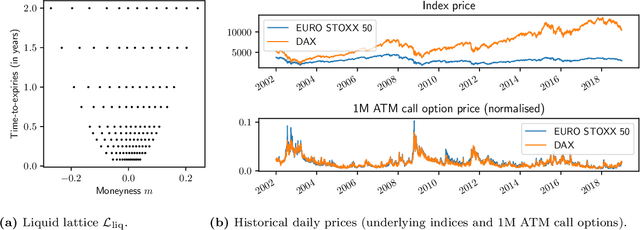

We study the capability of arbitrage-free neural-SDE market models to yield effective strategies for hedging options. In particular, we derive sensitivity-based and minimum-variance-based hedging strategies using these models and examine their performance when applied to various option portfolios using real-world data. Through backtesting analysis over typical and stressed market periods, we show that neural-SDE market models achieve lower hedging errors than Black--Scholes delta and delta-vega hedging consistently over time, and are less sensitive to the tenor choice of hedging instruments. In addition, hedging using market models leads to similar performance to hedging using Heston models, while the former tends to be more robust during stressed market periods.