 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Robust Domain Adaptation without Source Data
Mar 26, 2021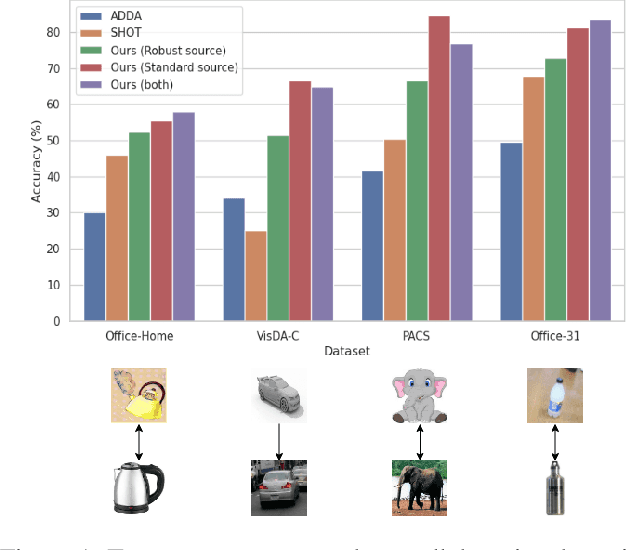
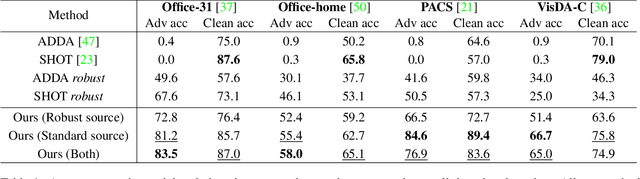
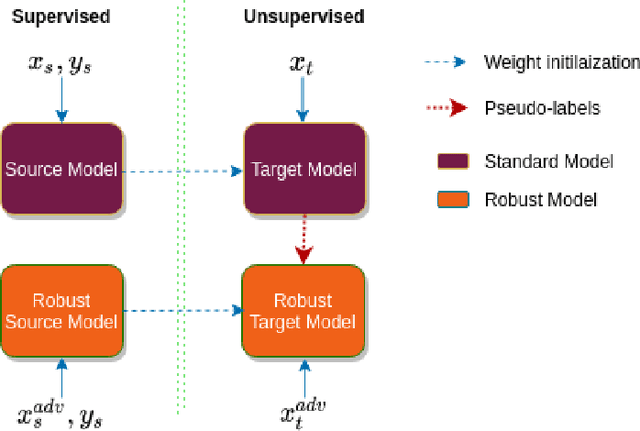

We study the problem of robust domain adaptation in the context of unavailable target labels and source data. The considered robustness is against adversarial perturbations. This paper aims at answering the question of finding the right strategy to make the target model robust and accurate in the setting of unsupervised domain adaptation without source data. The major findings of this paper are: (i) robust source models can be transferred robustly to the target; (ii) robust domain adaptation can greatly benefit from non-robust pseudo-labels and the pair-wise contrastive loss. The proposed method of using non-robust pseudo-labels performs surprisingly well on both clean and adversarial samples, for the task of image classification. We show a consistent performance improvement of over $10\%$ in accuracy against the tested baselines on four benchmark datasets.
Designing a Practical Degradation Model for Deep Blind Image Super-Resolution
Mar 25, 2021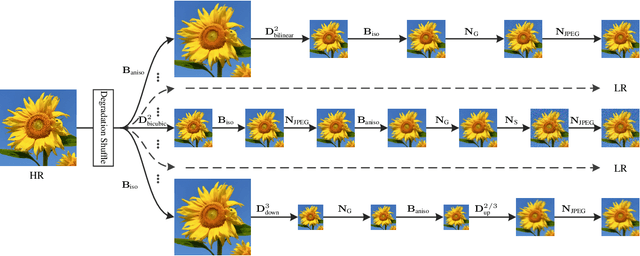
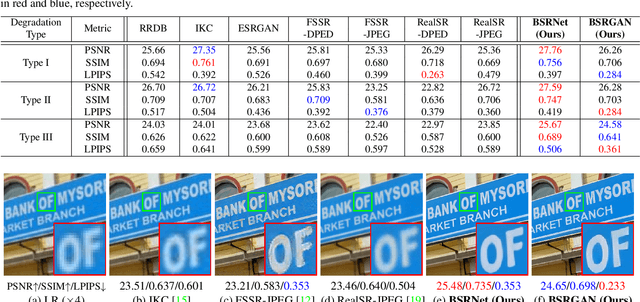

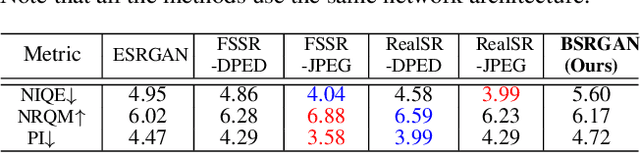
It is widely acknowledged that single image super-resolution (SISR) methods would not perform well if the assumed degradation model deviates from those in real images. Although several degradation models take additional factors into consideration, such as blur, they are still not effective enough to cover the diverse degradations of real images. To address this issue, this paper proposes to design a more complex but practical degradation model that consists of randomly shuffled blur, downsampling and noise degradations. Specifically, the blur is approximated by two convolutions with isotropic and anisotropic Gaussian kernels; the downsampling is randomly chosen from nearest, bilinear and bicubic interpolations; the noise is synthesized by adding Gaussian noise with different noise levels, adopting JPEG compression with different quality factors, and generating processed camera sensor noise via reverse-forward camera image signal processing (ISP) pipeline model and RAW image noise model. To verify the effectiveness of the new degradation model, we have trained a deep blind ESRGAN super-resolver and then applied it to super-resolve both synthetic and real images with diverse degradations. The experimental results demonstrate that the new degradation model can help to significantly improve the practicability of deep super-resolvers, thus providing a powerful alternative solution for real SISR applications.
Differentiable Multi-Granularity Human Representation Learning for Instance-Aware Human Semantic Parsing
Mar 08, 2021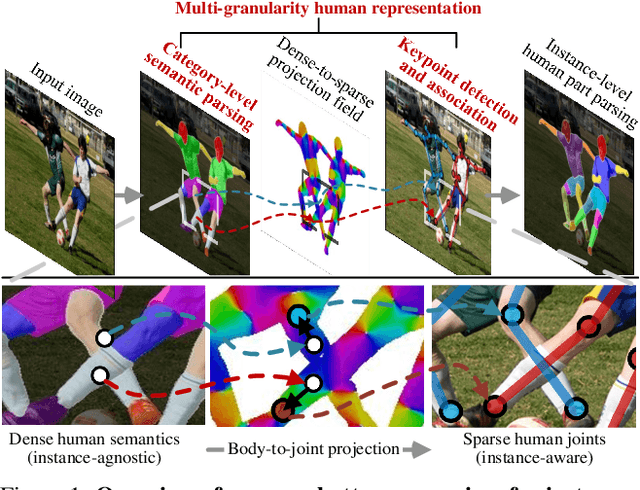
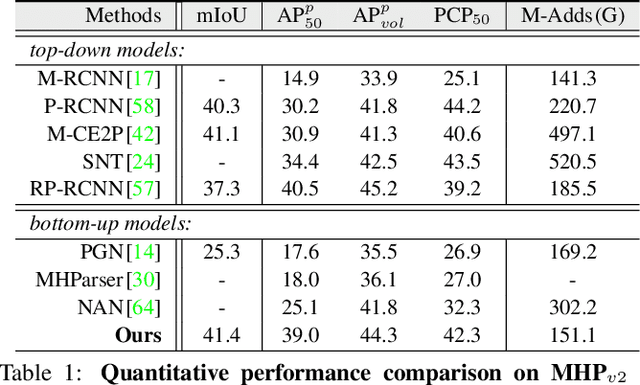
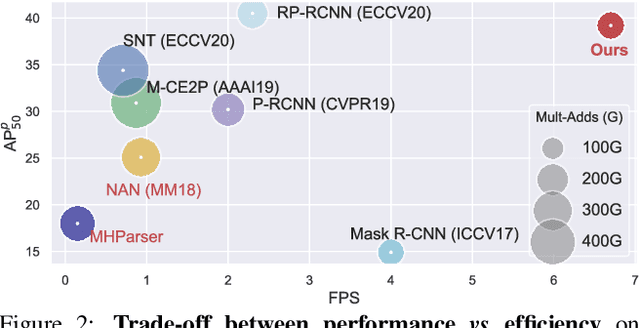
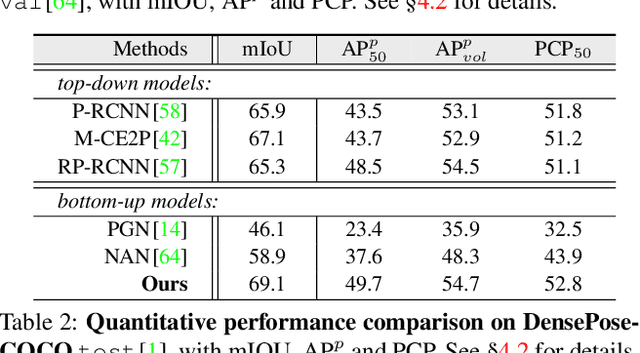
To address the challenging task of instance-aware human part parsing, a new bottom-up regime is proposed to learn category-level human semantic segmentation as well as multi-person pose estimation in a joint and end-to-end manner. It is a compact, efficient and powerful framework that exploits structural information over different human granularities and eases the difficulty of person partitioning. Specifically, a dense-to-sparse projection field, which allows explicitly associating dense human semantics with sparse keypoints, is learnt and progressively improved over the network feature pyramid for robustness. Then, the difficult pixel grouping problem is cast as an easier, multi-person joint assembling task. By formulating joint association as maximum-weight bipartite matching, a differentiable solution is developed to exploit projected gradient descent and Dykstra's cyclic projection algorithm. This makes our method end-to-end trainable and allows back-propagating the grouping error to directly supervise multi-granularity human representation learning. This is distinguished from current bottom-up human parsers or pose estimators which require sophisticated post-processing or heuristic greedy algorithms. Experiments on three instance-aware human parsing datasets show that our model outperforms other bottom-up alternatives with much more efficient inference.
Spectral Tensor Train Parameterization of Deep Learning Layers
Mar 07, 2021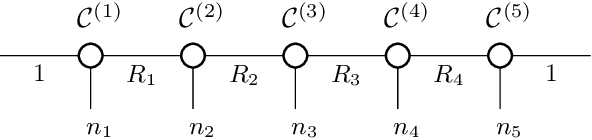


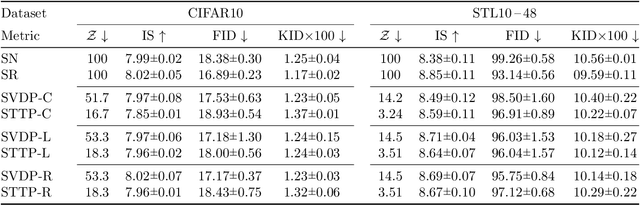
We study low-rank parameterizations of weight matrices with embedded spectral properties in the Deep Learning context. The low-rank property leads to parameter efficiency and permits taking computational shortcuts when computing mappings. Spectral properties are often subject to constraints in optimization problems, leading to better models and stability of optimization. We start by looking at the compact SVD parameterization of weight matrices and identifying redundancy sources in the parameterization. We further apply the Tensor Train (TT) decomposition to the compact SVD components, and propose a non-redundant differentiable parameterization of fixed TT-rank tensor manifolds, termed the Spectral Tensor Train Parameterization (STTP). We demonstrate the effects of neural network compression in the image classification setting and both compression and improved training stability in the generative adversarial training setting.
Efficient Conditional GAN Transfer with Knowledge Propagation across Classes
Feb 12, 2021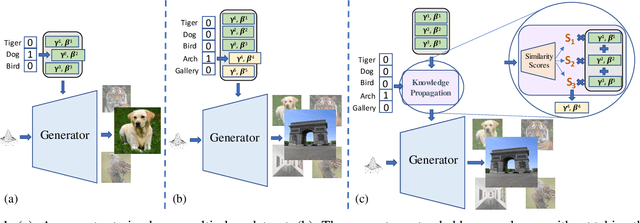



Generative adversarial networks (GANs) have shown impressive results in both unconditional and conditional image generation. In recent literature, it is shown that pre-trained GANs, on a different dataset, can be transferred to improve the image generation from a small target data. The same, however, has not been well-studied in the case of conditional GANs (cGANs), which provides new opportunities for knowledge transfer compared to unconditional setup. In particular, the new classes may borrow knowledge from the related old classes, or share knowledge among themselves to improve the training. This motivates us to study the problem of efficient conditional GAN transfer with knowledge propagation across classes. To address this problem, we introduce a new GAN transfer method to explicitly propagate the knowledge from the old classes to the new classes. The key idea is to enforce the popularly used conditional batch normalization (BN) to learn the class-specific information of the new classes from that of the old classes, with implicit knowledge sharing among the new ones. This allows for an efficient knowledge propagation from the old classes to the new classes, with the BN parameters increasing linearly with the number of new classes. The extensive evaluation demonstrates the clear superiority of the proposed method over state-of-the-art competitors for efficient conditional GAN transfer tasks. The code will be available at: https://github.com/mshahbazi72/cGANTransfer
Exploring Cross-Image Pixel Contrast for Semantic Segmentation
Feb 11, 2021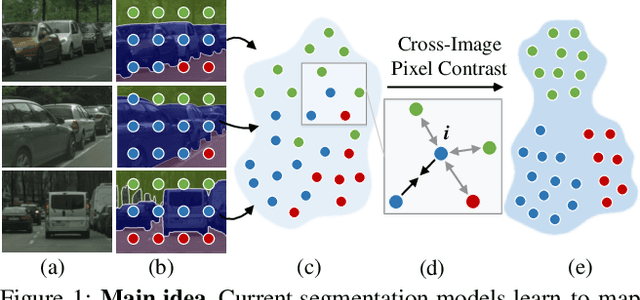
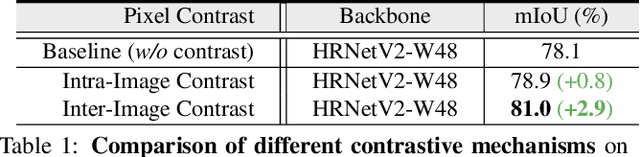
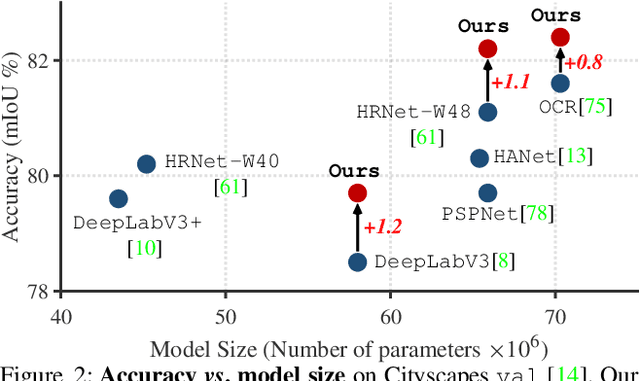

Current semantic segmentation methods focus only on mining "local" context, i.e., dependencies between pixels within individual images, by context-aggregation modules (e.g., dilated convolution, neural attention) or structure-aware optimization criteria (e.g., IoU-like loss). However, they ignore "global" context of the training data, i.e., rich semantic relations between pixels across different images. Inspired by the recent advance in unsupervised contrastive representation learning, we propose a pixel-wise contrastive framework for semantic segmentation in the fully supervised setting. The core idea is to enforce pixel embeddings belonging to a same semantic class to be more similar than embeddings from different classes. It raises a pixel-wise metric learning paradigm for semantic segmentation, by explicitly exploring the structures of labeled pixels, which were rarely explored before. Our method can be effortlessly incorporated into existing segmentation frameworks without extra overhead during testing. We experimentally show that, with famous segmentation models (i.e., DeepLabV3, HRNet, OCR) and backbones (i.e., ResNet, HR-Net), our method brings consistent performance improvements across diverse datasets (i.e., Cityscapes, PASCAL-Context, COCO-Stuff). We expect this work will encourage our community to rethink the current de facto training paradigm in fully supervised semantic segmentation.
Unsupervised Semantic Segmentation by Contrasting Object Mask Proposals
Feb 11, 2021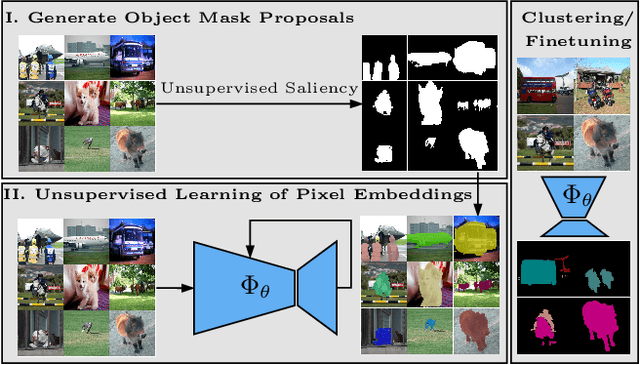
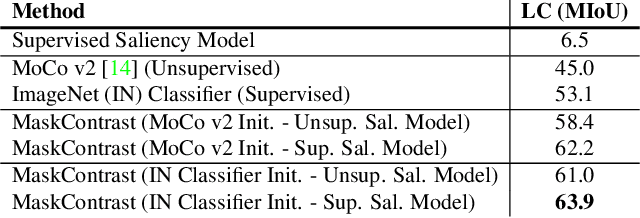
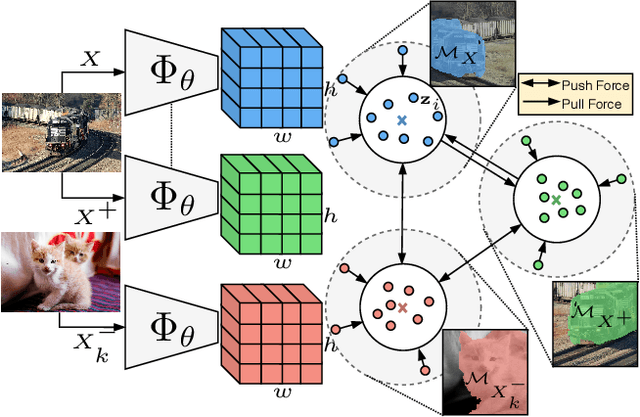

Being able to learn dense semantic representations of images without supervision is an important problem in computer vision. However, despite its significance, this problem remains rather unexplored, with a few exceptions that considered unsupervised semantic segmentation on small-scale datasets with a narrow visual domain. In this paper, we make a first attempt to tackle the problem on datasets that have been traditionally utilized for the supervised case. To achieve this, we introduce a novel two-step framework that adopts a predetermined prior in a contrastive optimization objective to learn pixel embeddings. This marks a large deviation from existing works that relied on proxy tasks or end-to-end clustering. Additionally, we argue about the importance of having a prior that contains information about objects, or their parts, and discuss several possibilities to obtain such a prior in an unsupervised manner. Extensive experimental evaluation shows that the proposed method comes with key advantages over existing works. First, the learned pixel embeddings can be directly clustered in semantic groups using K-Means. Second, the method can serve as an effective unsupervised pre-training for the semantic segmentation task. In particular, when fine-tuning the learned representations using just 1% of labeled examples on PASCAL, we outperform supervised ImageNet pre-training by 7.1% mIoU. The code is available at https://github.com/wvangansbeke/Unsupervised-Semantic-Segmentation.
Deep Burst Super-Resolution
Jan 26, 2021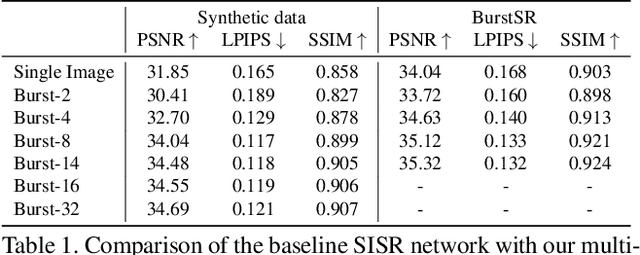
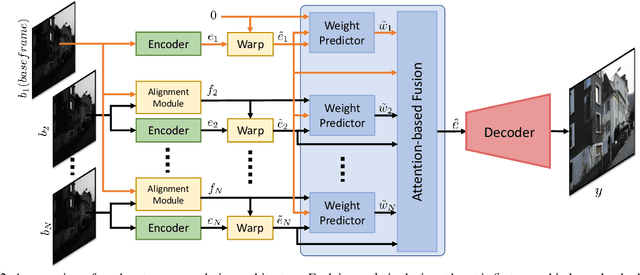
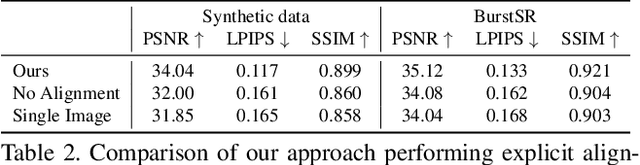
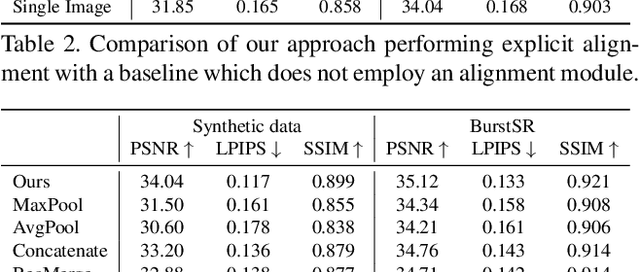
While single-image super-resolution (SISR) has attracted substantial interest in recent years, the proposed approaches are limited to learning image priors in order to add high frequency details. In contrast, multi-frame super-resolution (MFSR) offers the possibility of reconstructing rich details by combining signal information from multiple shifted images. This key advantage, along with the increasing popularity of burst photography, have made MFSR an important problem for real-world applications. We propose a novel architecture for the burst super-resolution task. Our network takes multiple noisy RAW images as input, and generates a denoised, super-resolved RGB image as output. This is achieved by explicitly aligning deep embeddings of the input frames using pixel-wise optical flow. The information from all frames are then adaptively merged using an attention-based fusion module. In order to enable training and evaluation on real-world data, we additionally introduce the BurstSR dataset, consisting of smartphone bursts and high-resolution DSLR ground-truth. We perform comprehensive experimental analysis, demonstrating the effectiveness of the proposed architecture.
Hyperspectral Image Super-Resolution with Spectral Mixup and Heterogeneous Datasets
Jan 19, 2021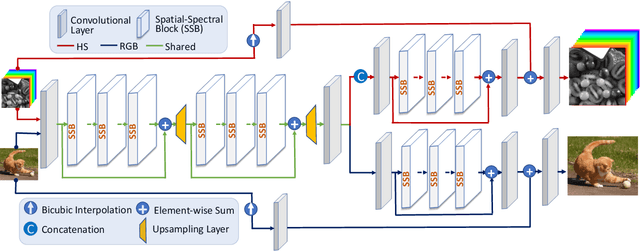
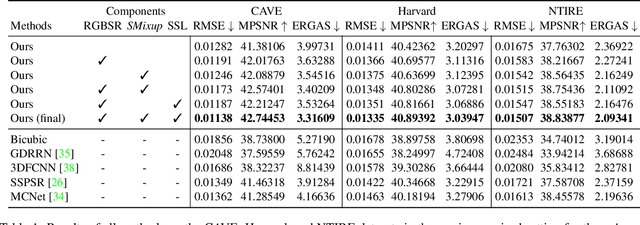
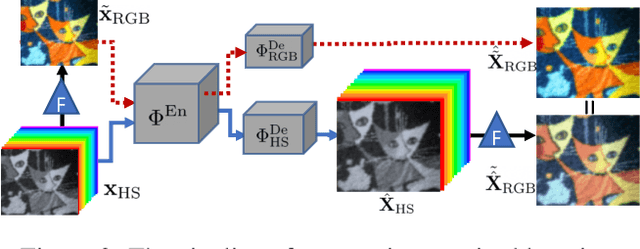
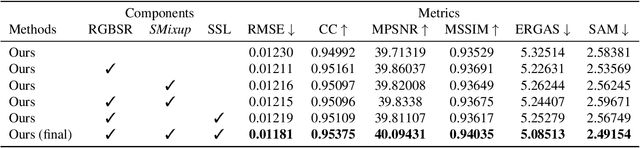
This work studies Hyperspectral image (HSI) super-resolution (SR). HSI SR is characterized by high-dimensional data and a limited amount of training examples. This exacerbates the undesirable behaviors of neural networks such as memorization and sensitivity to out-of-distribution samples. This work addresses these issues with three contributions. First, we propose a simple, yet effective data augmentation routine, termed Spectral Mixup, to construct effective virtual training samples. Second, we observe that HSI SR and RGB image SR are correlated and develop a novel multi-tasking network to train them jointly so that the auxiliary task RGB image SR can provide additional supervision. Finally, we extend the network to a semi-supervised setting so that it can learn from datasets containing low-resolution HSIs only. With these contributions, our method is able to learn from heterogeneous datasets and lift the requirement for having a large amount of HD HSI training samples. Extensive experiments on four datasets show that our method outperforms existing methods significantly and underpin the relevance of our contributions. The code of this work will be released soon.
Trilevel Neural Architecture Search for Efficient Single Image Super-Resolution
Jan 17, 2021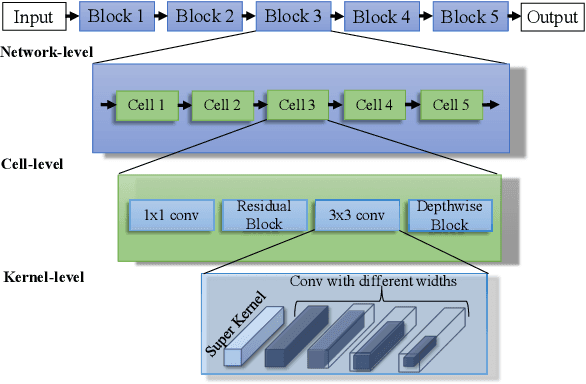
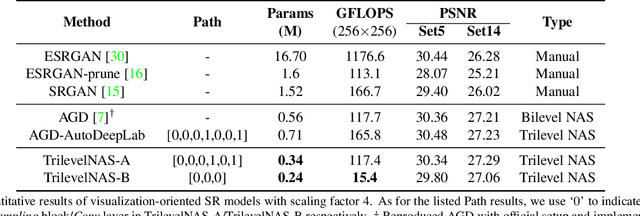
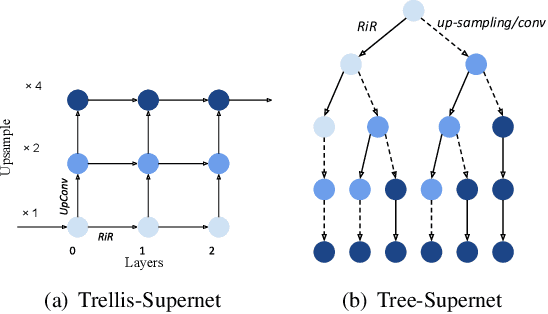
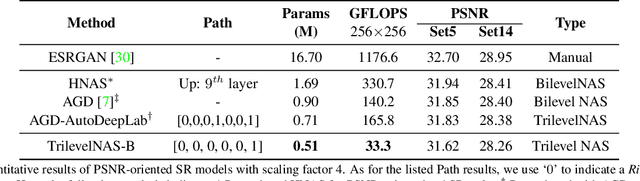
This paper proposes a trilevel neural architecture search (NAS) method for efficient single image super-resolution (SR). For that, we first define the discrete search space at three-level, i.e., at network-level, cell-level, and kernel-level (convolution-kernel). For modeling the discrete search space, we apply a new continuous relaxation on the discrete search spaces to build a hierarchical mixture of network-path, cell-operations, and kernel-width. Later an efficient search algorithm is proposed to perform optimization in a hierarchical supernet manner that provides a globally optimized and compressed network via joint convolution kernel width pruning, cell structure search, and network path optimization. Unlike current NAS methods, we exploit a sorted sparsestmax activation to let the three-level neural structures contribute sparsely. Consequently, our NAS optimization progressively converges to those neural structures with dominant contributions to the supernet. Additionally, our proposed optimization construction enables a simultaneous search and training in a single phase, which dramatically reduces search and train time compared to the traditional NAS algorithms. Experiments on the standard benchmark datasets demonstrate that our NAS algorithm provides SR models that are significantly lighter in terms of the number of parameters and FLOPS with PSNR value comparable to the current state-of-the-art.