 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning To Classify Images Without Labels
Paper and Code
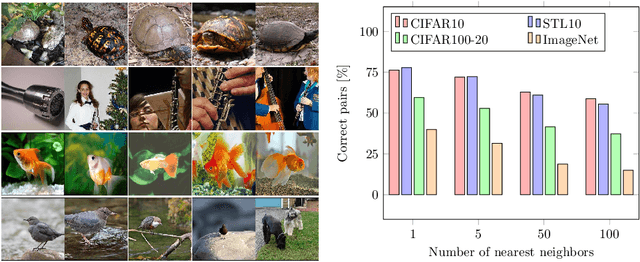
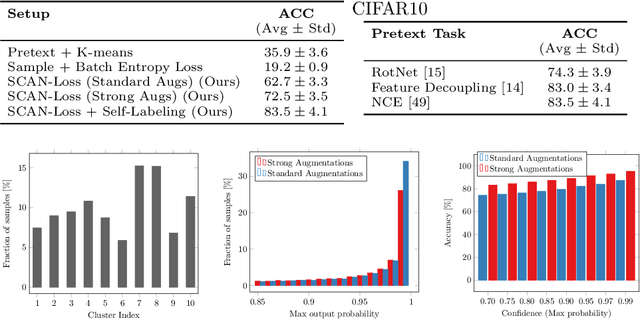
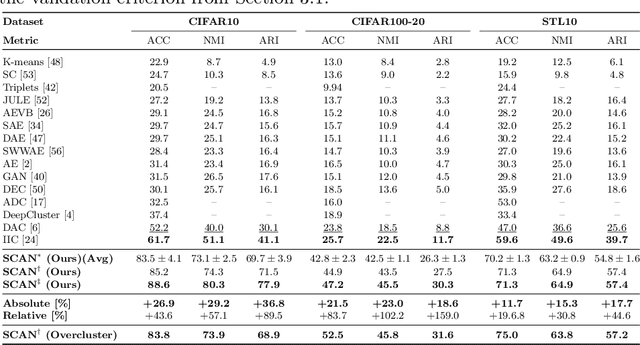
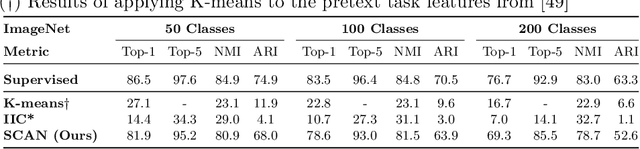
Is it possible to automatically classify images without the use of ground-truth annotations? Or when even the classes themselves, are not a priori known? These remain important, and open questions in computer vision. Several approaches have tried to tackle this problem in an end-to-end fashion. In this paper, we deviate from recent works, and advocate a two-step approach where feature learning and clustering are decoupled. First, a self-supervised task from representation learning is employed to obtain semantically meaningful features. Second, we use the obtained features as a prior in a learnable clustering approach. In doing so, we remove the ability for cluster learning to depend on low-level features, which is present in current end-to-end learning approaches. Experimental evaluation shows that we outperform state-of-the-art methods by huge margins, in particular +26.9% on CIFAR10, +21.5% on CIFAR100-20 and +11.7% on STL10 in terms of classification accuracy. Furthermore, results on ImageNet show that our approach is the first to scale well up to 200 randomly selected classes, obtaining 69.3% top-1 and 85.5% top-5 accuracy, and marking a difference of less than 7.5% with fully-supervised methods. Finally, we applied our approach to all 1000 classes on ImageNet, and found the results to be very encouraging. The code will be made publicly available.