 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Structured Prediction Approach for Robot Imitation Learning
Sep 26, 2023We propose a structured prediction approach for robot imitation learning from demonstrations. Among various tools for robot imitation learning, supervised learning has been observed to have a prominent role. Structured prediction is a form of supervised learning that enables learning models to operate on output spaces with complex structures. Through the lens of structured prediction, we show how robots can learn to imitate trajectories belonging to not only Euclidean spaces but also Riemannian manifolds. Exploiting ideas from information theory, we propose a class of loss functions based on the f-divergence to measure the information loss between the demonstrated and reproduced probabilistic trajectories. Different types of f-divergence will result in different policies, which we call imitation modes. Furthermore, our approach enables the incorporation of spatial and temporal trajectory modulation, which is necessary for robots to be adaptive to the change in working conditions. We benchmark our algorithm against state-of-the-art methods in terms of trajectory reproduction and adaptation. The quantitative evaluation shows that our approach outperforms other algorithms regarding both accuracy and efficiency. We also report real-world experimental results on learning manifold trajectories in a polishing task with a KUKA LWR robot arm, illustrating the effectiveness of our algorithmic framework.
Estimating Koopman operators with sketching to provably learn large scale dynamical systems
Jun 07, 2023



The theory of Koopman operators allows to deploy non-parametric machine learning algorithms to predict and analyze complex dynamical systems. Estimators such as principal component regression (PCR) or reduced rank regression (RRR) in kernel spaces can be shown to provably learn Koopman operators from finite empirical observations of the system's time evolution. Scaling these approaches to very long trajectories is a challenge and requires introducing suitable approximations to make computations feasible. In this paper, we boost the efficiency of different kernel-based Koopman operator estimators using random projections (sketching). We derive, implement and test the new "sketched" estimators with extensive experiments on synthetic and large-scale molecular dynamics datasets. Further, we establish non asymptotic error bounds giving a sharp characterization of the trade-offs between statistical learning rates and computational efficiency. Our empirical and theoretical analysis shows that the proposed estimators provide a sound and efficient way to learn large scale dynamical systems. In particular our experiments indicate that the proposed estimators retain the same accuracy of PCR or RRR, while being much faster.
A Grasp Pose is All You Need: Learning Multi-fingered Grasping with Deep Reinforcement Learning from Vision and Touch
Jun 06, 2023



Multi-fingered robotic hands could enable robots to perform sophisticated manipulation tasks. However, teaching a robot to grasp objects with an anthropomorphic hand is an arduous problem due to the high dimensionality of state and action spaces. Deep Reinforcement Learning (DRL) offers techniques to design control policies for this kind of problems without explicit environment or hand modeling. However, training these policies with state-of-the-art model-free algorithms is greatly challenging for multi-fingered hands. The main problem is that an efficient exploration of the environment is not possible for such high-dimensional problems, thus causing issues in the initial phases of policy optimization. One possibility to address this is to rely on off-line task demonstrations. However, oftentimes this is incredibly demanding in terms of time and computational resources. In this work, we overcome these requirements and propose the A Grasp Pose is All You Need (G-PAYN) method for the anthropomorphic hand of the iCub humanoid. We develop an approach to automatically collect task demonstrations to initialize the training of the policy. The proposed grasping pipeline starts from a grasp pose generated by an external algorithm, used to initiate the movement. Then a control policy (previously trained with the proposed G-PAYN) is used to reach and grab the object. We deployed the iCub into the MuJoCo simulator and use it to test our approach with objects from the YCB-Video dataset. The results show that G-PAYN outperforms current DRL techniques in the considered setting, in terms of success rate and execution time with respect to the baselines. The code to reproduce the experiments will be released upon acceptance.
Scalable Causal Discovery with Score Matching
Apr 06, 2023



This paper demonstrates how to discover the whole causal graph from the second derivative of the log-likelihood in observational non-linear additive Gaussian noise models. Leveraging scalable machine learning approaches to approximate the score function $\nabla \log p(\mathbf{X})$, we extend the work of Rolland et al. (2022) that only recovers the topological order from the score and requires an expensive pruning step removing spurious edges among those admitted by the ordering. Our analysis leads to DAS (acronym for Discovery At Scale), a practical algorithm that reduces the complexity of the pruning by a factor proportional to the graph size. In practice, DAS achieves competitive accuracy with current state-of-the-art while being over an order of magnitude faster. Overall, our approach enables principled and scalable causal discovery, significantly lowering the compute bar.
Causal Discovery with Score Matching on Additive Models with Arbitrary Noise
Apr 06, 2023



Causal discovery methods are intrinsically constrained by the set of assumptions needed to ensure structure identifiability. Moreover additional restrictions are often imposed in order to simplify the inference task: this is the case for the Gaussian noise assumption on additive non-linear models, which is common to many causal discovery approaches. In this paper we show the shortcomings of inference under this hypothesis, analyzing the risk of edge inversion under violation of Gaussianity of the noise terms. Then, we propose a novel method for inferring the topological ordering of the variables in the causal graph, from data generated according to an additive non-linear model with a generic noise distribution. This leads to NoGAM (Not only Gaussian Additive noise Models), a causal discovery algorithm with a minimal set of assumptions and state of the art performance, experimentally benchmarked on synthetic data.
Fast kernel methods for Data Quality Monitoring as a goodness-of-fit test
Mar 09, 2023We here propose a machine learning approach for monitoring particle detectors in real-time. The goal is to assess the compatibility of incoming experimental data with a reference dataset, characterising the data behaviour under normal circumstances, via a likelihood-ratio hypothesis test. The model is based on a modern implementation of kernel methods, nonparametric algorithms that can learn any continuous function given enough data. The resulting approach is efficient and agnostic to the type of anomaly that may be present in the data. Our study demonstrates the effectiveness of this strategy on multivariate data from drift tube chamber muon detectors.
Key Design Choices for Double-Transfer in Source-Free Unsupervised Domain Adaptation
Feb 10, 2023Fine-tuning and Domain Adaptation emerged as effective strategies for efficiently transferring deep learning models to new target tasks. However, target domain labels are not accessible in many real-world scenarios. This led to the development of Unsupervised Domain Adaptation (UDA) methods, which only employ unlabeled target samples. Furthermore, efficiency and privacy requirements may also prevent the use of source domain data during the adaptation stage. This challenging setting, known as Source-Free Unsupervised Domain Adaptation (SF-UDA), is gaining interest among researchers and practitioners due to its potential for real-world applications. In this paper, we provide the first in-depth analysis of the main design choices in SF-UDA through a large-scale empirical study across 500 models and 74 domain pairs. We pinpoint the normalization approach, pre-training strategy, and backbone architecture as the most critical factors. Based on our quantitative findings, we propose recipes to best tackle SF-UDA scenarios. Moreover, we show that SF-UDA is competitive also beyond standard benchmarks and backbone architectures, performing on par with UDA at a fraction of the data and computational cost. In the interest of reproducibility, we include the full experimental results and code as supplementary material.
Iterative regularization in classification via hinge loss diagonal descent
Dec 24, 2022Iterative regularization is a classic idea in regularization theory, that has recently become popular in machine learning. On the one hand, it allows to design efficient algorithms controlling at the same time numerical and statistical accuracy. On the other hand it allows to shed light on the learning curves observed while training neural networks. In this paper, we focus on iterative regularization in the context of classification. After contrasting this setting with that of regression and inverse problems, we develop an iterative regularization approach based on the use of the hinge loss function. More precisely we consider a diagonal approach for a family of algorithms for which we prove convergence as well as rates of convergence. Our approach compares favorably with other alternatives, as confirmed also in numerical simulations.
Regularized ERM on random subspaces
Dec 08, 2022We study a natural extension of classical empirical risk minimization, where the hypothesis space is a random subspace of a given space. In particular, we consider possibly data dependent subspaces spanned by a random subset of the data, recovering as a special case Nystrom approaches for kernel methods. Considering random subspaces naturally leads to computational savings, but the question is whether the corresponding learning accuracy is degraded. These statistical-computational tradeoffs have been recently explored for the least squares loss and self-concordant loss functions, such as the logistic loss. Here, we work to extend these results to convex Lipschitz loss functions, that might not be smooth, such as the hinge loss used in support vector machines. This unified analysis requires developing new proofs, that use different technical tools, such as sub-gaussian inputs, to achieve fast rates. Our main results show the existence of different settings, depending on how hard the learning problem is, for which computational efficiency can be improved with no loss in performance.
Fine-tuning or top-tuning? Transfer learning with pretrained features and fast kernel methods
Sep 16, 2022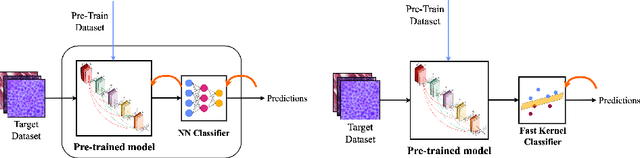
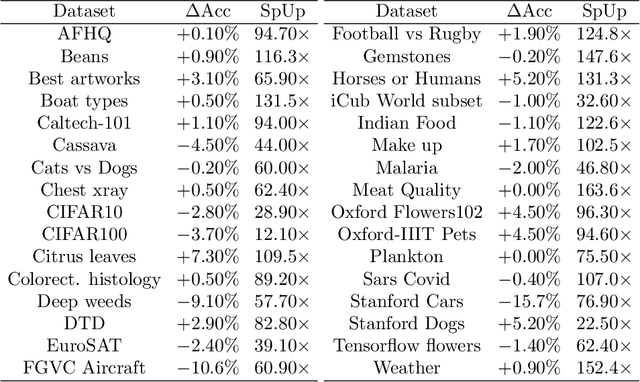
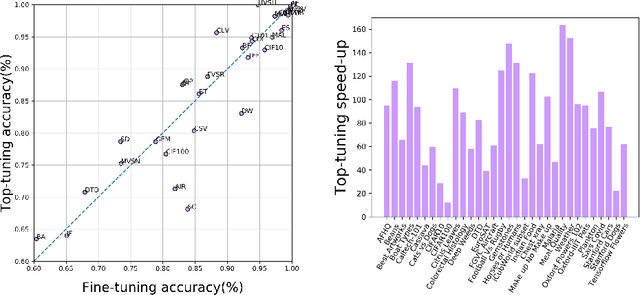
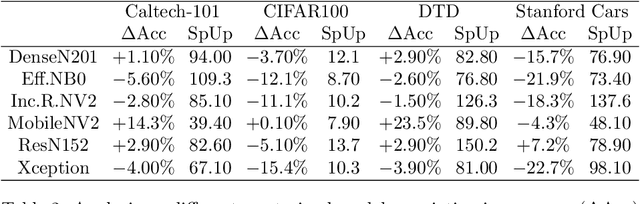
The impressive performances of deep learning architectures is associated to massive increase of models complexity. Millions of parameters need be tuned, with training and inference time scaling accordingly. But is massive fine-tuning necessary? In this paper, focusing on image classification, we consider a simple transfer learning approach exploiting pretrained convolutional features as input for a fast kernel method. We refer to this approach as top-tuning, since only the kernel classifier is trained. By performing more than 2500 training processes we show that this top-tuning approach provides comparable accuracy w.r.t. fine-tuning, with a training time that is between one and two orders of magnitude smaller. These results suggest that top-tuning provides a useful alternative to fine-tuning in small/medium datasets, especially when training efficiency is crucial.