 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinuous Wrist Control on the Hannes Prosthesis: a Vision-based Shared Autonomy Framework
Feb 24, 2025



Most control techniques for prosthetic grasping focus on dexterous fingers control, but overlook the wrist motion. This forces the user to perform compensatory movements with the elbow, shoulder and hip to adapt the wrist for grasping. We propose a computer vision-based system that leverages the collaboration between the user and an automatic system in a shared autonomy framework, to perform continuous control of the wrist degrees of freedom in a prosthetic arm, promoting a more natural approach-to-grasp motion. Our pipeline allows to seamlessly control the prosthetic wrist to follow the target object and finally orient it for grasping according to the user intent. We assess the effectiveness of each system component through quantitative analysis and finally deploy our method on the Hannes prosthetic arm. Code and videos: https://hsp-iit.github.io/hannes-wrist-control.
Gaze estimation learning architecture as support to affective, social and cognitive studies in natural human-robot interaction
Oct 25, 2024



Gaze is a crucial social cue in any interacting scenario and drives many mechanisms of social cognition (joint and shared attention, predicting human intention, coordination tasks). Gaze direction is an indication of social and emotional functions affecting the way the emotions are perceived. Evidence shows that embodied humanoid robots endowing social abilities can be seen as sophisticated stimuli to unravel many mechanisms of human social cognition while increasing engagement and ecological validity. In this context, building a robotic perception system to automatically estimate the human gaze only relying on robot's sensors is still demanding. Main goal of the paper is to propose a learning robotic architecture estimating the human gaze direction in table-top scenarios without any external hardware. Table-top tasks are largely used in many studies in experimental psychology because they are suitable to implement numerous scenarios allowing agents to collaborate while maintaining a face-to-face interaction. Such an architecture can provide a valuable support in studies where external hardware might represent an obstacle to spontaneous human behaviour, especially in environments less controlled than the laboratory (e.g., in clinical settings). A novel dataset was also collected with the humanoid robot iCub, including images annotated from 24 participants in different gaze conditions.
Key Design Choices in Source-Free Unsupervised Domain Adaptation: An In-depth Empirical Analysis
Feb 25, 2024



This study provides a comprehensive benchmark framework for Source-Free Unsupervised Domain Adaptation (SF-UDA) in image classification, aiming to achieve a rigorous empirical understanding of the complex relationships between multiple key design factors in SF-UDA methods. The study empirically examines a diverse set of SF-UDA techniques, assessing their consistency across datasets, sensitivity to specific hyperparameters, and applicability across different families of backbone architectures. Moreover, it exhaustively evaluates pre-training datasets and strategies, particularly focusing on both supervised and self-supervised methods, as well as the impact of fine-tuning on the source domain. Our analysis also highlights gaps in existing benchmark practices, guiding SF-UDA research towards more effective and general approaches. It emphasizes the importance of backbone architecture and pre-training dataset selection on SF-UDA performance, serving as an essential reference and providing key insights. Lastly, we release the source code of our experimental framework. This facilitates the construction, training, and testing of SF-UDA methods, enabling systematic large-scale experimental analysis and supporting further research efforts in this field.
iCub Detecting Gazed Objects: A Pipeline Estimating Human Attention
Aug 25, 2023



This paper explores the role of eye gaze in human-robot interactions and proposes a novel system for detecting objects gazed by the human using solely visual feedback. The system leverages on face detection, human attention prediction, and online object detection, and it allows the robot to perceive and interpret human gaze accurately, paving the way for establishing joint attention with human partners. Additionally, a novel dataset collected with the humanoid robot iCub is introduced, comprising over 22,000 images from ten participants gazing at different annotated objects. This dataset serves as a benchmark for evaluating the performance of the proposed pipeline. The paper also includes an experimental analysis of the pipeline's effectiveness in a human-robot interaction setting, examining the performance of each component. Furthermore, the developed system is deployed on the humanoid robot iCub, and a supplementary video showcases its functionality. The results demonstrate the potential of the proposed approach to enhance social awareness and responsiveness in social robotics, as well as improve assistance and support in collaborative scenarios, promoting efficient human-robot collaboration. The code and the collected dataset will be released upon acceptance.
A Grasp Pose is All You Need: Learning Multi-fingered Grasping with Deep Reinforcement Learning from Vision and Touch
Jun 06, 2023



Multi-fingered robotic hands could enable robots to perform sophisticated manipulation tasks. However, teaching a robot to grasp objects with an anthropomorphic hand is an arduous problem due to the high dimensionality of state and action spaces. Deep Reinforcement Learning (DRL) offers techniques to design control policies for this kind of problems without explicit environment or hand modeling. However, training these policies with state-of-the-art model-free algorithms is greatly challenging for multi-fingered hands. The main problem is that an efficient exploration of the environment is not possible for such high-dimensional problems, thus causing issues in the initial phases of policy optimization. One possibility to address this is to rely on off-line task demonstrations. However, oftentimes this is incredibly demanding in terms of time and computational resources. In this work, we overcome these requirements and propose the A Grasp Pose is All You Need (G-PAYN) method for the anthropomorphic hand of the iCub humanoid. We develop an approach to automatically collect task demonstrations to initialize the training of the policy. The proposed grasping pipeline starts from a grasp pose generated by an external algorithm, used to initiate the movement. Then a control policy (previously trained with the proposed G-PAYN) is used to reach and grab the object. We deployed the iCub into the MuJoCo simulator and use it to test our approach with objects from the YCB-Video dataset. The results show that G-PAYN outperforms current DRL techniques in the considered setting, in terms of success rate and execution time with respect to the baselines. The code to reproduce the experiments will be released upon acceptance.
Key Design Choices for Double-Transfer in Source-Free Unsupervised Domain Adaptation
Feb 10, 2023Fine-tuning and Domain Adaptation emerged as effective strategies for efficiently transferring deep learning models to new target tasks. However, target domain labels are not accessible in many real-world scenarios. This led to the development of Unsupervised Domain Adaptation (UDA) methods, which only employ unlabeled target samples. Furthermore, efficiency and privacy requirements may also prevent the use of source domain data during the adaptation stage. This challenging setting, known as Source-Free Unsupervised Domain Adaptation (SF-UDA), is gaining interest among researchers and practitioners due to its potential for real-world applications. In this paper, we provide the first in-depth analysis of the main design choices in SF-UDA through a large-scale empirical study across 500 models and 74 domain pairs. We pinpoint the normalization approach, pre-training strategy, and backbone architecture as the most critical factors. Based on our quantitative findings, we propose recipes to best tackle SF-UDA scenarios. Moreover, we show that SF-UDA is competitive also beyond standard benchmarks and backbone architectures, performing on par with UDA at a fraction of the data and computational cost. In the interest of reproducibility, we include the full experimental results and code as supplementary material.
iCub Being Social: Exploiting Social Cues for Interactive Object Detection Learning
Jul 27, 2022
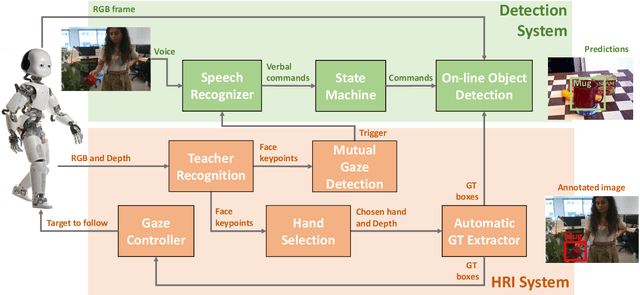
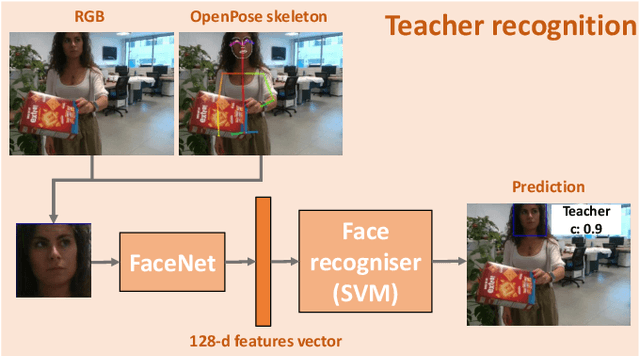

Performing joint interaction requires constant mutual monitoring of own actions and their effects on the other's behaviour. Such an action-effect monitoring is boosted by social cues and might result in an increasing sense of agency. Joint actions and joint attention are strictly correlated and both of them contribute to the formation of a precise temporal coordination. In human-robot interaction, the robot's ability to establish joint attention with a human partner and exploit various social cues to react accordingly is a crucial step in creating communicative robots. Along the social component, an effective human-robot interaction can be seen as a new method to improve and make the robot's learning process more natural and robust for a given task. In this work we use different social skills, such as mutual gaze, gaze following, speech and human face recognition, to develop an effective teacher-learner scenario tailored to visual object learning in dynamic environments. Experiments on the iCub robot demonstrate that the system allows the robot to learn new objects through a natural interaction with a human teacher in presence of distractors.
Learn Fast, Segment Well: Fast Object Segmentation Learning on the iCub Robot
Jun 27, 2022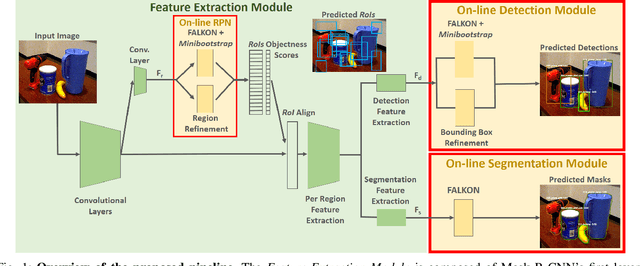

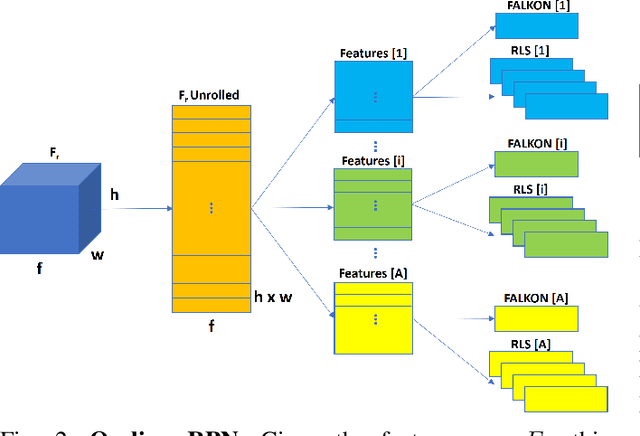

The visual system of a robot has different requirements depending on the application: it may require high accuracy or reliability, be constrained by limited resources or need fast adaptation to dynamically changing environments. In this work, we focus on the instance segmentation task and provide a comprehensive study of different techniques that allow adapting an object segmentation model in presence of novel objects or different domains. We propose a pipeline for fast instance segmentation learning designed for robotic applications where data come in stream. It is based on an hybrid method leveraging on a pre-trained CNN for feature extraction and fast-to-train Kernel-based classifiers. We also propose a training protocol that allows to shorten the training time by performing feature extraction during the data acquisition. We benchmark the proposed pipeline on two robotics datasets and we deploy it on a real robot, i.e. the iCub humanoid. To this aim, we adapt our method to an incremental setting in which novel objects are learned on-line by the robot. The code to reproduce the experiments is publicly available on GitHub.
Grasp Pre-shape Selection by Synthetic Training: Eye-in-hand Shared Control on the Hannes Prosthesis
Mar 18, 2022


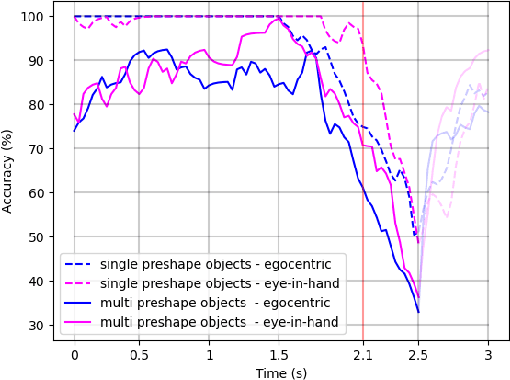
We consider the task of object grasping with a prosthetic hand capable of multiple grasp types. In this setting, communicating the intended grasp type often requires a high user cognitive load which can be reduced adopting shared autonomy frameworks. Among these, so-called eye-in-hand systems automatically control the hand aperture and pre-shaping before the grasp, based on visual input coming from a camera on the wrist. In this work, we present an eye-in-hand learning-based approach for hand pre-shape classification from RGB sequences. In order to reduce the need for tedious data collection sessions for training the system, we devise a pipeline for rendering synthetic visual sequences of hand trajectories for the purpose. We tackle the peculiarity of the eye-in-hand setting by means of a model for the human arm trajectories, with domain randomization over relevant visual elements. We develop a sensorized setup to acquire real human grasping sequences for benchmarking and show that, compared on practical use cases, models trained with our synthetic dataset achieve better generalization performance than models trained on real data. We finally integrate our model on the Hannes prosthetic hand and show its practical effectiveness. Our code, real and synthetic datasets will be released upon acceptance.
Weakly-Supervised Object Detection Learning through Human-Robot Interaction
Jul 16, 2021
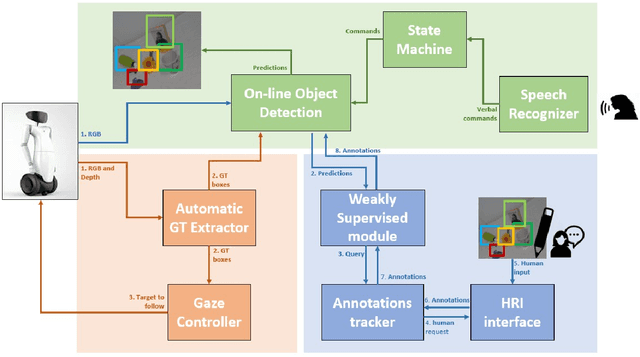

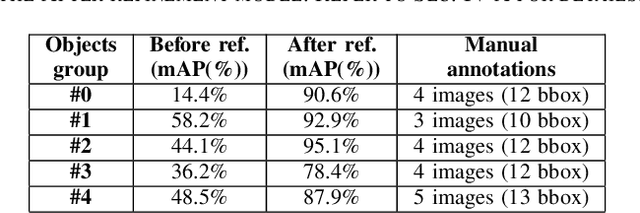
Reliable perception and efficient adaptation to novel conditions are priority skills for humanoids that function in dynamic environments. The vast advancements in latest computer vision research, brought by deep learning methods, are appealing for the robotics community. However, their adoption in applied domains is not straightforward since adapting them to new tasks is strongly demanding in terms of annotated data and optimization time. Nevertheless, robotic platforms, and especially humanoids, present opportunities (such as additional sensors and the chance to explore the environment) that can be exploited to overcome these issues. In this paper, we present a pipeline for efficiently training an object detection system on a humanoid robot. The proposed system allows to iteratively adapt an object detection model to novel scenarios, by exploiting: (i) a teacher-learner pipeline, (ii) weakly supervised learning techniques to reduce the human labeling effort and (iii) an on-line learning approach for fast model re-training. We use the R1 humanoid robot for both testing the proposed pipeline in a real-time application and acquire sequences of images to benchmark the method. We made the code of the application publicly available.