 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Next-Generation LLM Training: From the Data-Centric Perspective
Mar 16, 2026Large language models (LLMs) have demonstrated remarkable performance across a wide range of tasks and domains, with data playing a central role in enabling these advances. Despite this success, the preparation and effective utilization of the massive datasets required for LLM training remain major bottlenecks. In current practice, LLM training data is often constructed using ad hoc scripts, and there is still a lack of mature, agent-based data preparation systems that can automatically construct robust and reusable data workflows, thereby freeing data scientists from repetitive and error-prone engineering efforts. Moreover, once collected, datasets are often consumed largely in their entirety during training, without systematic mechanisms for data selection, mixture optimization, or reweighting. To address these limitations, we advocate two complementary research directions. First, we propose building a robust, agent-based automatic data preparation system that supports automated workflow construction and scalable data management. Second, we argue for a unified data-model interaction training system in which data is dynamically selected, mixed, and reweighted throughout the training process, enabling more efficient, adaptive, and performance-aware data utilization. Finally, we discuss the remaining challenges and outline promising directions for future research and system development.
DataFlow: An LLM-Driven Framework for Unified Data Preparation and Workflow Automation in the Era of Data-Centric AI
Dec 18, 2025The rapidly growing demand for high-quality data in Large Language Models (LLMs) has intensified the need for scalable, reliable, and semantically rich data preparation pipelines. However, current practices remain dominated by ad-hoc scripts and loosely specified workflows, which lack principled abstractions, hinder reproducibility, and offer limited support for model-in-the-loop data generation. To address these challenges, we present DataFlow, a unified and extensible LLM-driven data preparation framework. DataFlow is designed with system-level abstractions that enable modular, reusable, and composable data transformations, and provides a PyTorch-style pipeline construction API for building debuggable and optimizable dataflows. The framework consists of nearly 200 reusable operators and six domain-general pipelines spanning text, mathematical reasoning, code, Text-to-SQL, agentic RAG, and large-scale knowledge extraction. To further improve usability, we introduce DataFlow-Agent, which automatically translates natural-language specifications into executable pipelines via operator synthesis, pipeline planning, and iterative verification. Across six representative use cases, DataFlow consistently improves downstream LLM performance. Our math, code, and text pipelines outperform curated human datasets and specialized synthetic baselines, achieving up to +3\% execution accuracy in Text-to-SQL over SynSQL, +7\% average improvements on code benchmarks, and 1--3 point gains on MATH, GSM8K, and AIME. Moreover, a unified 10K-sample dataset produced by DataFlow enables base models to surpass counterparts trained on 1M Infinity-Instruct data. These results demonstrate that DataFlow provides a practical and high-performance substrate for reliable, reproducible, and scalable LLM data preparation, and establishes a system-level foundation for future data-centric AI development.
RARE: Retrieval-Augmented Reasoning Modeling
Mar 30, 2025Domain-specific intelligence demands specialized knowledge and sophisticated reasoning for problem-solving, posing significant challenges for large language models (LLMs) that struggle with knowledge hallucination and inadequate reasoning capabilities under constrained parameter budgets. Inspired by Bloom's Taxonomy in educational theory, we propose Retrieval-Augmented Reasoning Modeling (RARE), a novel paradigm that decouples knowledge storage from reasoning optimization. RARE externalizes domain knowledge to retrievable sources and internalizes domain-specific reasoning patterns during training. Specifically, by injecting retrieved knowledge into training prompts, RARE transforms learning objectives from rote memorization to contextualized reasoning application. It enables models to bypass parameter-intensive memorization and prioritize the development of higher-order cognitive processes. Our experiments demonstrate that lightweight RARE-trained models (e.g., Llama-3.1-8B) could achieve state-of-the-art performance, surpassing retrieval-augmented GPT-4 and Deepseek-R1 distilled counterparts. RARE establishes a paradigm shift where maintainable external knowledge bases synergize with compact, reasoning-optimized models, collectively driving more scalable domain-specific intelligence. Repo: https://github.com/Open-DataFlow/RARE
$\text{Memory}^3$: Language Modeling with Explicit Memory
Jul 01, 2024



The training and inference of large language models (LLMs) are together a costly process that transports knowledge from raw data to meaningful computation. Inspired by the memory hierarchy of the human brain, we reduce this cost by equipping LLMs with explicit memory, a memory format cheaper than model parameters and text retrieval-augmented generation (RAG). Conceptually, with most of its knowledge externalized to explicit memories, the LLM can enjoy a smaller parameter size, training cost, and inference cost, all proportional to the amount of remaining "abstract knowledge". As a preliminary proof of concept, we train from scratch a 2.4B LLM, which achieves better performance than much larger LLMs as well as RAG models, and maintains higher decoding speed than RAG. The model is named $\text{Memory}^3$, since explicit memory is the third form of memory in LLMs after implicit memory (model parameters) and working memory (context key-values). We introduce a memory circuitry theory to support the externalization of knowledge, and present novel techniques including a memory sparsification mechanism that makes storage tractable and a two-stage pretraining scheme that facilitates memory formation.
Deep Exponential Families
Nov 10, 2014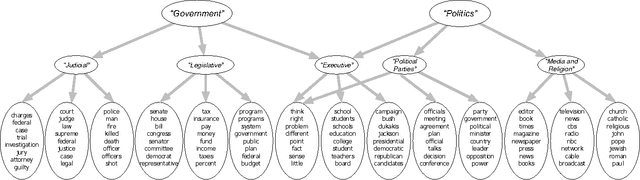

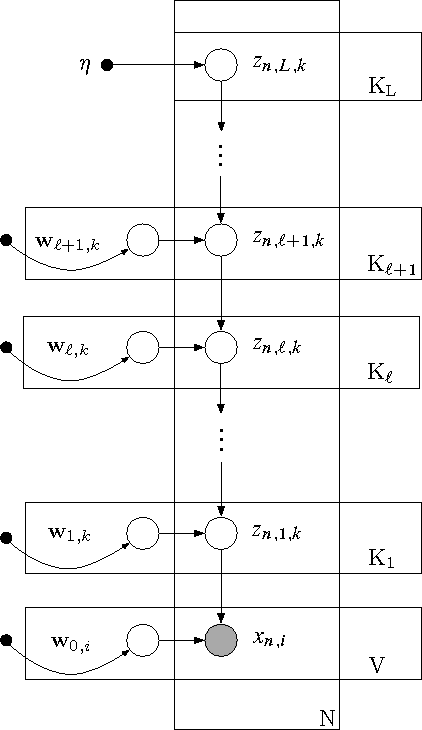
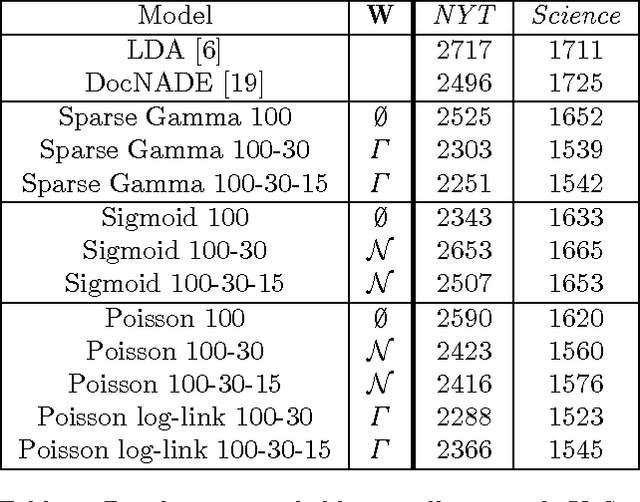
We describe \textit{deep exponential families} (DEFs), a class of latent variable models that are inspired by the hidden structures used in deep neural networks. DEFs capture a hierarchy of dependencies between latent variables, and are easily generalized to many settings through exponential families. We perform inference using recent "black box" variational inference techniques. We then evaluate various DEFs on text and combine multiple DEFs into a model for pairwise recommendation data. In an extensive study, we show that going beyond one layer improves predictions for DEFs. We demonstrate that DEFs find interesting exploratory structure in large data sets, and give better predictive performance than state-of-the-art models.