 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoise-Tolerant Hybrid Prototypical Learning with Noisy Web Data
Jan 05, 2025



We focus on the challenging problem of learning an unbiased classifier from a large number of potentially relevant but noisily labeled web images given only a few clean labeled images. This problem is particularly practical because it reduces the expensive annotation costs by utilizing freely accessible web images with noisy labels. Typically, prototypes are representative images or features used to classify or identify other images. However, in the few clean and many noisy scenarios, the class prototype can be severely biased due to the presence of irrelevant noisy images. The resulting prototypes are less compact and discriminative, as previous methods do not take into account the diverse range of images in the noisy web image collections. On the other hand, the relation modeling between noisy and clean images is not learned for the class prototype generation in an end-to-end manner, which results in a suboptimal class prototype. In this article, we introduce a similarity maximization loss named SimNoiPro. Our SimNoiPro first generates noise-tolerant hybrid prototypes composed of clean and noise-tolerant prototypes and then pulls them closer to each other. Our approach considers the diversity of noisy images by explicit division and overcomes the optimization discrepancy issue. This enables better relation modeling between clean and noisy images and helps extract judicious information from the noisy image set. The evaluation results on two extended few-shot classification benchmarks confirm that our SimNoiPro outperforms prior methods in measuring image relations and cleaning noisy data.
MC-Bench: A Benchmark for Multi-Context Visual Grounding in the Era of MLLMs
Oct 16, 2024



While multimodal large language models (MLLMs) have demonstrated extraordinary vision-language understanding capabilities and shown potential to serve as general-purpose assistants, their abilities to solve instance-level visual-language problems beyond a single image warrant further exploration. In order to assess these unproven abilities of MLLMs, this paper proposes a new visual grounding task called multi-context visual grounding, which aims to localize instances of interest across multiple images based on open-ended text prompts. To facilitate this research, we meticulously construct a new dataset MC-Bench for benchmarking the visual grounding capabilities of MLLMs. MC-Bench features 2K high-quality and manually annotated samples, consisting of instance-level labeled image pairs and corresponding text prompts that indicate the target instances in the images. In total, there are three distinct styles of text prompts, covering 20 practical skills. We benchmark over 20 state-of-the-art MLLMs and foundation models with potential multi-context visual grounding capabilities. Our evaluation reveals a non-trivial performance gap between existing MLLMs and humans across all metrics. We also observe that existing MLLMs typically outperform foundation models without LLMs only on image-level metrics, and the specialist MLLMs trained on single images often struggle to generalize to multi-image scenarios. Moreover, a simple stepwise baseline integrating advanced MLLM and a detector can significantly surpass prior end-to-end MLLMs. We hope our MC-Bench and empirical findings can encourage the research community to further explore and enhance the untapped potentials of MLLMs in instance-level tasks, particularly in multi-image contexts. Project page: https://xuyunqiu.github.io/MC-Bench/.
Point-Calibrated Spectral Neural Operators
Oct 15, 2024Two typical neural models have been extensively studied for operator learning, learning in spatial space via attention mechanism or learning in spectral space via spectral analysis technique such as Fourier Transform. Spatial learning enables point-level flexibility but lacks global continuity constraint, while spectral learning enforces spectral continuity prior but lacks point-wise adaptivity. This work innovatively combines the continuity prior and the point-level flexibility, with the introduced Point-Calibrated Spectral Transform. It achieves this by calibrating the preset spectral eigenfunctions with the predicted point-wise frequency preference via neural gate mechanism. Beyond this, we introduce Point-Calibrated Spectral Neural Operators, which learn operator mappings by approximating functions with the point-level adaptive spectral basis, thereby not only preserving the benefits of spectral prior but also boasting the superior adaptability comparable to the attention mechanism. Comprehensive experiments demonstrate its consistent performance enhancement in extensive PDE solving scenarios.
FreeLong: Training-Free Long Video Generation with SpectralBlend Temporal Attention
Jul 29, 2024Video diffusion models have made substantial progress in various video generation applications. However, training models for long video generation tasks require significant computational and data resources, posing a challenge to developing long video diffusion models. This paper investigates a straightforward and training-free approach to extend an existing short video diffusion model (e.g. pre-trained on 16-frame videos) for consistent long video generation (e.g. 128 frames). Our preliminary observation has found that directly applying the short video diffusion model to generate long videos can lead to severe video quality degradation. Further investigation reveals that this degradation is primarily due to the distortion of high-frequency components in long videos, characterized by a decrease in spatial high-frequency components and an increase in temporal high-frequency components. Motivated by this, we propose a novel solution named FreeLong to balance the frequency distribution of long video features during the denoising process. FreeLong blends the low-frequency components of global video features, which encapsulate the entire video sequence, with the high-frequency components of local video features that focus on shorter subsequences of frames. This approach maintains global consistency while incorporating diverse and high-quality spatiotemporal details from local videos, enhancing both the consistency and fidelity of long video generation. We evaluated FreeLong on multiple base video diffusion models and observed significant improvements. Additionally, our method supports coherent multi-prompt generation, ensuring both visual coherence and seamless transitions between scenes.
High-Fidelity Facial Albedo Estimation via Texture Quantization
Jun 19, 2024



Recent 3D face reconstruction methods have made significant progress in shape estimation, but high-fidelity facial albedo reconstruction remains challenging. Existing methods depend on expensive light-stage captured data to learn facial albedo maps. However, a lack of diversity in subjects limits their ability to recover high-fidelity results. In this paper, we present a novel facial albedo reconstruction model, HiFiAlbedo, which recovers the albedo map directly from a single image without the need for captured albedo data. Our key insight is that the albedo map is the illumination invariant texture map, which enables us to use inexpensive texture data to derive an albedo estimation by eliminating illumination. To achieve this, we first collect large-scale ultra-high-resolution facial images and train a high-fidelity facial texture codebook. By using the FFHQ dataset and limited UV textures, we then fine-tune the encoder for texture reconstruction from the input image with adversarial supervision in both image and UV space. Finally, we train a cross-attention module and utilize group identity loss to learn the adaptation from facial texture to the albedo domain. Extensive experimentation has demonstrated that our method exhibits excellent generalizability and is capable of achieving high-fidelity results for in-the-wild facial albedo recovery. Our code, pre-trained weights, and training data will be made publicly available at https://hifialbedo.github.io/.
DeltaPhi: Learning Physical Trajectory Residual for PDE Solving
Jun 14, 2024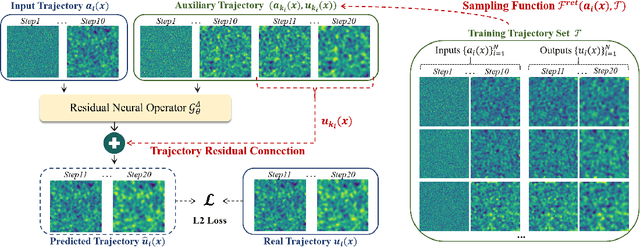
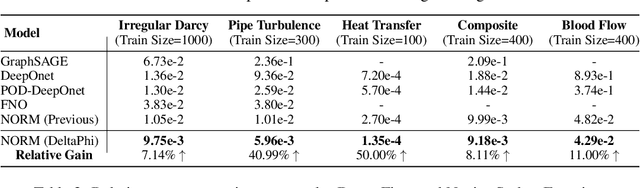
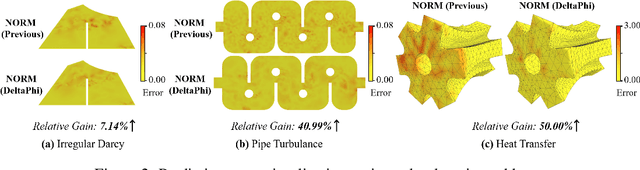
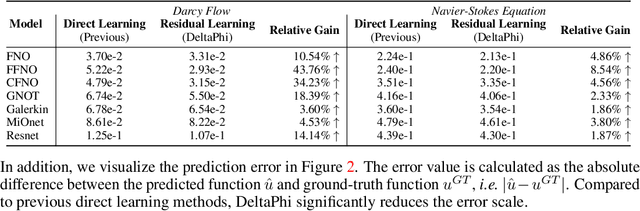
Although neural operator networks theoretically approximate any operator mapping, the limited generalization capability prevents them from learning correct physical dynamics when potential data biases exist, particularly in the practical PDE solving scenario where the available data amount is restricted or the resolution is extremely low. To address this issue, we propose and formulate the Physical Trajectory Residual Learning (DeltaPhi), which learns to predict the physical residuals between the pending solved trajectory and a known similar auxiliary trajectory. First, we transform the direct operator mapping between input-output function fields in original training data to residual operator mapping between input function pairs and output function residuals. Next, we learn the surrogate model for the residual operator mapping based on existing neural operator networks. Additionally, we design helpful customized auxiliary inputs for efficient optimization. Through extensive experiments, we conclude that, compared to direct learning, physical residual learning is preferred for PDE solving.
VillagerAgent: A Graph-Based Multi-Agent Framework for Coordinating Complex Task Dependencies in Minecraft
Jun 09, 2024In this paper, we aim to evaluate multi-agent systems against complex dependencies, including spatial, causal, and temporal constraints. First, we construct a new benchmark, named VillagerBench, within the Minecraft environment.VillagerBench comprises diverse tasks crafted to test various aspects of multi-agent collaboration, from workload distribution to dynamic adaptation and synchronized task execution. Second, we introduce a Directed Acyclic Graph Multi-Agent Framework VillagerAgent to resolve complex inter-agent dependencies and enhance collaborative efficiency. This solution incorporates a task decomposer that creates a directed acyclic graph (DAG) for structured task management, an agent controller for task distribution, and a state manager for tracking environmental and agent data. Our empirical evaluation on VillagerBench demonstrates that VillagerAgent outperforms the existing AgentVerse model, reducing hallucinations and improving task decomposition efficacy. The results underscore VillagerAgent's potential in advancing multi-agent collaboration, offering a scalable and generalizable solution in dynamic environments. The source code is open-source on GitHub (https://github.com/cnsdqd-dyb/VillagerAgent).
FragRel: Exploiting Fragment-level Relations in the External Memory of Large Language Models
Jun 05, 2024



To process contexts with unlimited length using Large Language Models (LLMs), recent studies explore hierarchically managing the long text. Only several text fragments are taken from the external memory and passed into the temporary working memory, i.e., LLM's context window. However, existing approaches isolatedly handle the text fragments without considering their structural connections, thereby suffering limited capability on texts with intensive inter-relations, e.g., coherent stories and code repositories. This work attempts to resolve this by exploiting the fragment-level relations in external memory. First, we formulate the fragment-level relations and present several instantiations for different text types. Next, we introduce a relation-aware fragment assessment criteria upon previous independent fragment assessment. Finally, we present the fragment-connected Hierarchical Memory based LLM. We validate the benefits of involving these relations on long story understanding, repository-level code generation, and long-term chatting.
AudioScenic: Audio-Driven Video Scene Editing
Apr 25, 2024



Audio-driven visual scene editing endeavors to manipulate the visual background while leaving the foreground content unchanged, according to the given audio signals. Unlike current efforts focusing primarily on image editing, audio-driven video scene editing has not been extensively addressed. In this paper, we introduce AudioScenic, an audio-driven framework designed for video scene editing. AudioScenic integrates audio semantics into the visual scene through a temporal-aware audio semantic injection process. As our focus is on background editing, we further introduce a SceneMasker module, which maintains the integrity of the foreground content during the editing process. AudioScenic exploits the inherent properties of audio, namely, audio magnitude and frequency, to guide the editing process, aiming to control the temporal dynamics and enhance the temporal consistency. First, we present an audio Magnitude Modulator module that adjusts the temporal dynamics of the scene in response to changes in audio magnitude, enhancing the visual dynamics. Second, the audio Frequency Fuser module is designed to ensure temporal consistency by aligning the frequency of the audio with the dynamics of the video scenes, thus improving the overall temporal coherence of the edited videos. These integrated features enable AudioScenic to not only enhance visual diversity but also maintain temporal consistency throughout the video. We present a new metric named temporal score for more comprehensive validation of temporal consistency. We demonstrate substantial advancements of AudioScenic over competing methods on DAVIS and Audioset datasets.
Neural Interaction Energy for Multi-Agent Trajectory Prediction
Apr 25, 2024



Maintaining temporal stability is crucial in multi-agent trajectory prediction. Insufficient regularization to uphold this stability often results in fluctuations in kinematic states, leading to inconsistent predictions and the amplification of errors. In this study, we introduce a framework called Multi-Agent Trajectory prediction via neural interaction Energy (MATE). This framework assesses the interactive motion of agents by employing neural interaction energy, which captures the dynamics of interactions and illustrates their influence on the future trajectories of agents. To bolster temporal stability, we introduce two constraints: inter-agent interaction constraint and intra-agent motion constraint. These constraints work together to ensure temporal stability at both the system and agent levels, effectively mitigating prediction fluctuations inherent in multi-agent systems. Comparative evaluations against previous methods on four diverse datasets highlight the superior prediction accuracy and generalization capabilities of our model.