 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPT-4o System Card
Oct 25, 2024GPT-4o is an autoregressive omni model that accepts as input any combination of text, audio, image, and video, and generates any combination of text, audio, and image outputs. It's trained end-to-end across text, vision, and audio, meaning all inputs and outputs are processed by the same neural network. GPT-4o can respond to audio inputs in as little as 232 milliseconds, with an average of 320 milliseconds, which is similar to human response time in conversation. It matches GPT-4 Turbo performance on text in English and code, with significant improvement on text in non-English languages, while also being much faster and 50\% cheaper in the API. GPT-4o is especially better at vision and audio understanding compared to existing models. In line with our commitment to building AI safely and consistent with our voluntary commitments to the White House, we are sharing the GPT-4o System Card, which includes our Preparedness Framework evaluations. In this System Card, we provide a detailed look at GPT-4o's capabilities, limitations, and safety evaluations across multiple categories, focusing on speech-to-speech while also evaluating text and image capabilities, and measures we've implemented to ensure the model is safe and aligned. We also include third-party assessments on dangerous capabilities, as well as discussion of potential societal impacts of GPT-4o's text and vision capabilities.
Text and Code Embeddings by Contrastive Pre-Training
Jan 24, 2022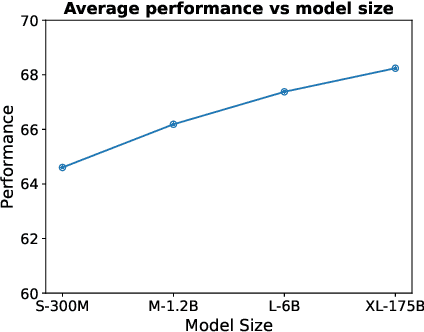
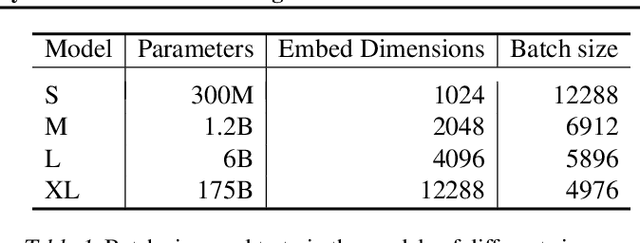
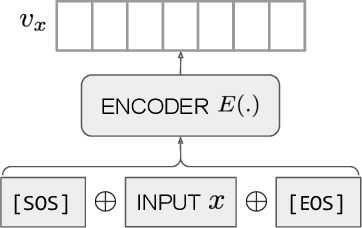
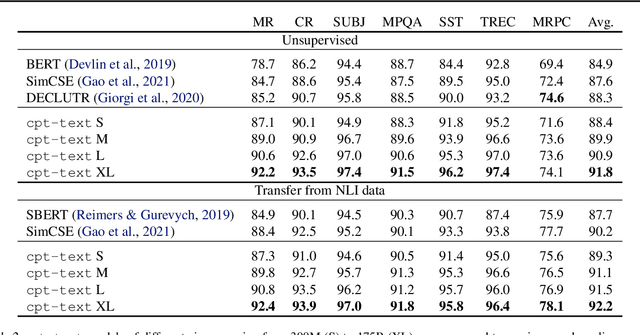
Text embeddings are useful features in many applications such as semantic search and computing text similarity. Previous work typically trains models customized for different use cases, varying in dataset choice, training objective and model architecture. In this work, we show that contrastive pre-training on unsupervised data at scale leads to high quality vector representations of text and code. The same unsupervised text embeddings that achieve new state-of-the-art results in linear-probe classification also display impressive semantic search capabilities and sometimes even perform competitively with fine-tuned models. On linear-probe classification accuracy averaging over 7 tasks, our best unsupervised model achieves a relative improvement of 4% and 1.8% over previous best unsupervised and supervised text embedding models respectively. The same text embeddings when evaluated on large-scale semantic search attains a relative improvement of 23.4%, 14.7%, and 10.6% over previous best unsupervised methods on MSMARCO, Natural Questions and TriviaQA benchmarks, respectively. Similarly to text embeddings, we train code embedding models on (text, code) pairs, obtaining a 20.8% relative improvement over prior best work on code search.
Evaluating Large Language Models Trained on Code
Jul 14, 2021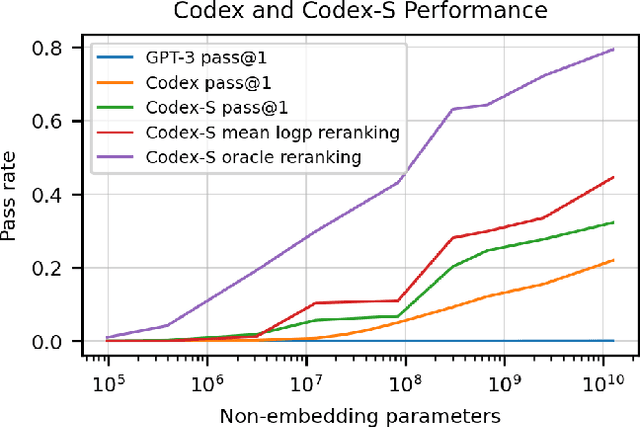
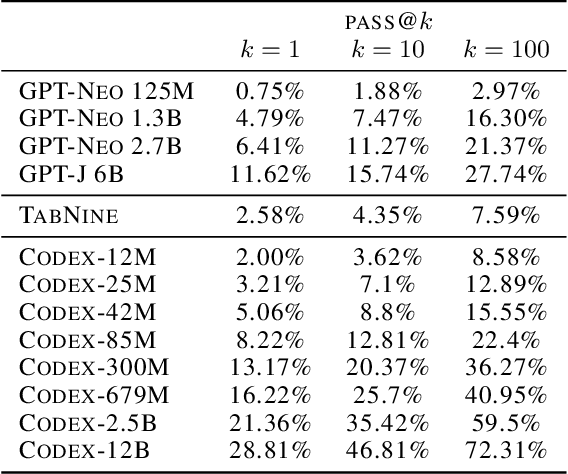
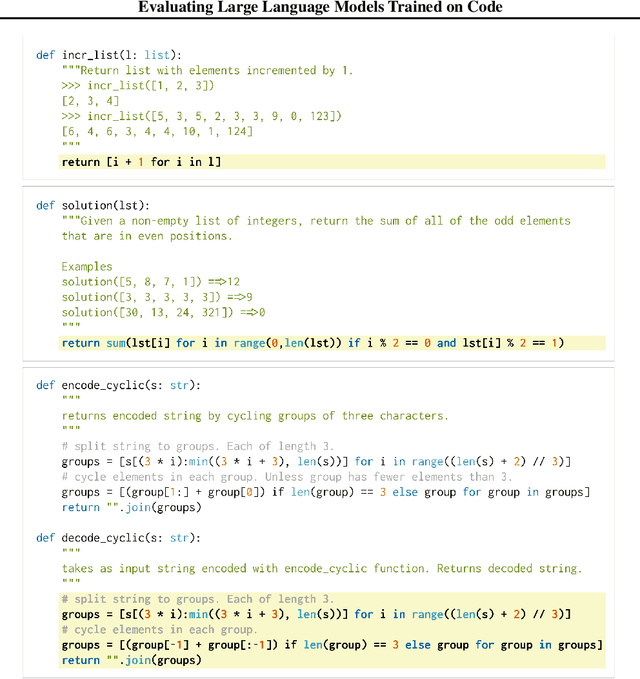
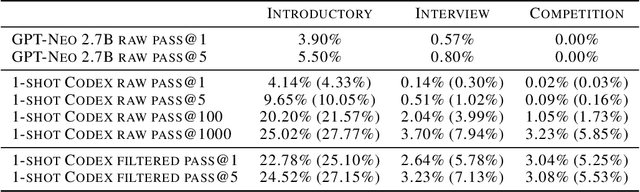
We introduce Codex, a GPT language model fine-tuned on publicly available code from GitHub, and study its Python code-writing capabilities. A distinct production version of Codex powers GitHub Copilot. On HumanEval, a new evaluation set we release to measure functional correctness for synthesizing programs from docstrings, our model solves 28.8% of the problems, while GPT-3 solves 0% and GPT-J solves 11.4%. Furthermore, we find that repeated sampling from the model is a surprisingly effective strategy for producing working solutions to difficult prompts. Using this method, we solve 70.2% of our problems with 100 samples per problem. Careful investigation of our model reveals its limitations, including difficulty with docstrings describing long chains of operations and with binding operations to variables. Finally, we discuss the potential broader impacts of deploying powerful code generation technologies, covering safety, security, and economics.
Local Knowledge Powered Conversational Agents
Oct 20, 2020


State-of-the-art conversational agents have advanced significantly in conjunction with the use of large transformer-based language models. However, even with these advancements, conversational agents still lack the ability to produce responses that are informative and coherent with the local context. In this work, we propose a dialog framework that incorporates both local knowledge as well as users' past dialogues to generate high quality conversations. We introduce an approach to build a dataset based on Reddit conversations, where outbound URL links are widely available in the conversations and the hyperlinked documents can be naturally included as local external knowledge. Using our framework and dataset, we demonstrate that incorporating local knowledge can largely improve informativeness, coherency and realisticness measures using human evaluations. In particular, our approach consistently outperforms the state-of-the-art conversational model on the Reddit dataset across all three measures. We also find that scaling the size of our models from 117M to 8.3B parameters yields consistent improvement of validation perplexity as well as human evaluated metrics. Our model with 8.3B parameters can generate human-like responses as rated by various human evaluations in a single-turn dialog setting.
BioMegatron: Larger Biomedical Domain Language Model
Oct 14, 2020
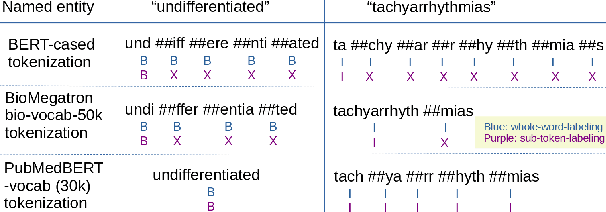
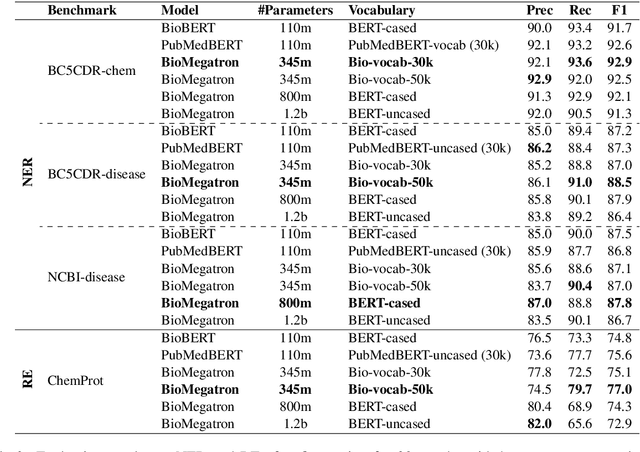
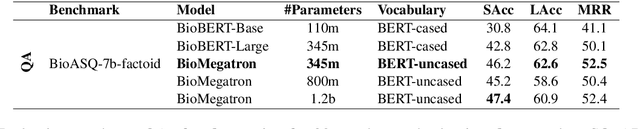
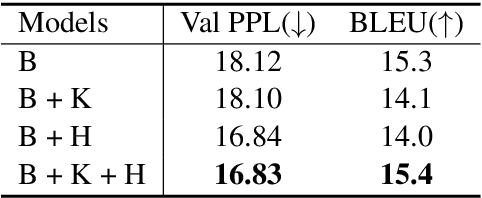
There has been an influx of biomedical domain-specific language models, showing language models pre-trained on biomedical text perform better on biomedical domain benchmarks than those trained on general domain text corpora such as Wikipedia and Books. Yet, most works do not study the factors affecting each domain language application deeply. Additionally, the study of model size on domain-specific models has been mostly missing. We empirically study and evaluate several factors that can affect performance on domain language applications, such as the sub-word vocabulary set, model size, pre-training corpus, and domain transfer. We show consistent improvements on benchmarks with our larger BioMegatron model trained on a larger domain corpus, contributing to our understanding of domain language model applications. We demonstrate noticeable improvements over the previous state-of-the-art (SOTA) on standard biomedical NLP benchmarks of named entity recognition, relation extraction, and question answering. Model checkpoints and code are available at [https://ngc.nvidia.com] and [https://github.com/NVIDIA/NeMo].
MEGATRON-CNTRL: Controllable Story Generation with External Knowledge Using Large-Scale Language Models
Oct 02, 2020
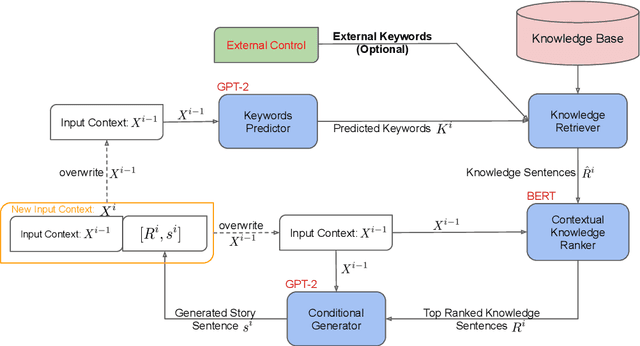
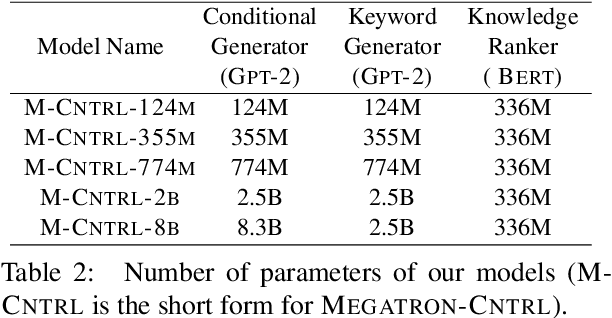
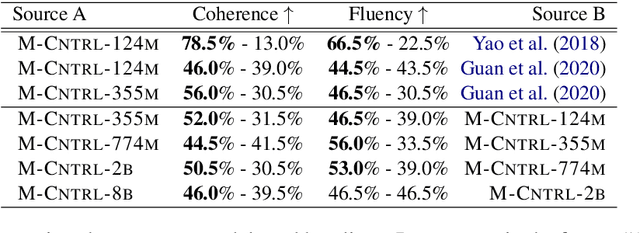
Existing pre-trained large language models have shown unparalleled generative capabilities. However, they are not controllable. In this paper, we propose MEGATRON-CNTRL, a novel framework that uses large-scale language models and adds control to text generation by incorporating an external knowledge base. Our framework consists of a keyword predictor, a knowledge retriever, a contextual knowledge ranker, and a conditional text generator. As we do not have access to ground-truth supervision for the knowledge ranker, we make use of weak supervision from sentence embedding. The empirical results show that our model generates more fluent, consistent, and coherent stories with less repetition and higher diversity compared to prior work on the ROC story dataset. We showcase the controllability of our model by replacing the keywords used to generate stories and re-running the generation process. Human evaluation results show that 77.5% of these stories are successfully controlled by the new keywords. Furthermore, by scaling our model from 124 million to 8.3 billion parameters we demonstrate that larger models improve both the quality of generation (from 74.5% to 93.0% for consistency) and controllability (from 77.5% to 91.5%).
Large Scale Multi-Actor Generative Dialog Modeling
May 13, 2020
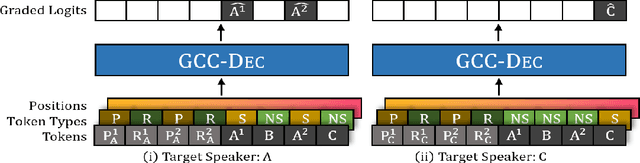

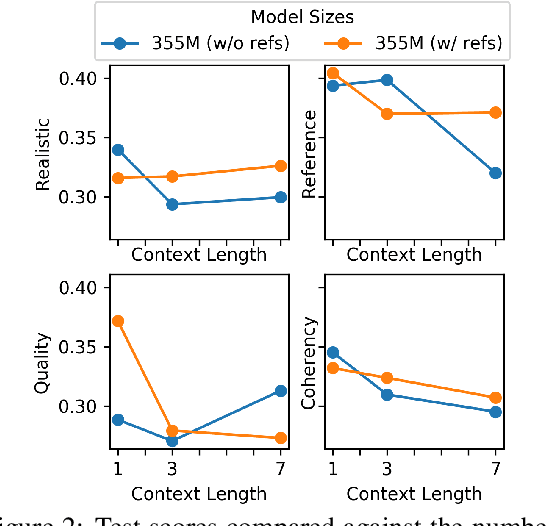
Non-goal oriented dialog agents (i.e. chatbots) aim to produce varying and engaging conversations with a user; however, they typically exhibit either inconsistent personality across conversations or the average personality of all users. This paper addresses these issues by controlling an agent's persona upon generation via conditioning on prior conversations of a target actor. In doing so, we are able to utilize more abstract patterns within a person's speech and better emulate them in generated responses. This work introduces the Generative Conversation Control model, an augmented and fine-tuned GPT-2 language model that conditions on past reference conversations to probabilistically model multi-turn conversations in the actor's persona. We introduce an accompanying data collection procedure to obtain 10.3M conversations from 6 months worth of Reddit comments. We demonstrate that scaling model sizes from 117M to 8.3B parameters yields an improvement from 23.14 to 13.14 perplexity on 1.7M held out Reddit conversations. Increasing model scale yielded similar improvements in human evaluations that measure preference of model samples to the held out target distribution in terms of realism (31% increased to 37% preference), style matching (37% to 42%), grammar and content quality (29% to 42%), and conversation coherency (32% to 40%). We find that conditionally modeling past conversations improves perplexity by 0.47 in automatic evaluations. Through human trials we identify positive trends between conditional modeling and style matching and outline steps to further improve persona control.
Training Question Answering Models From Synthetic Data
Feb 22, 2020
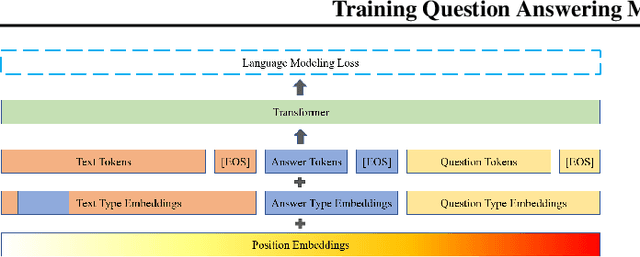
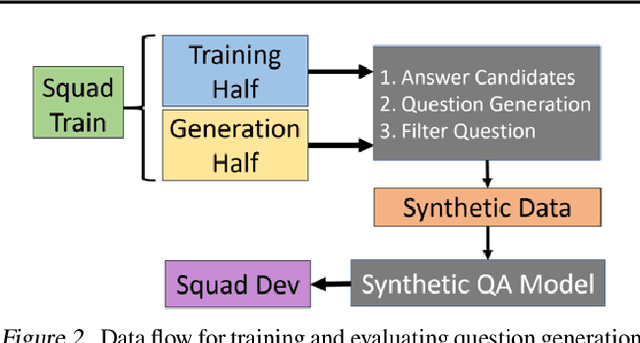
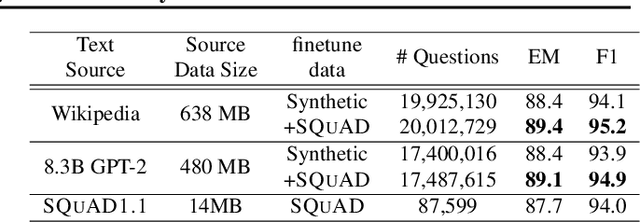
Question and answer generation is a data augmentation method that aims to improve question answering (QA) models given the limited amount of human labeled data. However, a considerable gap remains between synthetic and human-generated question-answer pairs. This work aims to narrow this gap by taking advantage of large language models and explores several factors such as model size, quality of pretrained models, scale of data synthesized, and algorithmic choices. On the SQuAD1.1 question answering task, we achieve higher accuracy using solely synthetic questions and answers than when using the SQuAD1.1 training set questions alone. Removing access to real Wikipedia data, we synthesize questions and answers from a synthetic corpus generated by an 8.3 billion parameter GPT-2 model. With no access to human supervision and only access to other models, we are able to train state of the art question answering networks on entirely model-generated data that achieve 88.4 Exact Match (EM) and 93.9 F1 score on the SQuAD1.1 dev set. We further apply our methodology to SQuAD2.0 and show a 2.8 absolute gain on EM score compared to prior work using synthetic data.
Zero-shot Text Classification With Generative Language Models
Dec 10, 2019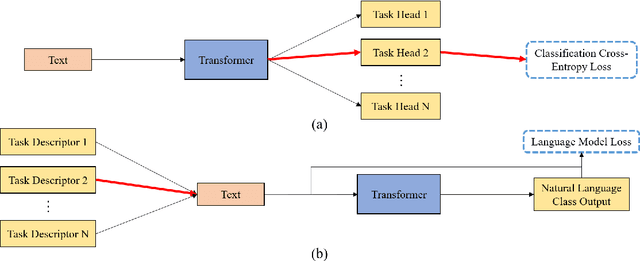
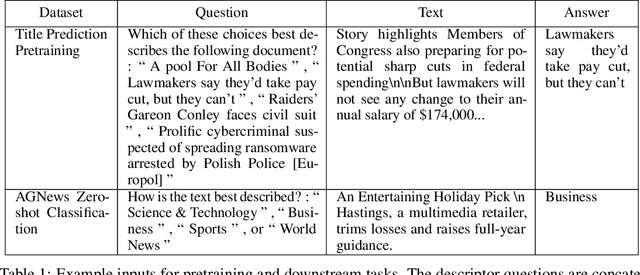
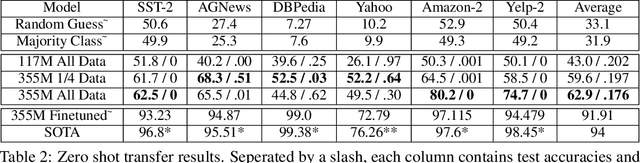
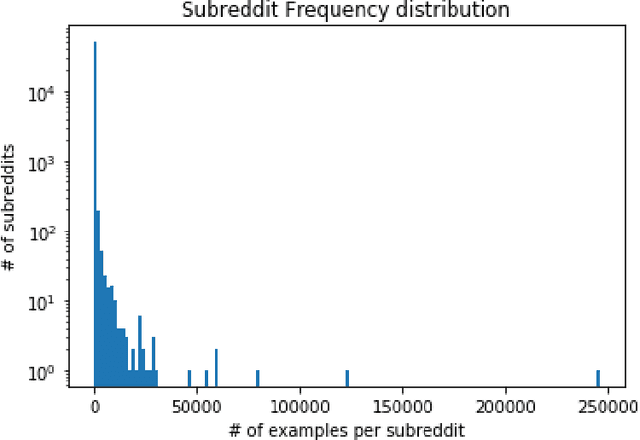
This work investigates the use of natural language to enable zero-shot model adaptation to new tasks. We use text and metadata from social commenting platforms as a source for a simple pretraining task. We then provide the language model with natural language descriptions of classification tasks as input and train it to generate the correct answer in natural language via a language modeling objective. This allows the model to generalize to new classification tasks without the need for multiple multitask classification heads. We show the zero-shot performance of these generative language models, trained with weak supervision, on six benchmark text classification datasets from the torchtext library. Despite no access to training data, we achieve up to a 45% absolute improvement in classification accuracy over random or majority class baselines. These results show that natural language can serve as simple and powerful descriptors for task adaptation. We believe this points the way to new metalearning strategies for text problems.
Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
Oct 05, 2019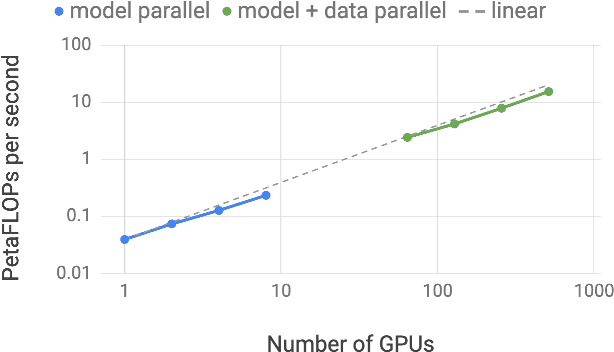
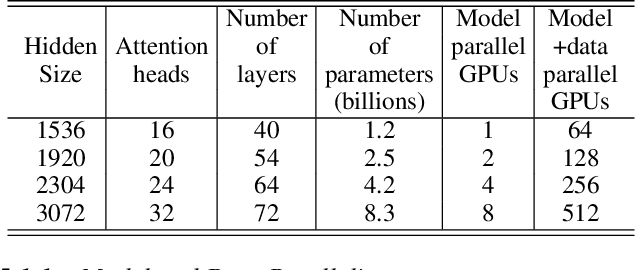
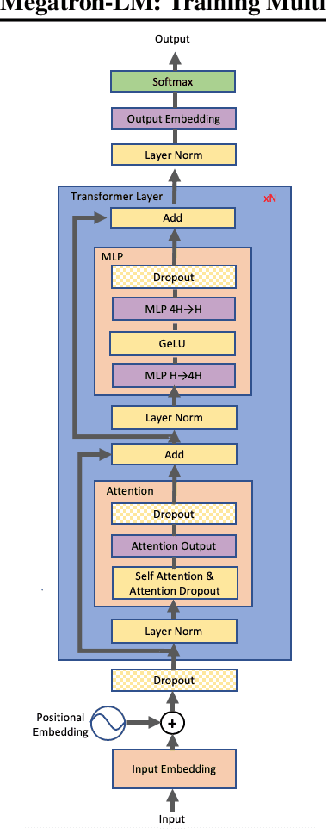

Recent work in unsupervised language modeling demonstrates that training large neural language models advances the state of the art in Natural Language Processing applications. However, for very large models, memory constraints limit the size of models that can be practically trained. Model parallelism allows us to train larger models, because the parameters can be split across multiple processors. In this work, we implement a simple, efficient intra-layer model parallel approach that enables training state of the art transformer language models with billions of parameters. Our approach does not require a new compiler or library changes, is orthogonal and complimentary to pipeline model parallelism, and can be fully implemented with the insertion of a few communication operations in native PyTorch. We illustrate this approach by converging an 8.3 billion parameter transformer language model using 512 GPUs, making it the largest transformer model ever trained at 24x times the size of BERT and 5.6x times the size of GPT-2. We sustain up to 15.1 PetaFLOPs per second across the entire application with 76% scaling efficiency, compared to a strong single processor baseline that sustains 39 TeraFLOPs per second, which is 30% of peak FLOPs. The model is trained on 174GB of text, requiring 12 ZettaFLOPs over 9.2 days to converge. Transferring this language model achieves state of the art (SOTA) results on the WikiText103 (10.8 compared to SOTA perplexity of 16.4) and LAMBADA (66.5% compared to SOTA accuracy of 63.2%) datasets. We release training and evaluation code, as well as the weights of our smaller portable model, for reproducibility.