 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReliable to Expressive: A Curriculum for Rubric-Following Safety Judges
Jun 08, 2026Safety judges are increasingly deployed to evaluate model outputs against evolving criteria, yet recent meta-evaluation work shows they remain brittle under prompt and rubric variation, with false negative-rate swings of up to 0.24 reported for stylistic perturbations alone. We argue that safety judgment is fundamentally a rubric-following problem: a robust judge must apply the given evaluation criteria consistently across rubric formulations rather than memorize one specific template. We propose a training strategy that combines (i) instance-conditioned dynamic rubrics generated from prompt-response-label triples to expose the judge to the variability of evaluation criteria, and (ii) a reliable-to-expressive curriculum that begins with clean fixed-rubric supervision and progressively introduces noisier dynamic-rubric data. We evaluate on a single human-labeled set under three contrasting rubric prompts (HarmBench-style, ShieldGemma-style, and a domain-specific rubric). Our 12B curriculum judge achieves 94.12-94.88% accuracy across the three rubrics with a cross-rubric range of only 0.76, outperforming general-purpose LLMs, dedicated safety classifiers, and reasoning-oriented judges up to 30B in both peak accuracy and stability. An ablation shows that naively mixing dynamic rubrics into SFT increases cross rubric variance (1.44 -> 3.60); only the curriculum schedule recovers and improves on the fixed rubric baseline (variance 0.76).
Culturally-Adapted Red-Teaming Across East and Southeast Asian Contexts: A Methodological and Comparative Analysis
Jun 08, 2026Multilingual safety evaluation of large language models (LLMs) has predominantly relied on direct translation (DT) of English benchmarks into target languages - an approach that converts surface-level linguistic form while failing to reflect the cultural context embedded in threat scenarios, social norms, and legal frameworks. We construct paired DT and culturally-adapted (CA) datasets via 1:1 seed matching for four languages - Korean (KO), Japanese (JA), Thai (TH), and Khmer (KM) - and compare Attack Success Rate (ASR) and Cultural Realism scores across four open-source LLM. CA prompts yield Delta-ASR > 0 across all 16 language x model combinations (mean +9.3 pp), and DT-based evaluation underestimates risk in 44 of 48 category x language combinations. Language-level analysis reveals that the distribution of threat forms is heterogeneous across languages. Cultural Realism analysis further shows that DT Cultural Depth (C3) scores remain consistently below 1.0 out of 3.0 across all four languages (mean 0.17), whereas CA scores reach up to 2.51, indicating that direct translation produces inputs systematically divergent from those encountered in real-world multicultural settings. These findings demonstrate that adapting benchmarks to language-specific cultural contexts - rather than relying on linguistic translation alone - is necessary for valid multilingual LLM safety evaluation.
Korean Culture into LLM Alignment: Toward Cultural Coherence
Jun 05, 2026Cultural-aspect work on large language models is dominated by a negative target: which outputs to suppress. We argue that a constructive counterpart is also needed, a working definition of what a culturally coherent response is rather than only what it must avoid, and instantiate it for Korean. We design an alignment-data pipeline around a prompt-based LLM seed generator that expands a Korean harm taxonomy, with a Korean-culturally-adapted safe-response policy at its centre: a per-category guideline grounded in Korean legal frameworks, social norms, and interpretive conventions, against which three frontier models each produce a candidate response. DPO fine-tuning on the resulting triplets improves the Korean cultural safe rate across six open-weight LLMs while causing no large degradation on Korean general-capability benchmarks, and qualitative outputs show fine-tuned models naming Korean statutes and institutional procedures and, where appropriate, supplying constructive Korean-context information alongside refusal.
Geometry-Correct Diffusion Posterior Sampling with Denoiser-Pullback Curvature Guidance and Manifold-Aligned Damping
May 27, 2026Diffusion posterior sampling conditions diffusion priors on measurements, but data-consistency updates are typically scaled by hand-tuned guidance weights and can destabilize sampling under stiff, operator-dependent curvature. We replace scalar guidance with a per-noise-level damped Gauss--Newton correction computed in diffusion-state coordinates. The correction pulls likelihood gradients back through the denoiser, uses a one-sided curvature model that avoids forward denoiser Jacobians, and applies diffusion-calibrated rank-one damping aligned with the denoiser residual. Each correction is solved with matrix-free GMRES using automatic differentiation, and sampling proceeds with a variance-preserving Langevin transition with a closed-form drift/noise split. On FFHQ and ImageNet across inverse problems, it achieves competitive PSNR/SSIM/LPIPS while running markedly faster than most of the compared baselines; on accelerated MRI reconstruction, it achieves the best PSNR/SSIM among the compared baselines.
* Code: https://github.com/Seunghyeok0715/CLAMP
STAR-Teaming: A Strategy-Response Multiplex Network Approach to Automated LLM Red Teaming
Apr 21, 2026While Large Language Models (LLMs) are widely used, they remain susceptible to jailbreak prompts that can elicit harmful or inappropriate responses. This paper introduces STAR-Teaming, a novel black-box framework for automated red teaming that effectively generates such prompts. STAR-Teaming integrates a Multi-Agent System (MAS) with a Strategy-Response Multiplex Network and employs network-driven optimization to sample effective attack strategies. This network-based approach recasts the intractable high-dimensional embedding space into a tractable structure, yielding two key advantages: it enhances the interpretability of the LLM's strategic vulnerabilities, and it streamlines the search for effective strategies by organizing the search space into semantic communities, thereby preventing redundant exploration. Empirical results demonstrate that STAR-Teaming significantly surpasses existing methods, achieving a higher attack success rate (ASR) at a lower computational cost. Extensive experiments validate the effectiveness and explainability of the Multiplex Network. The code is available at https://github.com/selectstar-ai/STAR-Teaming-paper.
LIBERO-Para: A Diagnostic Benchmark and Metrics for Paraphrase Robustness in VLA Models
Mar 30, 2026Vision-Language-Action (VLA) models achieve strong performance in robotic manipulation by leveraging pre-trained vision-language backbones. However, in downstream robotic settings, they are typically fine-tuned with limited data, leading to overfitting to specific instruction formulations and leaving robustness to paraphrased instructions underexplored. To study this gap, we introduce LIBERO-Para, a controlled benchmark that independently varies action expressions and object references for fine-grained analysis of linguistic generalization. Across seven VLA configurations (0.6B-7.5B), we observe consistent performance degradation of 22-52 pp under paraphrasing. This degradation is primarily driven by object-level lexical variation: even simple synonym substitutions cause large drops, indicating reliance on surface-level matching rather than semantic grounding. Moreover, 80-96% of failures arise from planning-level trajectory divergence rather than execution errors, showing that paraphrasing disrupts task identification. Binary success rate treats all paraphrases equally, obscuring whether models perform consistently across difficulty levels or rely on easier cases. To address this, we propose PRIDE, a metric that quantifies paraphrase difficulty using semantic and syntactic factors. Our benchmark and corresponding code are available at: https://github.com/cau-hai-lab/LIBERO-Para
FAST-DIPS: Adjoint-Free Analytic Steps and Hard-Constrained Likelihood Correction for Diffusion-Prior Inverse Problems
Mar 02, 2026Training-free diffusion priors enable inverse-problem solvers without retraining, but for nonlinear forward operators data consistency often relies on repeated derivatives or inner optimization/MCMC loops with conservative step sizes, incurring many iterations and denoiser/score evaluations. We propose a training-free solver that replaces these inner loops with a hard measurement-space feasibility constraint (closed-form projection) and an analytic, model-optimal step size, enabling a small, fixed compute budget per noise level. Anchored at the denoiser prediction, the correction is approximated via an adjoint-free, ADMM-style splitting with projection and a few steepest-descent updates, using one VJP and either one JVP or a forward-difference probe, followed by backtracking and decoupled re-annealing. We prove local model optimality and descent under backtracking for the step-size rule, and derive an explicit KL bound for mode-substitution re-annealing under a local Gaussian conditional surrogate. We also develop a latent variant and a one-parameter pixel$\rightarrow$latent hybrid schedule. Experiments achieve competitive PSNR/SSIM/LPIPS with up to 19.5$\times$ speedup, without hand-coded adjoints or inner MCMC.
SURE Guided Posterior Sampling: Trajectory Correction for Diffusion-Based Inverse Problems
Dec 29, 2025Diffusion models have emerged as powerful learned priors for solving inverse problems. However, current iterative solving approaches which alternate between diffusion sampling and data consistency steps typically require hundreds or thousands of steps to achieve high quality reconstruction due to accumulated errors. We address this challenge with SURE Guided Posterior Sampling (SGPS), a method that corrects sampling trajectory deviations using Stein's Unbiased Risk Estimate (SURE) gradient updates and PCA based noise estimation. By mitigating noise induced errors during the critical early and middle sampling stages, SGPS enables more accurate posterior sampling and reduces error accumulation. This allows our method to maintain high reconstruction quality with fewer than 100 Neural Function Evaluations (NFEs). Our extensive evaluation across diverse inverse problems demonstrates that SGPS consistently outperforms existing methods at low NFE counts.
Joint Spectrum Sensing and Resource Allocation for OFDMA-based Underwater Acoustic Communications
Jun 16, 2025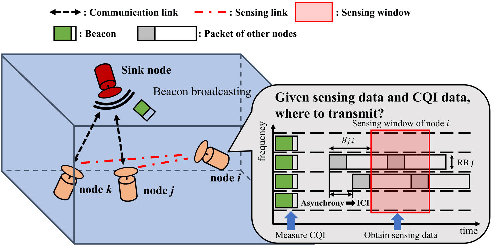
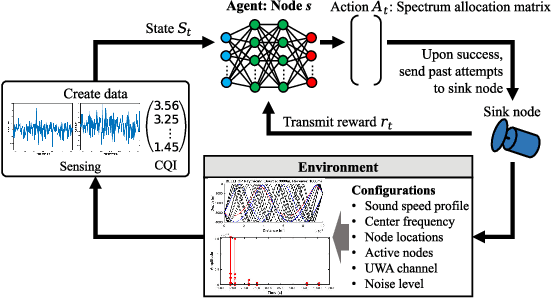
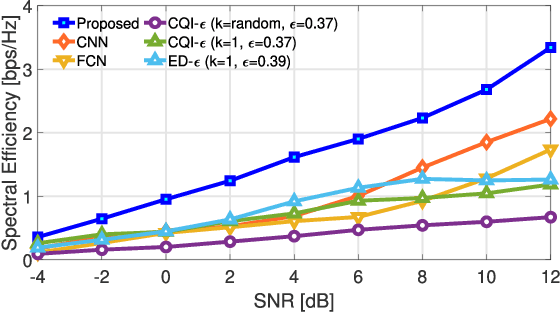
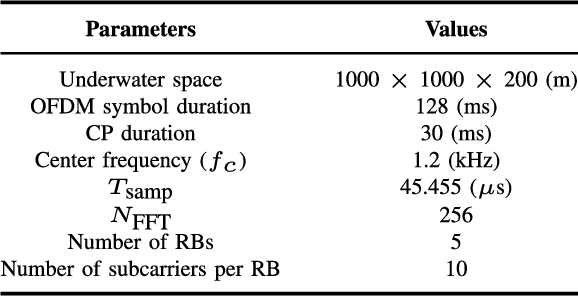
Underwater acoustic (UWA) communications generally rely on cognitive radio (CR)-based ad-hoc networks due to challenges such as long propagation delay, limited channel resources, and high attenuation. To address the constraints of limited frequency resources, UWA communications have recently incorporated orthogonal frequency division multiple access (OFDMA), significantly enhancing spectral efficiency (SE) through multiplexing gains. Still, {the} low propagation speed of UWA signals, combined with {the} dynamic underwater environment, creates asynchrony in multiple access scenarios. This causes inaccurate spectrum sensing as inter-carrier interference (ICI) increases, which leads to difficulties in resource allocation. As efficient resource allocation is essential for achieving high-quality communication in OFDMA-based CR networks, these challenges degrade communication reliability in UWA systems. To resolve the issue, we propose an end-to-end sensing and resource optimization method using deep reinforcement learning (DRL) in an OFDMA-based UWA-CR network. Through extensive simulations, we confirm that the proposed method is superior to baseline schemes, outperforming other methods by 42.9 % in SE and 4.4 % in communication success rate.
RAPID: Robust and Agile Planner Using Inverse Reinforcement Learning for Vision-Based Drone Navigation
Feb 04, 2025This paper introduces a learning-based visual planner for agile drone flight in cluttered environments. The proposed planner generates collision-free waypoints in milliseconds, enabling drones to perform agile maneuvers in complex environments without building separate perception, mapping, and planning modules. Learning-based methods, such as behavior cloning (BC) and reinforcement learning (RL), demonstrate promising performance in visual navigation but still face inherent limitations. BC is susceptible to compounding errors due to limited expert imitation, while RL struggles with reward function design and sample inefficiency. To address these limitations, this paper proposes an inverse reinforcement learning (IRL)-based framework for high-speed visual navigation. By leveraging IRL, it is possible to reduce the number of interactions with simulation environments and improve capability to deal with high-dimensional spaces while preserving the robustness of RL policies. A motion primitive-based path planning algorithm collects an expert dataset with privileged map data from diverse environments, ensuring comprehensive scenario coverage. By leveraging both the acquired expert and learner dataset gathered from the agent's interactions with the simulation environments, a robust reward function and policy are learned across diverse states. While the proposed method is trained in a simulation environment only, it can be directly applied to real-world scenarios without additional training or tuning. The performance of the proposed method is validated in both simulation and real-world environments, including forests and various structures. The trained policy achieves an average speed of 7 m/s and a maximum speed of 8.8 m/s in real flight experiments. To the best of our knowledge, this is the first work to successfully apply an IRL framework for high-speed visual navigation of drones.