 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA$^3$T: Alignment-Aware Acoustic and Text Pretraining for Speech Synthesis and Editing
Mar 18, 2022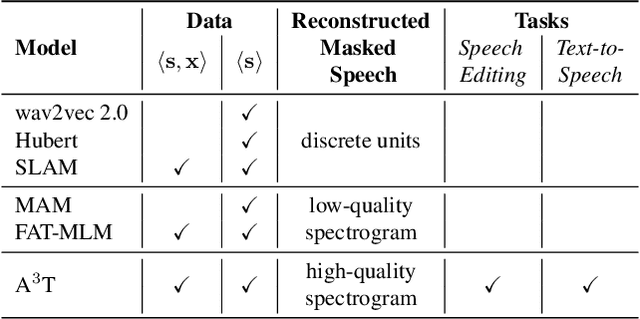
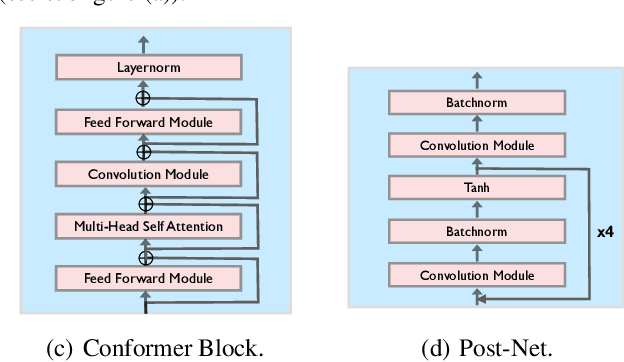

Recently, speech representation learning has improved many speech-related tasks such as speech recognition, speech classification, and speech-to-text translation. However, all the above tasks are in the direction of speech understanding, but for the inverse direction, speech synthesis, the potential of representation learning is yet to be realized, due to the challenging nature of generating high-quality speech. To address this problem, we propose our framework, Alignment-Aware Acoustic-Text Pretraining (A$^3$T), which reconstructs masked acoustic signals with text input and acoustic-text alignment during training. In this way, the pretrained model can generate high quality of reconstructed spectrogram, which can be applied to the speech editing and unseen speaker TTS directly. Experiments show A$^3$T outperforms SOTA models on speech editing, and improves multi-speaker speech synthesis without the external speaker verification model.
Computation Rate Maximum for Mobile Terminals in UAV-assisted Wireless Powered MEC Networks with Fairness Constraint
Sep 13, 2021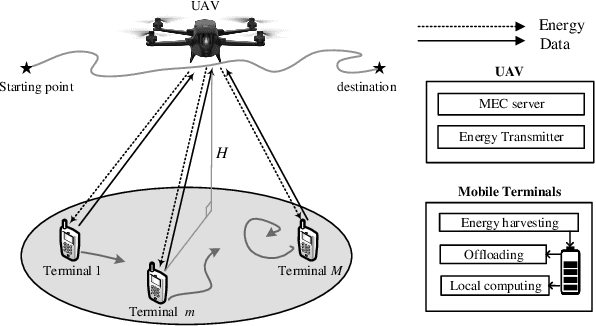
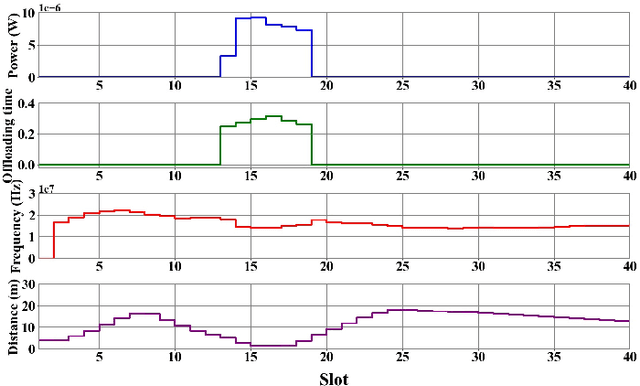
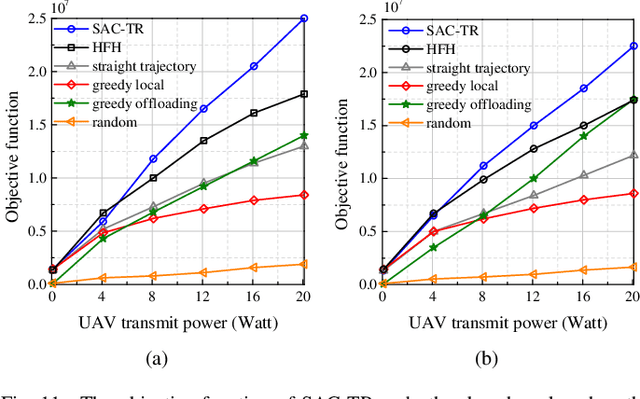
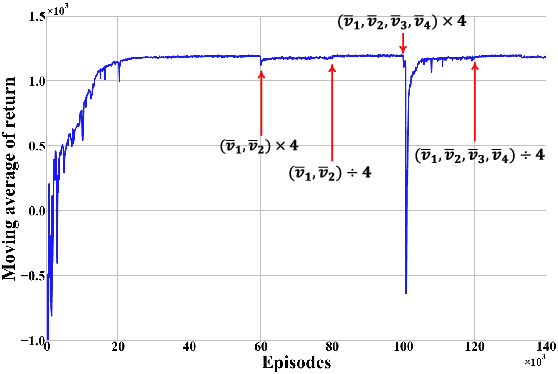
This paper investigates an unmanned aerial vehicle (UAV)-assisted wireless powered mobile-edge computing (MEC) system, where the UAV powers the mobile terminals by wireless power transfer (WPT) and provides computation service for them. We aim to maximize the computation rate of terminals while ensuring fairness among them. Considering the random trajectories of mobile terminals, we propose a soft actor-critic (SAC)-based UAV trajectory planning and resource allocation (SAC-TR) algorithm, which combines off-policy and maximum entropy reinforcement learning to promote the convergence of the algorithm. We design the reward as a heterogeneous function of computation rate, fairness, and reaching of destination. Simulation results show that SAC-TR can quickly adapt to varying network environments and outperform representative benchmarks in a variety of situations.
The Role of Phonetic Units in Speech Emotion Recognition
Aug 02, 2021
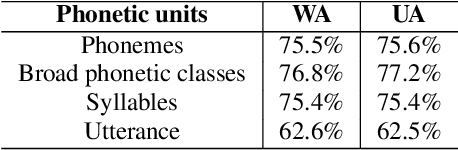
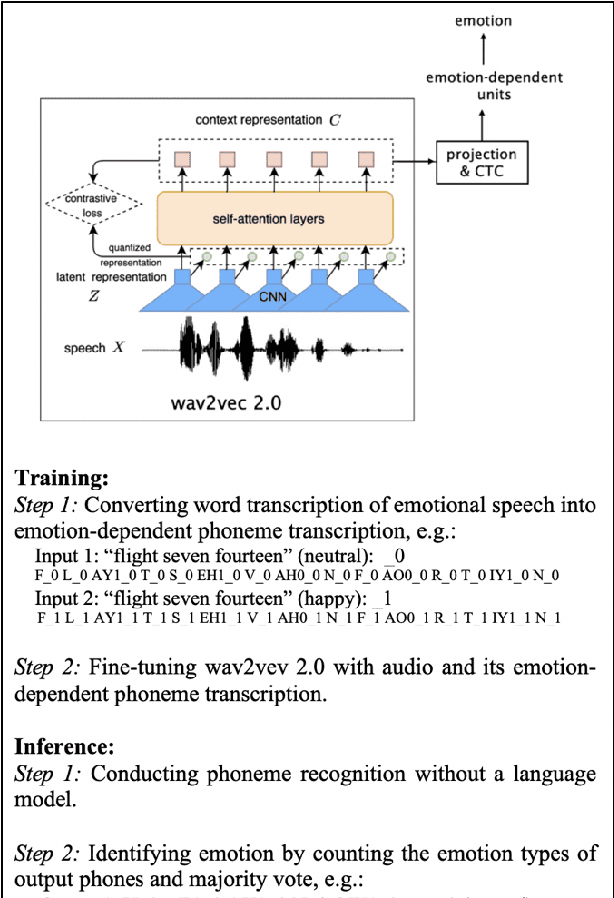
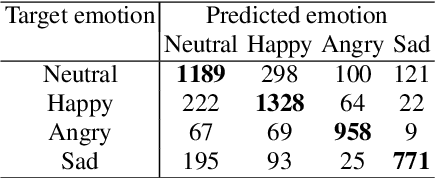
We propose a method for emotion recognition through emotiondependent speech recognition using Wav2vec 2.0. Our method achieved a significant improvement over most previously reported results on IEMOCAP, a benchmark emotion dataset. Different types of phonetic units are employed and compared in terms of accuracy and robustness of emotion recognition within and across datasets and languages. Models of phonemes, broad phonetic classes, and syllables all significantly outperform the utterance model, demonstrating that phonetic units are helpful and should be incorporated in speech emotion recognition. The best performance is from using broad phonetic classes. Further research is needed to investigate the optimal set of broad phonetic classes for the task of emotion recognition. Finally, we found that Wav2vec 2.0 can be fine-tuned to recognize coarser-grained or larger phonetic units than phonemes, such as broad phonetic classes and syllables.
Decoupling recognition and transcription in Mandarin ASR
Aug 02, 2021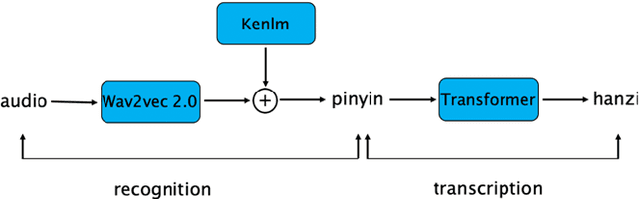
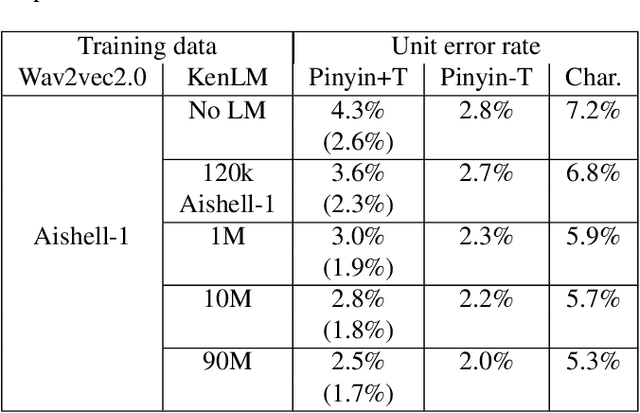
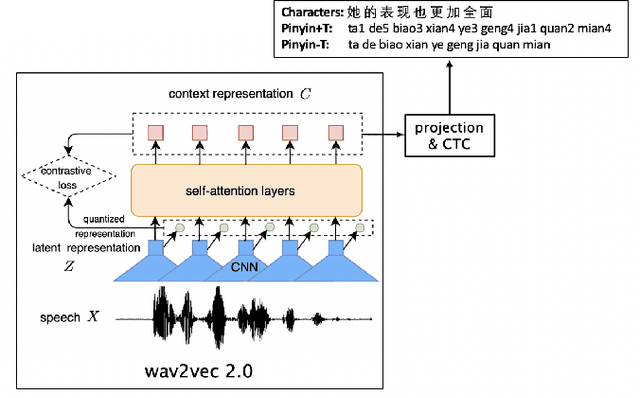
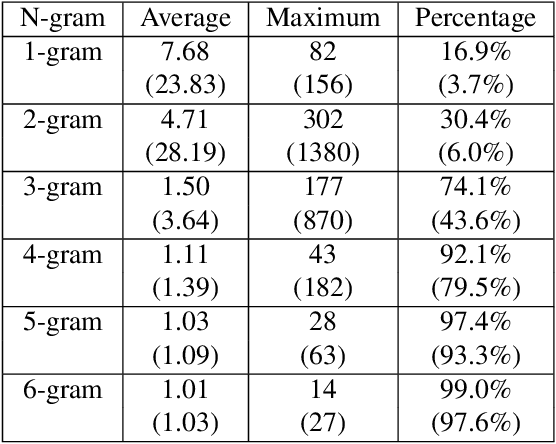
Much of the recent literature on automatic speech recognition (ASR) is taking an end-to-end approach. Unlike English where the writing system is closely related to sound, Chinese characters (Hanzi) represent meaning, not sound. We propose factoring audio -> Hanzi into two sub-tasks: (1) audio -> Pinyin and (2) Pinyin -> Hanzi, where Pinyin is a system of phonetic transcription of standard Chinese. Factoring the audio -> Hanzi task in this way achieves 3.9% CER (character error rate) on the Aishell-1 corpus, the best result reported on this dataset so far.
Structure-aware Interactive Graph Neural Networks for the Prediction of Protein-Ligand Binding Affinity
Jul 21, 2021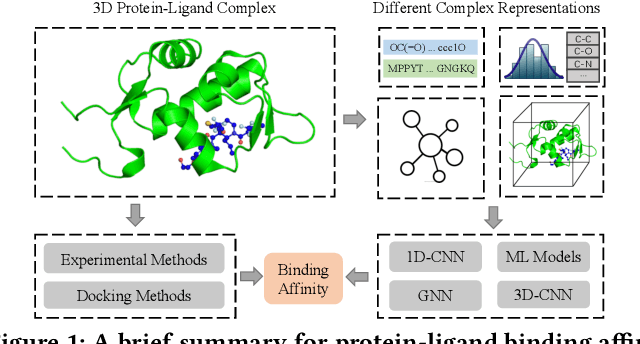
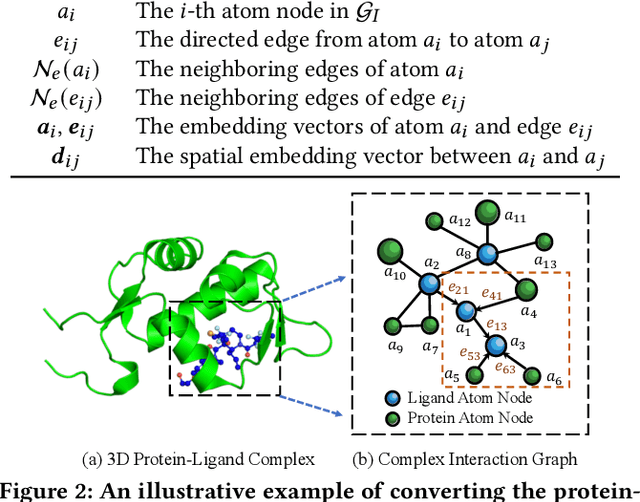
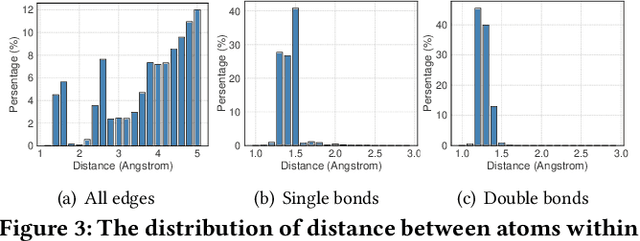
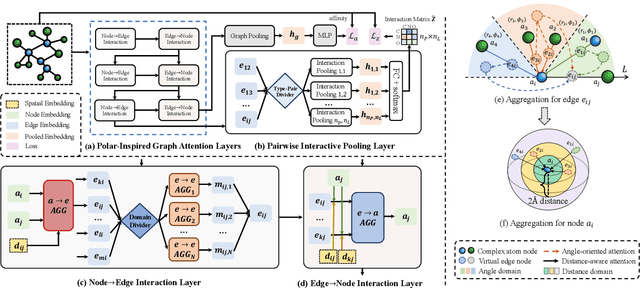
Drug discovery often relies on the successful prediction of protein-ligand binding affinity. Recent advances have shown great promise in applying graph neural networks (GNNs) for better affinity prediction by learning the representations of protein-ligand complexes. However, existing solutions usually treat protein-ligand complexes as topological graph data, thus the biomolecular structural information is not fully utilized. The essential long-range interactions among atoms are also neglected in GNN models. To this end, we propose a structure-aware interactive graph neural network (SIGN) which consists of two components: polar-inspired graph attention layers (PGAL) and pairwise interactive pooling (PiPool). Specifically, PGAL iteratively performs the node-edge aggregation process to update embeddings of nodes and edges while preserving the distance and angle information among atoms. Then, PiPool is adopted to gather interactive edges with a subsequent reconstruction loss to reflect the global interactions. Exhaustive experimental study on two benchmarks verifies the superiority of SIGN.
Direct Simultaneous Speech-to-Text Translation Assisted by Synchronized Streaming ASR
Jun 11, 2021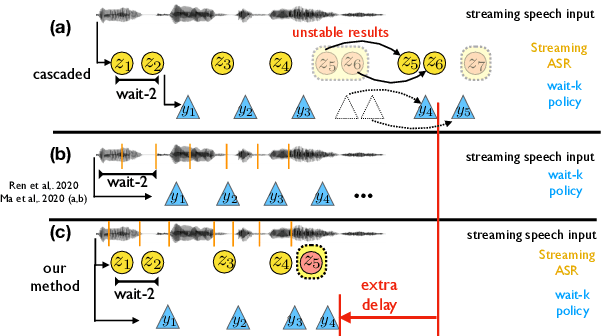
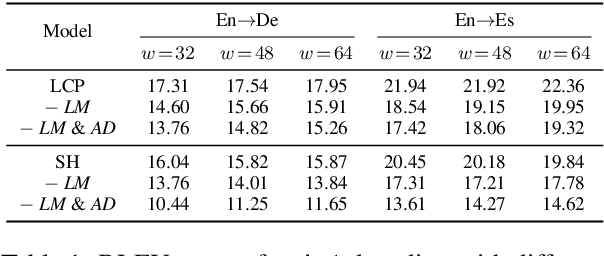
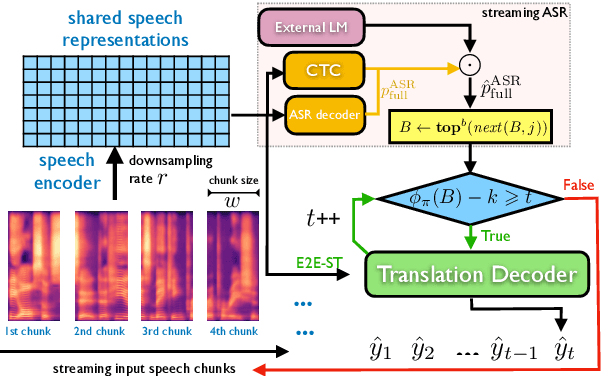
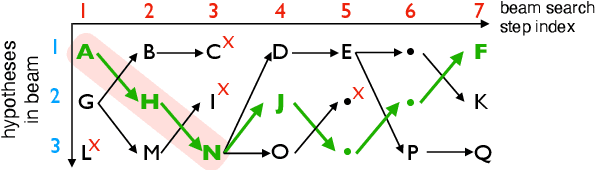
Simultaneous speech-to-text translation is widely useful in many scenarios. The conventional cascaded approach uses a pipeline of streaming ASR followed by simultaneous MT, but suffers from error propagation and extra latency. To alleviate these issues, recent efforts attempt to directly translate the source speech into target text simultaneously, but this is much harder due to the combination of two separate tasks. We instead propose a new paradigm with the advantages of both cascaded and end-to-end approaches. The key idea is to use two separate, but synchronized, decoders on streaming ASR and direct speech-to-text translation (ST), respectively, and the intermediate results of ASR guide the decoding policy of (but is not fed as input to) ST. During training time, we use multitask learning to jointly learn these two tasks with a shared encoder. En-to-De and En-to-Es experiments on the MuSTC dataset demonstrate that our proposed technique achieves substantially better translation quality at similar levels of latency.
Fused Acoustic and Text Encoding for Multimodal Bilingual Pretraining and Speech Translation
Feb 10, 2021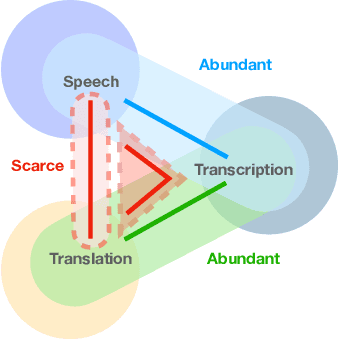
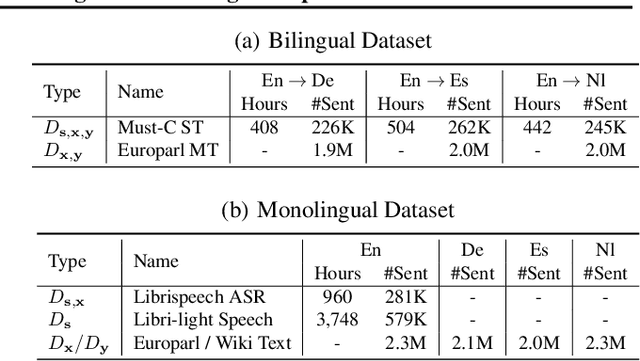
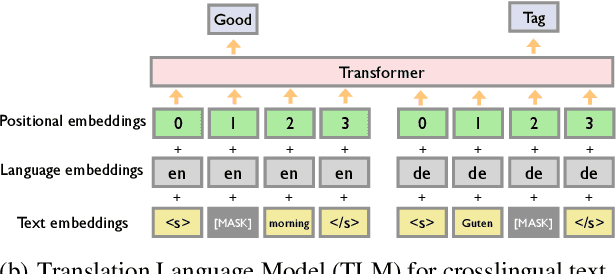
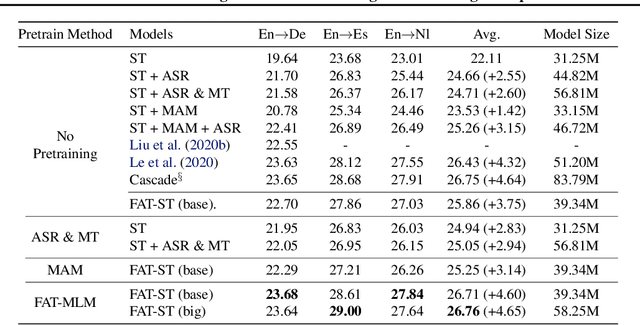
Recently text and speech representation learning has successfully improved many language related tasks. However, all existing methods only learn from one input modality, while a unified acoustic and text representation is desired by many speech-related tasks such as speech translation. We propose a Fused Acoustic and Text Masked Language Model (FAT-MLM) which jointly learns a unified representation for both acoustic and text in-put. Within this cross modal representation learning framework, we further present an end-to-end model for Fused Acoustic and Text Speech Translation (FAT-ST). Experiments on three translation directions show that our proposed speech translation models fine-tuned from FAT-MLM substantially improve translation quality (+5.90 BLEU).
Distance-aware Molecule Graph Attention Network for Drug-Target Binding Affinity Prediction
Dec 17, 2020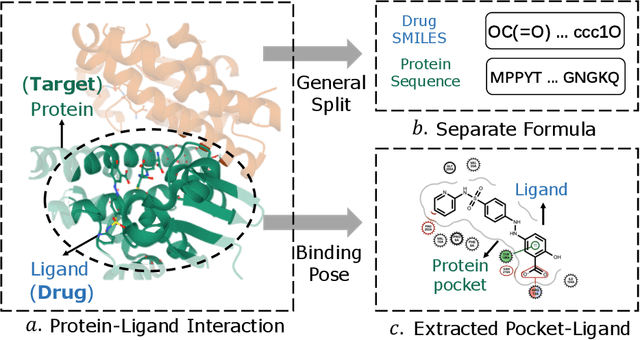

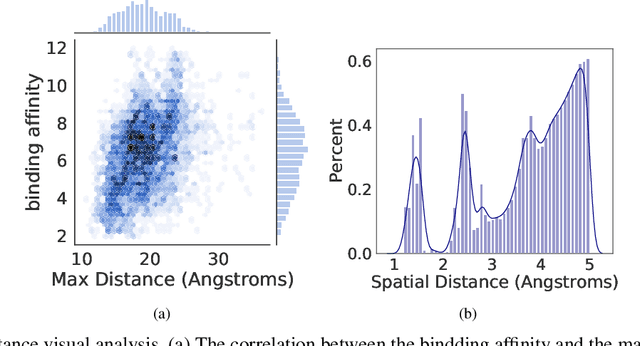
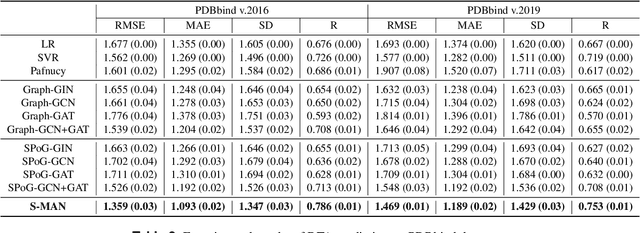
Accurately predicting the binding affinity between drugs and proteins is an essential step for computational drug discovery. Since graph neural networks (GNNs) have demonstrated remarkable success in various graph-related tasks, GNNs have been considered as a promising tool to improve the binding affinity prediction in recent years. However, most of the existing GNN architectures can only encode the topological graph structure of drugs and proteins without considering the relative spatial information among their atoms. Whereas, different from other graph datasets such as social networks and commonsense knowledge graphs, the relative spatial position and chemical bonds among atoms have significant impacts on the binding affinity. To this end, in this paper, we propose a diStance-aware Molecule graph Attention Network (S-MAN) tailored to drug-target binding affinity prediction. As a dedicated solution, we first propose a position encoding mechanism to integrate the topological structure and spatial position information into the constructed pocket-ligand graph. Moreover, we propose a novel edge-node hierarchical attentive aggregation structure which has edge-level aggregation and node-level aggregation. The hierarchical attentive aggregation can capture spatial dependencies among atoms, as well as fuse the position-enhanced information with the capability of discriminating multiple spatial relations among atoms. Finally, we conduct extensive experiments on two standard datasets to demonstrate the effectiveness of S-MAN.
Context-aware Stand-alone Neural Spelling Correction
Nov 12, 2020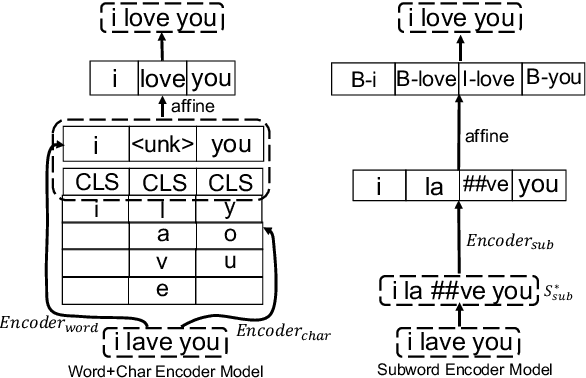
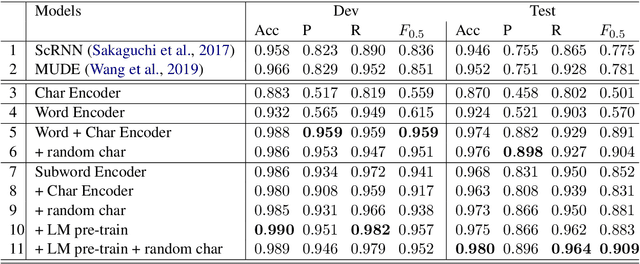
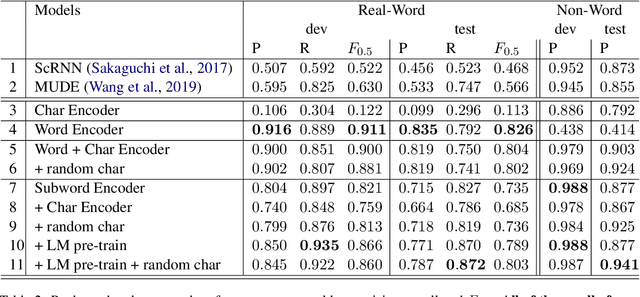

Existing natural language processing systems are vulnerable to noisy inputs resulting from misspellings. On the contrary, humans can easily infer the corresponding correct words from their misspellings and surrounding context. Inspired by this, we address the stand-alone spelling correction problem, which only corrects the spelling of each token without additional token insertion or deletion, by utilizing both spelling information and global context representations. We present a simple yet powerful solution that jointly detects and corrects misspellings as a sequence labeling task by fine-turning a pre-trained language model. Our solution outperforms the previous state-of-the-art result by 12.8% absolute F0.5 score.
SigNet: An Advanced Deep Learning Framework for Radio Signal Classification
Oct 28, 2020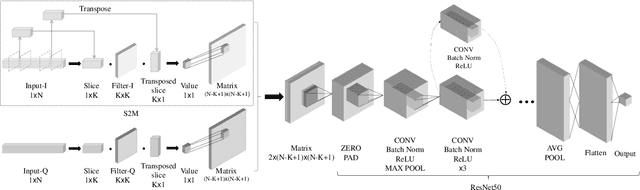
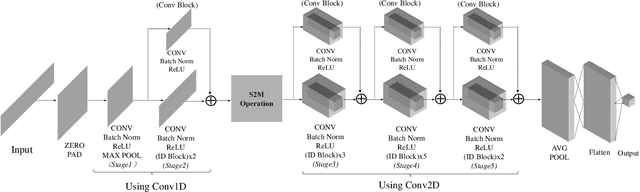
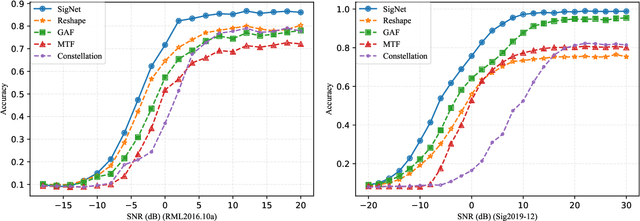
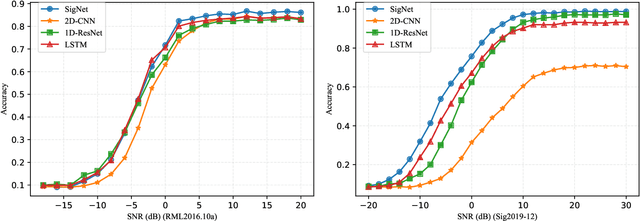
Deep learning methods achieve great success in many areas due to their powerful feature extraction capabilities and end-to-end training mechanism, and recently they are also introduced for radio signal modulation classification. In this paper, we propose a novel deep learning framework called SigNet, where a signal-to-matrix (S2M) operator is adopted to convert the original signal into a square matrix first and is co-trained with a follow-up CNN architecture for classification. This model is further accelerated by integrating 1D convolution operators, leading to the upgraded model SigNet2.0. The experiments on two signal datasets show that both SigNet and SigNet2.0 outperform a number of well-known baselines, achieving the state-of-the-art performance. Notably, they obtain significantly higher accuracy than 1D-ResNet and 2D-CNN (at most increasing 70.5\%), while much faster than LSTM (at most saving 88.0\% training time). More interestingly, our proposed models behave extremely well in few-shot learning when a small training data set is provided. They can achieve a relatively high accuracy even when 1\% training data are kept, while other baseline models may lose their effectiveness much more quickly as the datasets get smaller. Such result suggests that SigNet/SigNet2.0 could be extremely useful in the situations where labeled signal data are difficult to obtain.